- ▪ サブゴール開始時にユーザに対して3種類の質問が可能 ① 対象物体の位置:”Where is [object]?” ② 対象物体の形容:”What does [object] look like?” ③ 移動すべき方向:”Which direction should I turn to?” ▪ オラクル応答:シミュレータから取得したメタデータから自動生成 ① ”The [object] is to your [direction] in/on the [container].” ② “The [object] is [color] and made of [material].” ③ “You should turn [direction] / You don’t need to move.” ▪ 評価指標:Success Rate (SR),Path Weighted Success Rate (PWSR)
to the floorlamp, power on the floorlamp.” “Which direction should I turn to?” “You should turn right.” “What does the floorlamp look like?” “The floorlamp is gray.” t=142 t=147
▪ 例)Clean -> “put the object in the sink” + “turn on the faucet” + “turn off the faucet” ▪ 方針2:分割したサブゴールをマージして新たなタスクを作成 ▪ 指示文:主要なサブゴールのみを説明するように作成 ▪ 例)”go to the fridge” + “open the fridge” -> Move & Open 新たなタスク例 [Gao+, RA-L22]
{kind=link}
{kind=link}
{kind=link}
![問題設定 (1/2): DialFRED [Gao+, RA-L22] (Dialogue + ALFRED) - 4](https://files.speakerdeck.com/presentations/59dcbcd9b21e475891ab2a683189894f/slide_3.jpg){kind=link}
![問題設定 (2/2): DialFRED [Gao+, RA-L22] (Dialogue + ALFRED) - 5](https://files.speakerdeck.com/presentations/59dcbcd9b21e475891ab2a683189894f/slide_4.jpg){kind=link}
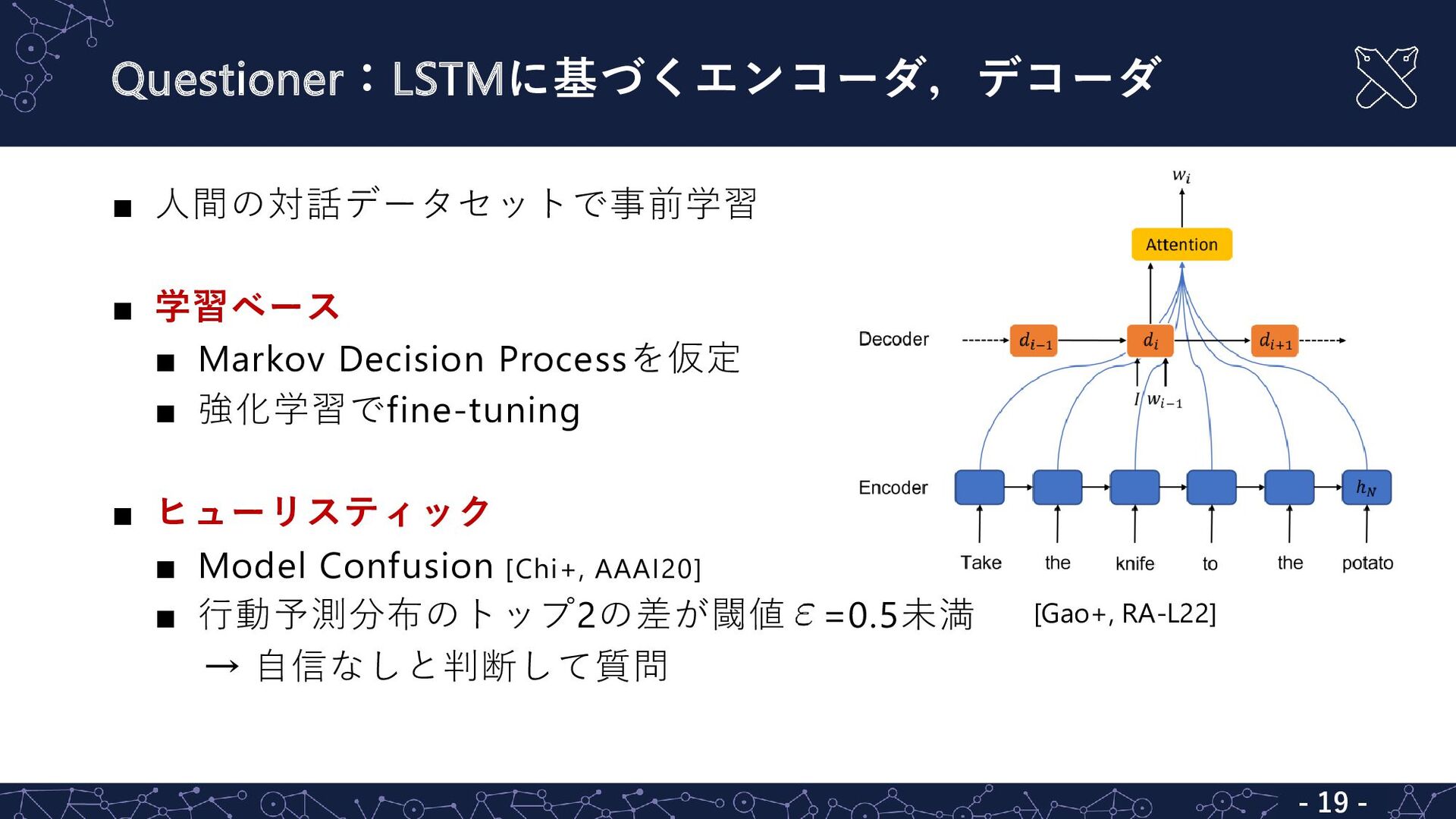
![提案手法:DialMAT - 6 - ▪ Questioner:サブゴール開始時にどの質問を行うか判定 ▪ LSTMベースの [Gao+, RA-L22]](https://files.speakerdeck.com/presentations/59dcbcd9b21e475891ab2a683189894f/slide_5.jpg){kind=link}
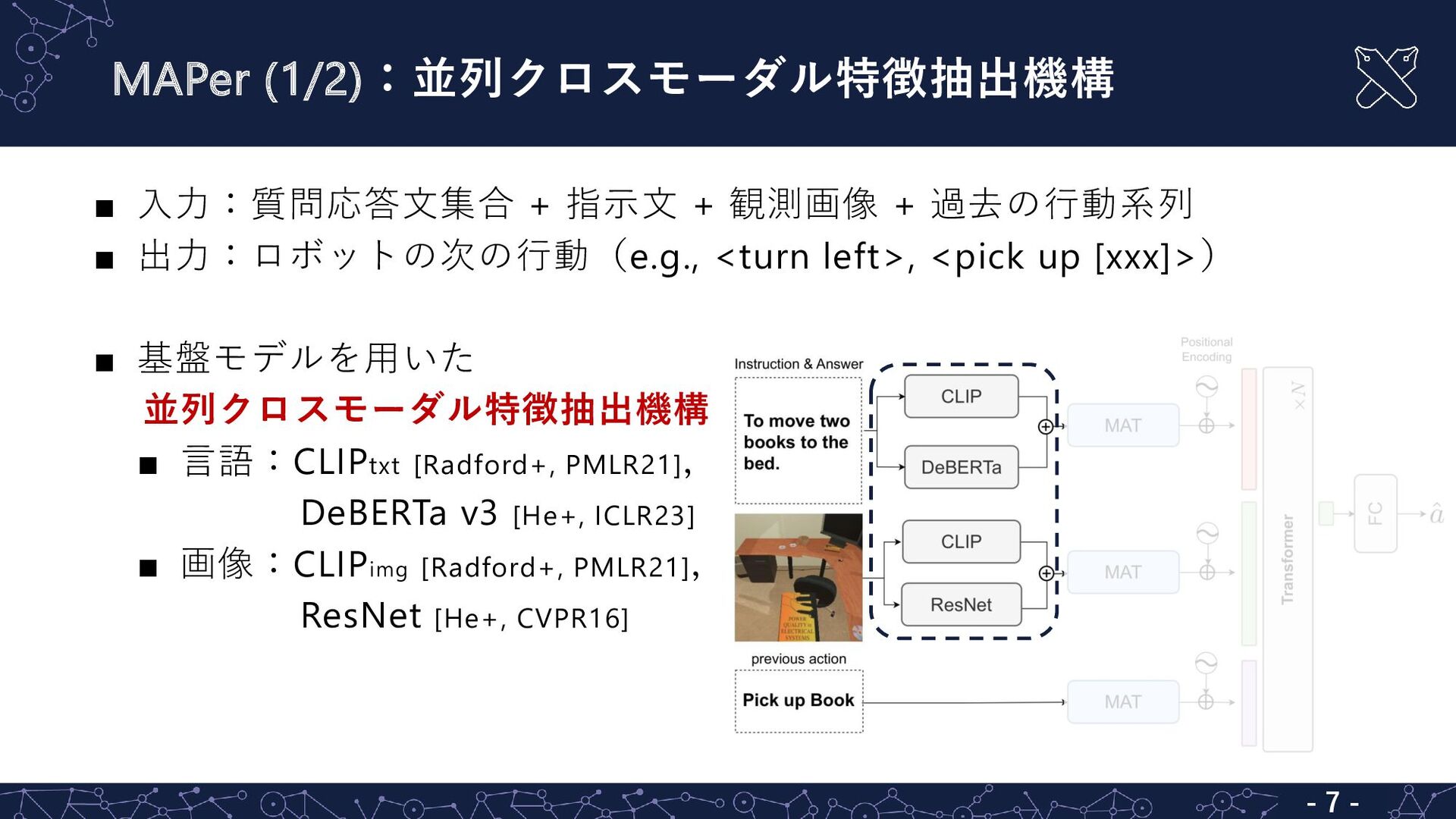{kind=link}
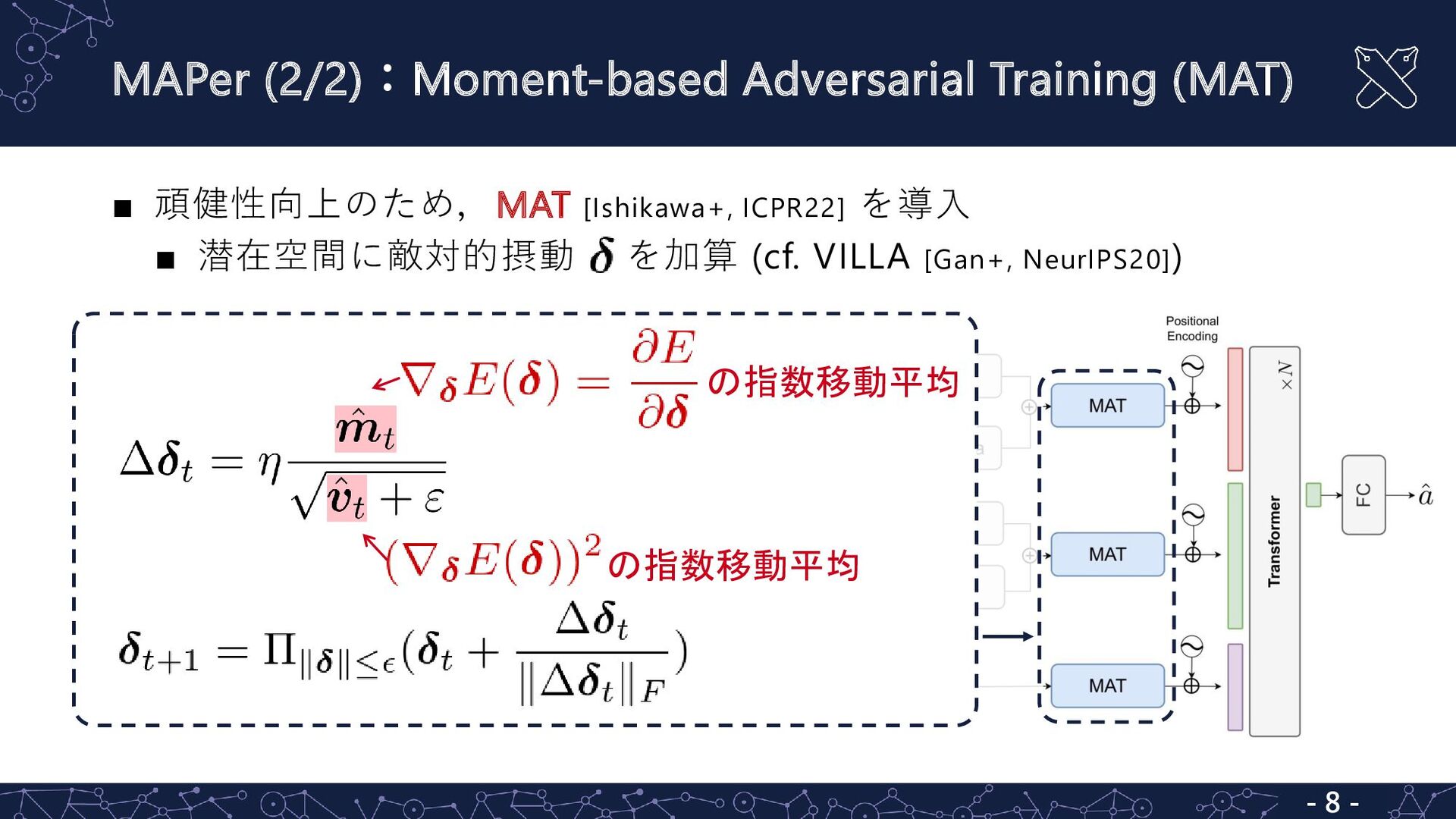{kind=link}
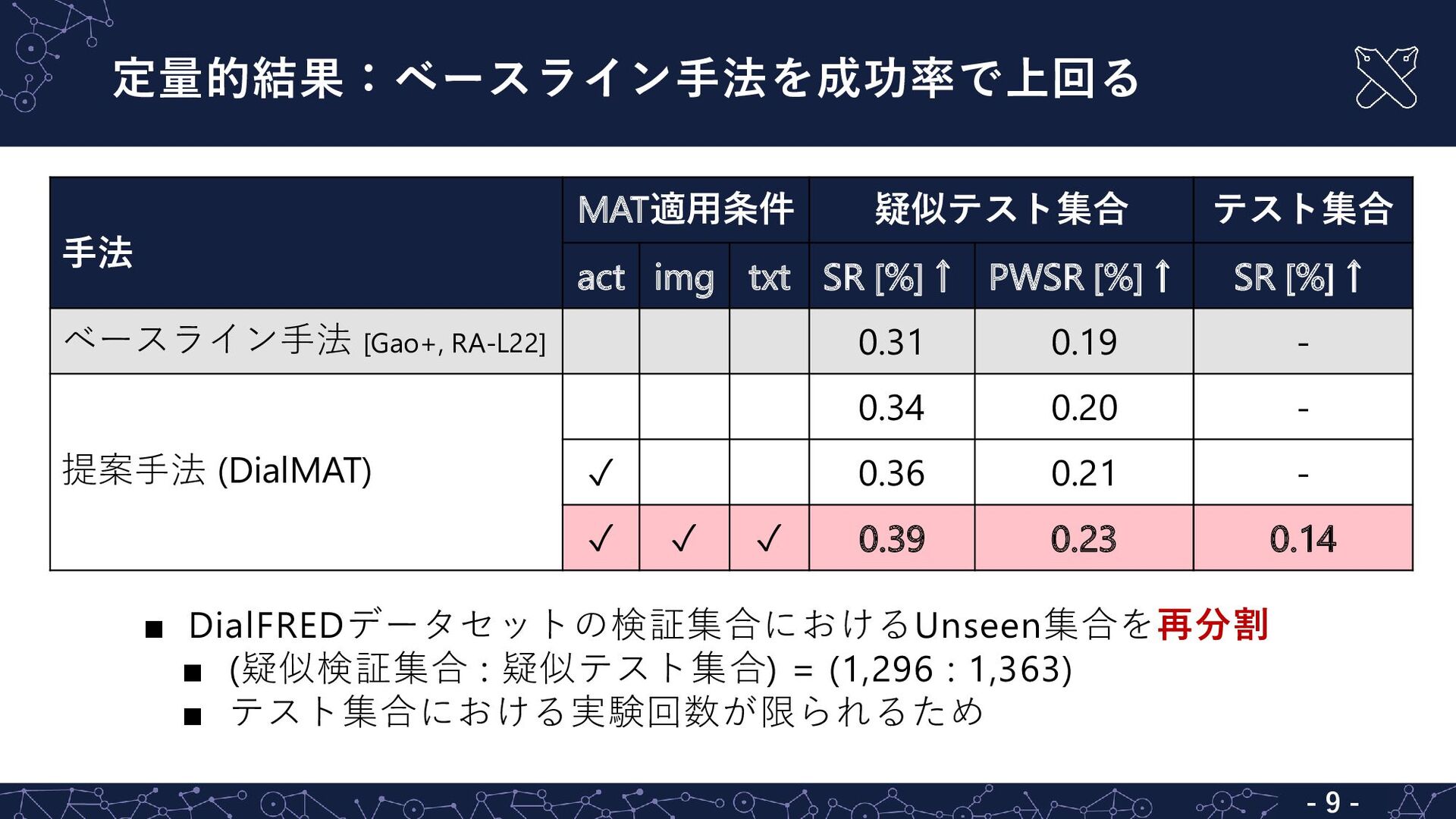{kind=link}
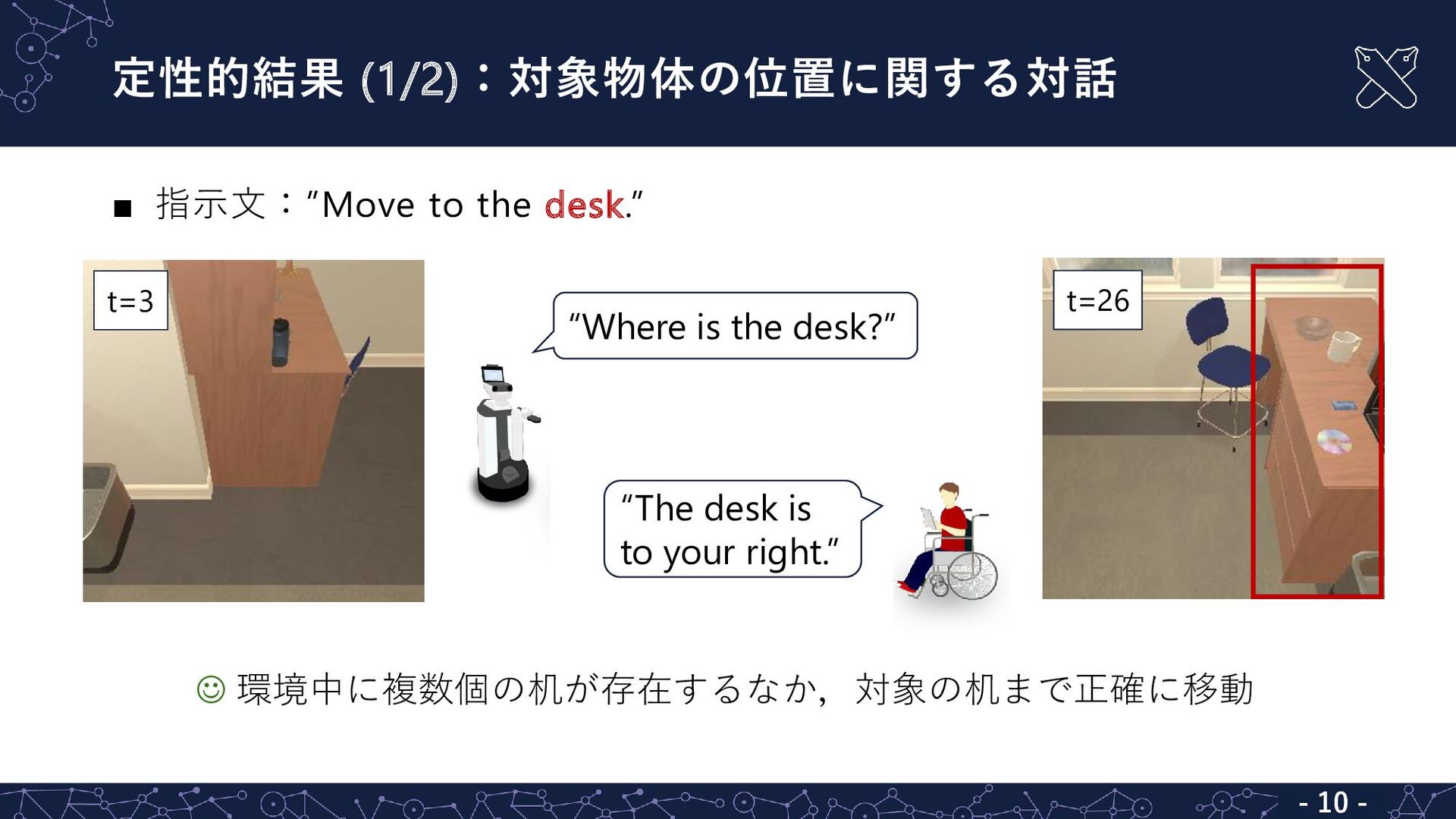{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![ALFREDタスクの種類を拡張 (2/2) :25種類のタスク - 16 - [Gao+, RA-L22]](https://files.speakerdeck.com/presentations/59dcbcd9b21e475891ab2a683189894f/slide_15.jpg){kind=link}
{kind=link}
![質問応答例:3種類の質問 - 18 - [Gao+, RA-L22]](https://files.speakerdeck.com/presentations/59dcbcd9b21e475891ab2a683189894f/slide_17.jpg){kind=link}
{kind=link}