Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
データベースと応用システム:データの検索機構
Search
自然言語処理研究室
June 13, 2014
Education
3.1k
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
データベースと応用システム:データの検索機構
自然言語処理研究室
June 13, 2014
More Decks by 自然言語処理研究室
See All by 自然言語処理研究室
データサイエンス14_システム.pdf
jnlp
0
420
データサイエンス13_解析.pdf
jnlp
0
540
データサイエンス12_分類.pdf
jnlp
0
380
データサイエンス11_前処理.pdf
jnlp
0
500
Recurrent neural network based language model
jnlp
0
180
自然言語処理研究室 研究概要(2012年)
jnlp
0
160
自然言語処理研究室 研究概要(2013年)
jnlp
0
130
自然言語処理研究室 研究概要(2014年)
jnlp
0
150
自然言語処理研究室 研究概要(2015年)
jnlp
0
230
Other Decks in Education
See All in Education
Visionary Initiative: Future Intelligence — Laying the foundations for the future of science, intelligence, and society | Science Tokyo
sciencetokyo
PRO
0
170
면접관 눈에 띄는 데이터 분석 포트폴리오 만드는 법 | 2026년 5월 세미나
datarian
0
950
0526
cbtlibrary
0
200
2026年度春学期 統計学 第9回 確からしさを記述する ー 確率 (2026. 5. 28)
akiraasano
PRO
0
160
「答えを出す」より「わかる」をつくる
kzkmaeda
1
250
Visionary Initiative: Materials-Positive Society 「モノの進化をポジティブな社会の原動力に」|Science Tokyo(東京科学大学)
sciencetokyo
PRO
0
800
!コスパよくインターンに受かる方法!
ruribou
1
310
新しいJavaを学んで・使っていこう! / osd26do
gishi_yama
0
190
遊ぶかね欲しさの犯行(ルビ:労働)です
shirayanagiryuji
0
200
Where Data Meets Storytelling
georgesinnott
0
140
Πλουτοκρατία: Η Τυραννία του Μαμμωνά και η Μεταανθρώπινη Δουλεία
amethyst1
0
280
sepm-training-sample
levii
0
100
Featured
See All Featured
Heart Work Chapter 1 - Part 1
lfama
PRO
8
36k
Skip the Path - Find Your Career Trail
mkilby
1
170
Winning Ecommerce Organic Search in an AI Era - #searchnstuff2025
aleyda
1
2.1k
Reality Check: Gamification 10 Years Later
codingconduct
0
2.2k
Hiding What from Whom? A Critical Review of the History of Programming languages for Music
tomoyanonymous
3
1k
Designing Experiences People Love
moore
143
24k
Why You Should Never Use an ORM
jnunemaker
PRO
61
9.9k
Distributed Sagas: A Protocol for Coordinating Microservices
caitiem20
333
23k
The MySQL Ecosystem @ GitHub 2015
samlambert
251
13k
Optimising Largest Contentful Paint
csswizardry
37
3.8k
Getting science done with accelerated Python computing platforms
jacobtomlinson
2
360
Prompt Engineering for Job Search
mfonobong
0
380
Transcript
(c)長岡技術科学大学 電気系 1 データベースと応用システム データの検索機構 山本和英 長岡技術科学大学 電気系
(c)長岡技術科学大学 電気系 2 ディスクアクセス
(c)長岡技術科学大学 電気系 3 ハードディスク(HDD) • セクタ:記憶単位 • トラック:セクタの集まり • シリンダ:トラックの集まり
• 記憶容量= シリンダ数 x 1シリンダのトラック数 x 1トラックのセクタ数
(c)長岡技術科学大学 電気系 4 アクセス時間 • シーク時間 (位置決め時間) – 磁気ヘッドを目的のトラック上まで移動させる時間 •
サーチ時間 (回転待ち時間) – (データにたどりつくための)ディスクの回転時間 – (平均を取って)1/2回転する時間を使う • データ転送時間 – データの1回転時間 = 1トラックのデータ転送時間
(c)長岡技術科学大学 電気系 5 アクセス時間の計算例 • 平均位置決め時間: 20ms • 記憶容量: 20kB/トラック
• 回転数: 3000 rpm – 1回転に要する時間: 60000ms/3000回転 = 20ms/回転 – 20msで20kBアクセスできる ⇒ 1msで1kB • 5kBのデータのアクセス時間は、 20ms (シーク時間) + 10ms (サーチ時間=0.5回転する時間) + 5ms (5kBのデータ転送時間) = 35ms
(c)長岡技術科学大学 電気系 6 インデックス(索引)
(c)長岡技術科学大学 電気系 7 インデックス • データを効率的(=高速)に検索するための仕組み • 一般にインデックスがあったほうが検索効率は向 上するが、必ずそうなるとは限らない(例:データ量 が少ない時)
• データを更新するとインデックスも更新する必要が ある
(c)長岡技術科学大学 電気系 8 インデックスの効果 データ数が同じでも、データの内容によってインデッ クスの効果は異なる: • データ値が多様である – 2値(0と1)しかないようなデータでは、いくらインデッ
クスを作成しても効果は低い • データ値による頻度の分布が小さい – 種類数が同じでもデータ値に偏りが大きいと平均検索 効率は悪くなる
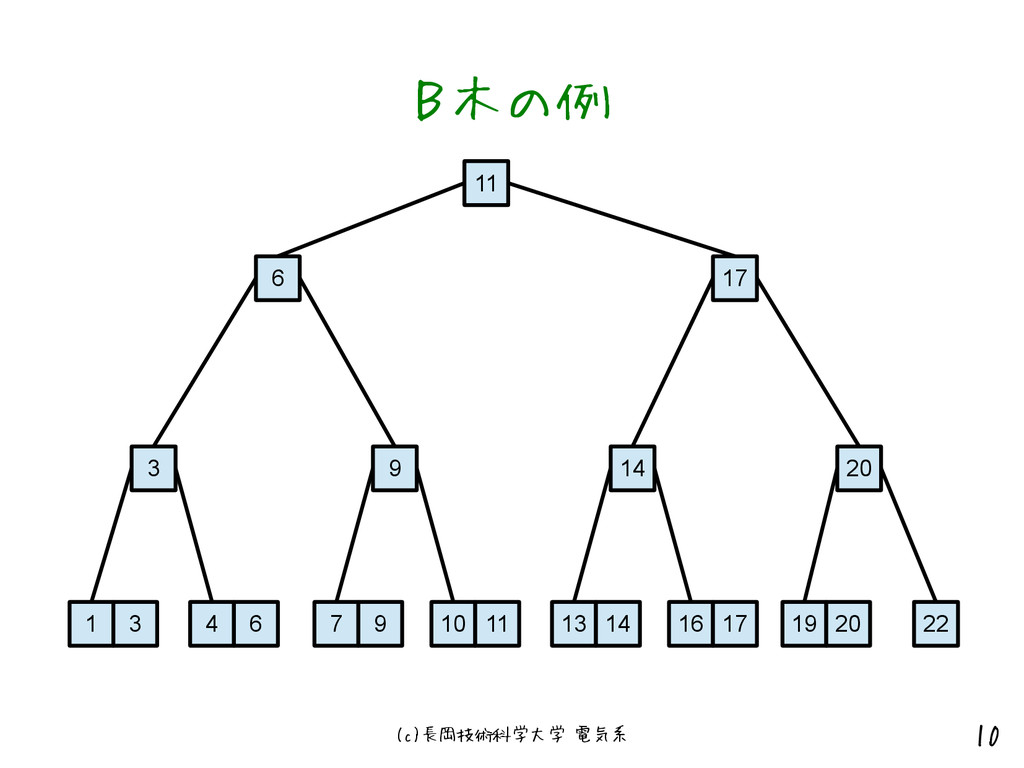
(c)長岡技術科学大学 電気系 9 B木インデックス • 多分岐の木構造となっているインデックス • バランス木 – リーフノード(最下位ノード)の深さが同じ
• 検索時間のばらつきが低い • データ数が2倍になっても検索時間(=探索する階 層)は1増えるだけ
(c)長岡技術科学大学 電気系 10 B木の例 11 6 17 3 9 14
20 22 1 3 4 6 7 9 10 11 13 14 16 17 19 20
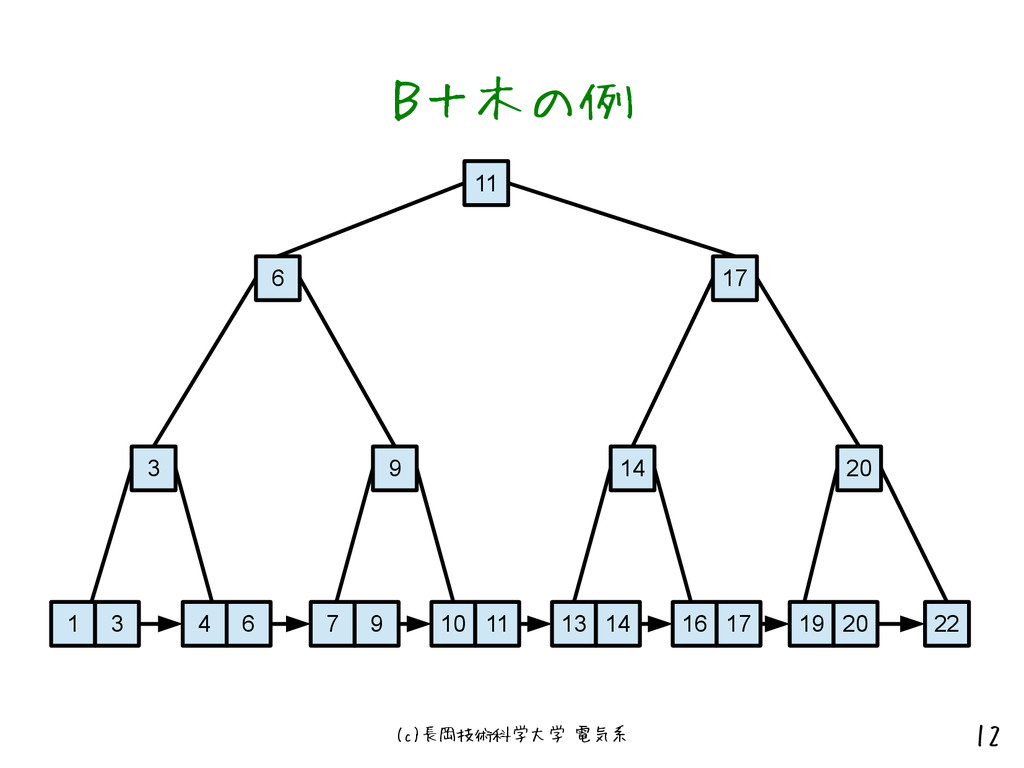
(c)長岡技術科学大学 電気系 11 B+木インデックス • B木インデックスは順次アクセスの際に効率が悪い • よって、B木インデックスの条件を満たしたまま、さ らに各リーフノードをポインタで順に連結した –
この時のリーフノードをシーケンスセットと呼ぶ • これによってB木の特徴を生かしたまま、順次アクセ スの非効率を解消
(c)長岡技術科学大学 電気系 12 B+木の例 11 6 17 3 9 14
20 22 1 3 4 6 7 9 10 11 13 14 16 17 19 20
(c)長岡技術科学大学 電気系 13 ハッシュインデックス • キー値にある関数を適用して、その値によって行の 格納位置を求めるインデックス • ハッシュ関数の例:「ある素数で割った余り」 •
検索効率がデータベースの規模に左右されない • 衝突(コンフリクト)が起こると同義語(シノニム)が 発生し、これが多いとアクセス効率が低下する • 範囲検索(例:不等号条件)や曖昧検索(部分文 字列条件)などには使えない
(c)長岡技術科学大学 電気系 14 ビットマップインデックス • 取り得る値の種類が少ないフィールド(例: ON/OFF、男・女)に対して有効 • リーフページ以外はB+木インデックスと同じ •
各キー値に対して、複数の格納位置(ROWID)では なく、各ビットが表中の各行に対応するビット列を 持つ • ビット演算が容易にできるので、AND/OR/NOTだけ で行う検索には効率的
(c)長岡技術科学大学 電気系 15 使われないインデックス こういう検索をするとインデックスがあっても使われな い: DISTINCTやGROUP BYを使った検索 WHERE 商品名
LIKE '%パソコン' WHERE 売上 * 1.05 = 5250 WHERE NOT 学籍番号 = 999 WHERE 従業員 IS NULL WHERE コード = 'HT%' OR 商品名 LIKE '%パソコン ' – AND検索はインデックスを使用する
(c)長岡技術科学大学 電気系 16 チューニングと保守管理
(c)長岡技術科学大学 電気系 17 チューニング • データベースへのアクセス性能を向上させる改良の こと。 • データ構造、アプリケーション(SQLやインデック ス)、システムリソース(メモリやディスク)の順に検
討する • データ構造のチューニングは性能改善の可能性が 高いが影響も大きい。
(c)長岡技術科学大学 電気系 18 チューニング:データモデル • テーブルを非正規化する – 正規化は冗長性を除去して更新時異常を防止できる が、検索時にデータの結合処理が必要になる •
サマリテーブルを作成する – 集合関数(GROUP BY)などの計算を、その都度計算す るのでなくあらかじめ計算して結果をテーブルにしてお く。 • 分散データベースを使用する – スケーラビリティや信頼性を高め、アクセス性能を向上 させる
(c)長岡技術科学大学 電気系 19 チューニング:SQL インデックスを利用する • 効果大:主キー、外部キー、WHEREやORDER BYで よく使われる列 •
効果小:ON/OFFや男・女など、種類数が少ない 時 • 更新が頻繁に行われるテーブルは、インデックスも 頻繁に更新する必要があるため、注意が必要
(c)長岡技術科学大学 電気系 20 チューニング:ストアドプロシージャの利用 よく使う一連の処理(プロシージャ)をまとめてサー バーに保存(ストア)しておくこと • メリット: – 手間いらず
– ネットワーク負荷が軽減する – 処理時間も軽減する(コンパイルしてあるので) • 注意点: – 1回目に読み込み時間がかかる
(c)長岡技術科学大学 電気系 21 チューニング:ディスクアクセス • クラスタリング – 一緒に用いることの多いデータの集まり(=クラスタ)を、事 前に同じブロックに格納すること •
データベースの再編成 – 追加、削除等を繰り返して断片的になったデータベースの データをきれいに「置き直す」こと – ディスクアクセスやメモリの効率が改善 • 一時作業領域を増やす • ディスク競合の回避 – データとインデックスのアクセス先を分離 – データとログのアクセス先も分離
(c)長岡技術科学大学 電気系 22 チューニング:トランザクション • ロックの粒度の検討 – 大きくロックする(例:テーブル)と、ロック待ちが増える – 小さくロックする(例:行)と、ロック待ちとロック解除が
頻繁になって負荷がかかる • よって、 – 頻繁にアクセスされるデータは小さくロック – 同時アクセスが少ないデータは大きくロック
(c)長岡技術科学大学 電気系 23 チューニング:メモリ バッファヒット率を改善させる • できるだけメモリ内でアクセスを完結させ、ディスク アクセスしないことが望ましい • 一般に、バッファヒット率が80%未満の場合はバッ
ファの拡張やメモリの増設が必要
(c)長岡技術科学大学 電気系 24 データベースの保守管理 • データベースを一定期間使用した後、利用状況の 変化に対応するために保守管理を行う • 再構成 –
テーブルに列やインデックスを追加 – データ構造を変更、など • 再編成 – 未使用断片領域を解消してデータを再配置 – 記憶効率やアクセス効率を改善 – データ構造は変更されない
(c)長岡技術科学大学 電気系 25 テーブルの結合
(c)長岡技術科学大学 電気系 26 テーブルの結合方法 • SQL文の処理は、選択、射影、結合の3種類 • このうち、結合が最も負荷がかかる • 3種類の結合方法
– 入れ子ループ(ネストループ)結合 – マージ結合 – ハッシュ結合 • 普通はハッシュ結合が効率的だが、条件によって は異なる
(c)長岡技術科学大学 電気系 27 ネストループ結合 • 要するに、2レコードを総当たりで比較する探索 • 処理コストはレコードの積に比例 • 一般に、
– インデックスのない小テーブルと – インデックスのある大テーブル を結合する場合に効果的
(c)長岡技術科学大学 電気系 28 マージ結合 • 要するに、両方のテーブルのフィールドをソートして おいて、順に走査する探索 • レコードの走査が1回で済むので効率的
(c)長岡技術科学大学 電気系 29 ハッシュ結合 • 一般には最も効率的 • テーブルBのハッシュテーブルを作る • テーブルAのレコードごとに、ハッシュテーブルを検
索
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}