Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
[RSJ23]Trimodal Cross-Attentional Transformer f...
Search
Sponsored
·
Ship Features Fearlessly
Turn features on and off without deploys. Used by thousands of Ruby developers.
→
Semantic Machine Intelligence Lab., Keio Univ.
PRO
September 09, 2023
Technology
1.2k
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
[RSJ23]Trimodal Cross-Attentional Transformer for Rearrangement Target Detection Using Visual Foundation Models
Semantic Machine Intelligence Lab., Keio Univ.
PRO
September 09, 2023
More Decks by Semantic Machine Intelligence Lab., Keio Univ.
See All by Semantic Machine Intelligence Lab., Keio Univ.
[Journal club] Predict Before You Explore: Predictive Planning with Specialized Memory for Embodied Question Answering
keio_smilab
PRO
0
81
[Journal club] PHyCLIP: 𝒍𝟏-Product of Hyperbolic Factors Unifies Hierarchy and Compositionality in Vision-Language Representation Learning
keio_smilab
PRO
0
86
[Journal club] ReMEmbR: Building and Reasoning Over Long-Horizon Spatio-Temporal Memory for Robot Navigation
keio_smilab
PRO
0
110
[Journal club] ReLaGS: Relational Language Gaussian Splatting
keio_smilab
PRO
0
120
[Journal club] Flow as the Cross-Domain Manipulation Interface
keio_smilab
PRO
0
98
Mobi-𝜋: Mobilizing Your Robot Learning Policy
keio_smilab
PRO
0
160
A Gentle Introduction to Transformers
keio_smilab
PRO
16
7k
FlowAR: Scale-wise Autoregressive Image Generation Meets Flow Matching
keio_smilab
PRO
0
60
[Journal club] VLA-Adapter: An Effective Paradigm for Tiny-Scale Vision-Language-Action Model
keio_smilab
PRO
1
150
Other Decks in Technology
See All in Technology
そのドキュメント、自動化しませんか?
yuksew
1
410
AI、CDK と協働する Full TypeScript アプリケーション開発 / Full TypeScript Application with AI and CDK
geekplus_tech
2
480
GoでCコンパイラを作った話
repunit
0
150
OpenTelemetryにおけるGoのゼロコード・コンパイル時計装について #fukuokago
quiver
0
200
AIツールを導入しても生産性はあがらない? カオナビが直面した 3つの壁と乗り越え方。/ Overcoming 3 Barriers to AI-Driven Productivity at kaonavi
kaonavi
0
160
AI Coding Agent時代のcdk-nagガードレール 〜組織ルールを強制CIで守り抜く設計の挑戦〜
mhrtech
3
510
SRENEXT_2026_Chairs__Talks_in_Tamachi.sre.pdf
srenext
1
140
【公開用】AI_Dev_Ex2026_AI_登壇資料
matsuritechnologies
PRO
1
470
StepFunctionsとGraphRAGを活用した暗黙知活用のためのRAG基盤
yakumo
0
120
ファミコンでPHPを動かす / PHP on the Famicom
tomzoh
2
600
生成AI×AWS CDK×AWS FISで"振り返れる"ミニGameDayをつくろう
yoshimi0227
2
530
_NIKKEI_Tech_Talk__勉強会は熱量では続かない___17回続いた輪読会の設計術.pdf
_awache
1
100
Featured
See All Featured
Fantastic passwords and where to find them - at NoRuKo
philnash
52
3.8k
Lightning talk: Run Django tests with GitHub Actions
sabderemane
0
220
Facilitating Awesome Meetings
lara
57
7k
Leveraging Curiosity to Care for An Aging Population
cassininazir
1
410
Docker and Python
trallard
47
4k
Design in an AI World
tapps
1
270
Digital Projects Gone Horribly Wrong (And the UX Pros Who Still Save the Day) - Dean Schuster
uxyall
1
2.1k
B2B Lead Gen: Tactics, Traps & Triumph
marketingsoph
0
180
Agile Leadership in an Agile Organization
kimpetersen
PRO
0
190
Code Review Best Practice
trishagee
74
20k
Beyond borders and beyond the search box: How to win the global "messy middle" with AI-driven SEO
davidcarrasco
3
190
State of Search Keynote: SEO is Dead Long Live SEO
ryanjones
0
220
Transcript
視覚的基盤モデルを用いた Trimodal Cross-Attentional Transformer に基づく再配置対象の検出 慶應義塾大学 西村喬行,松尾榛夏,杉浦孔明
背景:生活支援ロボットにおけるRearrangementタスク ▪ 生活支援ロボット ▪ 高齢化社会における在宅介助者不足解消に期待 ▪ Rearrangement (再配置)タスクができれば便利 ▪ 変化検出が重要
- 2 - 片付けしといて 片付けるべき オブジェクトを特定 CVPR23 Scene Understanding Challenge
問題設定:Rearrangement Target Detection (RTD) - 3 - ▪ 目標状態及び現在の状態画像から再配置すべき物体を検出 ▪
再配置対象 ▪ 位置,向きが変化した物体&開閉した引き出し及び扉 目標状態 現在の状態 マスク画像
問題設定:RTDタスクは人間にとっても容易ではない - 4 - 現在の状態 目標状態
問題設定:RTDタスクは人間にとっても容易ではない - 5 - 目標状態 現在の状態 マスク画像
既存研究:RTDに似たタスクにScene Change Detectionがある - 6 - タスク名 既存研究 Scene Change
Detection CSCDNet [Sakurada+, ICRA20] C-3PO [Wang+, PR23] Rearrangement Target Detection [松尾+, JSAI23] CSCDNet [Sakurada+, ICRA20] C-3PO [Wang+, PR23]
既存研究:RTDに似たタスクにScene Change Detectionがある - 7 -
既存手法の問題点: RTDのためにはセグメンテーションの性能が不十分 - 8 - 画素値比較 [松尾, JSAI23] 画素値比較
影や明るさ変化に対応できない [松尾+, JSAI23] ドア開閉の深度変化や小物体に対する性能は不十分 影の変化をマスク 小物体を誤検出 ドアの開閉に課題
- 9 - 新規性: RGBD画像及びSAM [Kirillov+, 23]で 生成したセグメンテーション画像を扱う Trimodal Cross-Attentional
Encoder 提案手法: Trimodal Cross-Attentional Transformer及びSAMの導入 ☺深度とセグメント情報の統合及び (Trimodal) 目標、現在の状態関係性のモデル化 (Cross-Attentional Encoder)
▪ SAM [Kirillov+, 23] ☺ 各物体の領域情報を与えることができる →小物体や領域予測に役立つ Mask2Former [Cheng+, CVPR21]はSAMと比べ性能が劣る
- 10 - 対象画像 Mask2Former SAM 一部正確に領域予測 出来ていない ☺小物体も正確に予測
提案手法: モデル図の全体像 - 11 - Serial Encoder Serial Encoder Decoder
Trimodal Cross-Attentional Transformer
- 12 - ▪ 入力:RGBD画像の組 ▪ SAM [Kirillov+, 23] ▪
セグメンテーション画像 ▪ Serial Encoder ▪ Trimodal Cross-Attentional Encoder ▪ Decoder ▪ 出力:再配置物体のマスク画像 提案手法:主に3 つのモジュールをもつ
Serial Encoder:CoaT [Xu+, ICCV21] による視覚情報の強化 - 13 - RGBD画像を 結合
番目のserial block ➀パッチ埋め込み層でダウンサンプリング ②平坦化&CLSトークンを結合 ③Conv-Attention Module [Xu+, ICCV21]を 適用 ④画像トークンとCLSトークンを分離& 画像トークンを変形 ☺ Serial Encoder [Xu+, ICCV21]を用いて複数次元の画像特徴量を抽出
Conv-Attention Module [Xu+, ICCV21] 時間,空間計算量を削減したattention構造 - 14 - CoaT [Xu+,
ICCV21] -Convolutional Position Encoding 畳み込みをPosition embeddingとして利用 -Factorized Attention ☺計算量の削減
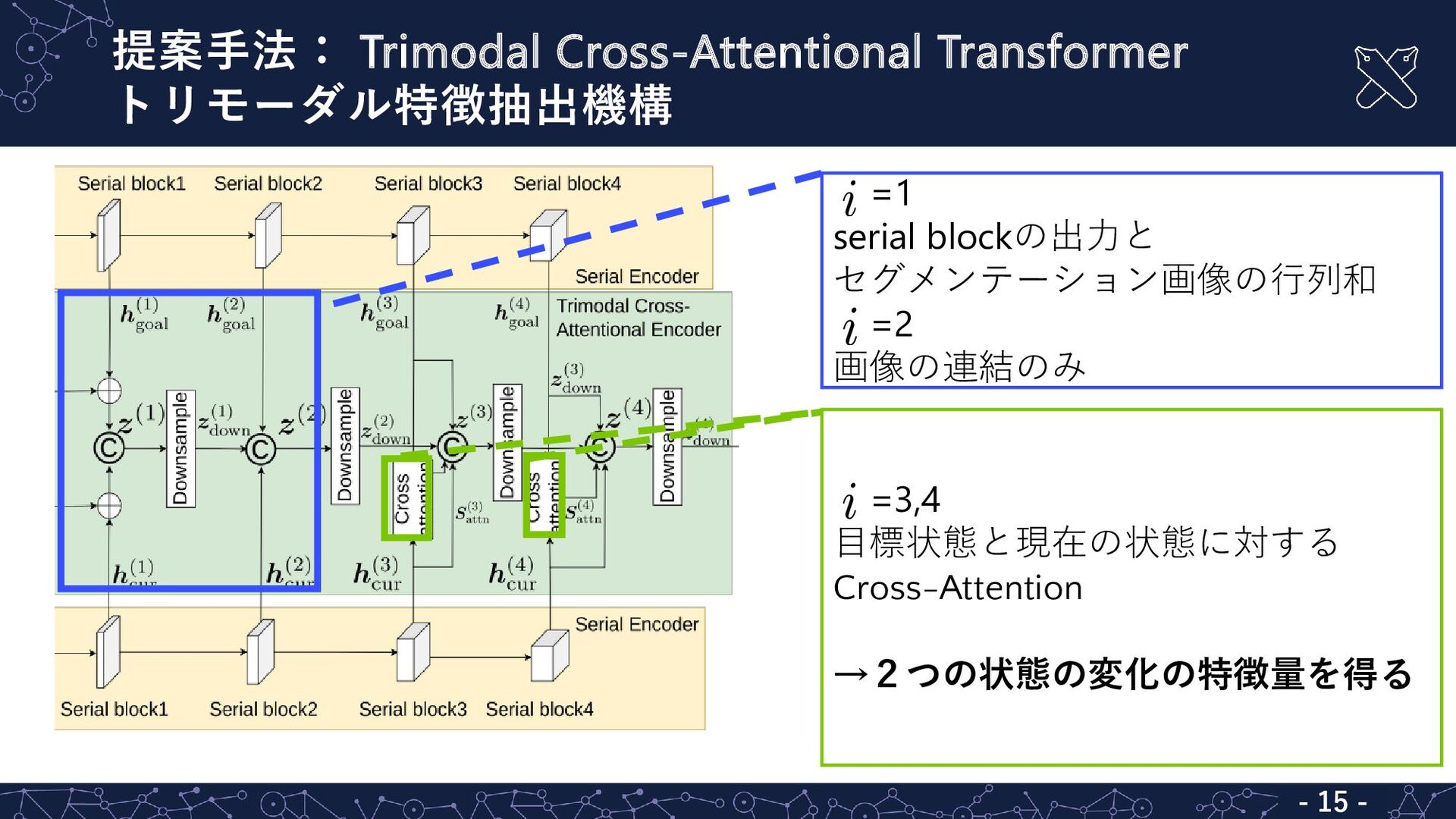
提案手法: Trimodal Cross-Attentional Transformer トリモーダル特徴抽出機構 - 15 - =1 serial
blockの出力と セグメンテーション画像の行列和 =2 画像の連結のみ =3,4 目標状態と現在の状態に対する Cross-Attention →2つの状態の変化の特徴量を得る
RTDDデータセットの構築:大規模な再配置検出データセット - 16 - ◼ AI2-THOR [Kolve+, 17]で作成 ◼ 目標,現在の状態のRGBD画像
◼ 正解マスク画像 ◼ 12000サンプル(10:1:1) ◼ ランダムに対象を配置 ◼ 30cm以上の移動 ◼ 60%以上の開閉
定量的結果:ベースライン手法をmIoU及びF1-scoreで上回る ▪ Trimodal Cross-Attentional Encoderを使用した手法の精度が最高 ▪ 深度画像の寄与が大きい ▪ ベースライン手法をmIoU及びF1 -score
で上回った (P<0.05) 手法 深度画像 mask mIoU [%] F1 -score [%] ベースライン手法 [松尾, JSAI23] - - 59.0±0.5 85.2±0.3 提案手法 ✓ 73.4±0.6 91.3±0.2 ✓ 58.3±0.7 84.9±0.3 ✓ ✓ 73.5±0.3 91.3±0.1 - 17 - +6.1 +14.5
定性的結果:課題であるドアの開閉&小物体で良好な結果 ☺ 引き出しの開閉&机上の小物体の検出でより適切にセグメンテーション - 18 - 目標状態 現在の状態 GT [松尾,
JSAI23] 提案手法 扉の領域が不精確 ☺小物体の予測
定性的結果:物体内部をより適切にマスク - 19 - 目標状態 現在の状態 GT [松尾, JSAI23] 提案手法
☺ 大きな物体の内部をより適切にマスク 内部領域の 予測が不精確 ☺mIoU 4.5↑
失敗例 : depth画像の寄与度が大きい - 20 - 目標状態 現在の状態 GT 提案手法
depth画像に透明な物体が存在しない 瓶のマスク画像が 生成されない
エラー分析 : depth画像に関連したエラーが多い - 21 - エラー種類 サンプル数 depthマップ上で違いが分かりにくい物体 41
変化距離が短い物体 32 過小または過大な領域予測 21 アノテーション誤り 20 ◼ depth画像の寄与度が高い ◼ 透明、薄い物体がdepth画像上に存在しない ◼ 変化距離の検出に課題
まとめ - 22 - ▪ 背景 ✓ 生活支援ロボットに変化検出は重要 ▪ 提案
✓ RGBD画像及びSAMで生成した セグメンテーション画像を扱う Trimodal Cross-Attentional Encoder ▪ 結果 ✓ ベースラインをmIoU及びF1 -scoreにおいて上回る ✓ドアの開閉&机上の小物体の検出で良好な結果
Appendix
Google Bard 2/2 : 存在しないものを参照 - 24 - Disappeared:
The computer mouse has disappeared. Added: There is a small plant on the table. ☺ Moved: The position of the keyboard has changed slightly.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![既存手法の問題点: RTDのためにはセグメンテーションの性能が不十分 - 8 - 画素値比較 [松尾, JSAI23] 画素値比較 ](https://files.speakerdeck.com/presentations/412f5e548f9b494fb7e396ac3c98ad3f/slide_7.jpg){kind=link}
![- 9 - 新規性: RGBD画像及びSAM [Kirillov+, 23]で 生成したセグメンテーション画像を扱う Trimodal Cross-Attentional](https://files.speakerdeck.com/presentations/412f5e548f9b494fb7e396ac3c98ad3f/slide_8.jpg){kind=link}
![▪ SAM [Kirillov+, 23] ☺ 各物体の領域情報を与えることができる →小物体や領域予測に役立つ Mask2Former [Cheng+, CVPR21]はSAMと比べ性能が劣る](https://files.speakerdeck.com/presentations/412f5e548f9b494fb7e396ac3c98ad3f/slide_9.jpg){kind=link}
{kind=link}
![- 12 - ▪ 入力:RGBD画像の組 ▪ SAM [Kirillov+, 23] ▪](https://files.speakerdeck.com/presentations/412f5e548f9b494fb7e396ac3c98ad3f/slide_11.jpg){kind=link}
![Serial Encoder:CoaT [Xu+, ICCV21] による視覚情報の強化 - 13 - RGBD画像を 結合](https://files.speakerdeck.com/presentations/412f5e548f9b494fb7e396ac3c98ad3f/slide_12.jpg){kind=link}
![Conv-Attention Module [Xu+, ICCV21] 時間,空間計算量を削減したattention構造 - 14 - CoaT [Xu+,](https://files.speakerdeck.com/presentations/412f5e548f9b494fb7e396ac3c98ad3f/slide_13.jpg){kind=link}
{kind=link}
![RTDDデータセットの構築:大規模な再配置検出データセット - 16 - ◼ AI2-THOR [Kolve+, 17]で作成 ◼ 目標,現在の状態のRGBD画像](https://files.speakerdeck.com/presentations/412f5e548f9b494fb7e396ac3c98ad3f/slide_15.jpg){kind=link}
{kind=link}
{kind=link}
![定性的結果:物体内部をより適切にマスク - 19 - 目標状態 現在の状態 GT [松尾, JSAI23] 提案手法](https://files.speakerdeck.com/presentations/412f5e548f9b494fb7e396ac3c98ad3f/slide_18.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}