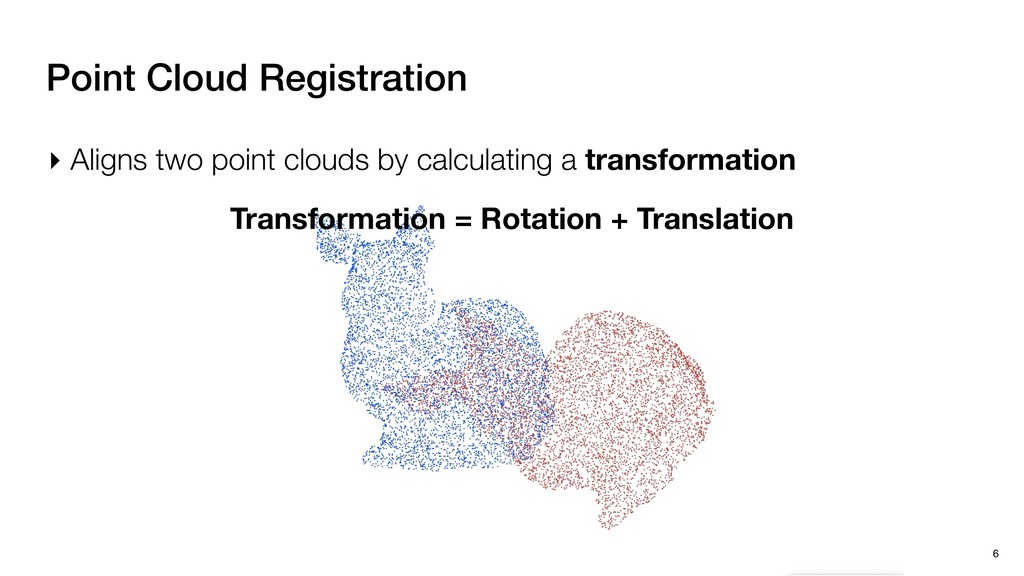
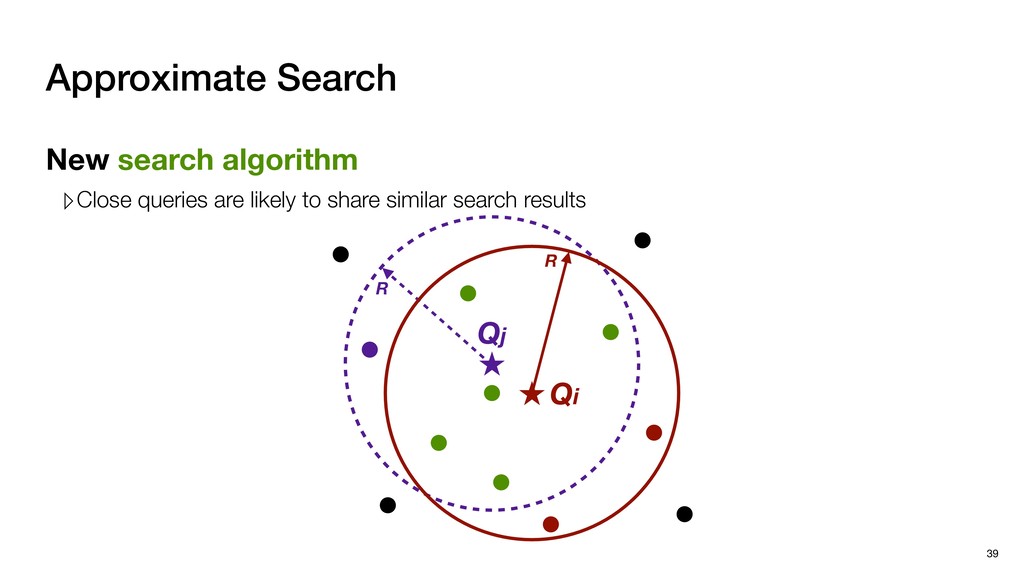
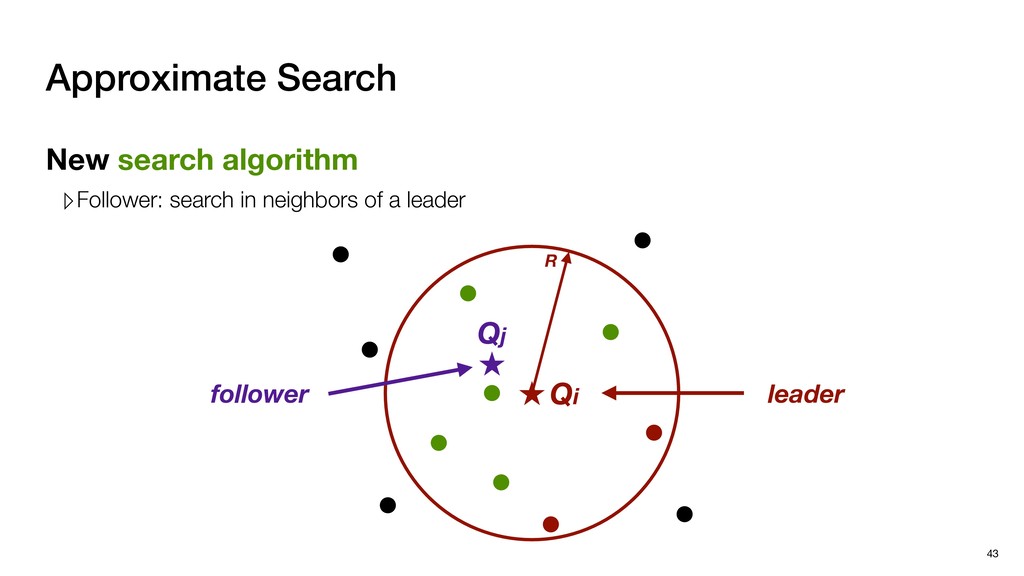
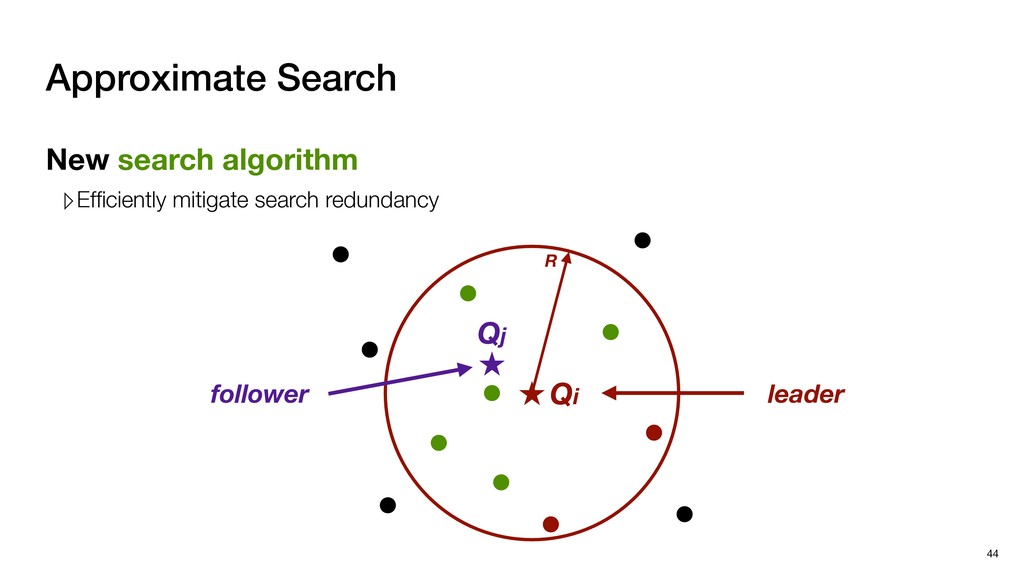
coordinates ‣ Effective in capturing visual features ‣ 3-d scanners/sensors ▹ Scan from multiple perspectives ▹ Stitch these Point Clouds to form a complete Point Cloud
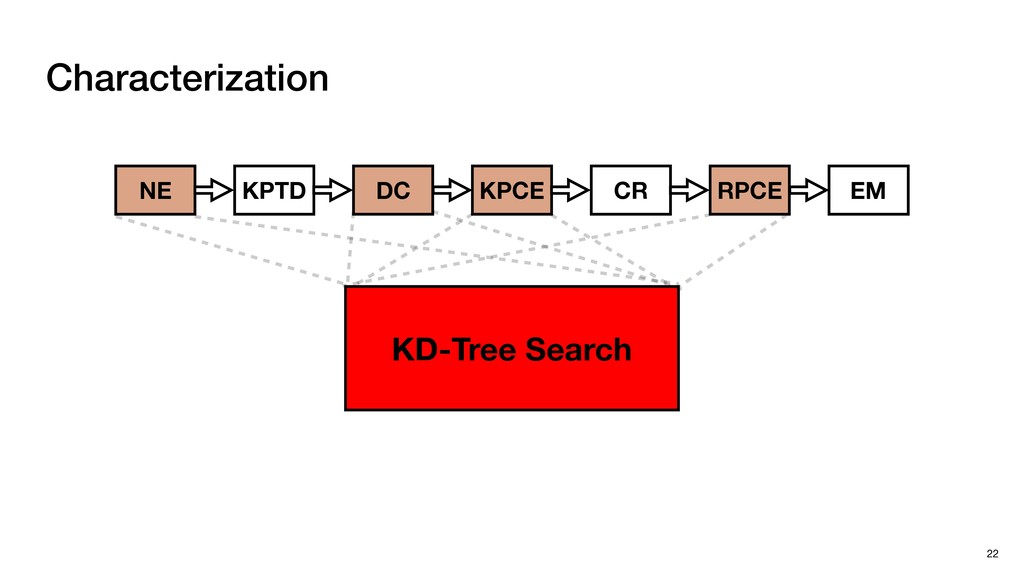
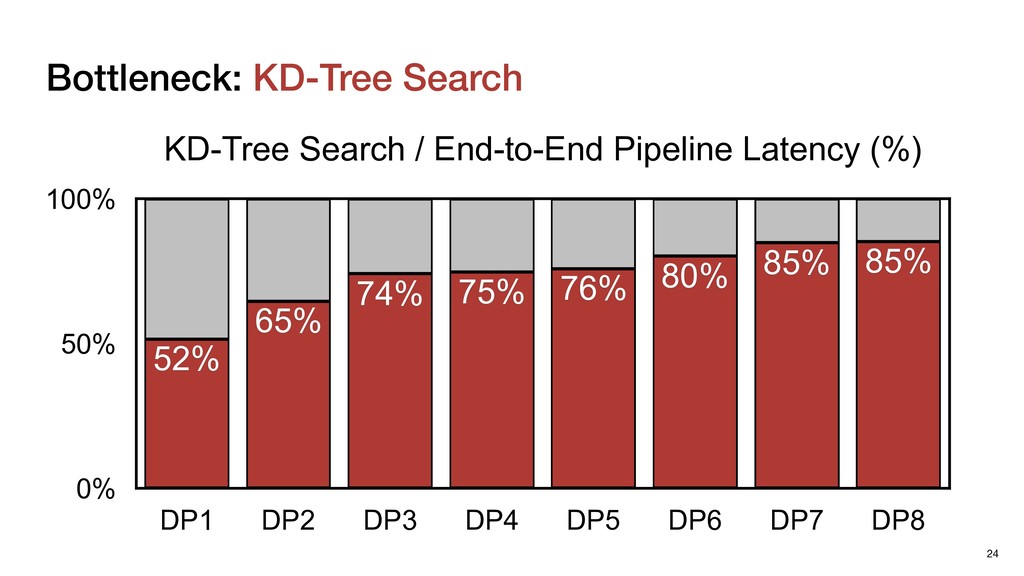
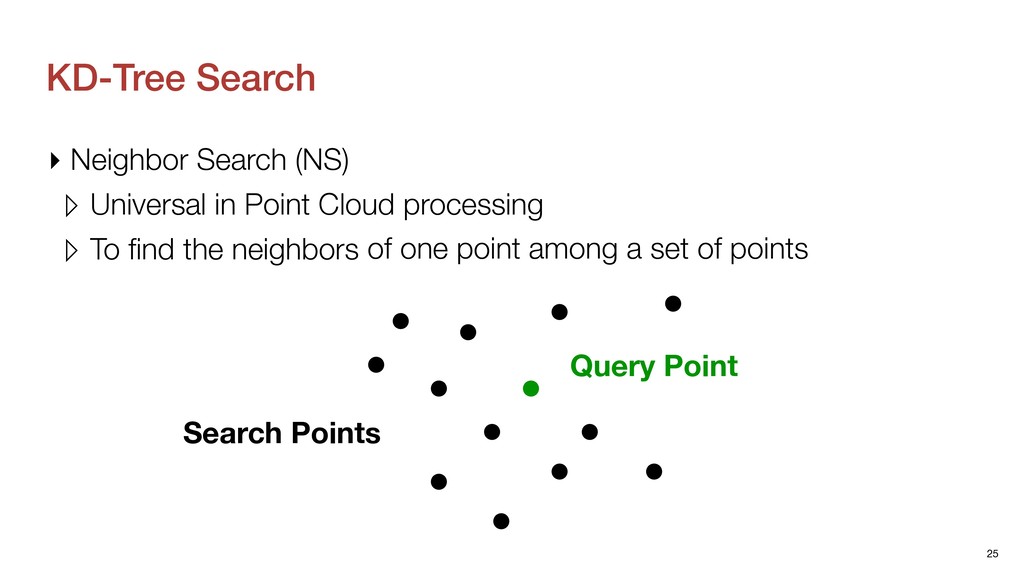
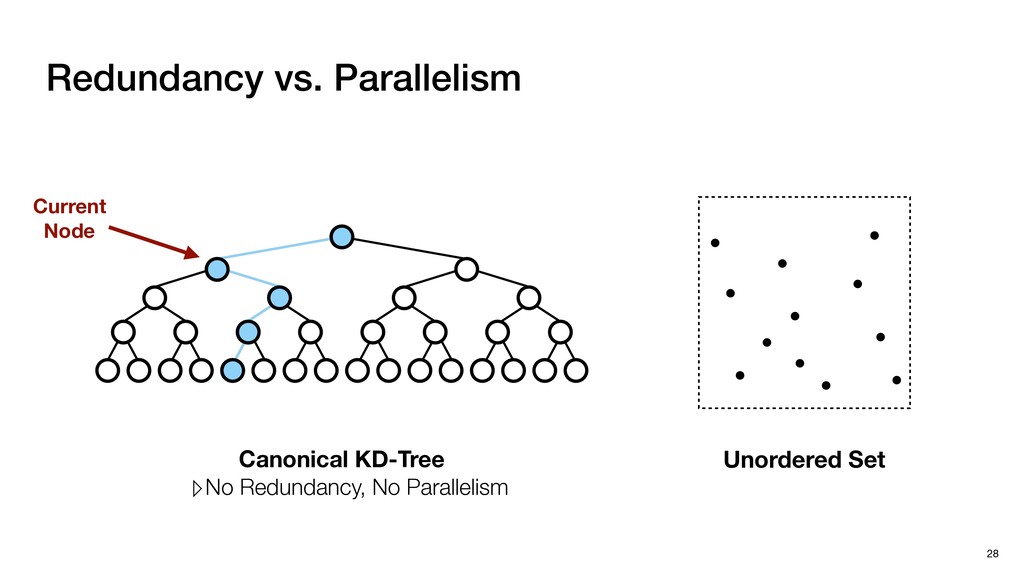
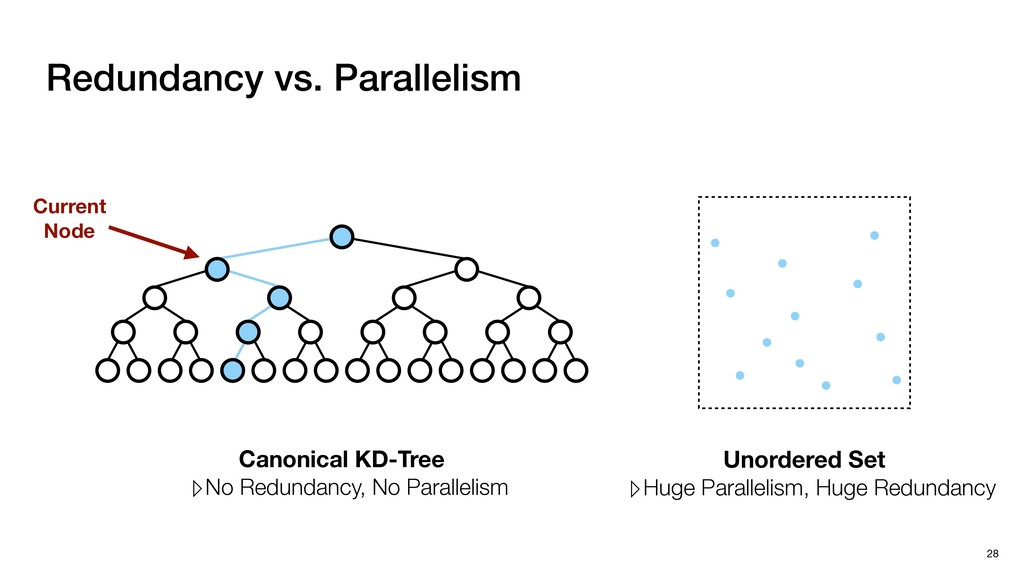
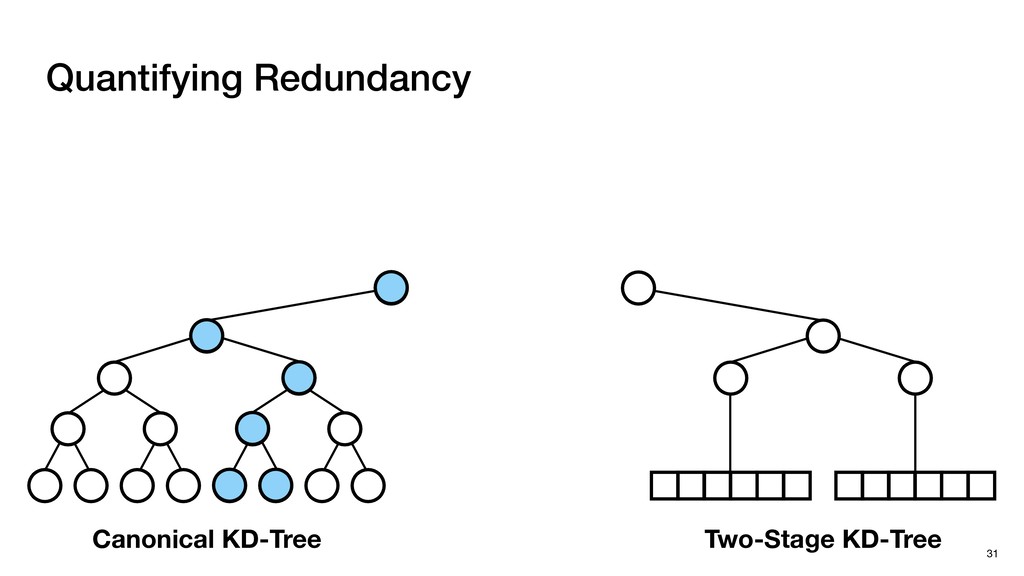
Cloud processing ▹ To find the neighbors ▸ KD-Tree Search ▹ Standard implementation for NS in point clouds ▹ Effectively reduces the computation workload of NS 26 of one point among a set of points
Cloud processing ▹ To find the neighbors ▸ KD-Tree Search ▹ Standard implementation for NS in point clouds ▹ Effectively reduces the computation workload of NS ▹ Inefficient on GPUs due to its sequential nature 26 of one point among a set of points
Cloud processing ▹ To find the neighbors ▸ KD-Tree Search ▹ Standard implementation for NS in point clouds ▹ Effectively reduces the computation workload of NS ▹ Inefficient on GPUs due to its sequential nature ▹ Challenging for hardware acceleration 26 of one point among a set of points
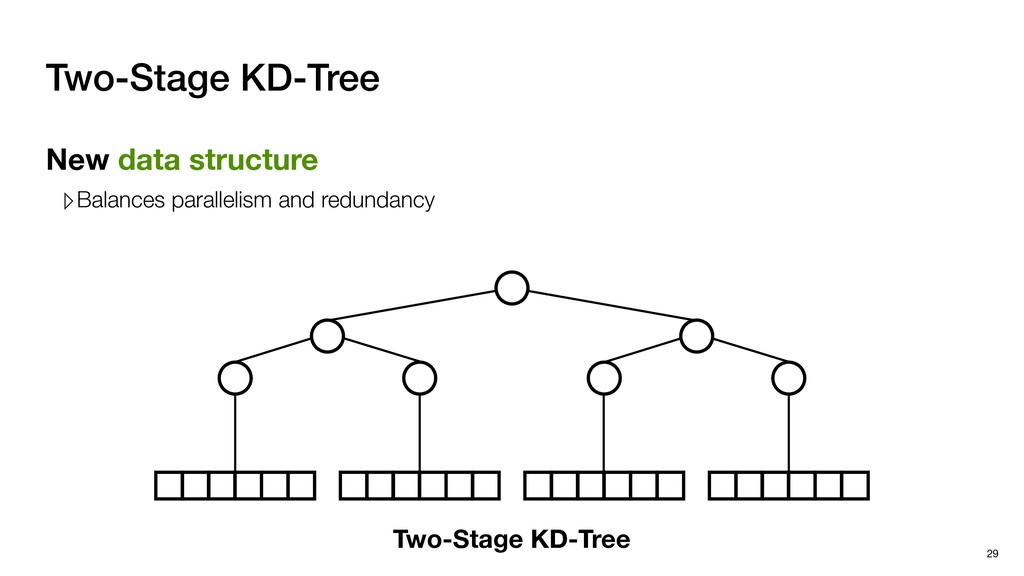
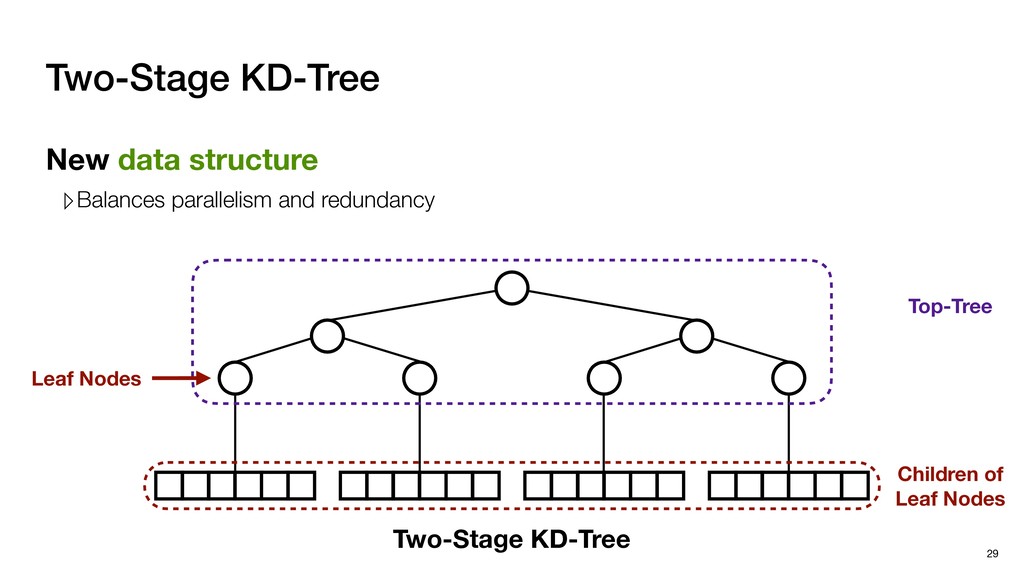
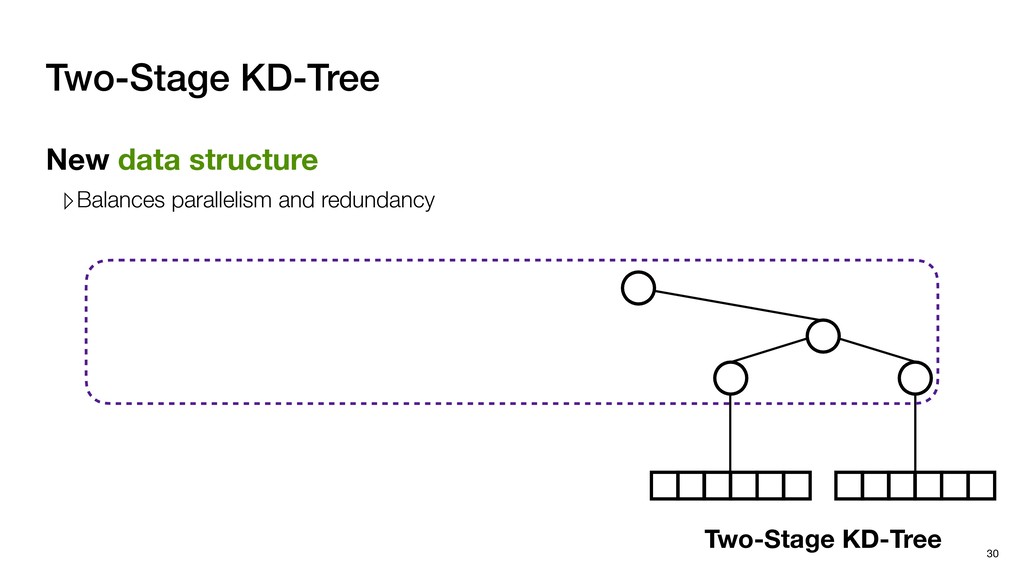
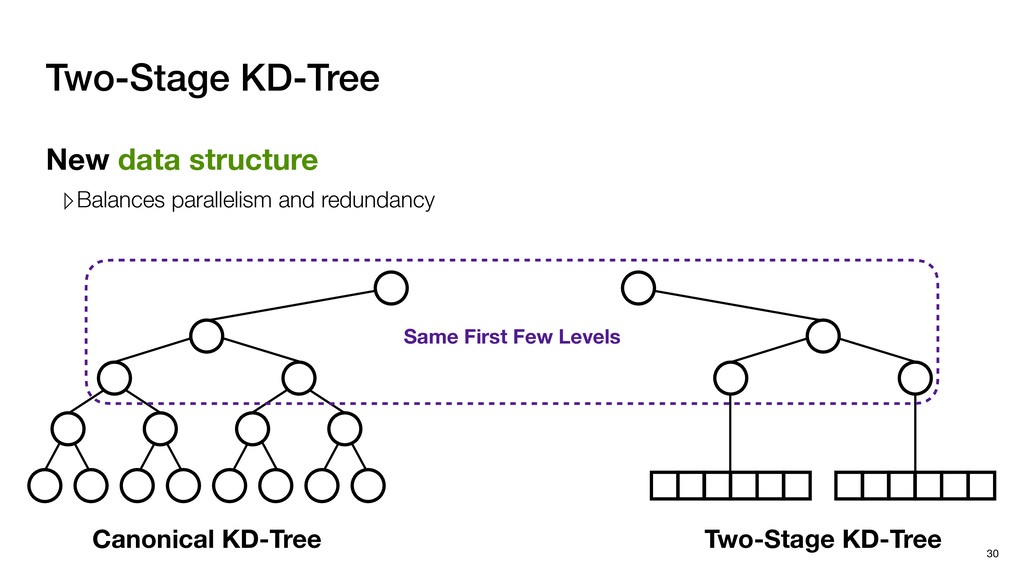
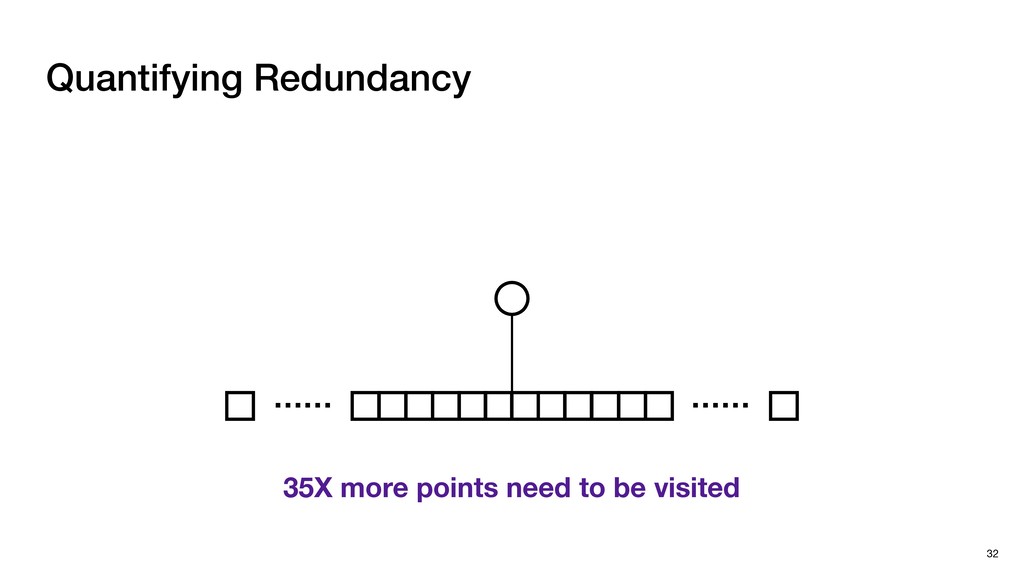
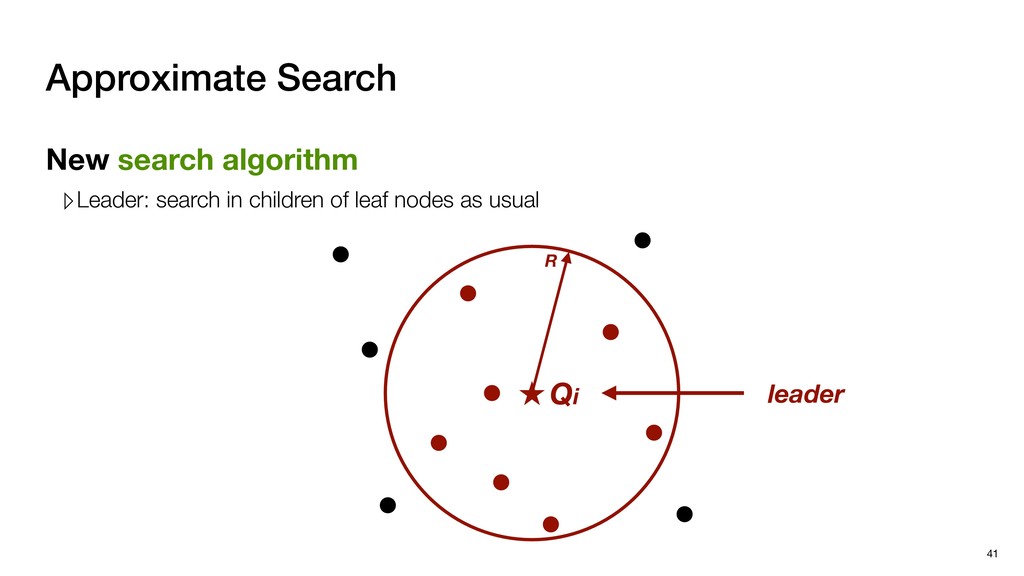
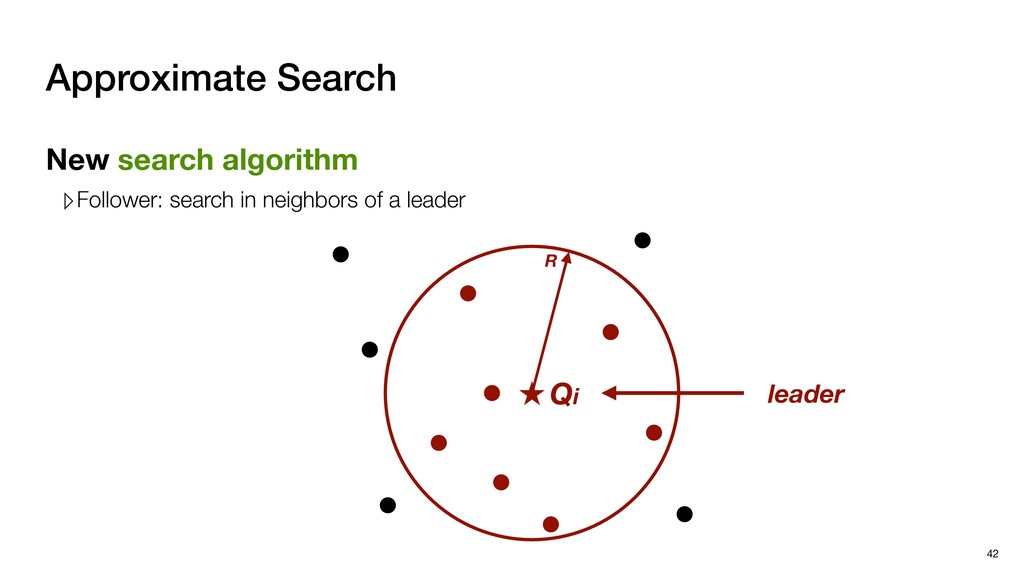
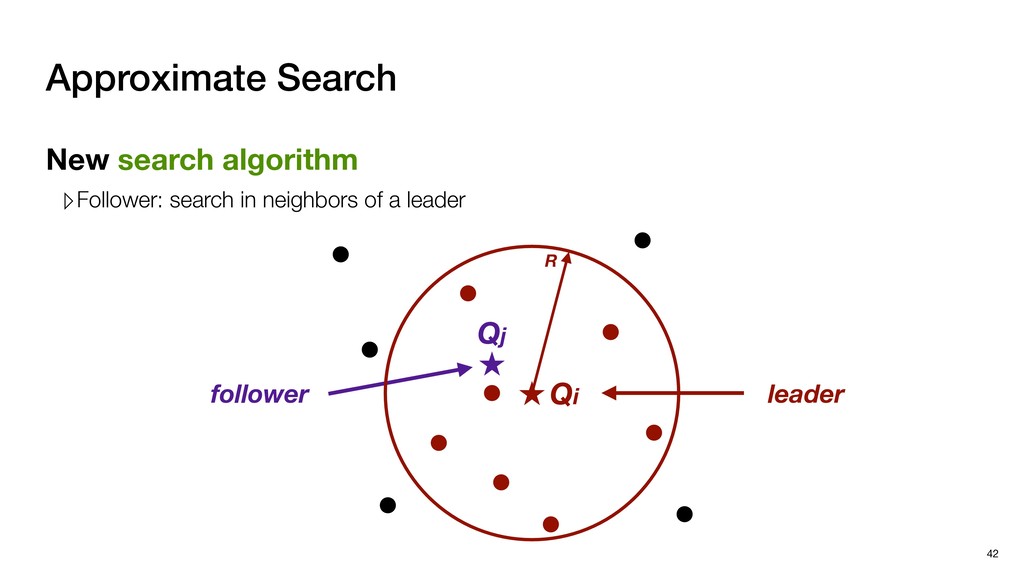
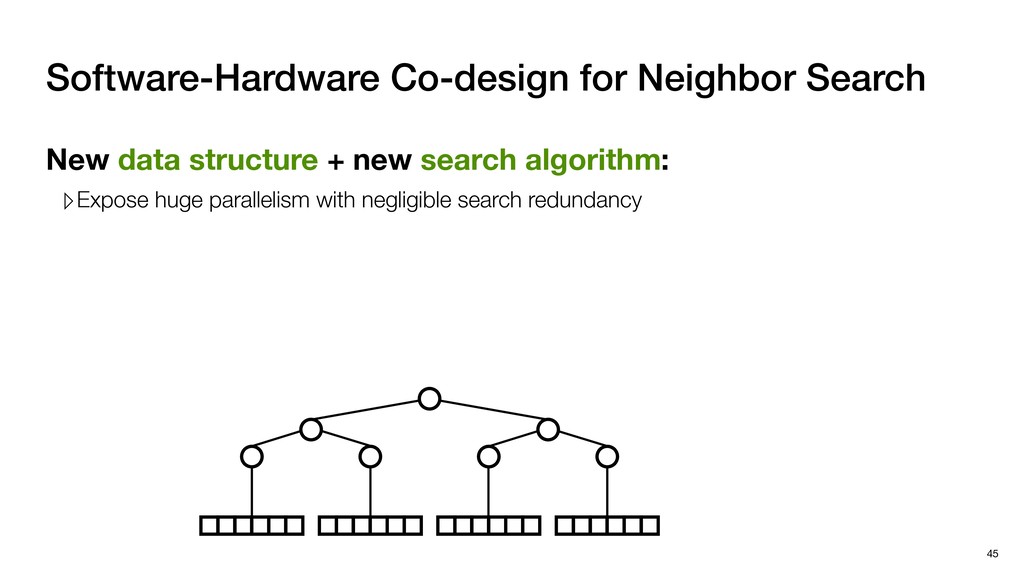
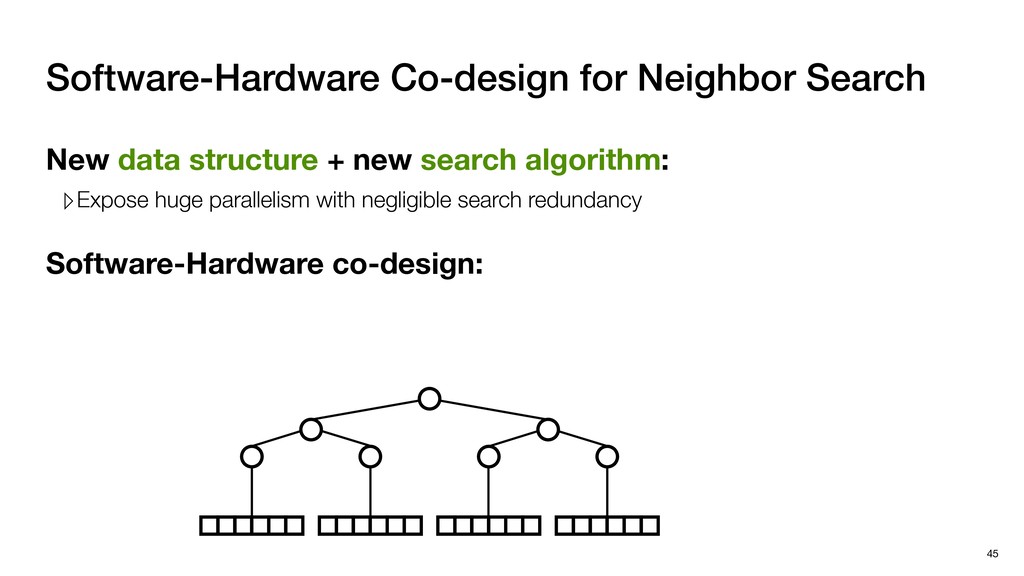
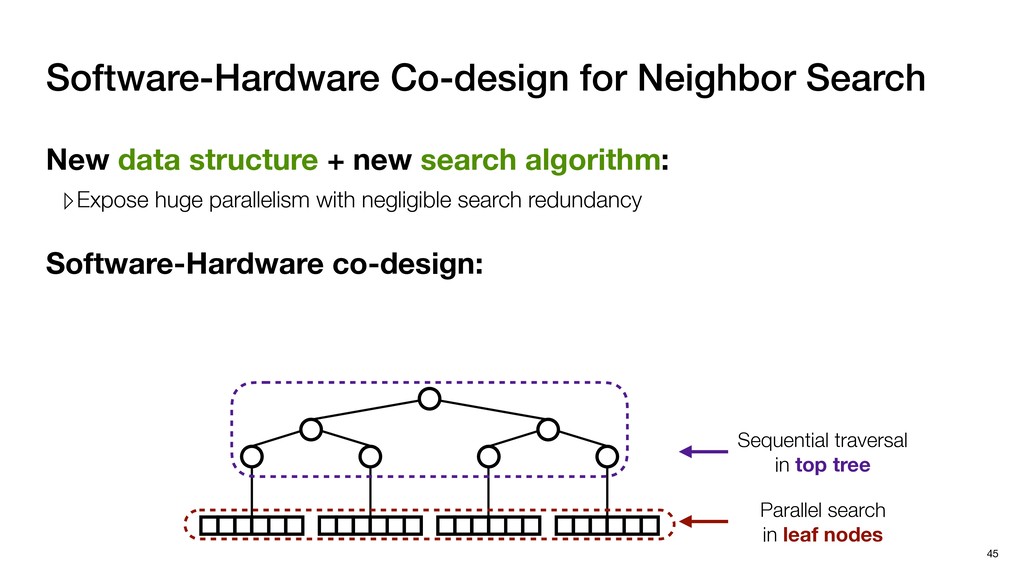
with negligible search redundancy Software-Hardware co-design: Software-Hardware Co-design for Neighbor Search 45 Sequential traversal in top tree Parallel search in leaf nodes
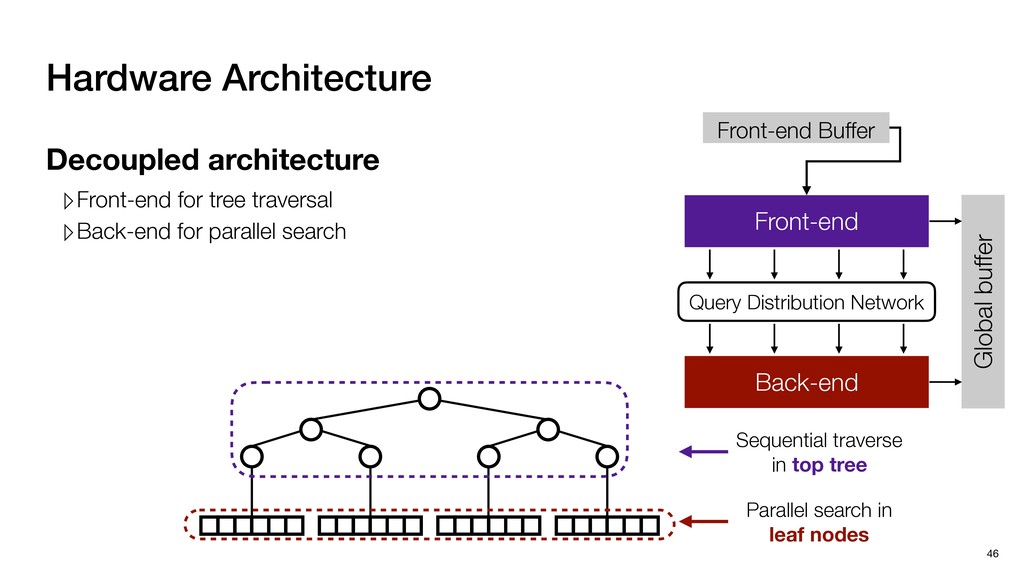
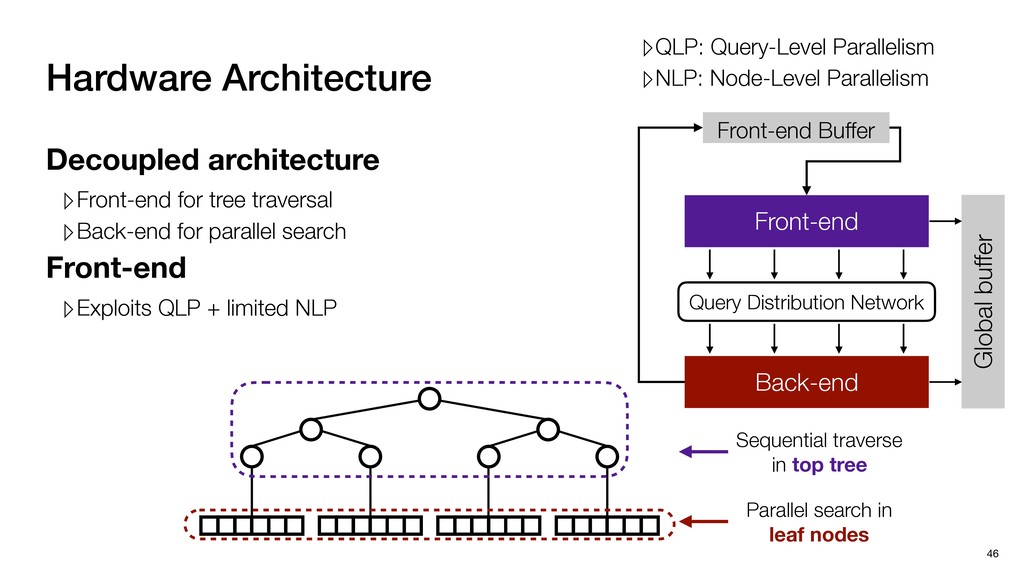
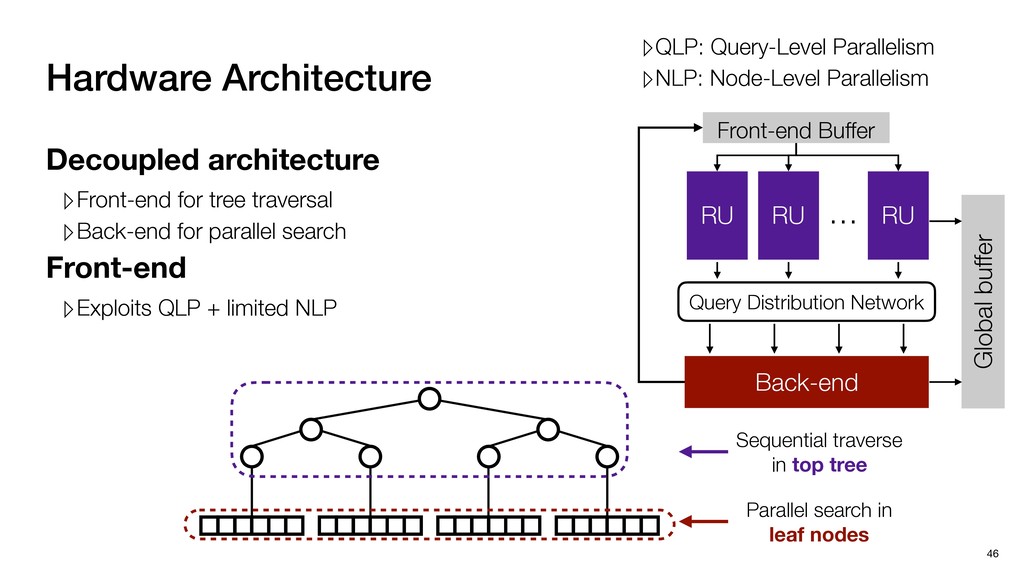
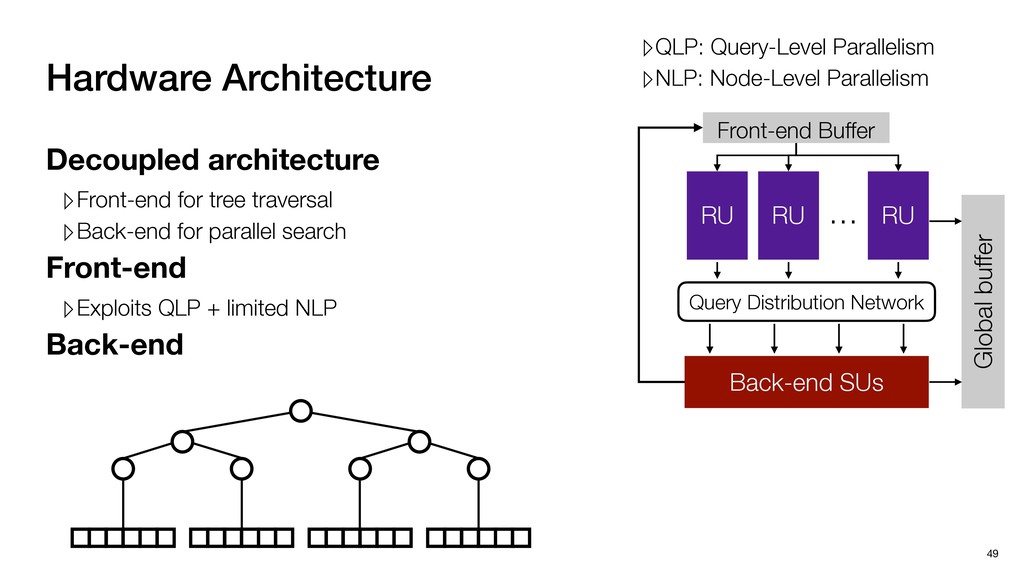
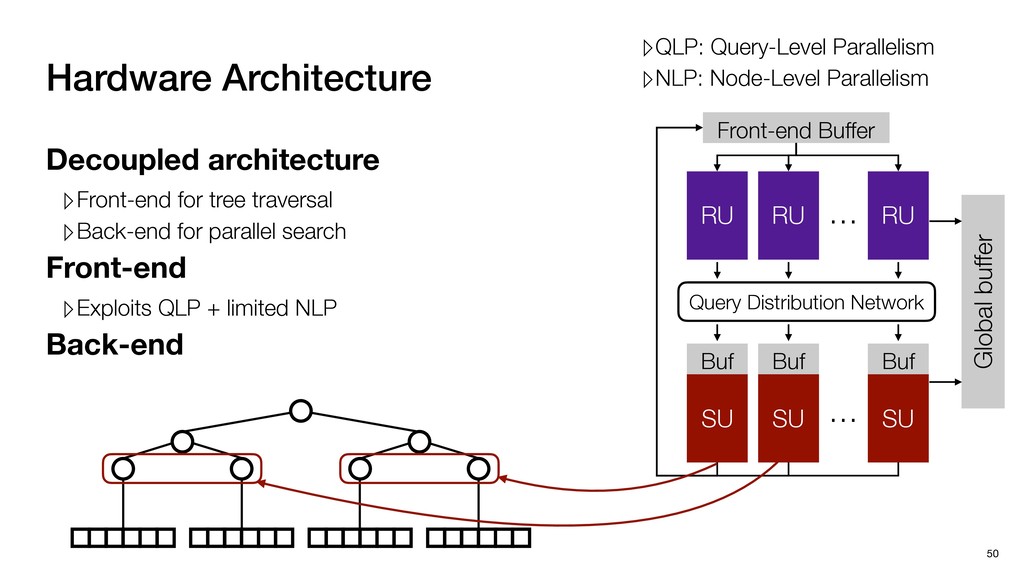
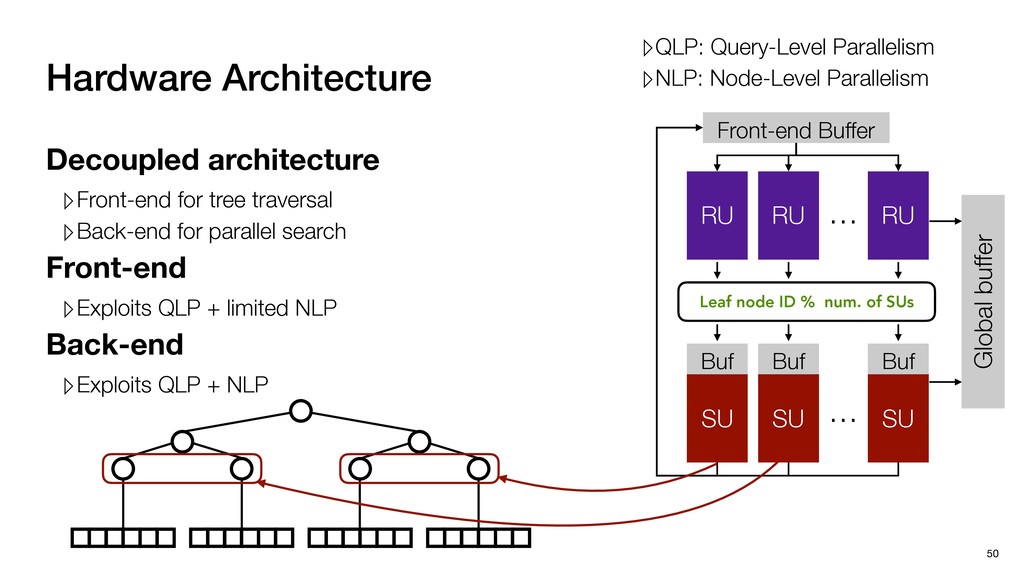
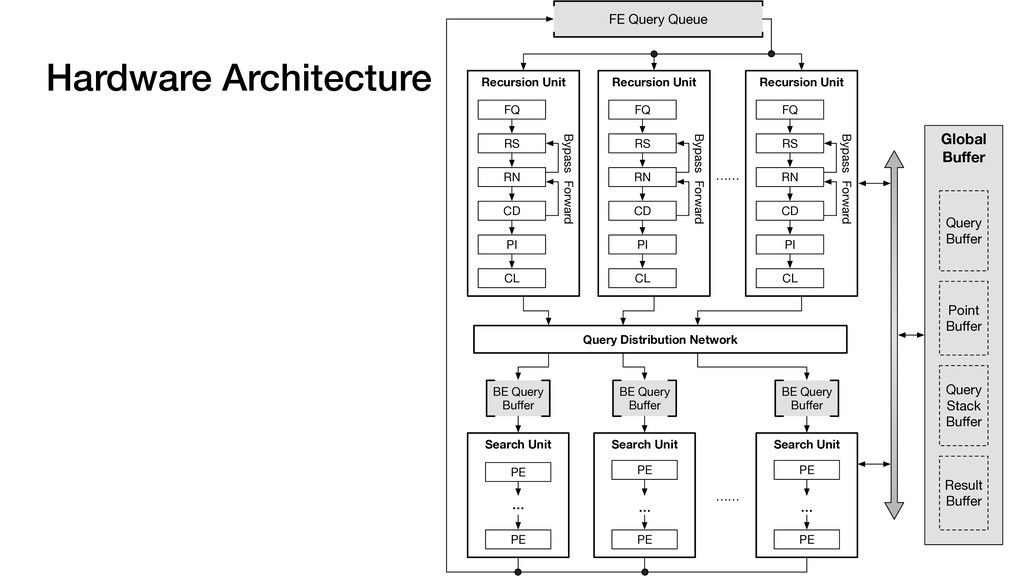
Global buffer Decoupled architecture ▹Front-end for tree traversal ▹Back-end for parallel search Sequential traverse in top tree Parallel search in leaf nodes
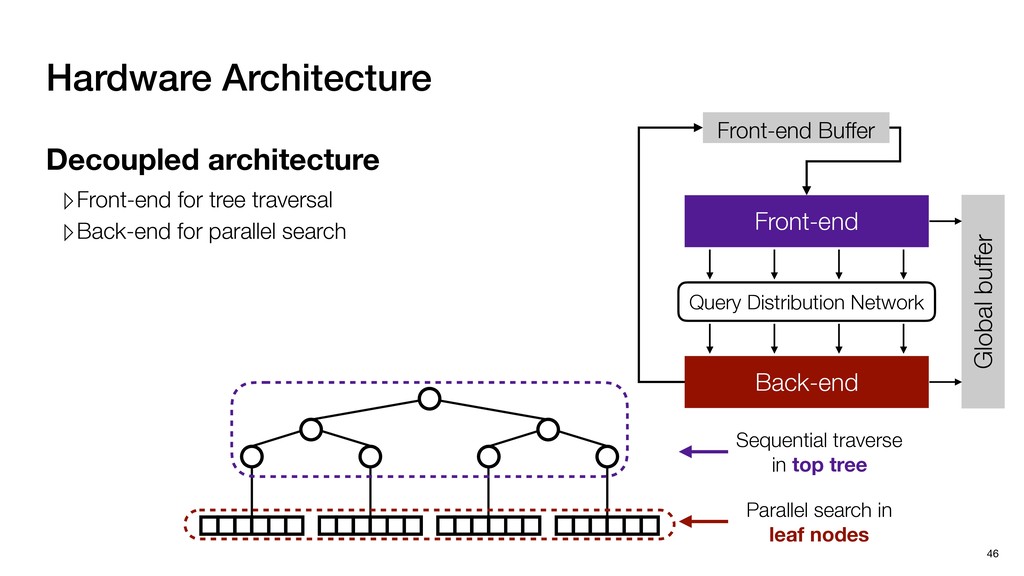
Global buffer Decoupled architecture ▹Front-end for tree traversal ▹Back-end for parallel search Sequential traverse in top tree Parallel search in leaf nodes
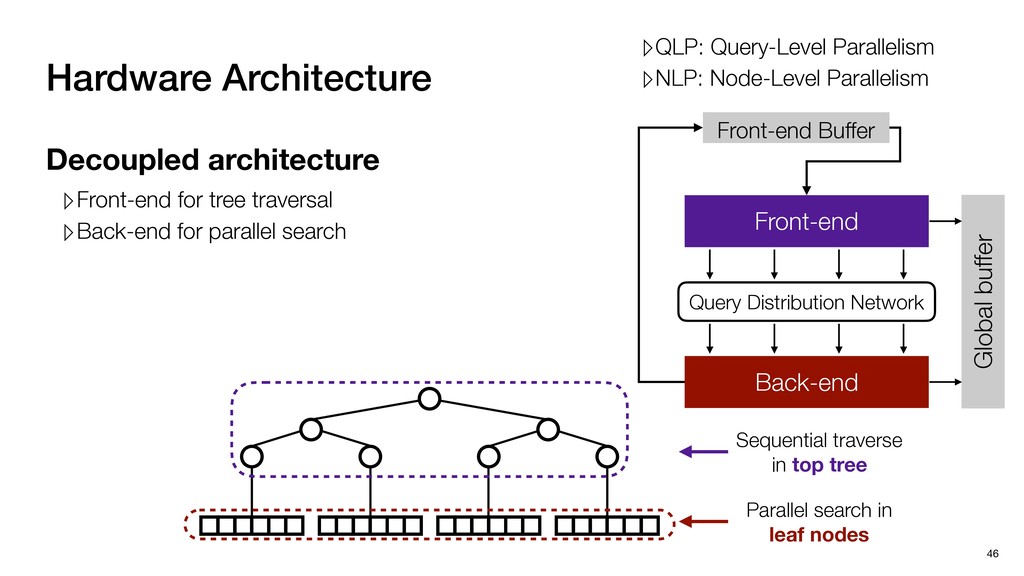
Global buffer Decoupled architecture ▹Front-end for tree traversal ▹Back-end for parallel search ▹QLP: Query-Level Parallelism ▹NLP: Node-Level Parallelism Sequential traverse in top tree Parallel search in leaf nodes
Global buffer Decoupled architecture ▹Front-end for tree traversal ▹Back-end for parallel search Front-end ▹Exploits QLP + limited NLP ▹QLP: Query-Level Parallelism ▹NLP: Node-Level Parallelism Sequential traverse in top tree Parallel search in leaf nodes
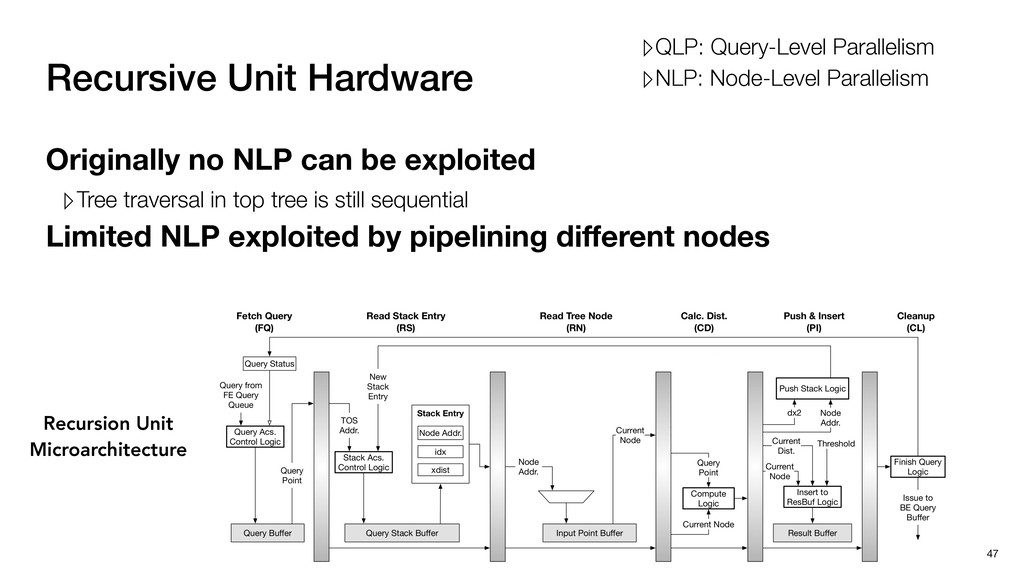
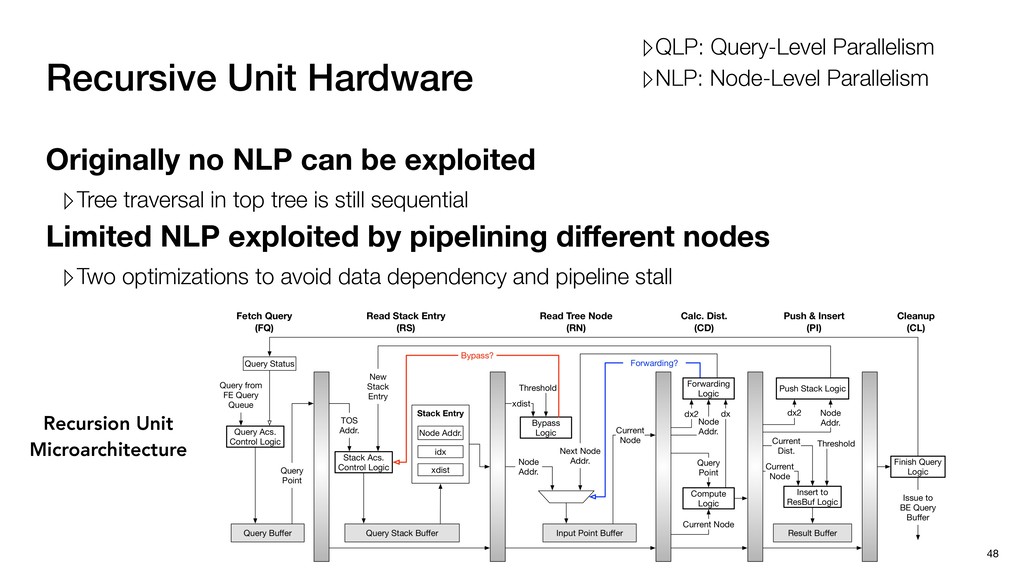
traversal in top tree is still sequential Limited NLP exploited by pipelining different nodes 47 ▹QLP: Query-Level Parallelism ▹NLP: Node-Level Parallelism Recursion Unit Microarchitecture
traversal in top tree is still sequential Limited NLP exploited by pipelining different nodes ▹Two optimizations to avoid data dependency and pipeline stall 48 Recursion Unit Microarchitecture ▹QLP: Query-Level Parallelism ▹NLP: Node-Level Parallelism
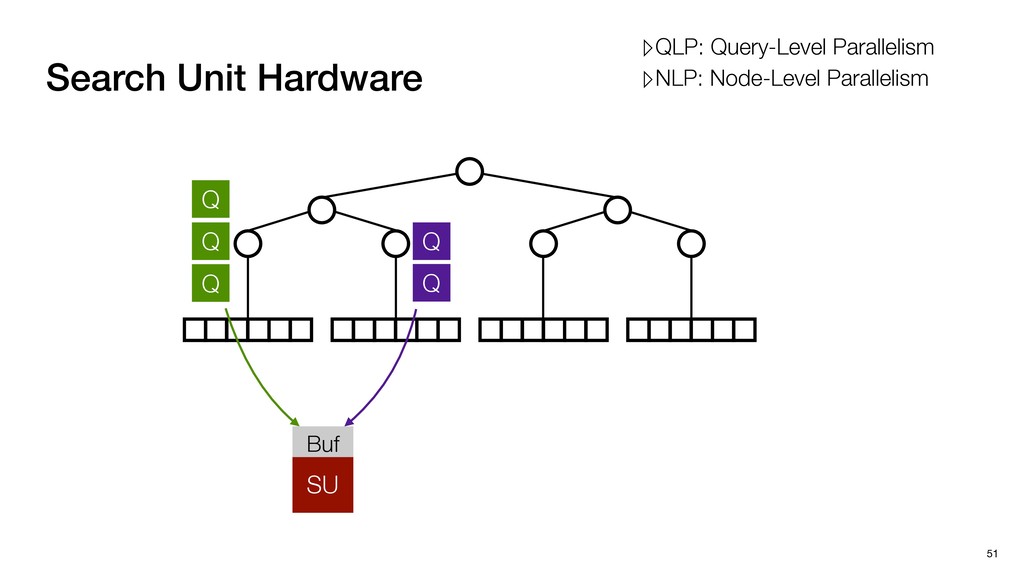
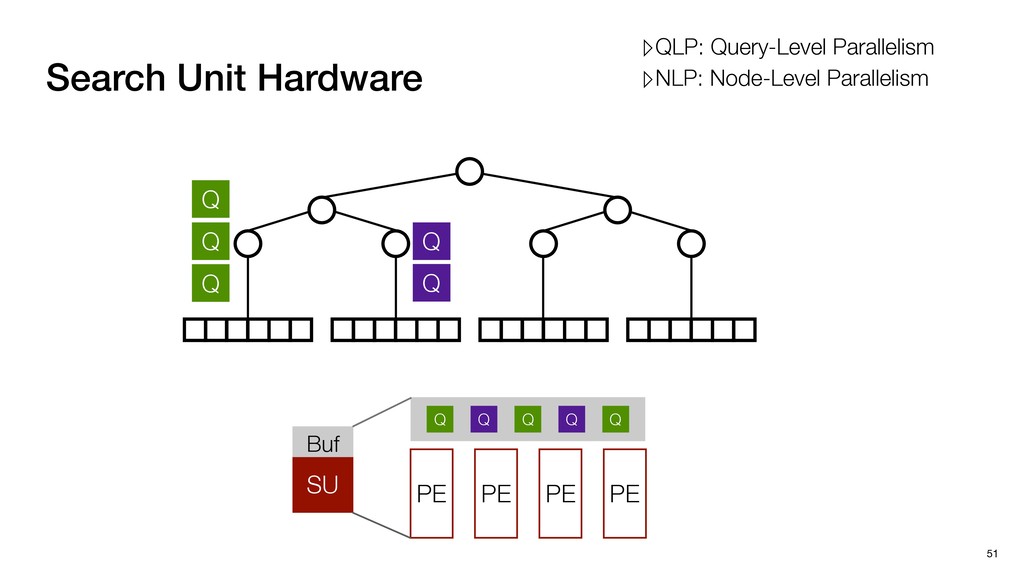
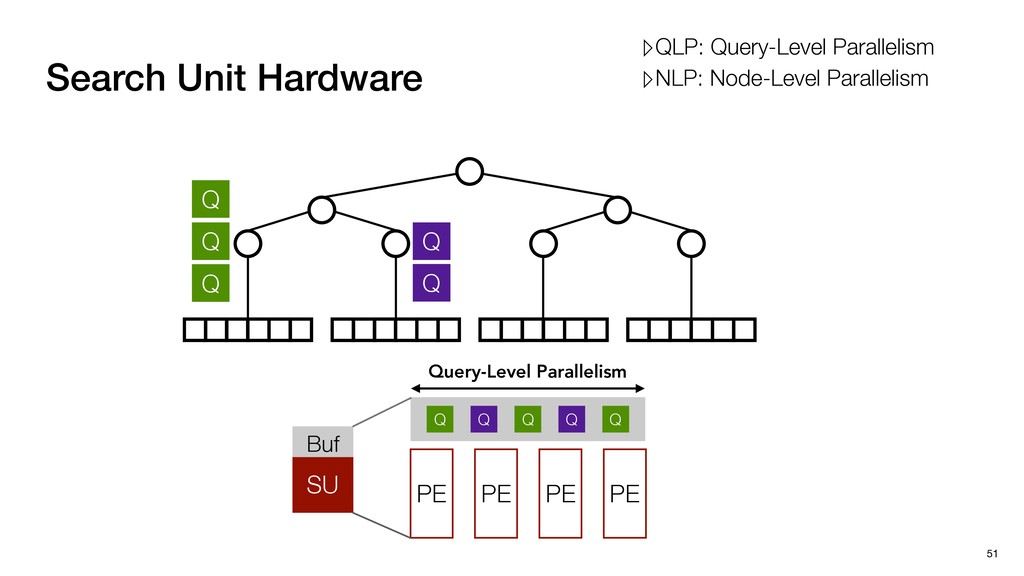
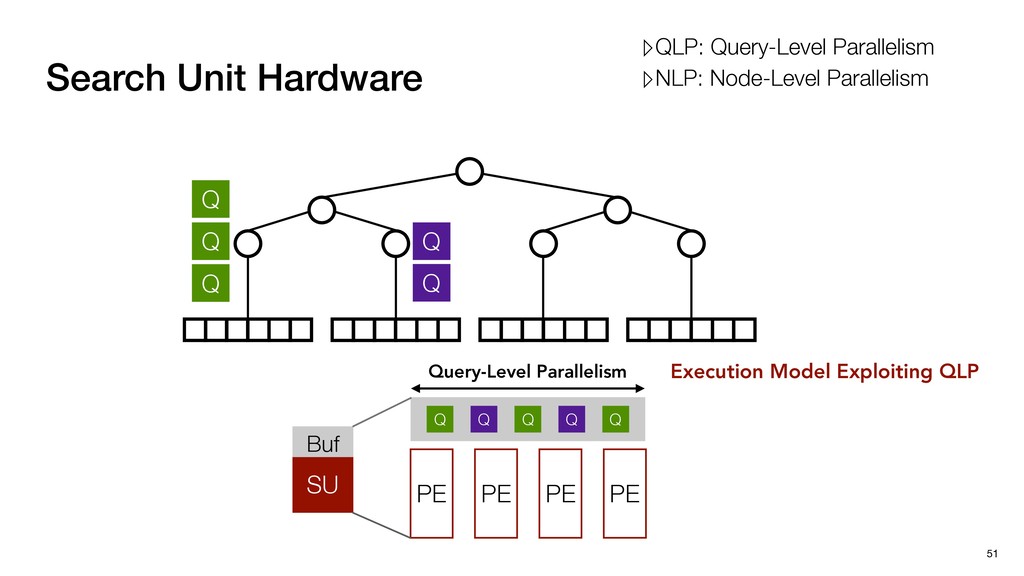
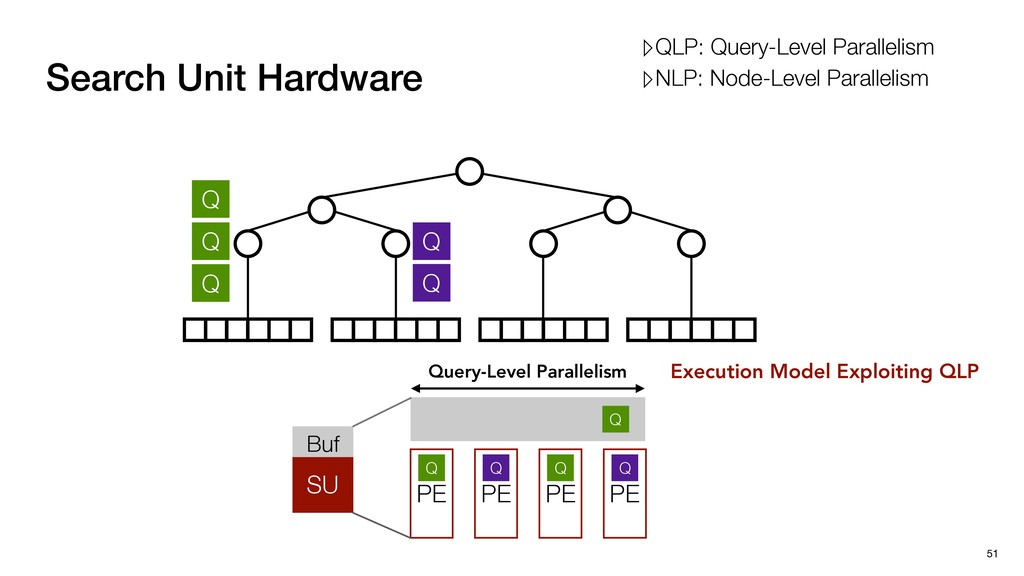
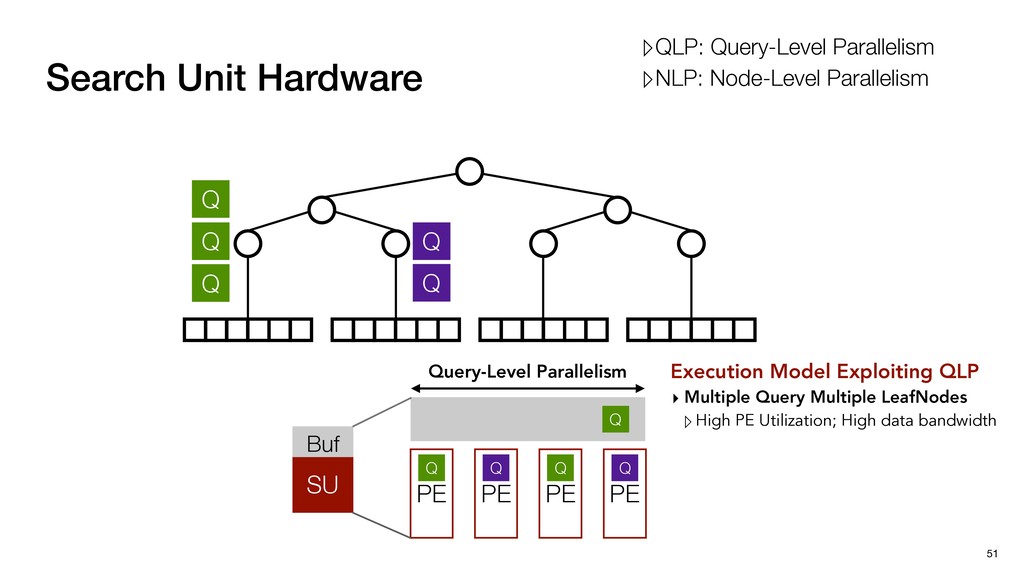
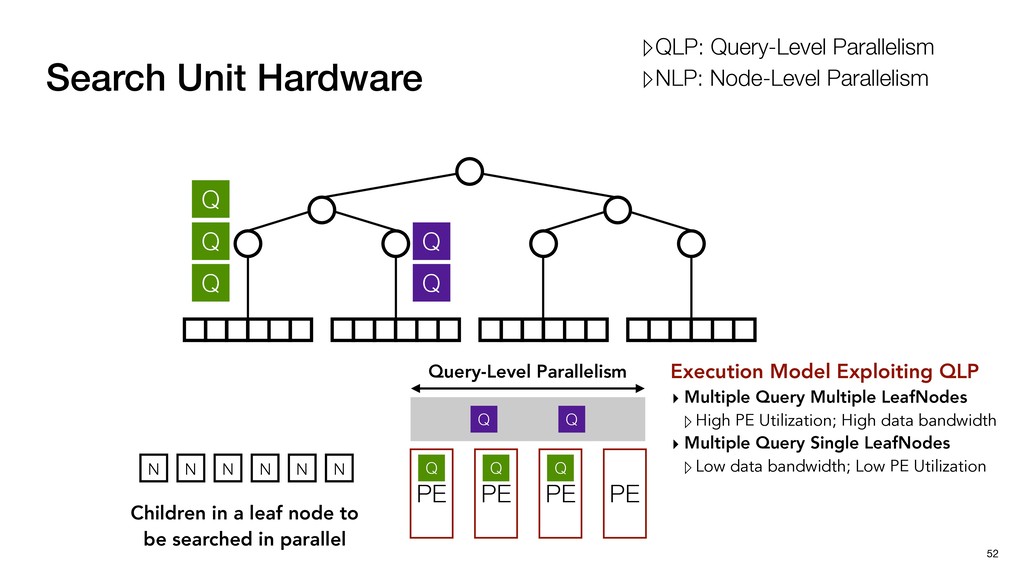
Buf Q Q Q Q Q Query-Level Parallelism PE PE PE PE Execution Model Exploiting QLP ▸ Multiple Query Multiple LeafNodes ▹High PE Utilization; High data bandwidth ▹QLP: Query-Level Parallelism ▹NLP: Node-Level Parallelism
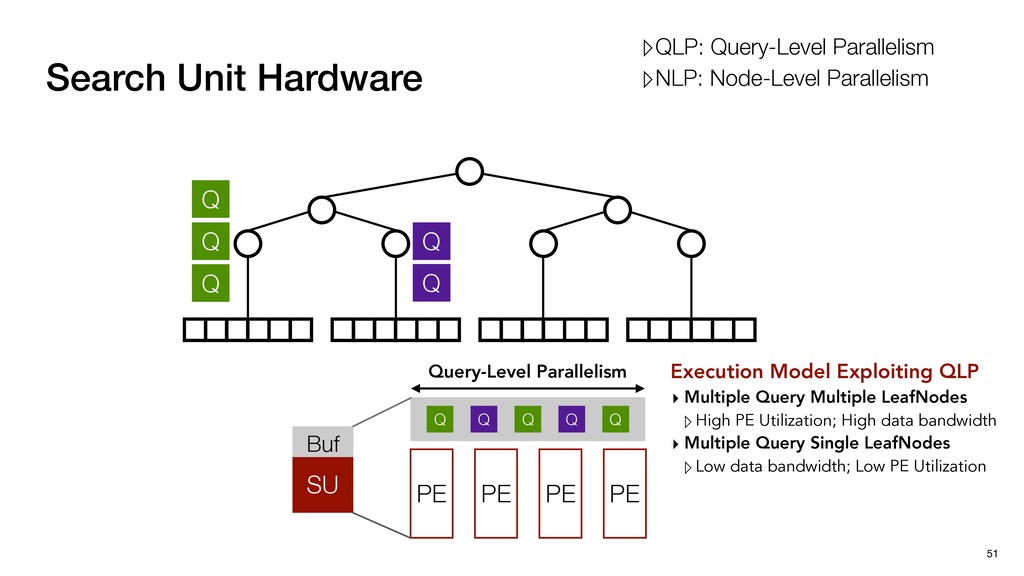
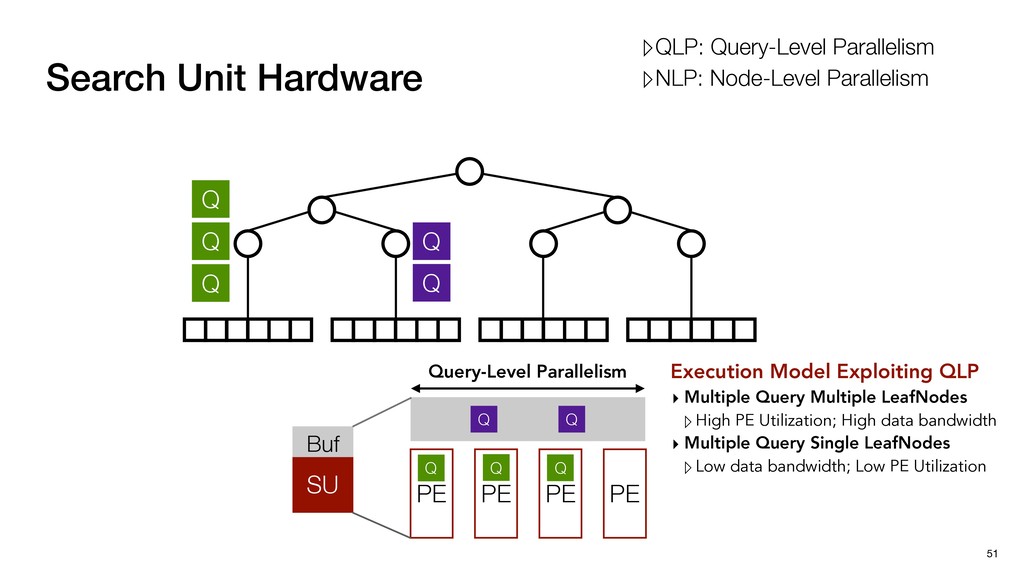
Buf Q Q Q Q Q Query-Level Parallelism PE PE PE PE Execution Model Exploiting QLP ▸ Multiple Query Multiple LeafNodes ▹High PE Utilization; High data bandwidth ▸ Multiple Query Single LeafNodes ▹Low data bandwidth; Low PE Utilization ▹QLP: Query-Level Parallelism ▹NLP: Node-Level Parallelism
Buf Q Q Q Q Q Query-Level Parallelism PE PE PE PE Execution Model Exploiting QLP ▸ Multiple Query Multiple LeafNodes ▹High PE Utilization; High data bandwidth ▸ Multiple Query Single LeafNodes ▹Low data bandwidth; Low PE Utilization ▹QLP: Query-Level Parallelism ▹NLP: Node-Level Parallelism
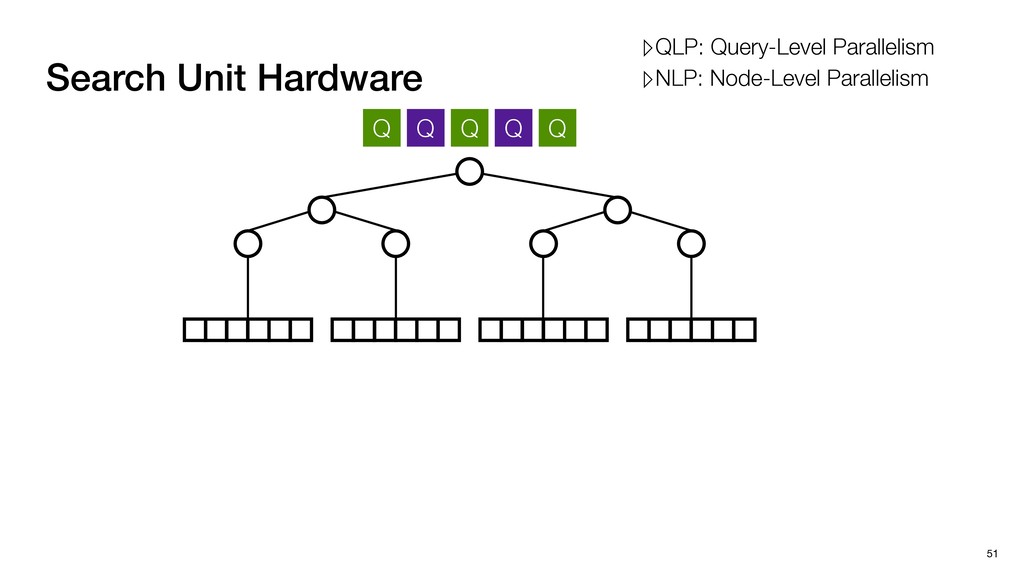
PE Utilization; High data bandwidth ▸ Multiple Query Single LeafNodes ▹Low data bandwidth; Low PE Utilization PE PE PE Q Q Q Q Q Q Q Search Unit Hardware 52 Q Q Q Q Q PE N N N N N N Children in a leaf node to be searched in parallel Query-Level Parallelism ▹QLP: Query-Level Parallelism ▹NLP: Node-Level Parallelism
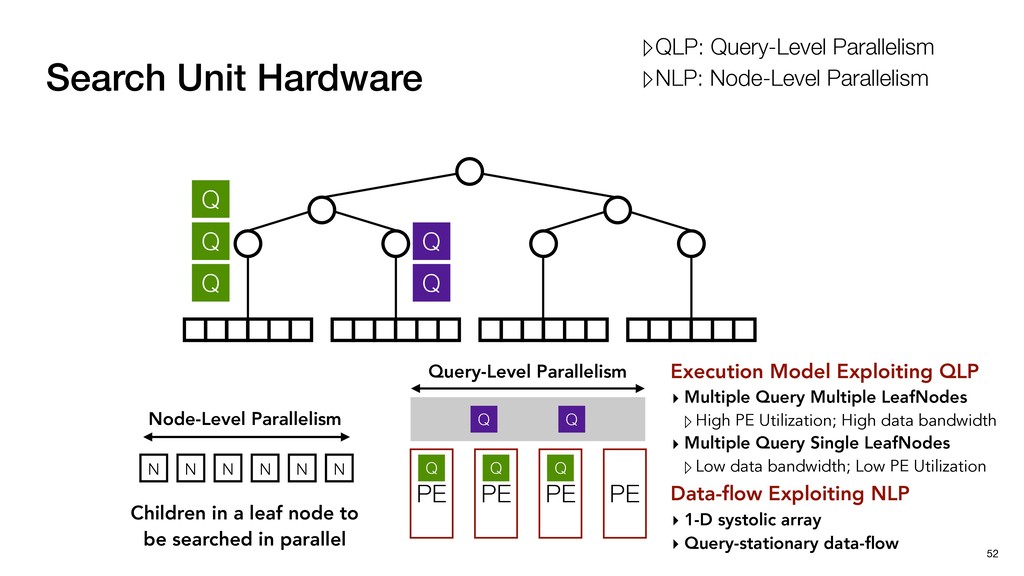
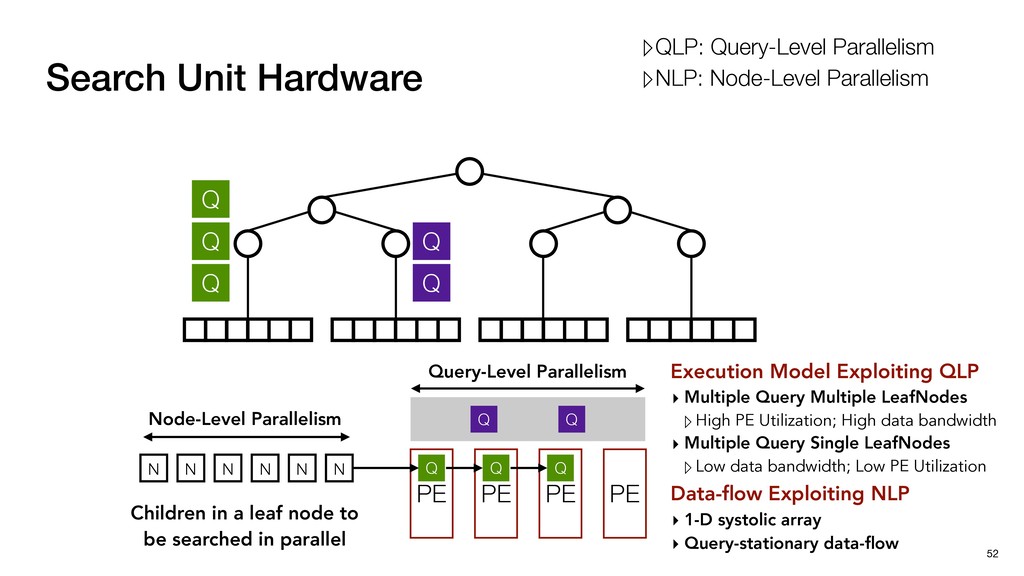
PE Utilization; High data bandwidth ▸ Multiple Query Single LeafNodes ▹Low data bandwidth; Low PE Utilization PE PE PE Q Q Q Q Q Q Q Search Unit Hardware 52 Q Q Q Q Q Node-Level Parallelism PE N N N N N N Children in a leaf node to be searched in parallel Query-Level Parallelism ▹QLP: Query-Level Parallelism ▹NLP: Node-Level Parallelism
PE Utilization; High data bandwidth ▸ Multiple Query Single LeafNodes ▹Low data bandwidth; Low PE Utilization PE PE PE Q Q Q Q Q Q Q Search Unit Hardware 52 Q Q Q Q Q Node-Level Parallelism PE Data-flow Exploiting NLP ▸ 1-D systolic array ▸ Query-stationary data-flow N N N N N N Children in a leaf node to be searched in parallel Query-Level Parallelism ▹QLP: Query-Level Parallelism ▹NLP: Node-Level Parallelism
PE Utilization; High data bandwidth ▸ Multiple Query Single LeafNodes ▹Low data bandwidth; Low PE Utilization PE PE PE Q Q Q Q Q Q Q Search Unit Hardware 52 Q Q Q Q Q Node-Level Parallelism PE Data-flow Exploiting NLP ▸ 1-D systolic array ▸ Query-stationary data-flow N N N N N N Children in a leaf node to be searched in parallel Query-Level Parallelism ▹QLP: Query-Level Parallelism ▹NLP: Node-Level Parallelism
Ti) • Our System: ✓ Performance: Cycle-accurate simulator parameterized by an RTL model ✓ Power & Area: Post layout simulation in a 16nm process node ‣ All Other Parts: CPU (Intel Xeon Silver 4110)
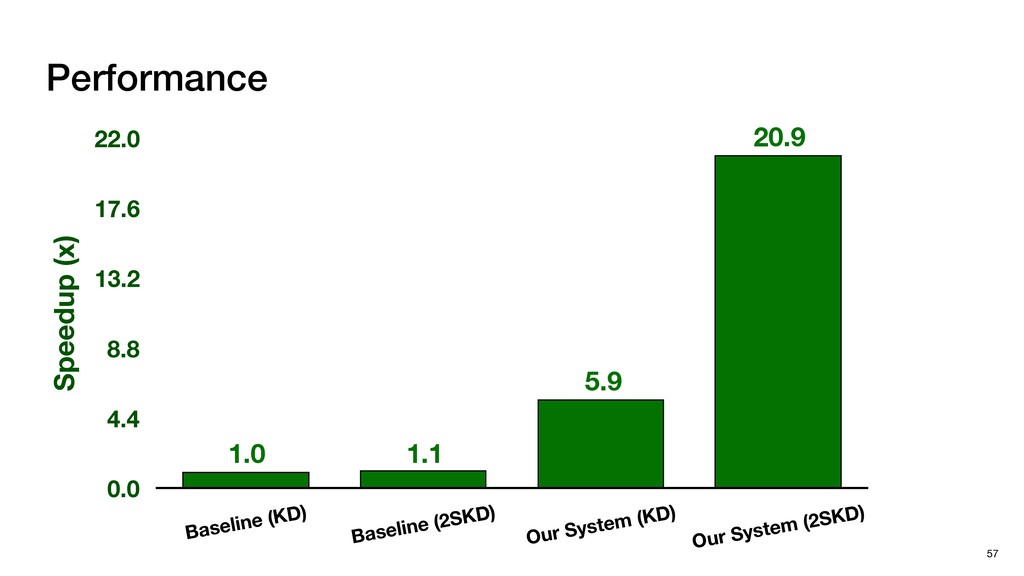
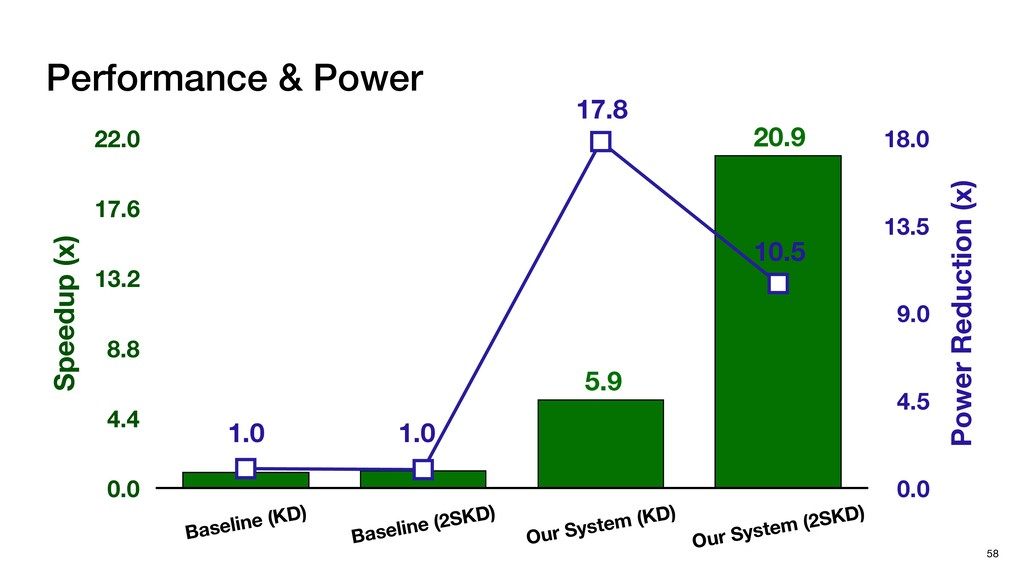
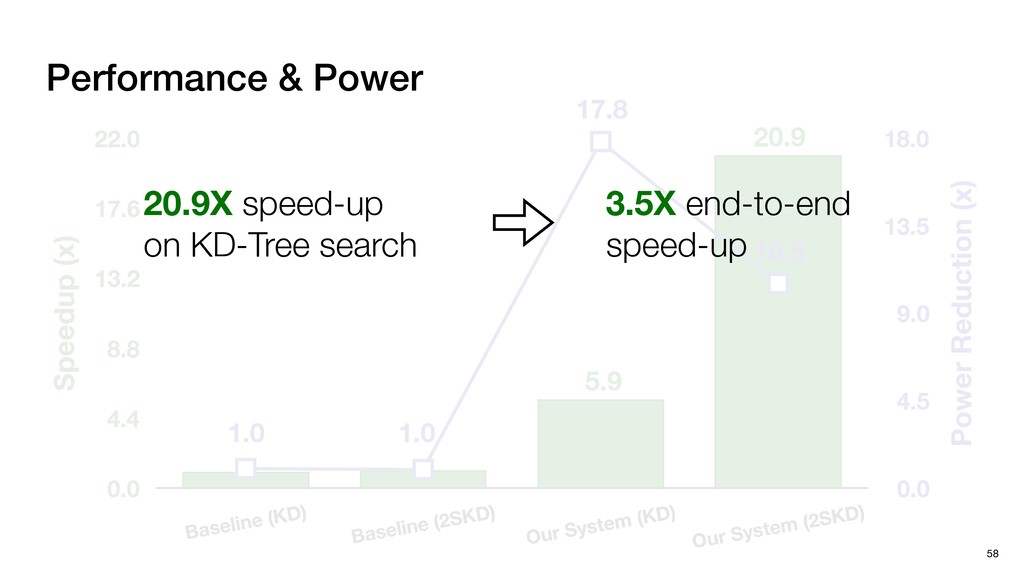
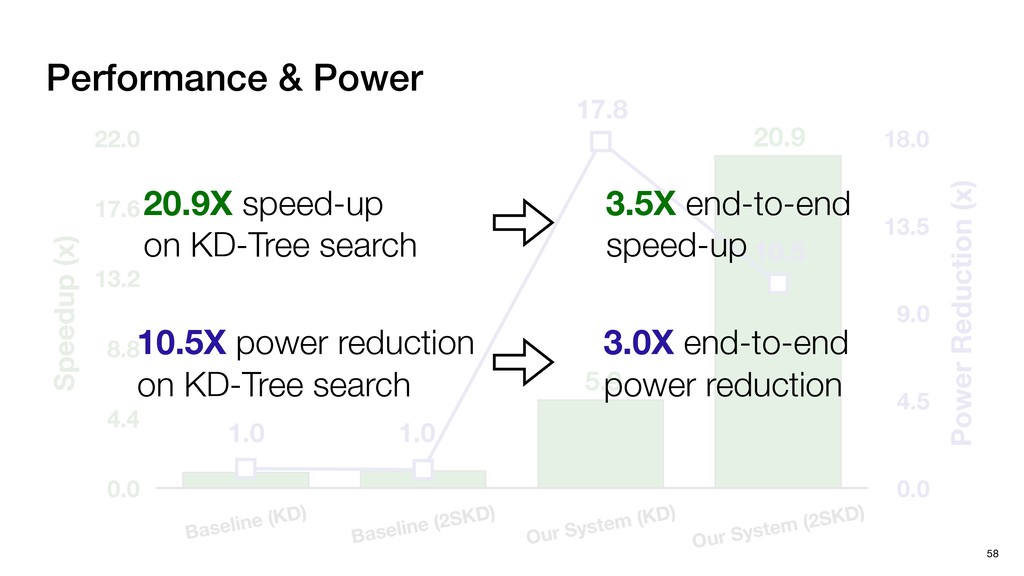
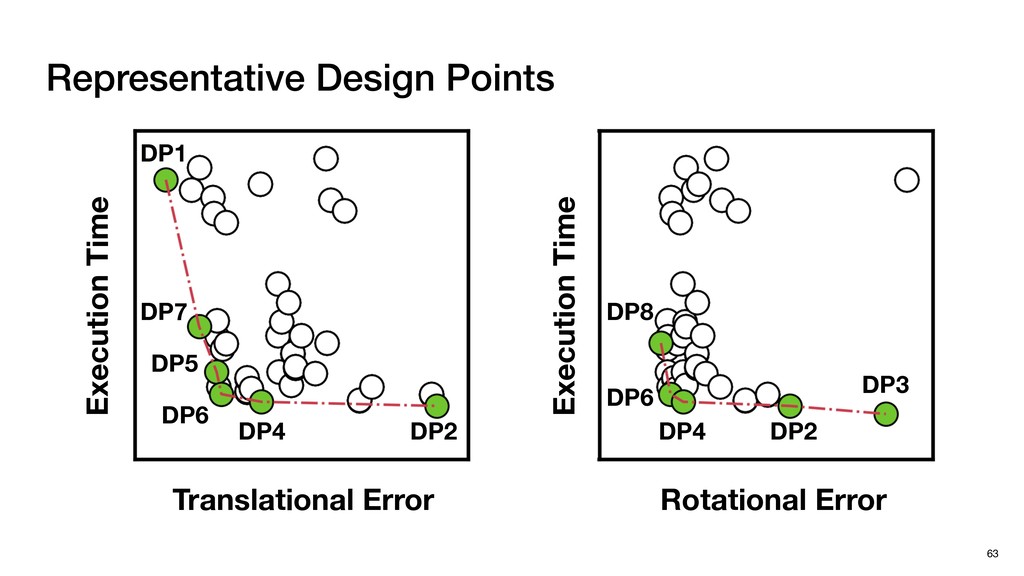
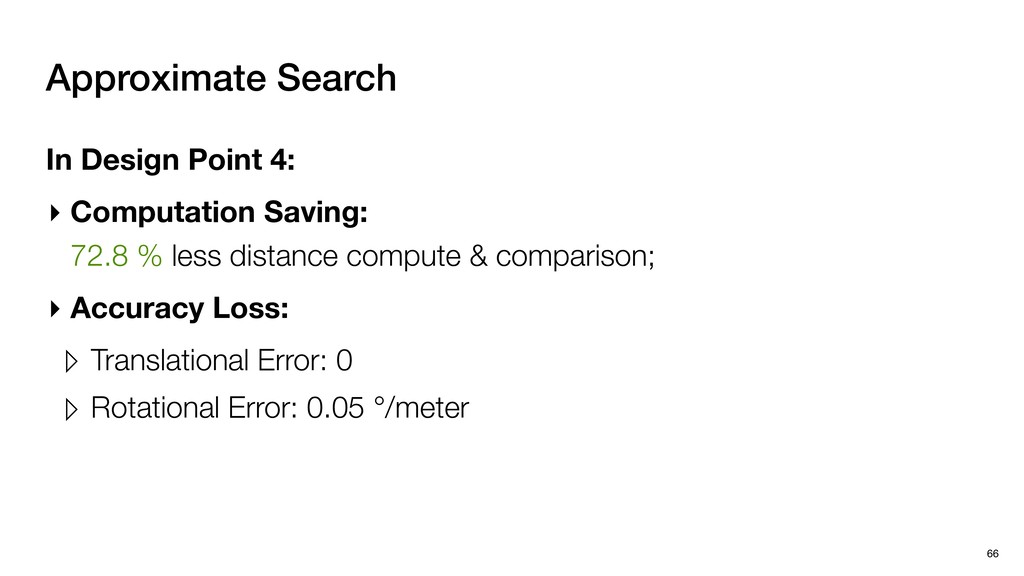
HW optimizations No SW Optimization No HW Optimization + SW Optimization No HW Optimization No SW Optimization + HW Optimization Four systems for Comparison Baseline (KD) Baseline (2SKD) Tigris (KD)
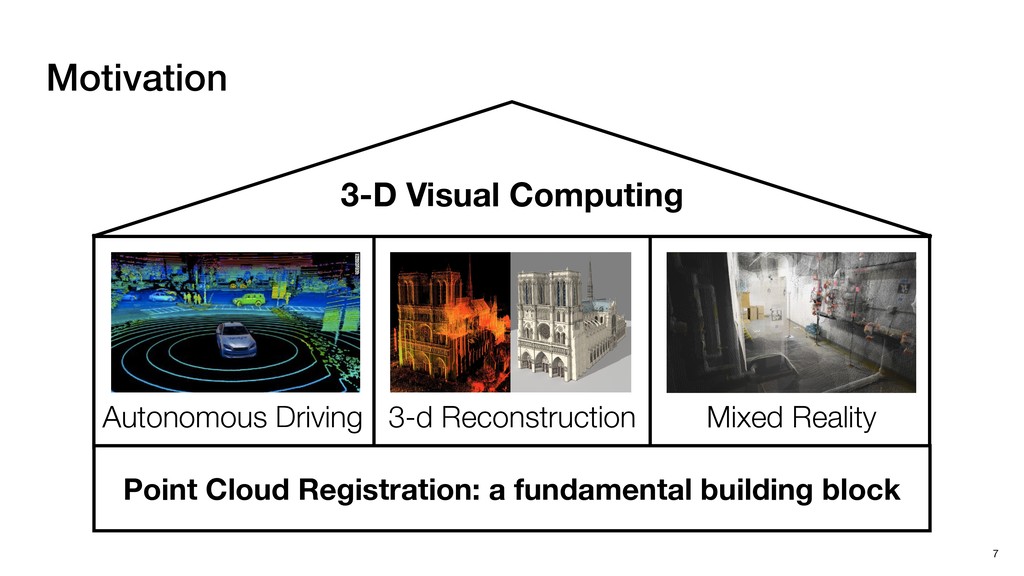
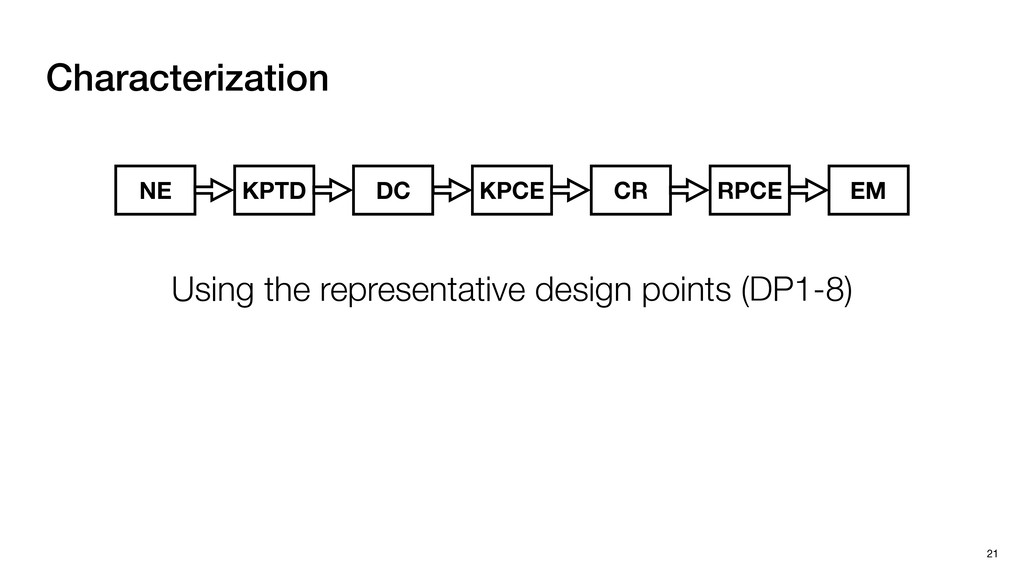
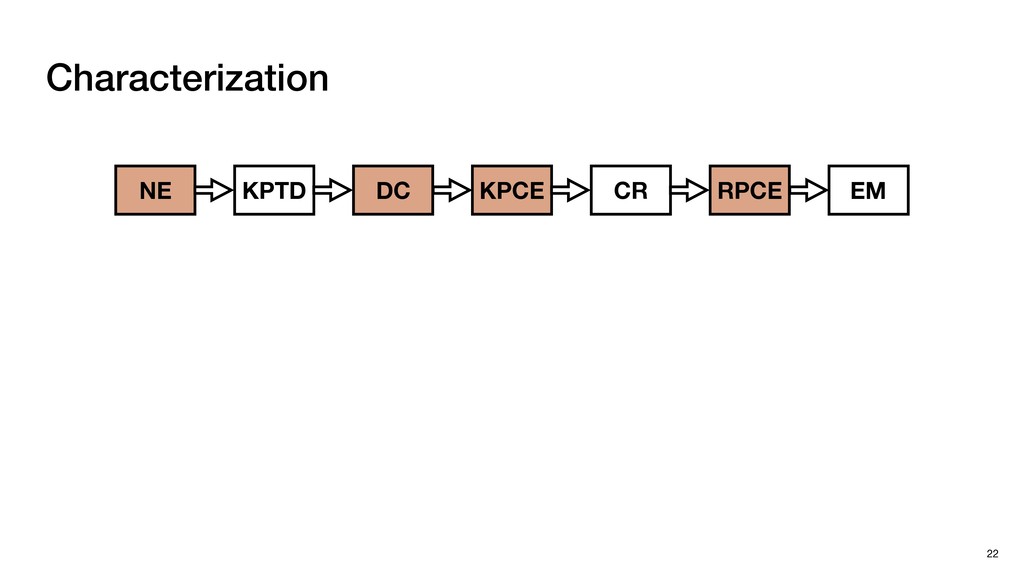
block in emerging domains such as Autonomous Driving and Mixed Reality ‣ Our Tigris System ▹ An early step towards efficient Point Cloud Registration ‣ Key Insight ▹ Co-designing Software and Hardware to boost efficiency
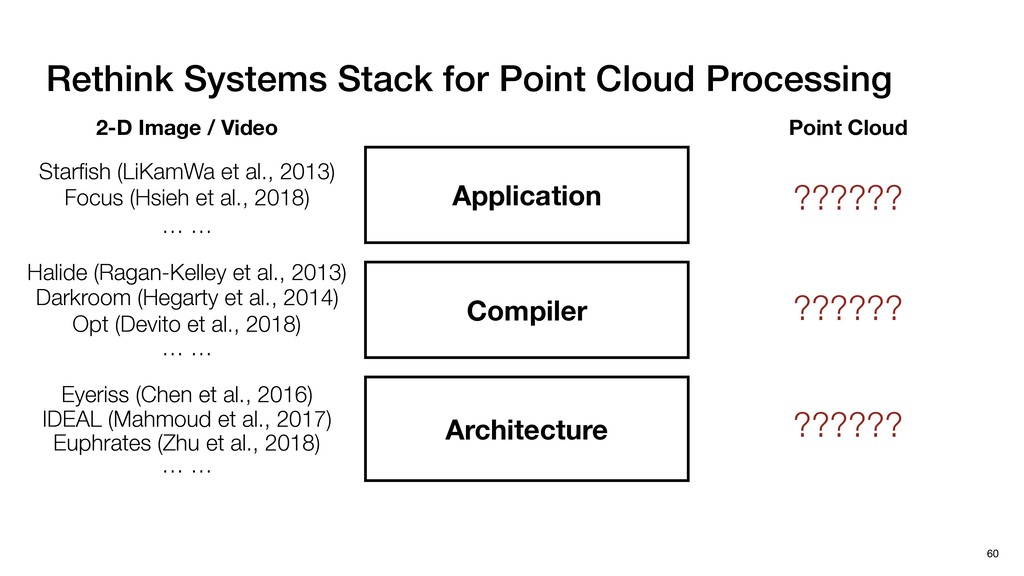
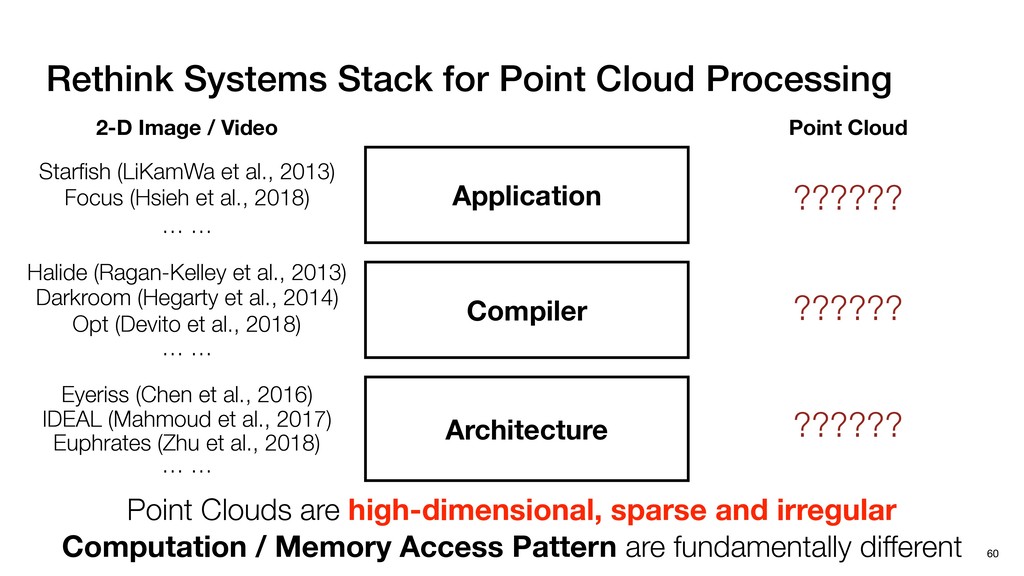
/ Video Application Compiler Architecture Point Clouds are high-dimensional, sparse and irregular Computation / Memory Access Pattern are fundamentally different Point Cloud Halide (Ragan-Kelley et al., 2013) Darkroom (Hegarty et al., 2014) Opt (Devito et al., 2018) … … Starfish (LiKamWa et al., 2013) Focus (Hsieh et al., 2018) … … ?????? ?????? IDEAL (Mahmoud et al., 2017) Eyeriss (Chen et al., 2016) … … Euphrates (Zhu et al., 2018) ??????
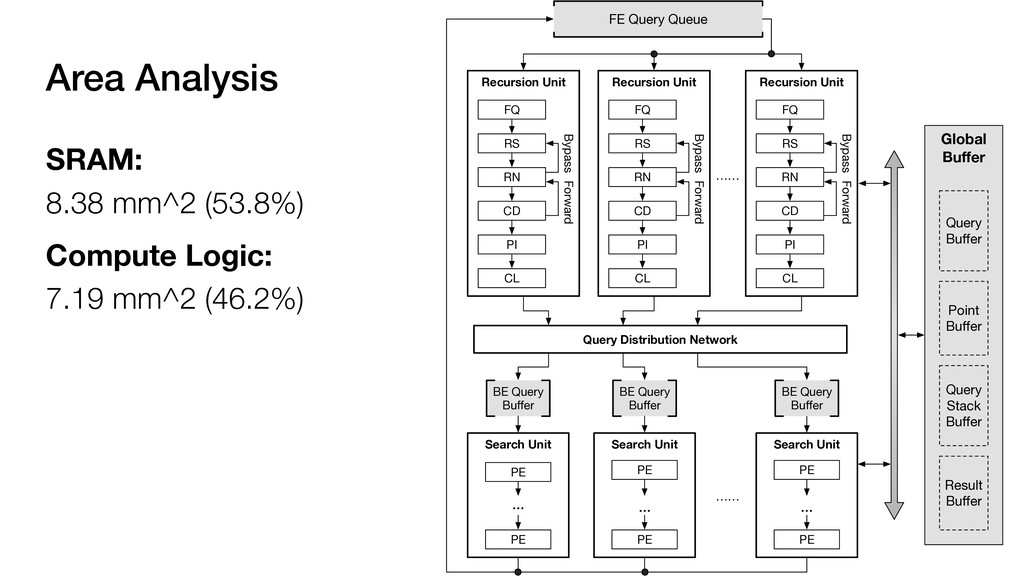
7.19 mm^2 (46.2%) Global Buffer Search Unit …… BE Query Buffer PE … PE Search Unit PE … PE Search Unit PE … PE BE Query Buffer BE Query Buffer Recursion Unit FQ RS RN CD PI CL Bypass Forward Query Distribution Network Recursion Unit FQ RS RN CD PI CL Bypass Forward Recursion Unit FQ RS RN CD PI CL Bypass Forward …… FE Query Queue Query Buffer Point Buffer Query Stack Buffer Result Buffer
Buffer PE … PE Search Unit PE … PE Search Unit PE … PE BE Query Buffer BE Query Buffer Recursion Unit FQ RS RN CD PI CL Bypass Forward Query Distribution Network Recursion Unit FQ RS RN CD PI CL Bypass Forward Recursion Unit FQ RS RN CD PI CL Bypass Forward …… FE Query Queue Query Buffer Point Buffer Query Stack Buffer Result Buffer
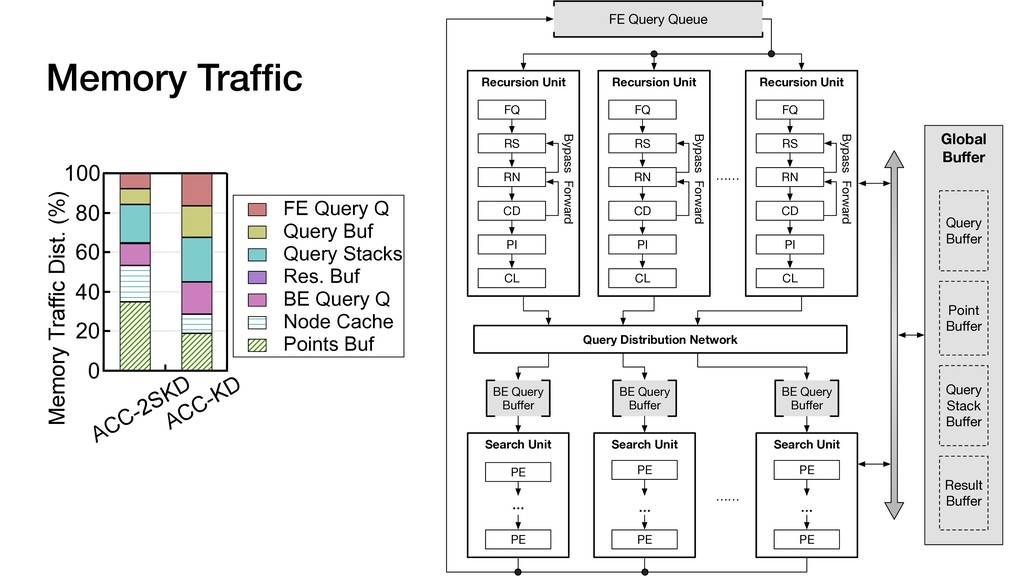
Traffic Dist. (%) ACC-2SKD ACC-KD FE Query Q Query Buf Query Stacks Res. Buf BE Query Q Node Cache Points Buf Global Buffer Search Unit …… BE Query Buffer PE … PE Search Unit PE … PE Search Unit PE … PE BE Query Buffer BE Query Buffer Recursion Unit FQ RS RN CD PI CL Bypass Forward Query Distribution Network Recursion Unit FQ RS RN CD PI CL Bypass Forward Recursion Unit FQ RS RN CD PI CL Bypass Forward …… FE Query Queue Query Buffer Point Buffer Query Stack Buffer Result Buffer
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}