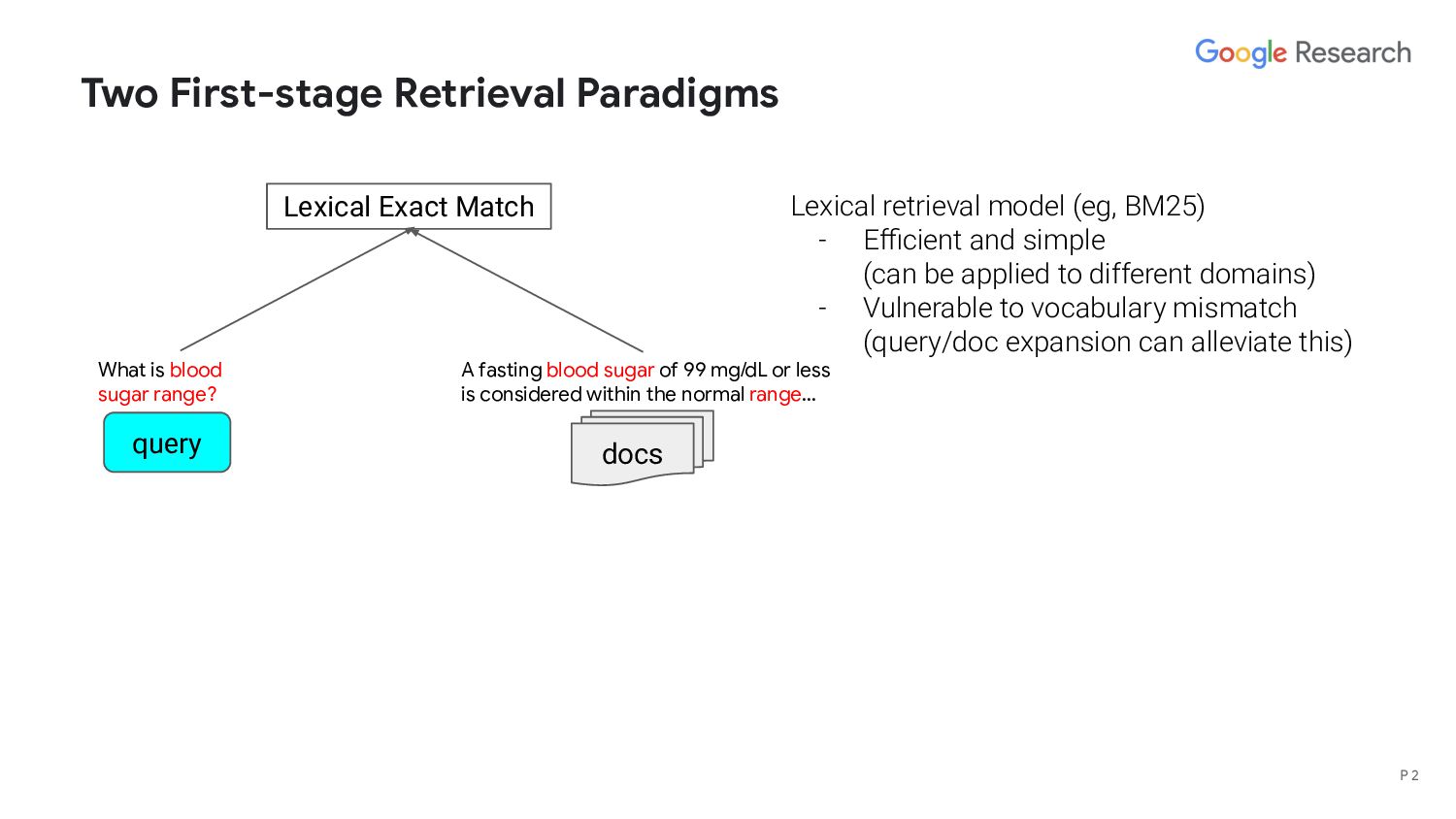
range? A fasting blood sugar of 99 mg/dL or less is considered within the normal range… Lexical Exact Match Lexical retrieval model (eg, BM25) - Efficient and simple (can be applied to different domains) - Vulnerable to vocabulary mismatch (query/doc expansion can alleviate this) P 2
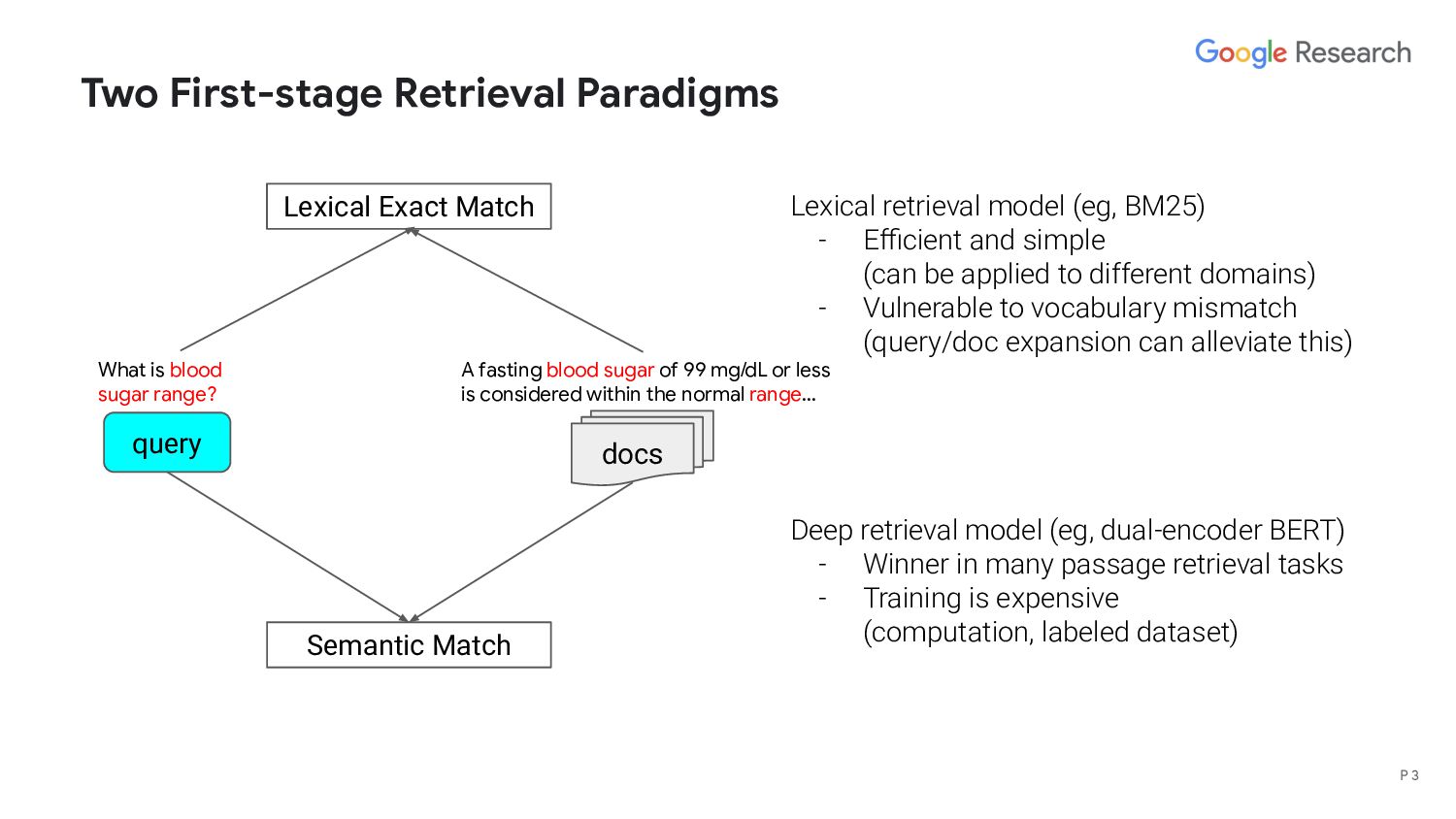
range? A fasting blood sugar of 99 mg/dL or less is considered within the normal range… Semantic Match Lexical Exact Match Lexical retrieval model (eg, BM25) - Efficient and simple (can be applied to different domains) - Vulnerable to vocabulary mismatch (query/doc expansion can alleviate this) Deep retrieval model (eg, dual-encoder BERT) - Winner in many passage retrieval tasks - Training is expensive (computation, labeled dataset) P 3
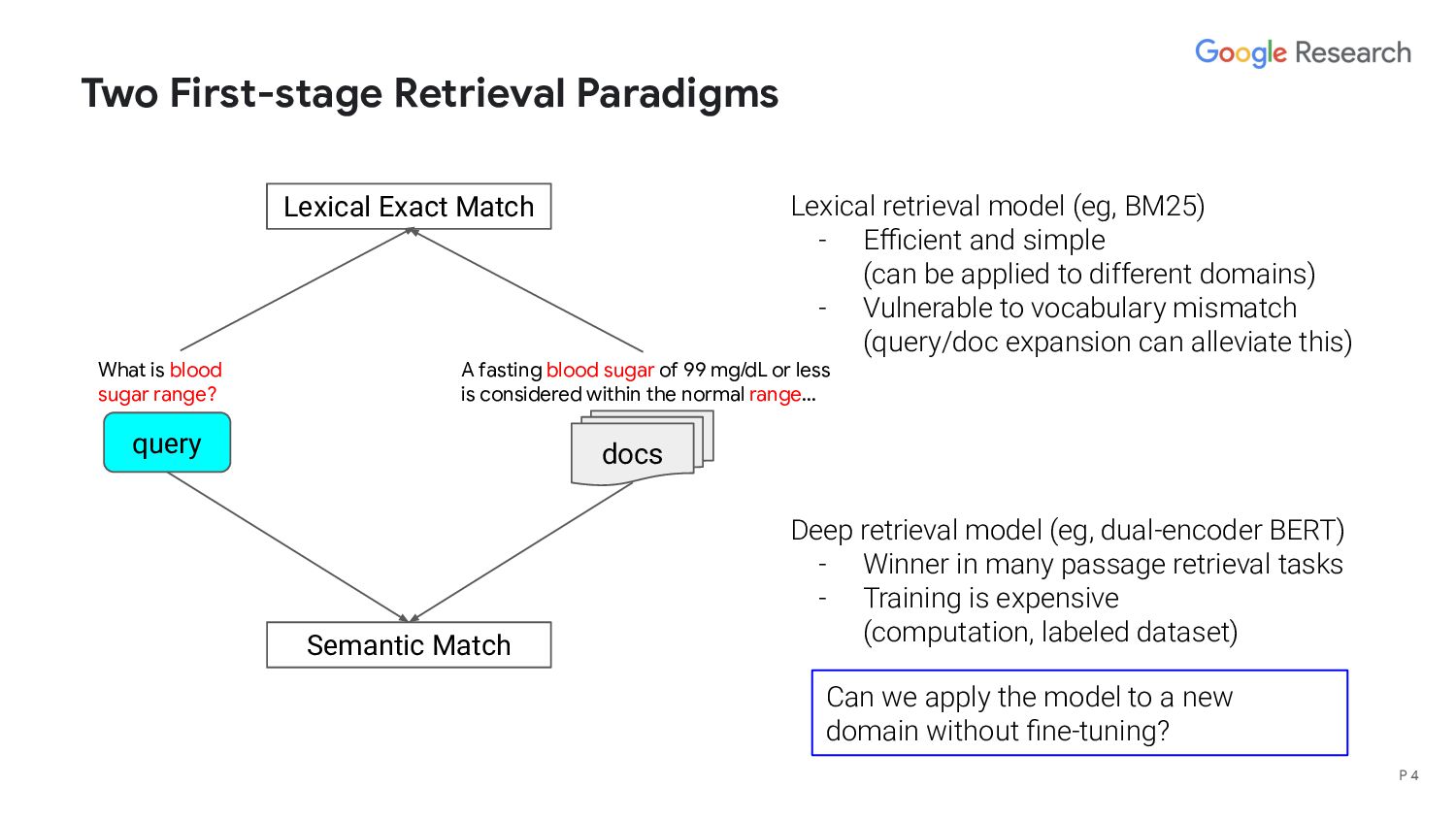
range? A fasting blood sugar of 99 mg/dL or less is considered within the normal range… Semantic Match Lexical Exact Match Lexical retrieval model (eg, BM25) - Efficient and simple (can be applied to different domains) - Vulnerable to vocabulary mismatch (query/doc expansion can alleviate this) Deep retrieval model (eg, dual-encoder BERT) - Winner in many passage retrieval tasks - Training is expensive (computation, labeled dataset) P 4 Can we apply the model to a new domain without fine-tuning?
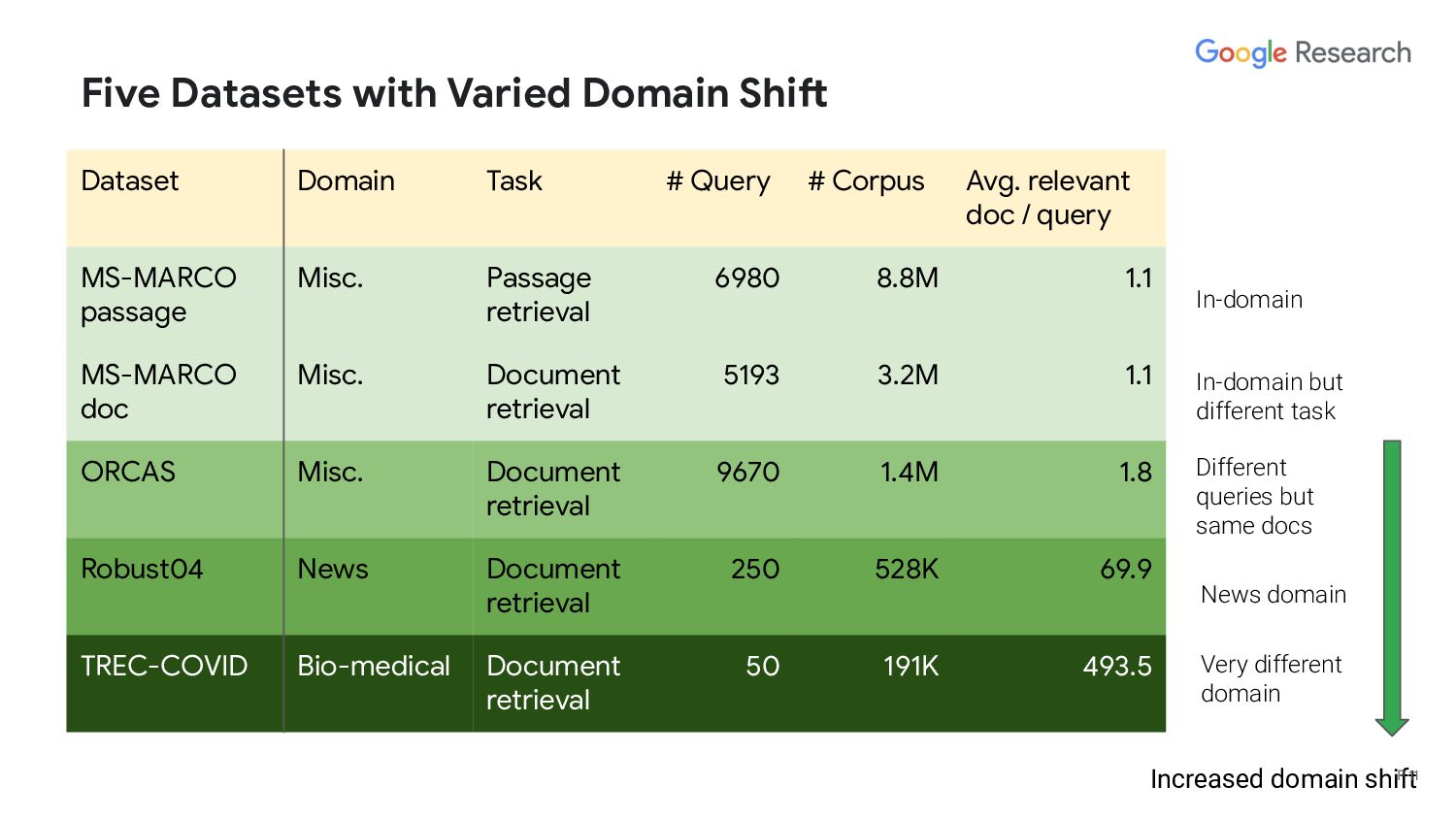
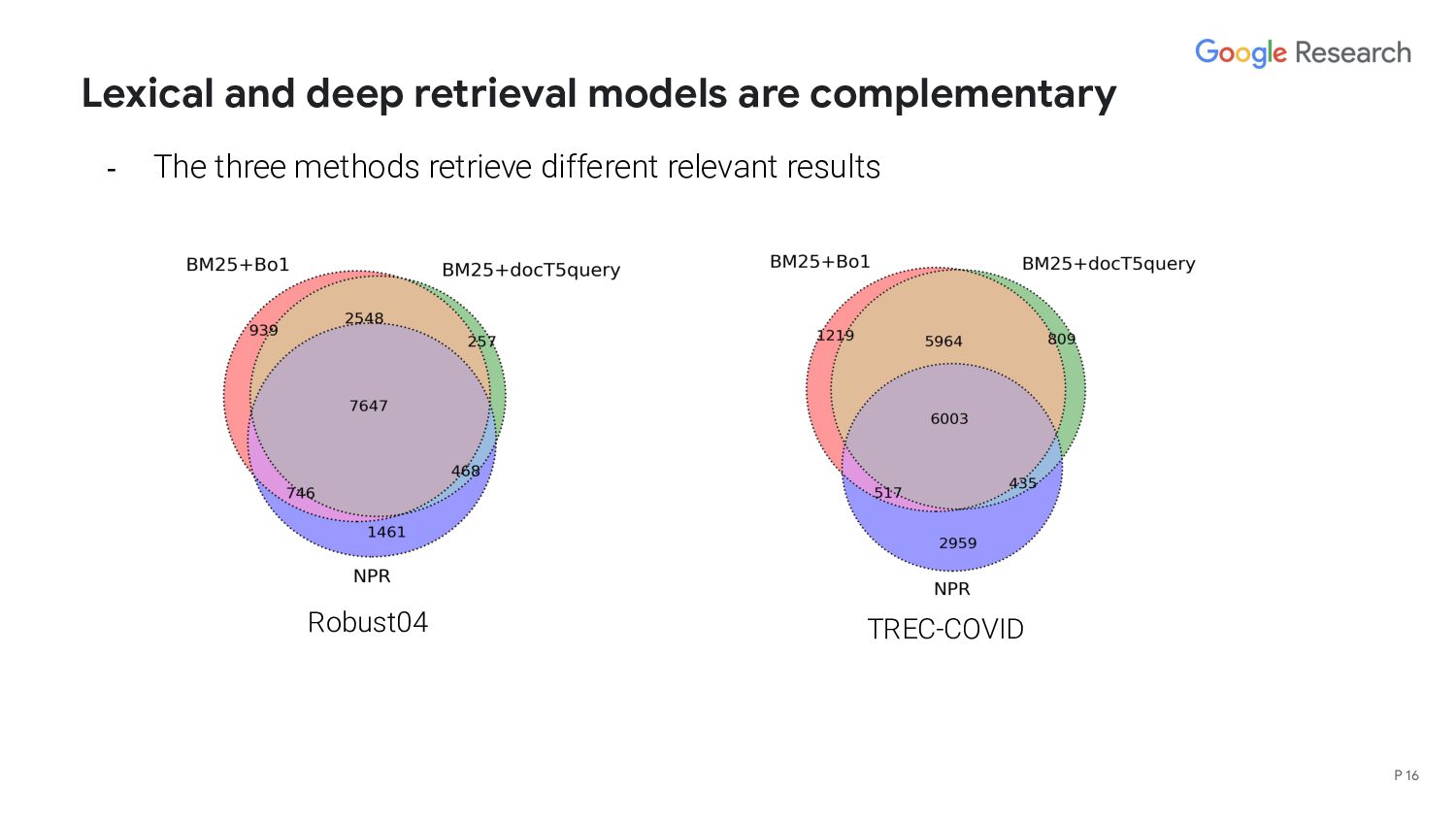
generalize to a new domain in a zero-shot setting? - RQ 2: Is deep retrieval complementary to lexical matching and query and document expansion? - RQ 3: Can lexical matching, expansion, and deep retrieval models be combined in a non-parametric hybrid retrieval model? P 5
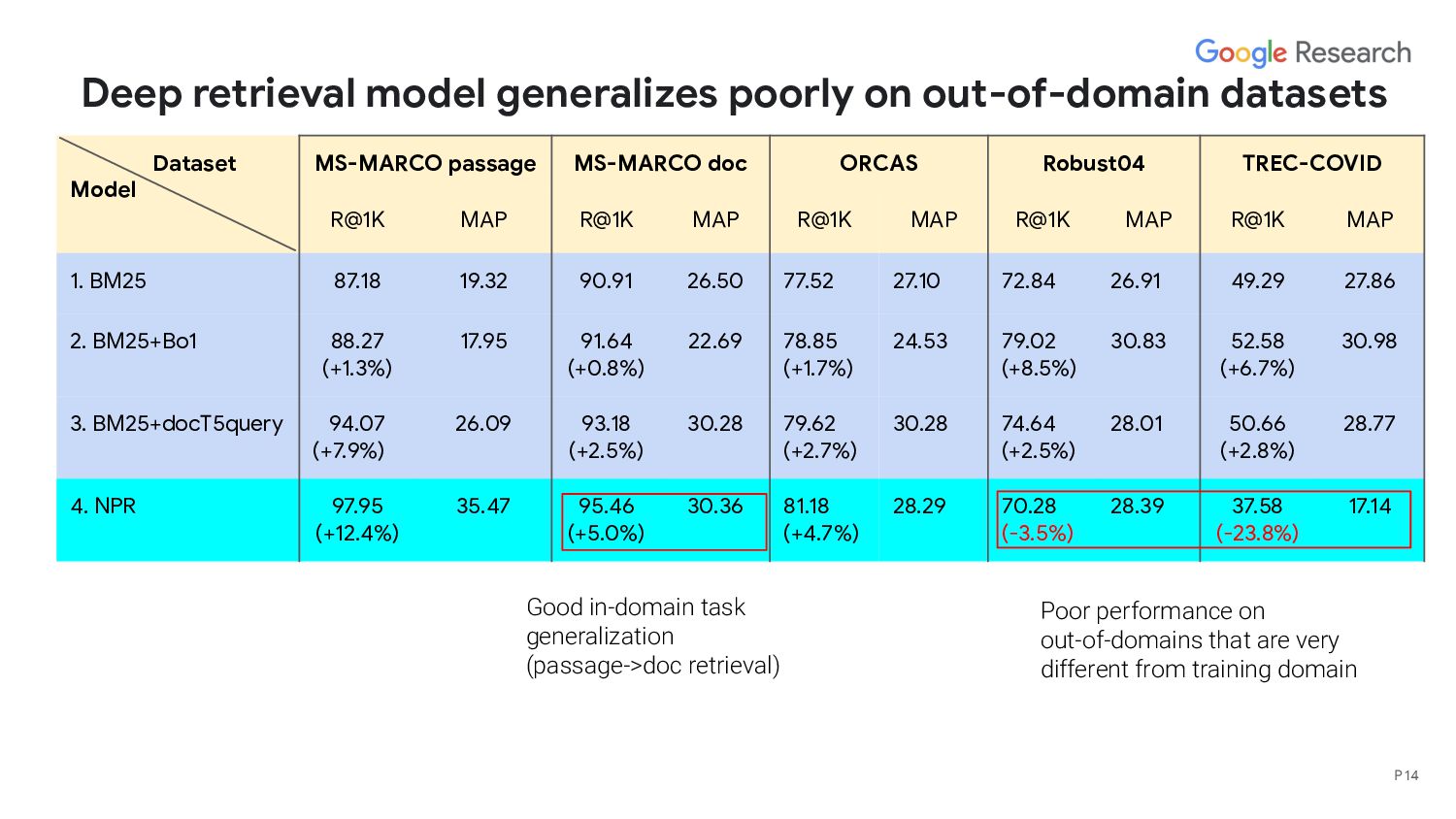
retrieval models (the most common approach, eg, [Karpukhin et al., 2020, Luan et al., 2021]) Need raw score normalization and weight tuning 2. Use RM3 (top lexical results are considered as relevance feedback) to select deep retriever results and combine them with top lexical results [Kuzi et al., 2020] 3. Combine the top results of two models in an alternative way [Zhan et al., 2020] P 6 Existing models were not evaluated in a zero-shot setup
generalize to a new domain in a zero-shot setting? - RQ 2: Is deep retrieval complementary to lexical matching and query and document expansion? - RQ 3: Can lexical matching, expansion, and deep retrieval models be combined in a non-parametric hybrid retrieval model? We are the first to propose and evaluate a hybrid retrieval model in a zero-shot setup P 7
can be easily applied to a new domain in a zero shot setting - A simple fusion framework based on Reciprocal Rank Fusion (RRF) Models The rank for d by model m query doc k=60 (following the original paper [Cormack et al., 2009]) - Non-parametric - Easy to fuse more than two models - Flexible to plug/unplug a model P 8
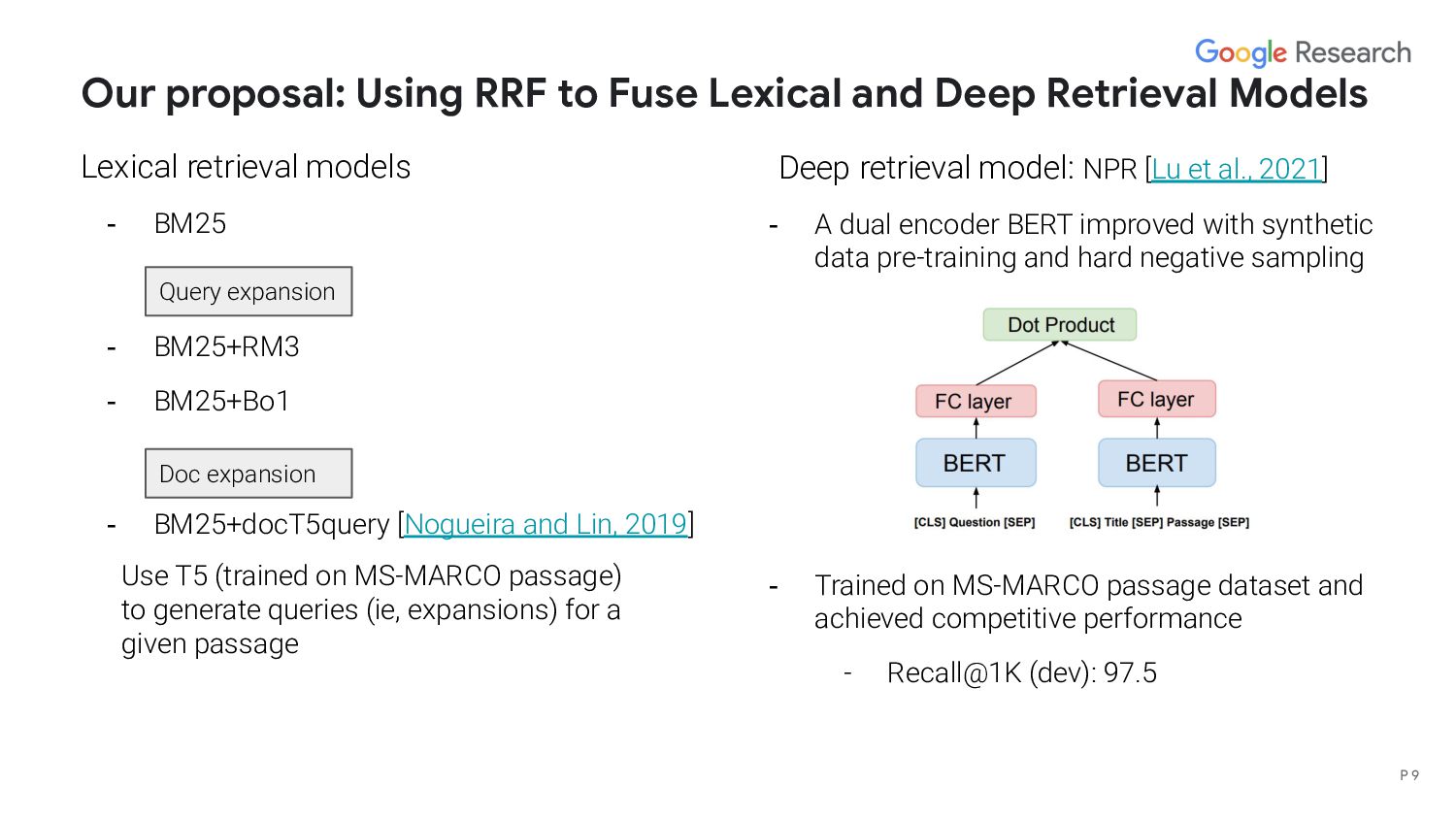
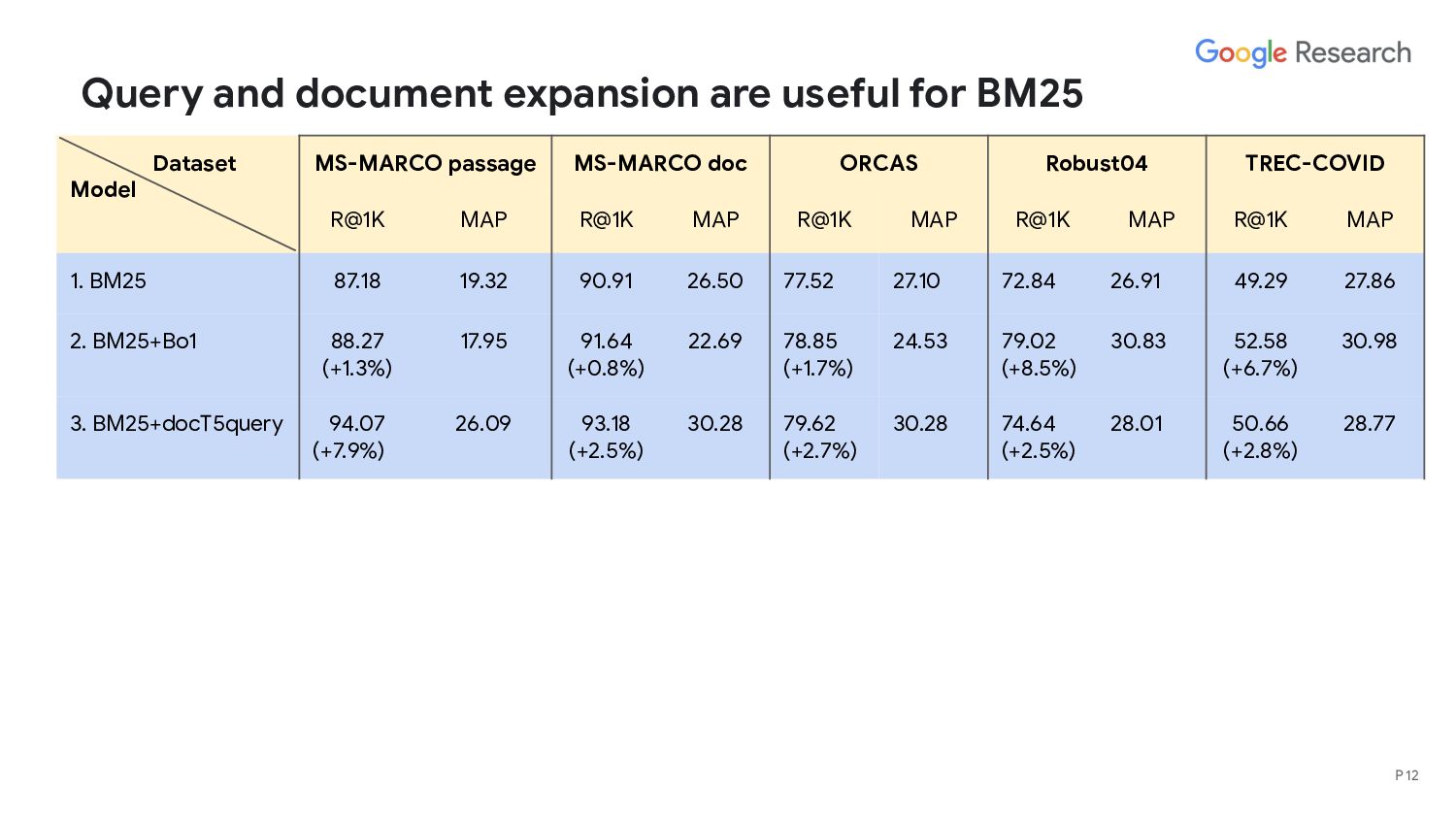
Models Lexical retrieval models - BM25 - BM25+RM3 - BM25+Bo1 - BM25+docT5query [Nogueira and Lin, 2019] Deep retrieval model: NPR [Lu et al., 2021] - A dual encoder BERT improved with synthetic data pre-training and hard negative sampling - Trained on MS-MARCO passage dataset and achieved competitive performance - Recall@1K (dev): 97.5 Query expansion Doc expansion P 9 Use T5 (trained on MS-MARCO passage) to generate queries (ie, expansions) for a given passage
generalize to a new domain in a zero-shot setting? - RQ 2: Is deep retrieval complementary to lexical matching and query and document expansion? - RQ 3: Can lexical matching, expansion, and deep retrieval models be combined in a non-parametric hybrid retrieval model? P 10
generalize to a new domain in a zero-shot setting? - RQ 2: Is deep retrieval complementary to lexical matching and query and document expansion? - RQ 3: Can lexical matching, expansion, and deep retrieval models be combined in a non-parametric hybrid retrieval model? P 13
generalize to a new domain in a zero-shot setting? - RQ 2: Is deep retrieval complementary to lexical matching and query and document expansion? - RQ 3: Can lexical matching, expansion, and deep retrieval models be combined in a non-parametric hybrid retrieval model? P 15
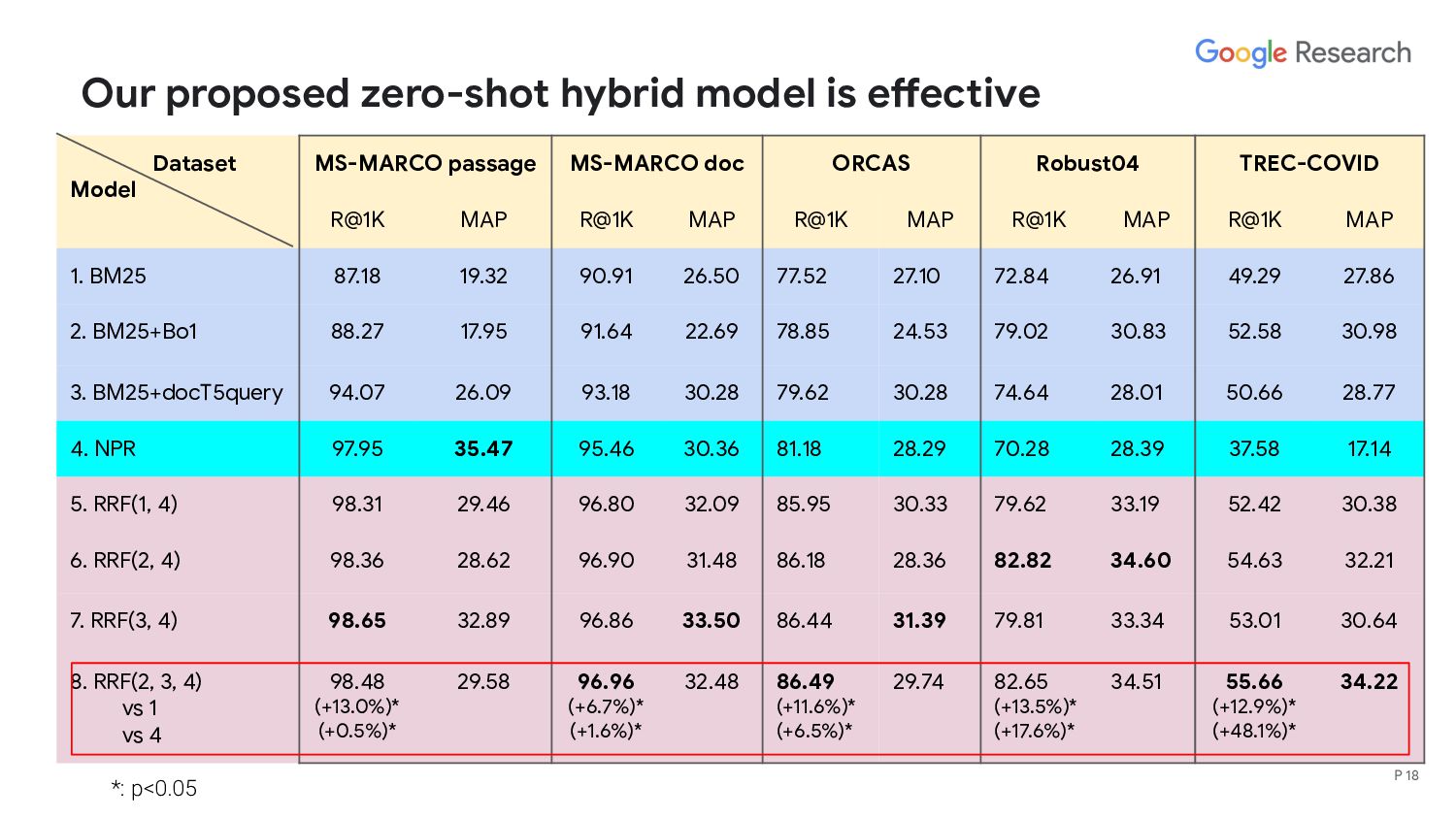
generalize to a new domain in a zero-shot setting? - RQ 2: Is deep retrieval complementary to lexical matching and query and document expansion? - RQ 3: Can lexical matching, expansion, and deep retrieval models be combined in a non-parametric hybrid retrieval model? P 17
generalize to a new domain in a zero-shot setting? - RQ 2: Is deep retrieval complementary to lexical matching and query and document expansion? - RQ 3: Can lexical matching, expansion, and deep retrieval models be combined in a non-parametric hybrid retrieval model? P 19
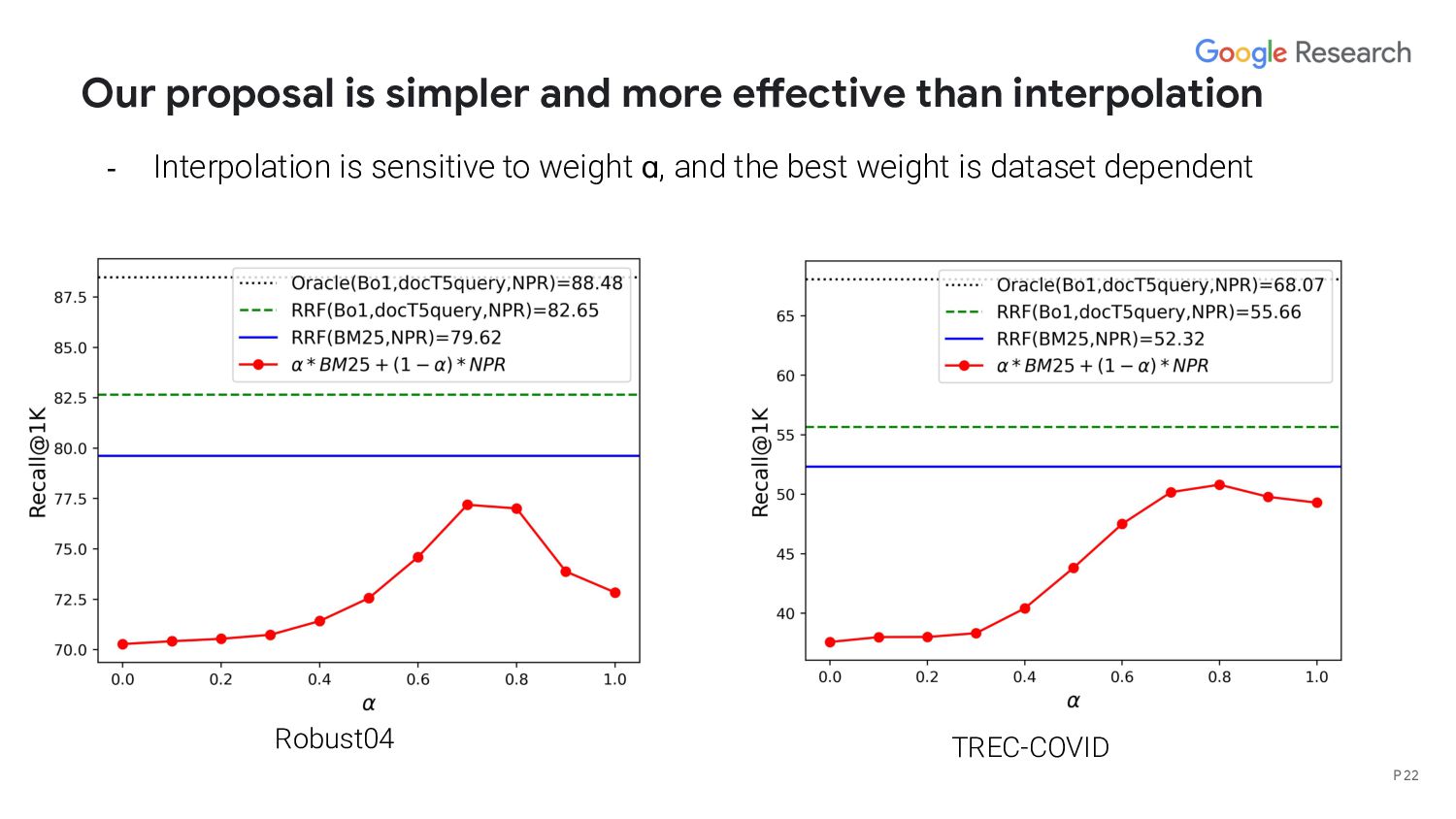
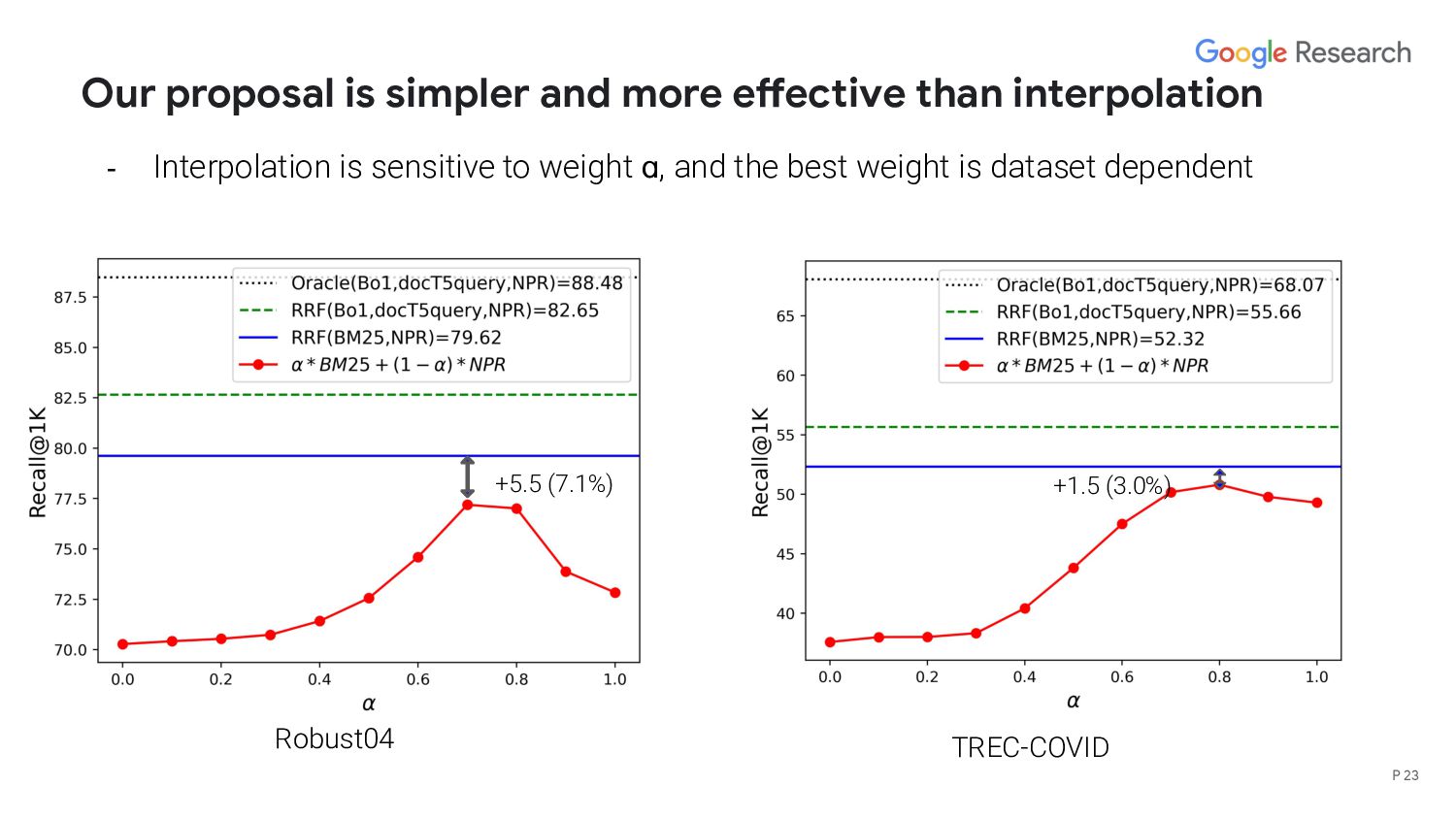
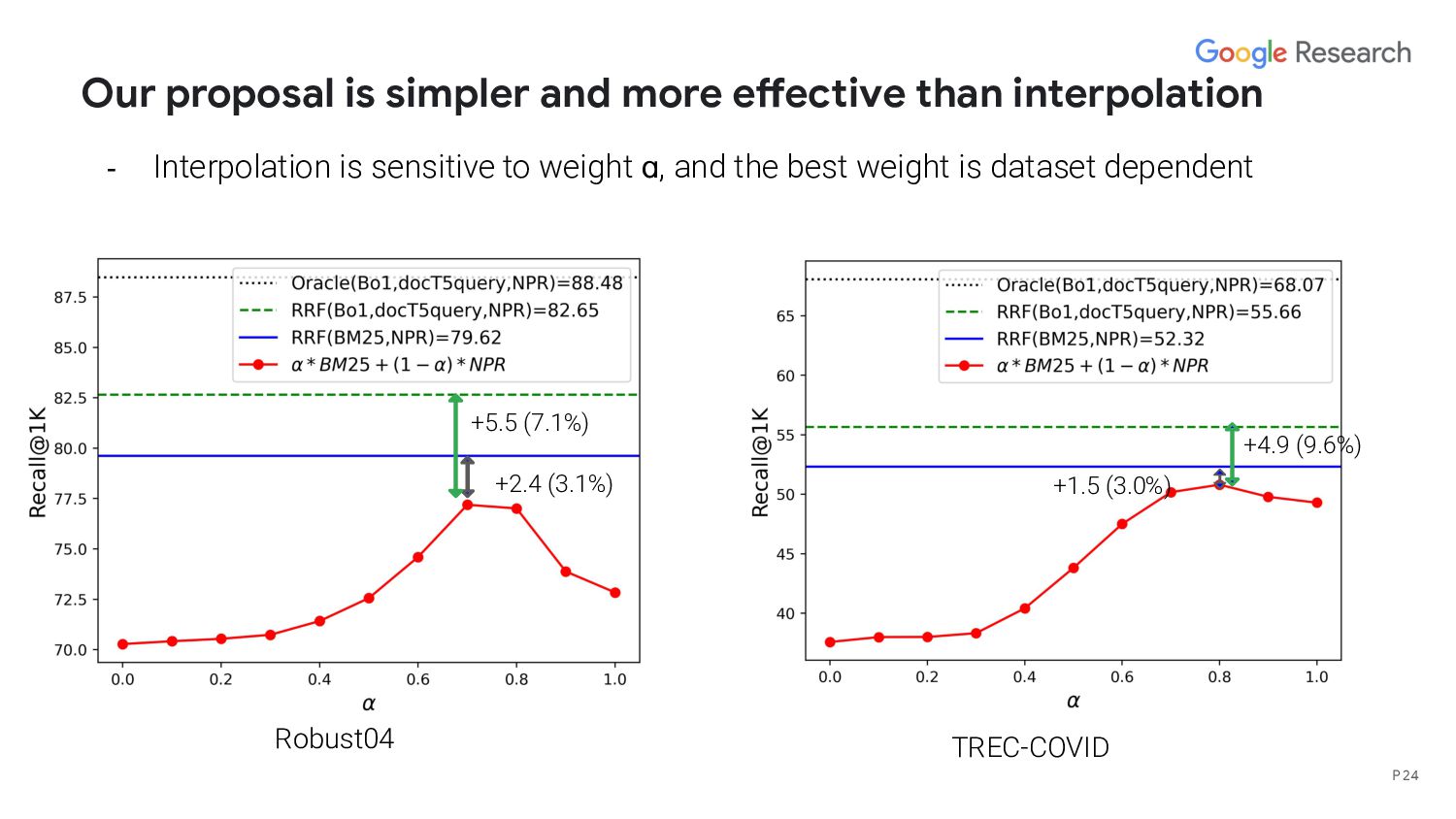
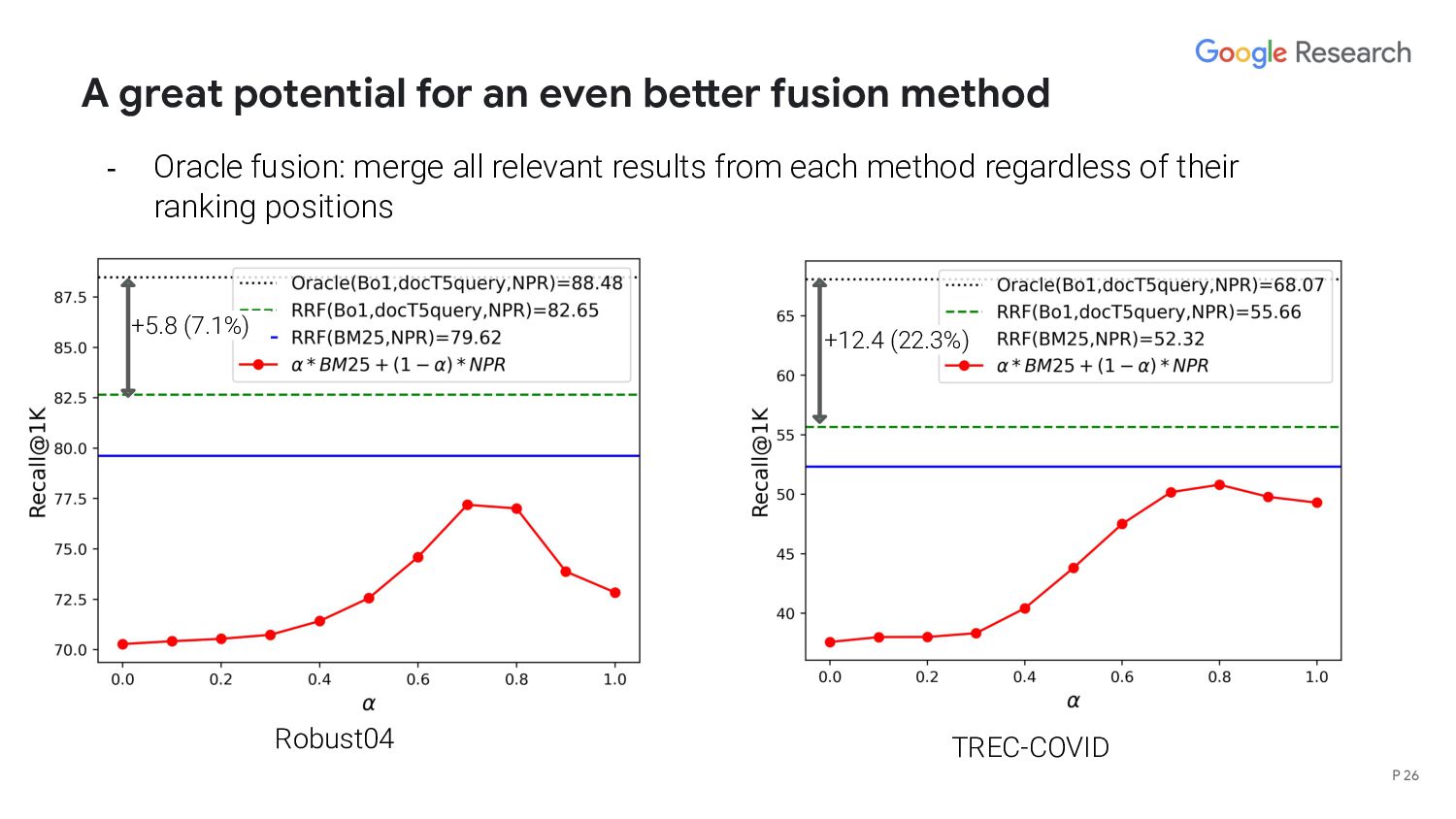
interpolation method? - What’s the upper bound of a fusion based hybrid model? - When does deep/lexical model perform better than the other? - We hypothesize that the performance is correlated with query length/structure P 27
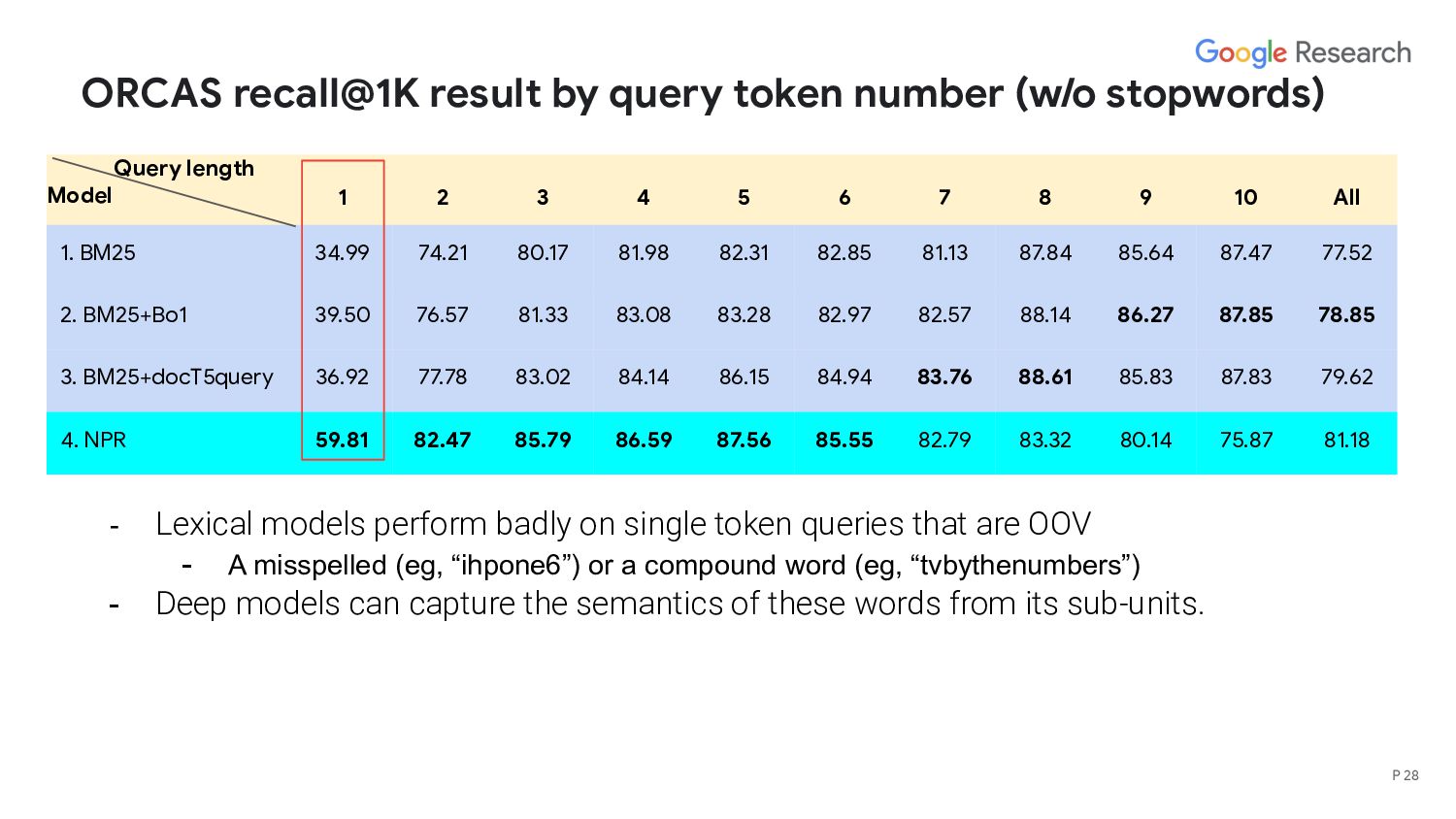
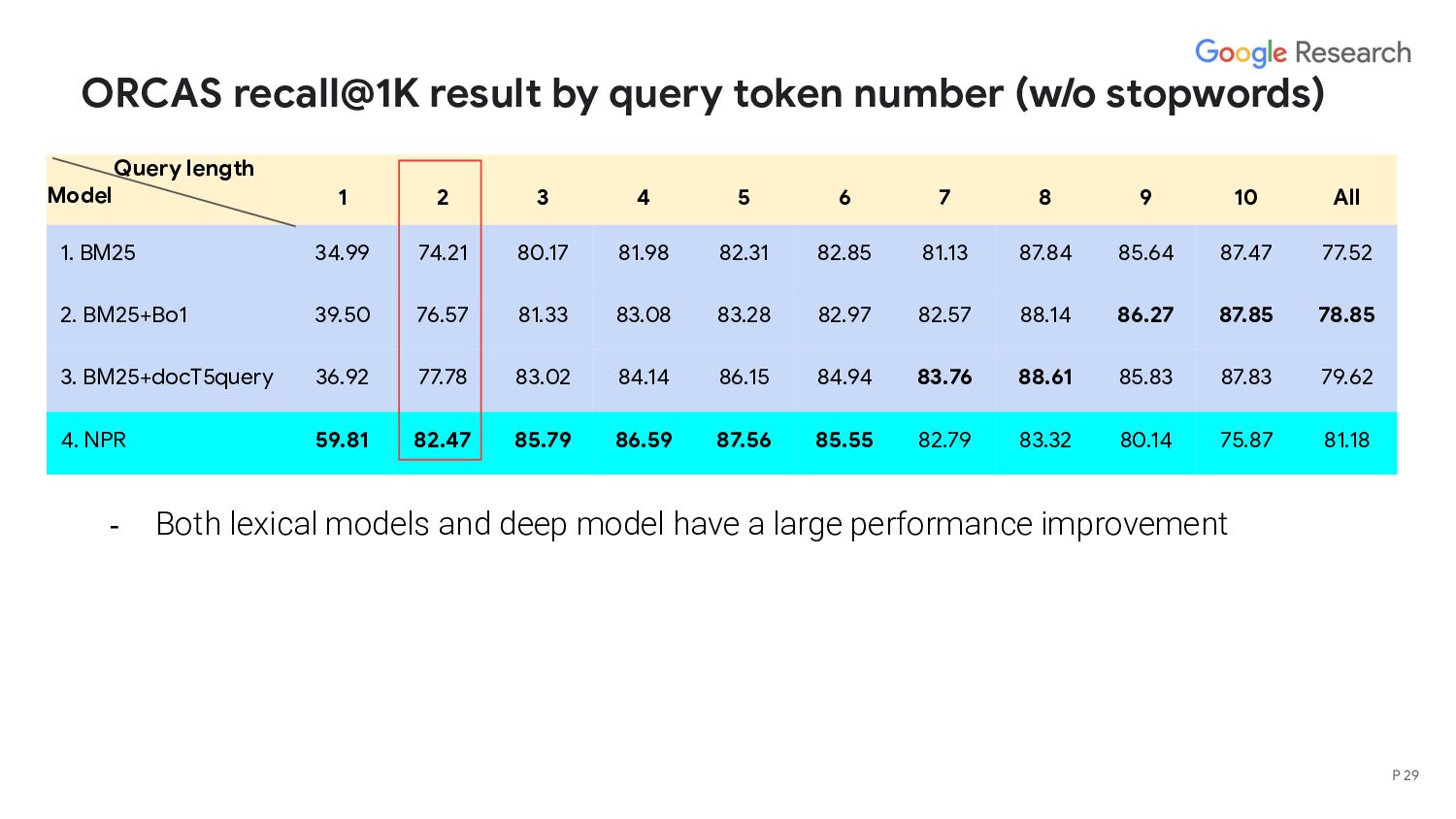
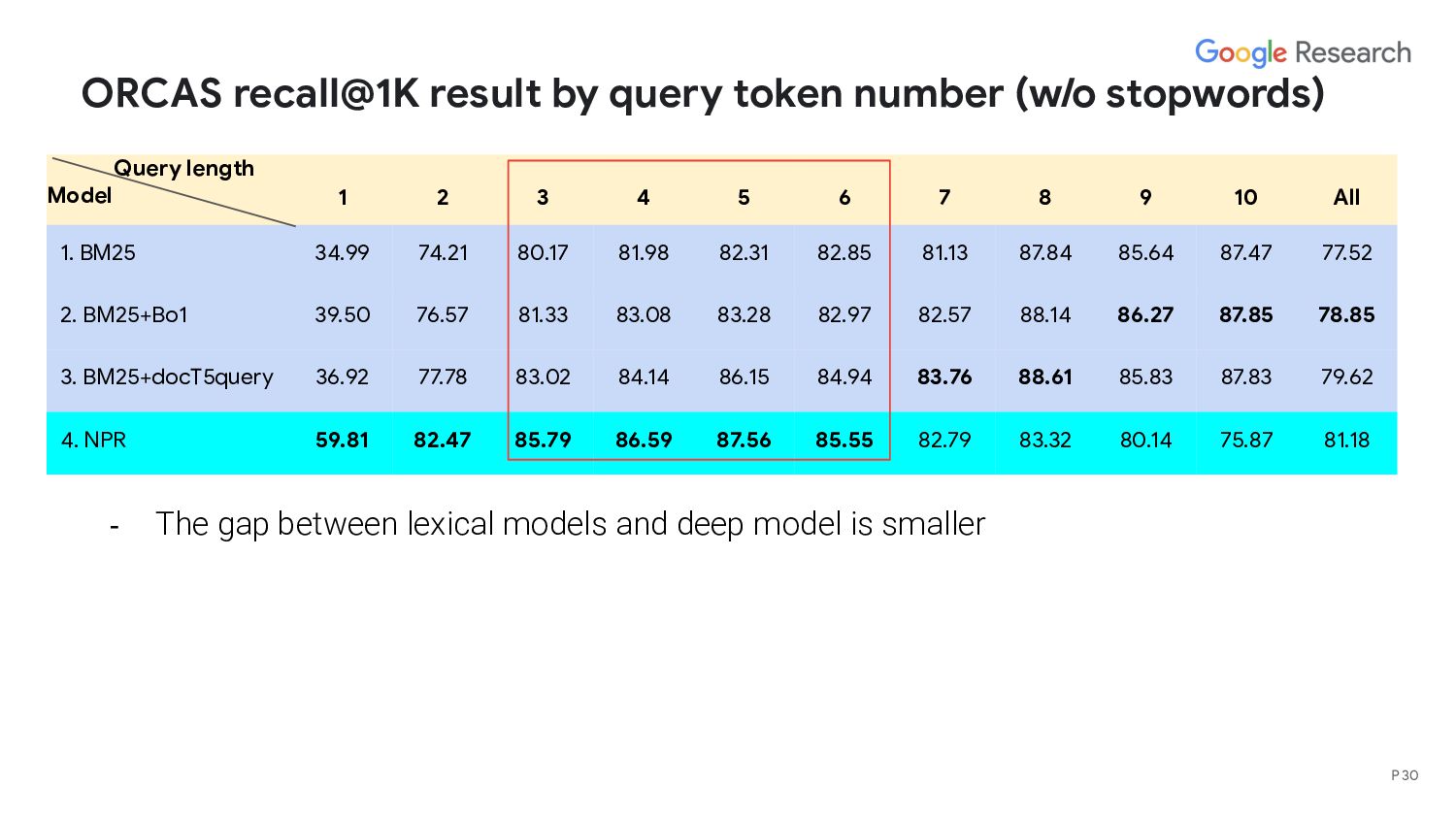
length Model 1 2 3 4 5 6 7 8 9 10 All 1. BM25 34.99 74.21 80.17 81.98 82.31 82.85 81.13 87.84 85.64 87.47 77.52 2. BM25+Bo1 39.50 76.57 81.33 83.08 83.28 82.97 82.57 88.14 86.27 87.85 78.85 3. BM25+docT5query 36.92 77.78 83.02 84.14 86.15 84.94 83.76 88.61 85.83 87.83 79.62 4. NPR 59.81 82.47 85.79 86.59 87.56 85.55 82.79 83.32 80.14 75.87 81.18 - Lexical models beat deep models on very long queries - Deep model performs poorly on long queries employing complex logic and seeking very specific information, eg, “According to piaget, which of the following abilities do children gain during middle childhood?” - Lexical models retrieve a doc containing the identical query but deep model fails. - Deep model is worse at capturing exact match (consistent with prior works) P 31
datasets in a zero-shot setting - A deep retrieval model and lexical models (with query/doc expansions) are complementary to each other - Propose a simple non-parametric hybrid model based on RRF to combine lexical and deep model results - Good performance in five datasets with zero-shot setting - Future work - Parameterize the hybrid model using query structure, query length, and the degree of domain shift - Improve the out-of-domain deep retrieval models via domain adaptation P 32
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}