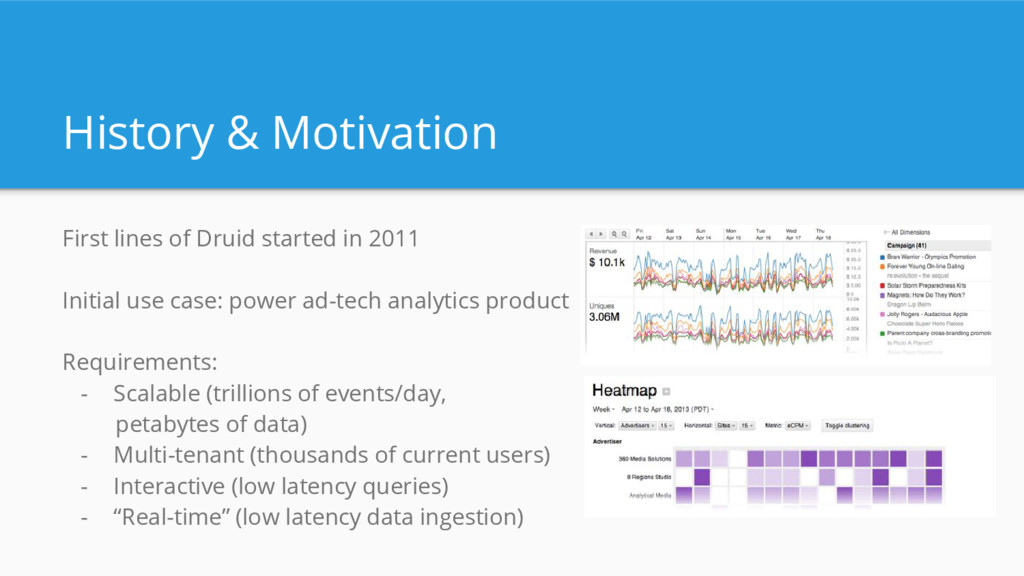
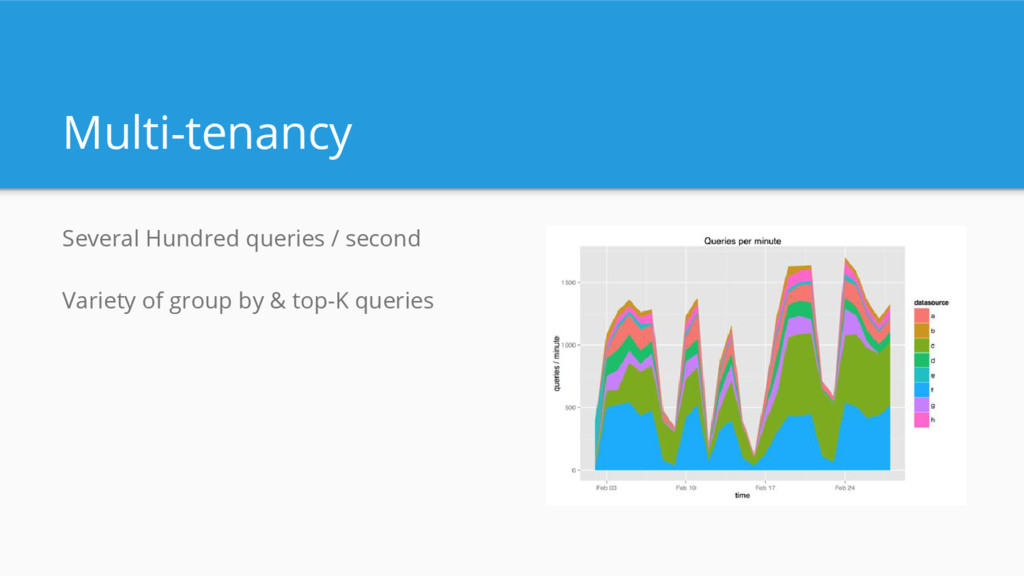
Initial use case: power ad-tech analytics product Requirements: - Scalable (trillions of events/day, petabytes of data) - Multi-tenant (thousands of current users) - Interactive (low latency queries) - “Real-time” (low latency data ingestion)
- GPL license initially - Part-time development until early 2014 Community growth - Apache v2 licensed in early 2015 - 150+ contributors from 100+ organizations In production at many different companies across many verticals - Ad-tech, network traffic, security, finance, gaming, operations, activity streams, etc.
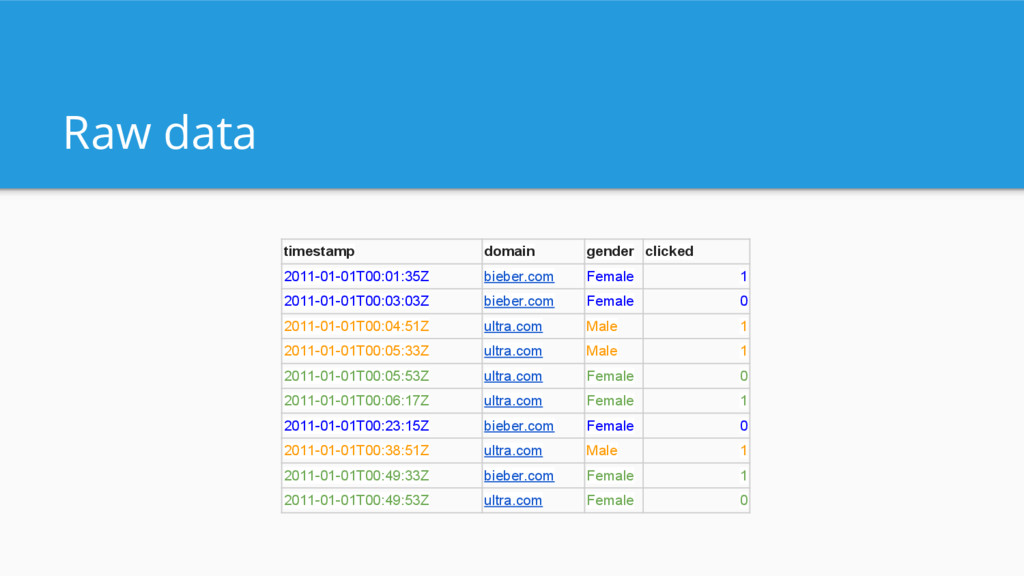
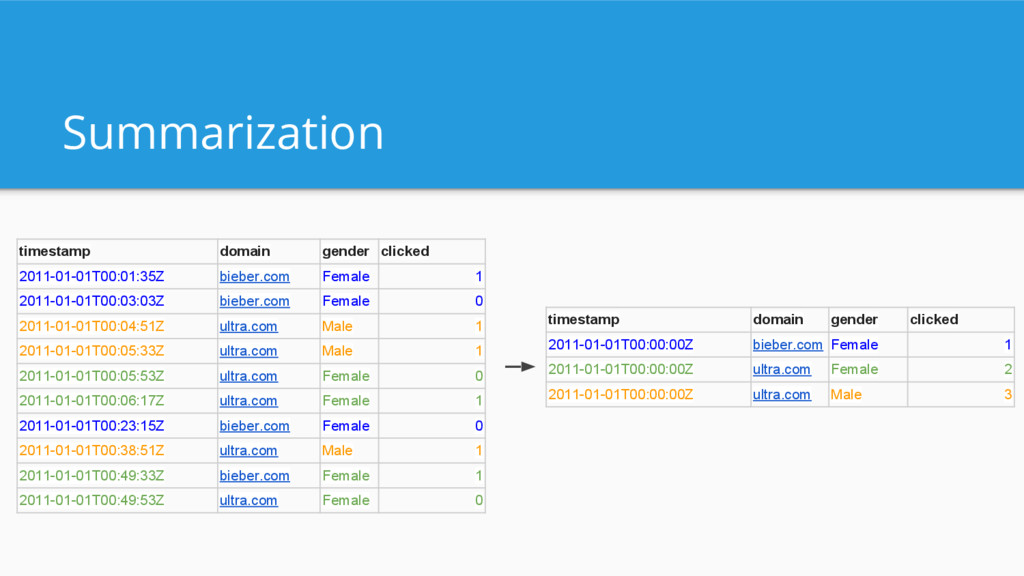
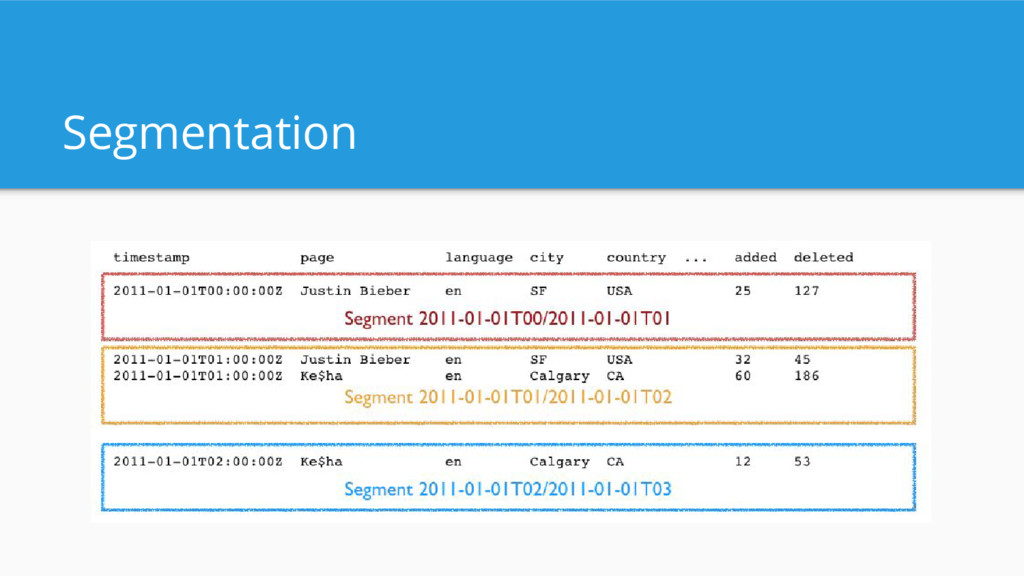
Business intelligence/OLAP queries - “How much revenue did product X generate last quarter in SF”? - “How many of my users that visited last week returned this week?” - Not dumping entire data set - Not examining single events - Filtering, grouping, and aggregating data - Result set < input set (aggregations)
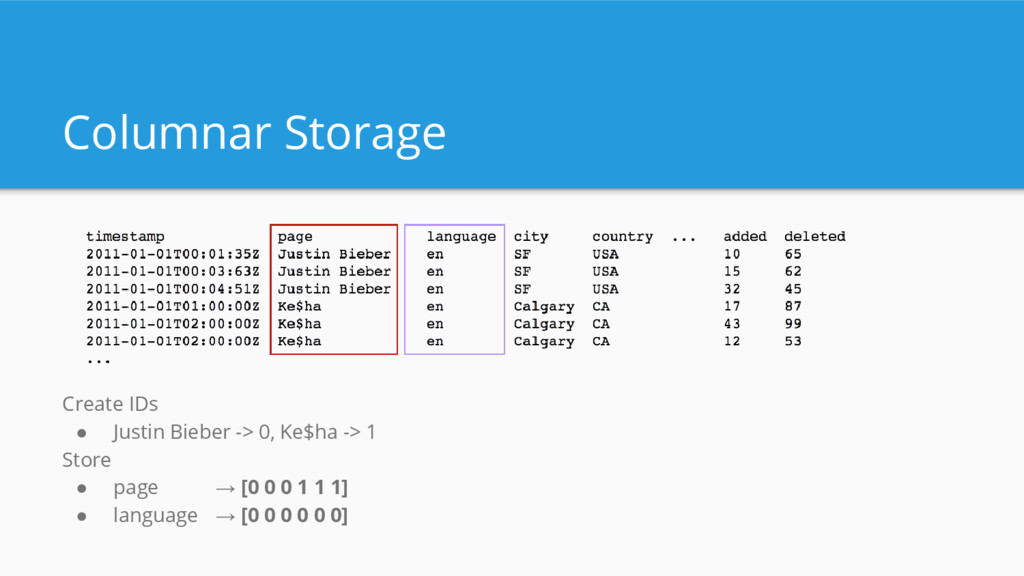
Different compression algorithms for different columns - Encoding for string columns - Compression for measure columns Different indexes for different columns
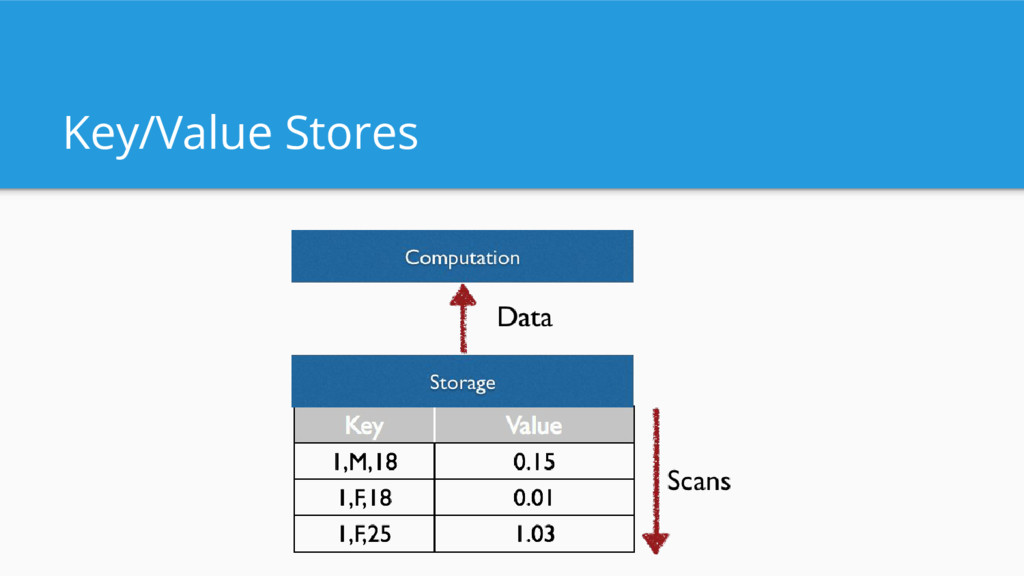
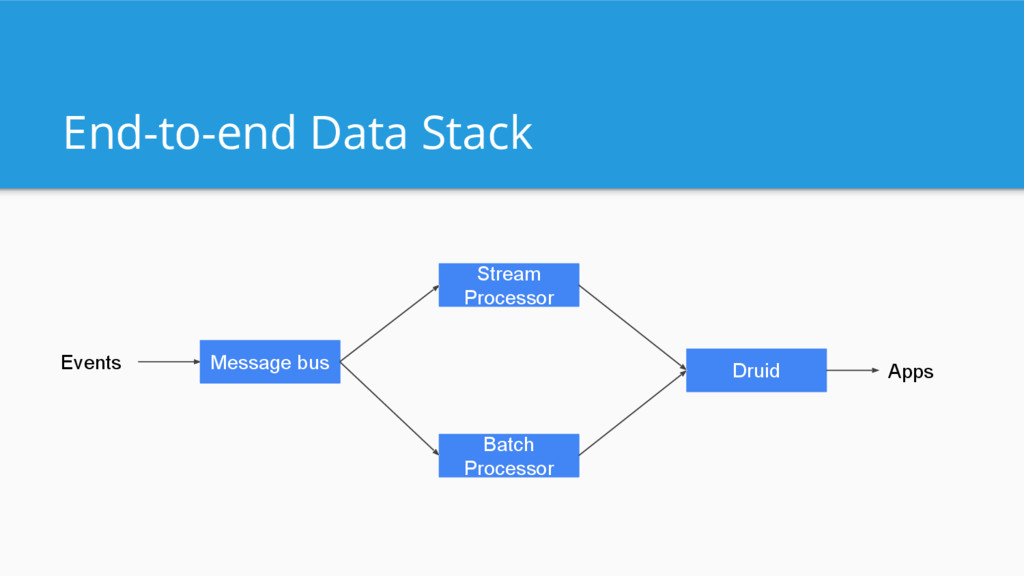
queries Supports lots of concurrent reads Streaming data ingestion Supports extremely fast filters Ideal for powering user-facing analytic applications
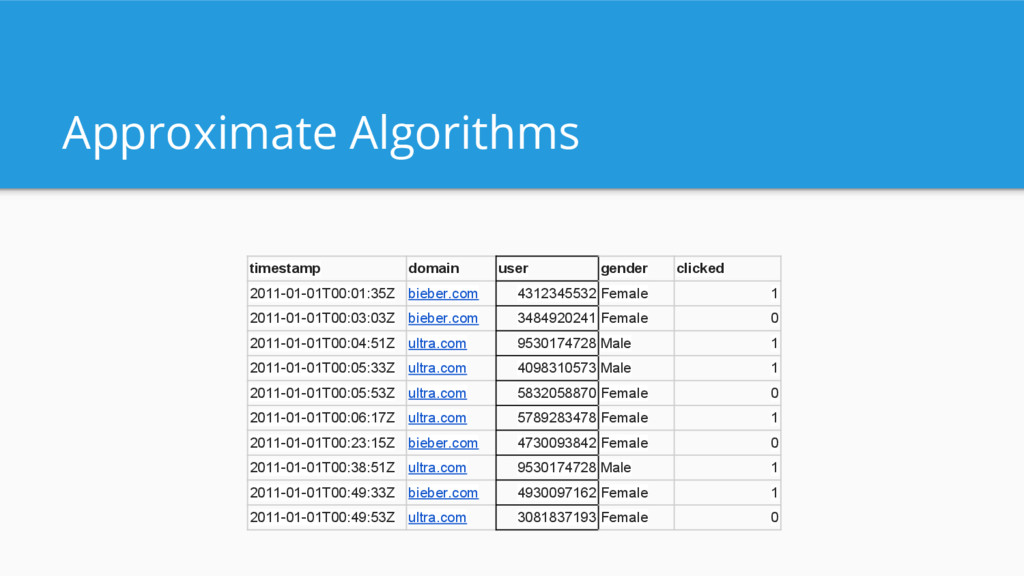
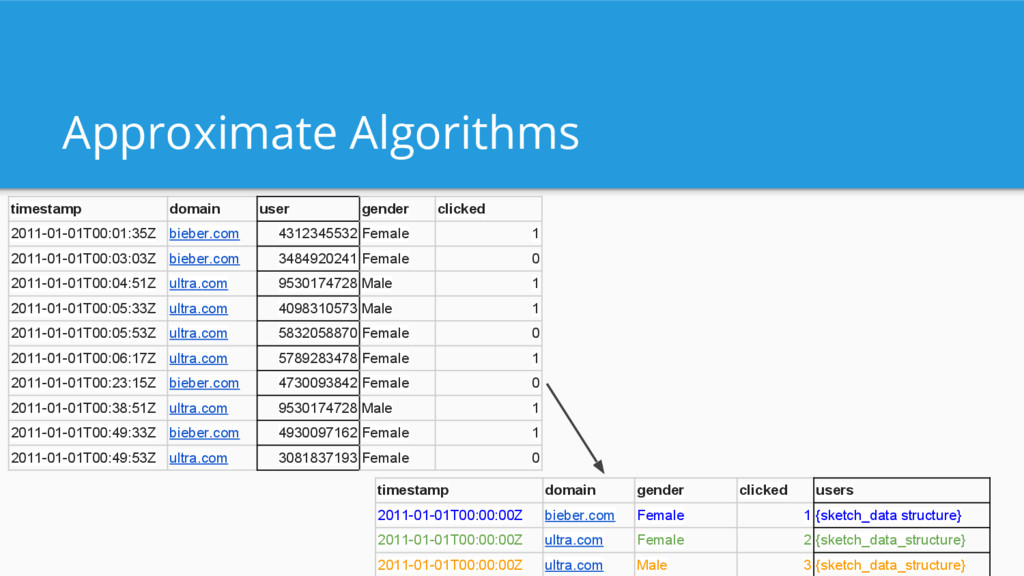
components Often used for approximate algorithms - Count distinct (Hyperloglog) - Approximate Histograms - Funnel/behavioral analysis (theta sketches) Approximate algorithms are very powerful for fast queries
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Columnar Storage Justin Bieber → [0, 1, 2] → [111000]](https://files.speakerdeck.com/presentations/673a0448e272418f81e4a68f16062490/slide_24.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}