**Privacy-Preserving Machine Learning**: Machine learning on data you _cannot see_.
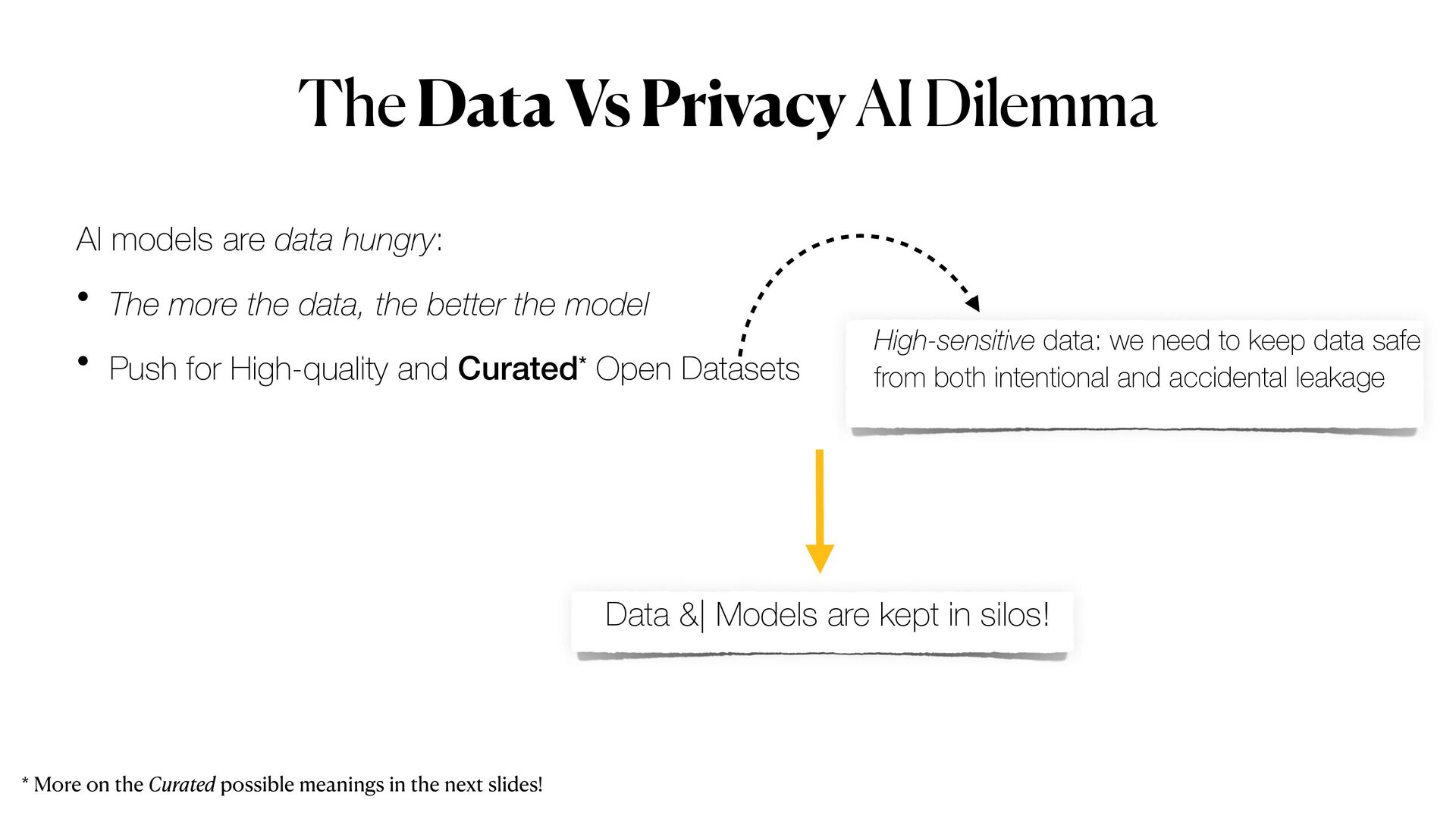
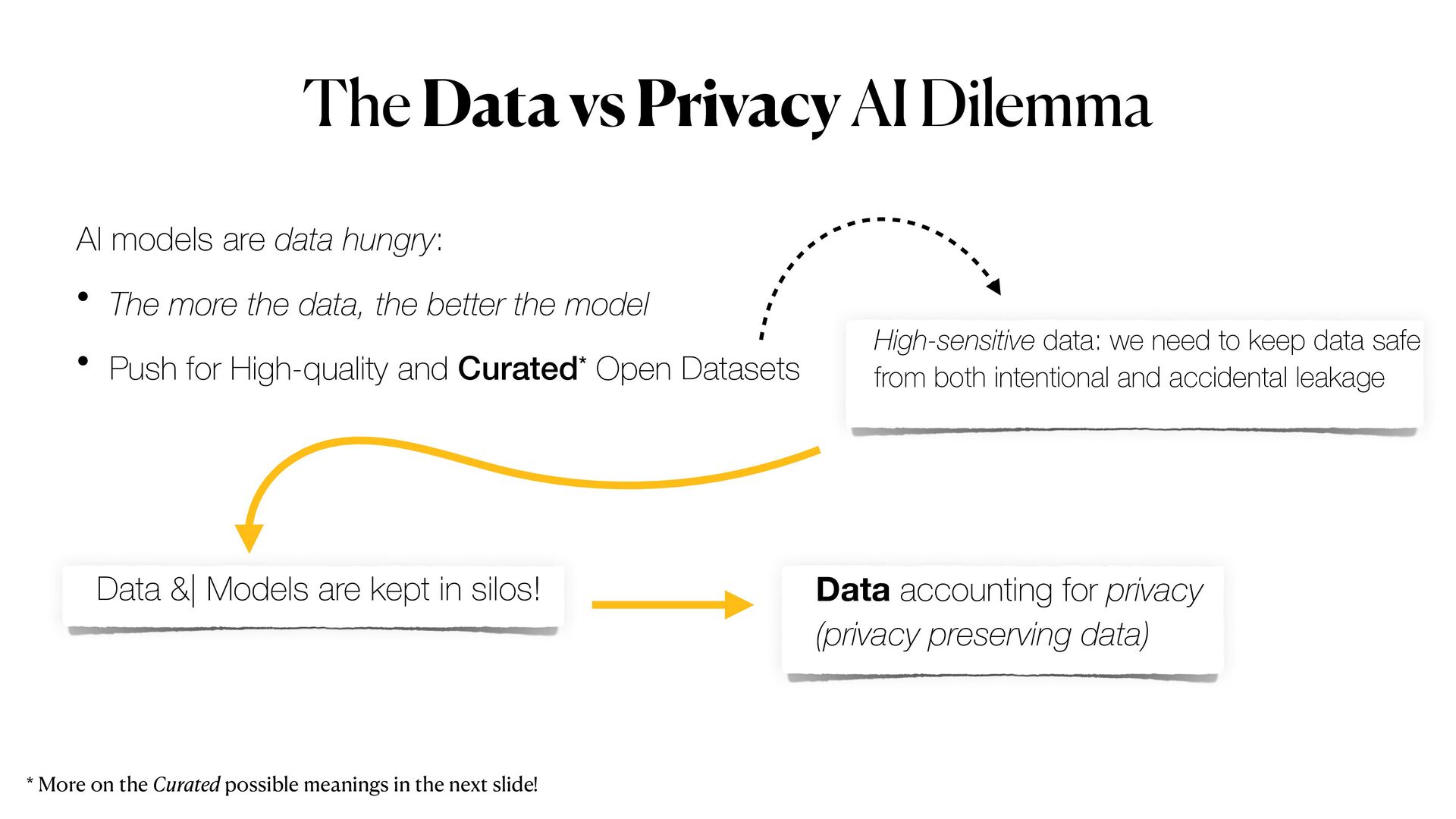
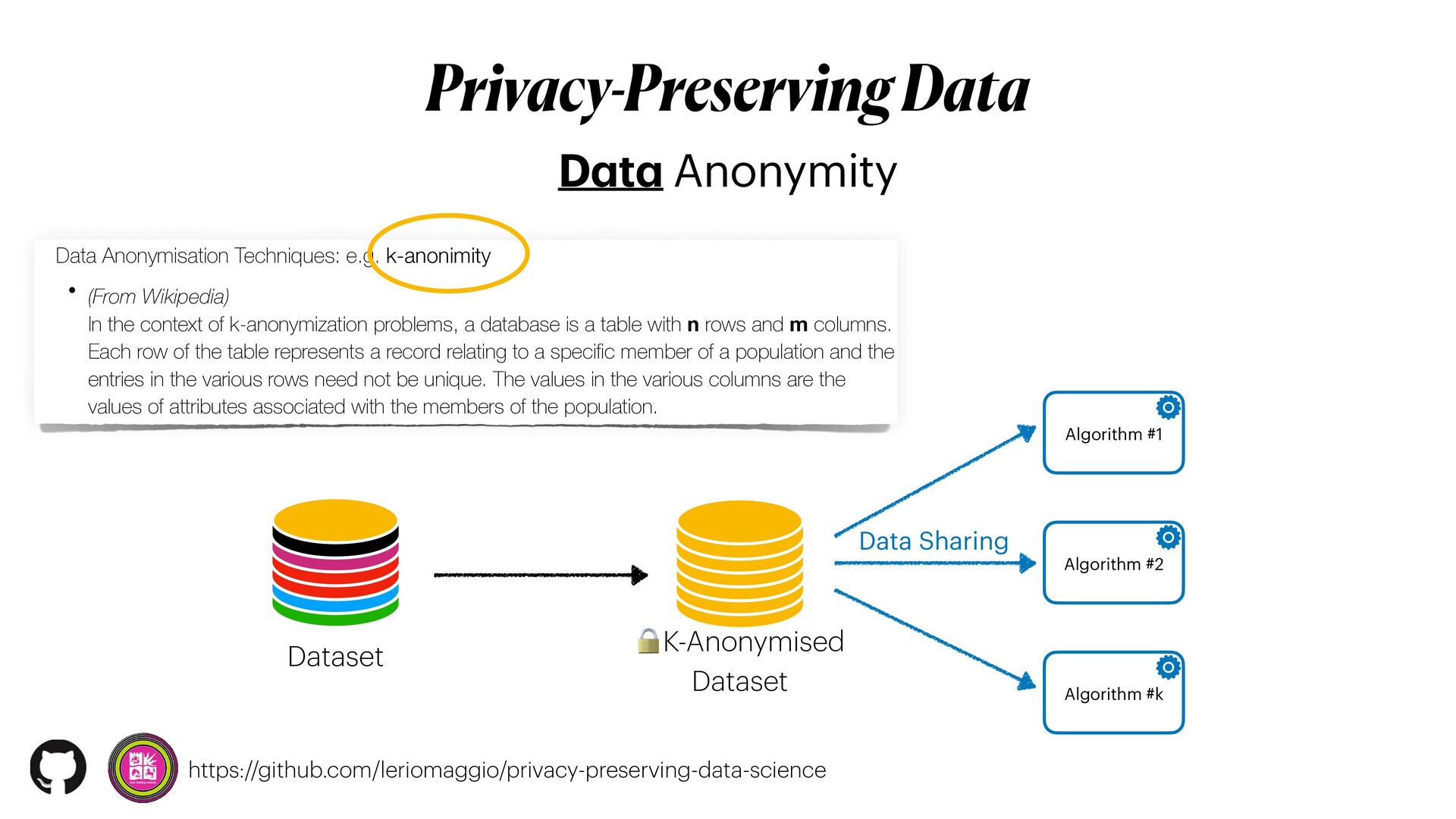
Privacy guarantees are one of the most crucial requirements when it comes to analyse sensitive information. However, data anonymisation techniques alone do not always provide complete privacy protection; moreover Machine Learning (ML) models could also be exploited to _leak_ sensitive data when _attacked_ and no counter-measure is put in place.
*Privacy-preserving machine learning* (PPML) methods hold the promise to overcome all those issues, allowing to train machine learning models with full privacy guarantees.
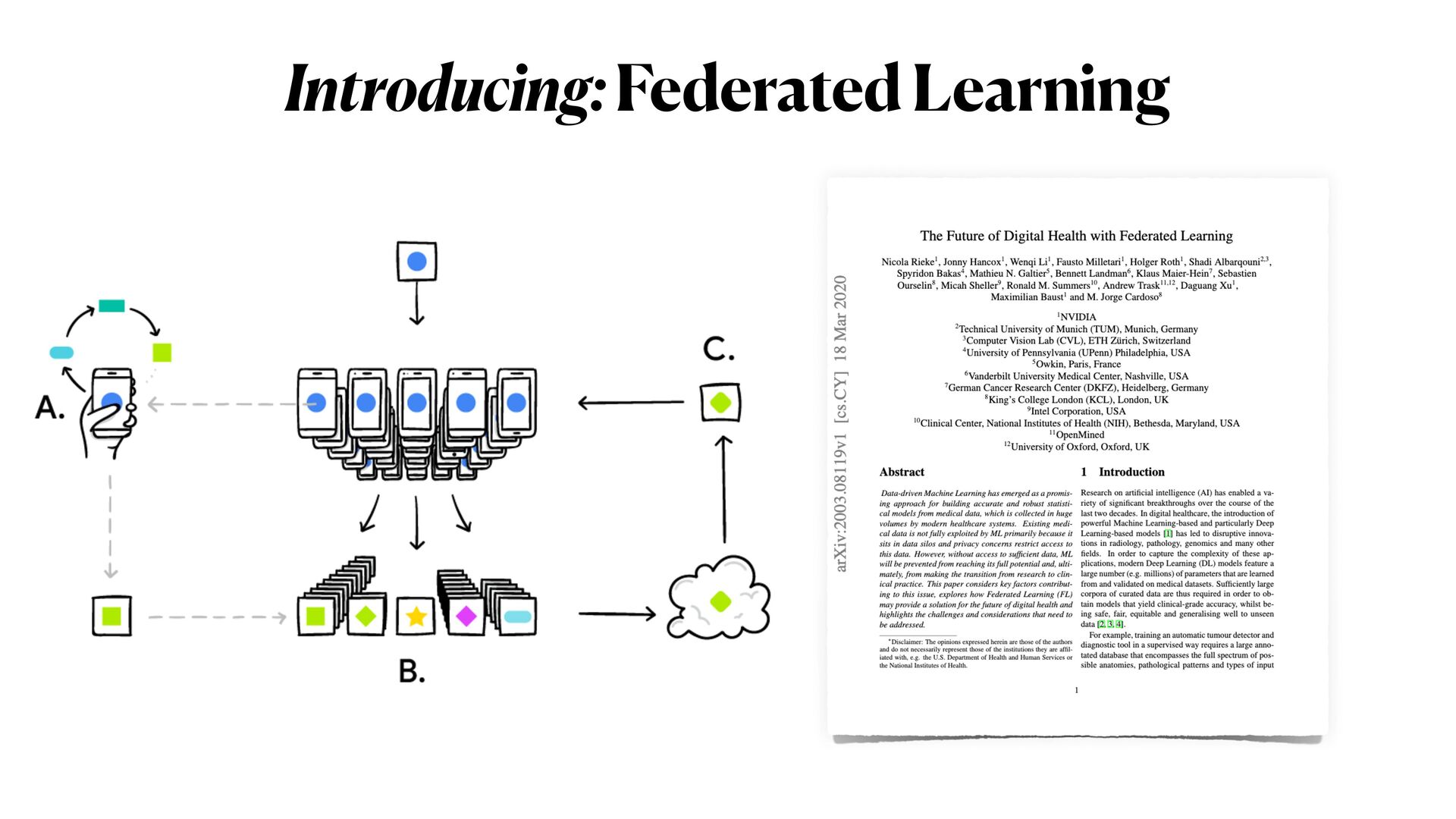
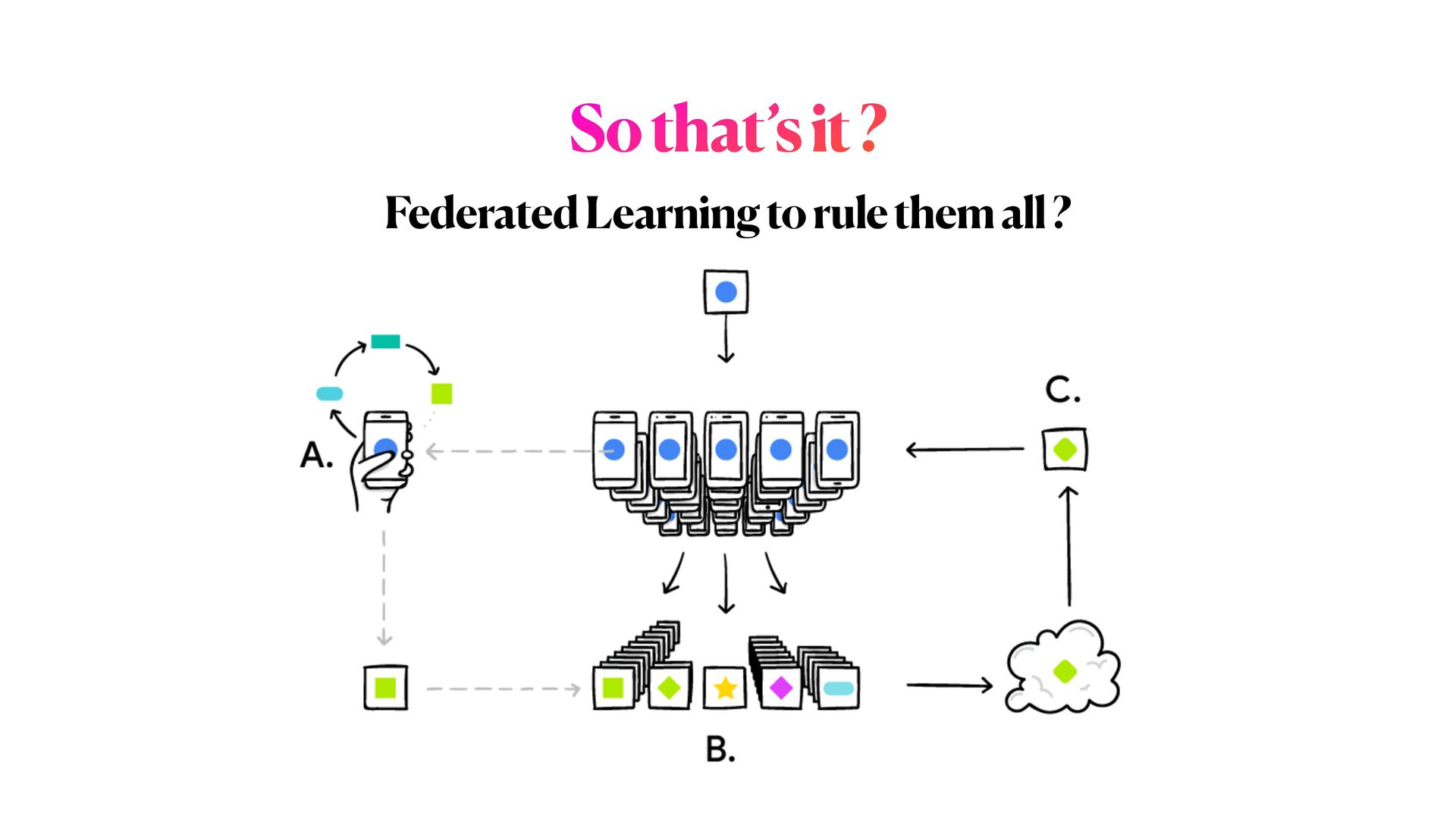
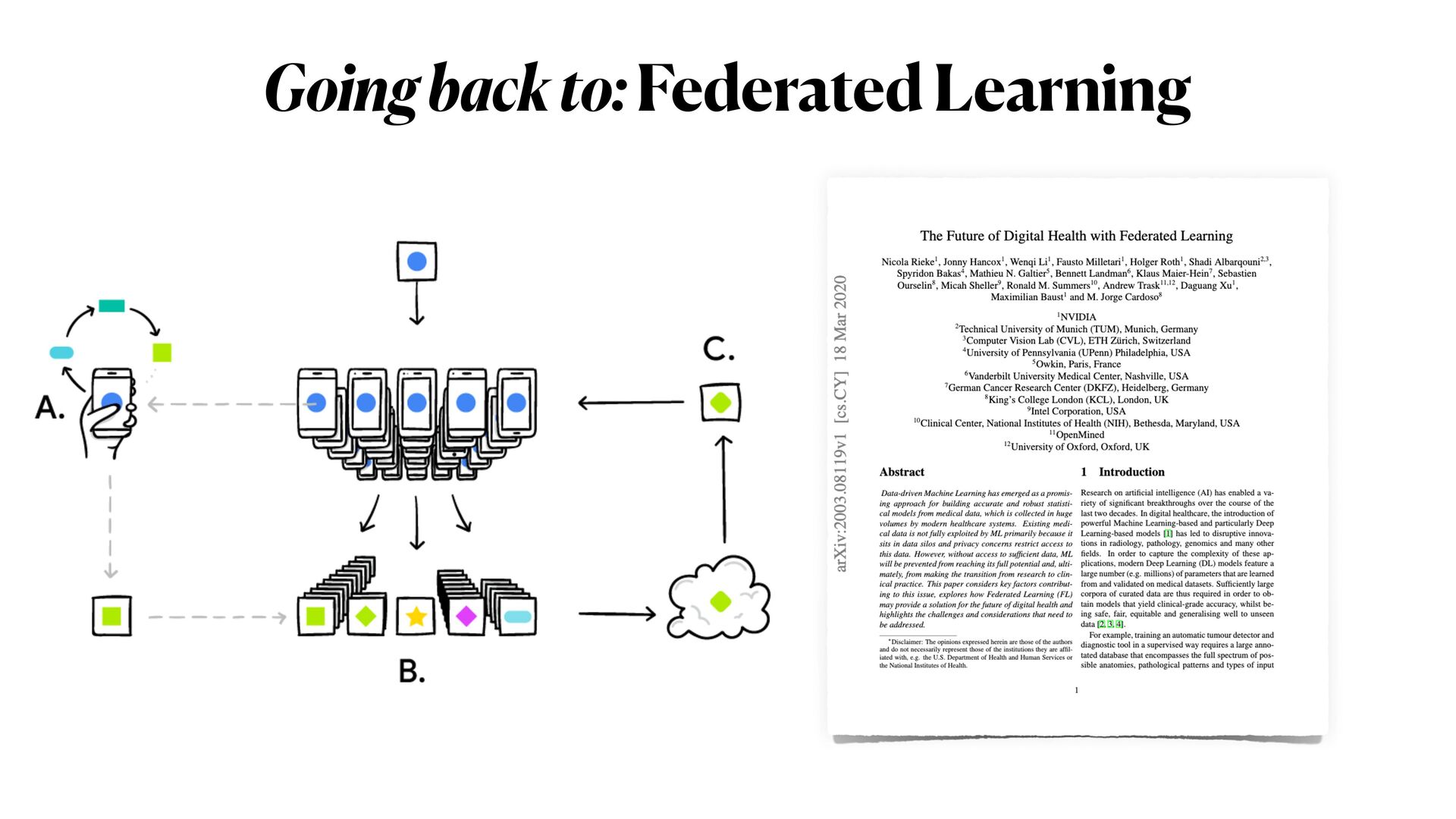
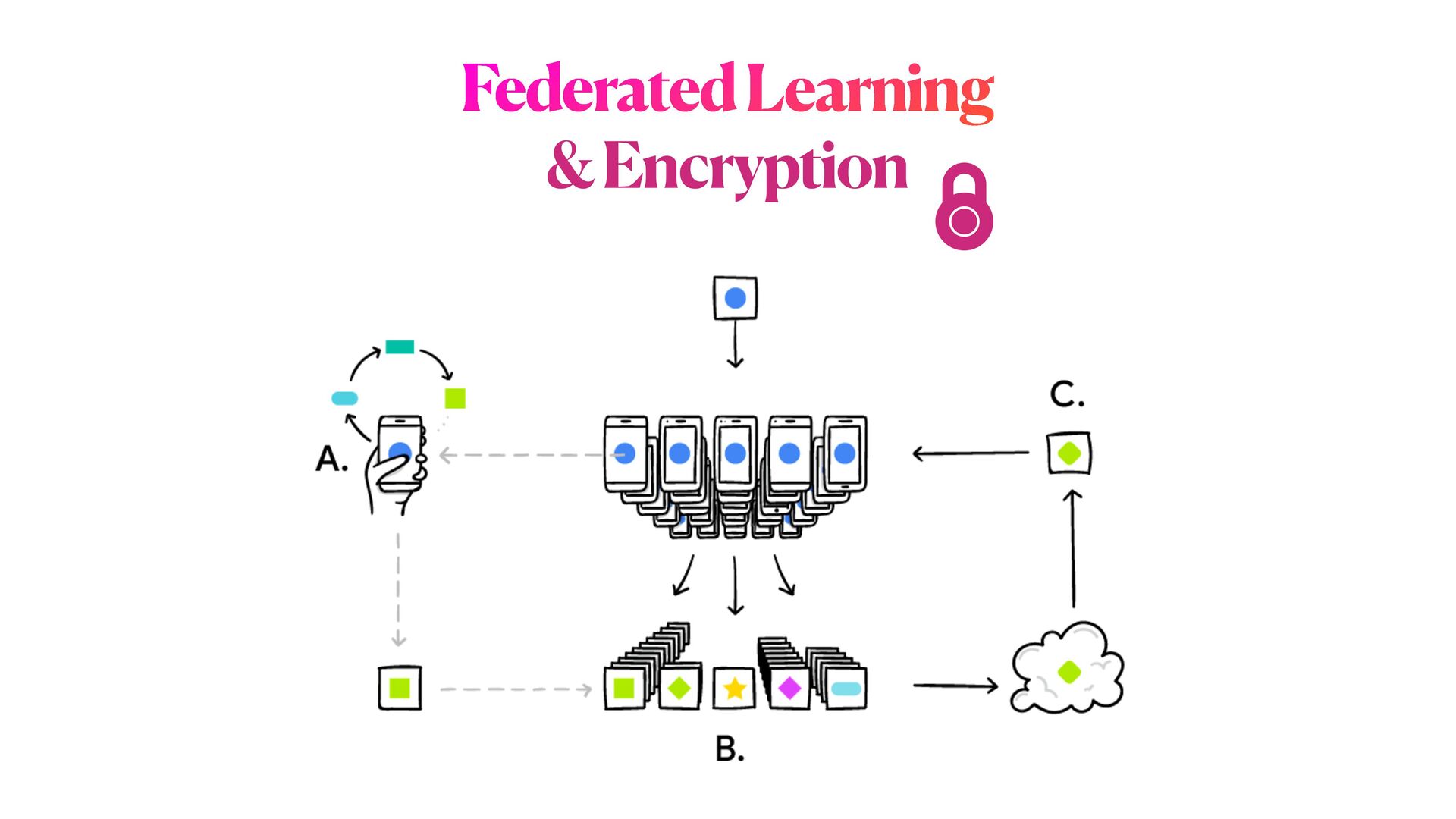
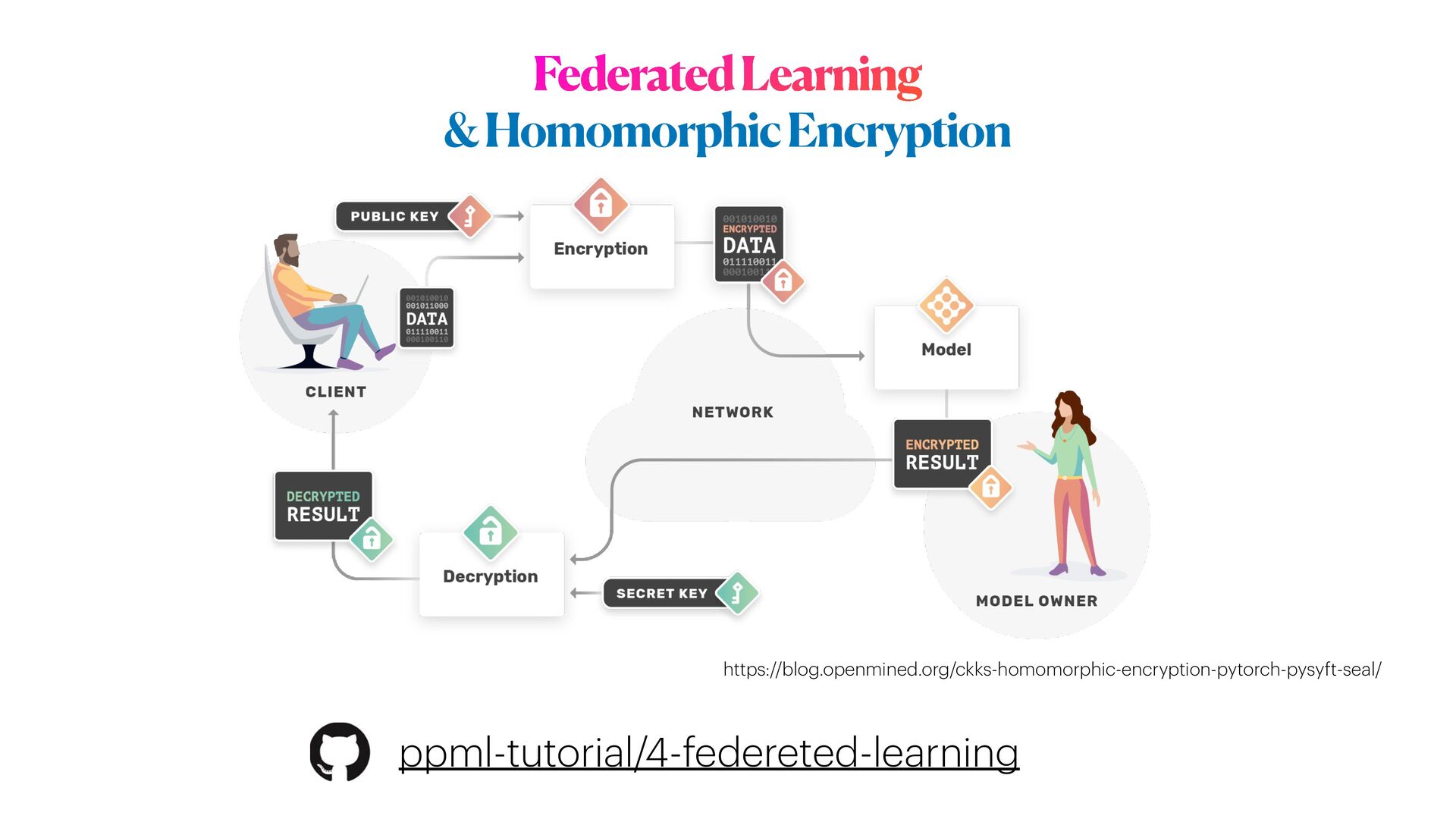
This workshop will be mainly organised in **two parts**. In the first part, we will explore one example of ML model exploitation (i.e. _inference attack_ ) to reconstruct original data from a trained model, and we will then see how **differential privacy** can help us protecting the privacy of our model, with _minimum disruption_ to the original pipeline. In the second part of the workshop, we will examine a more complicated ML scenario to train Deep learning networks on encrypted data, with specialised _distributed federated_ _learning_ strategies.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}