Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
ACL読み会2020_Jointly Masked Sequence-to-Sequence ...
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
maskcott
August 07, 2020
Research
27
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
ACL読み会2020_Jointly Masked Sequence-to-Sequence Model for Non-Autoregressive Neural Machine Translation
maskcott
August 07, 2020
More Decks by maskcott
See All by maskcott
論文紹介2022後期(EMNLP2022)_Towards Opening the Black Box of Neural Machine Translation: Source and Target Interpretations of the Transformer
maskcott
0
77
論文紹介2022後期(ACL2022)_DEEP: DEnoising Entity Pre-training for Neural Machine Translation
maskcott
0
43
PACLIC2022_Japanese Named Entity Recognition from Automatic Speech Recognition Using Pre-trained Models
maskcott
0
46
WAT2022_TMU NMT System with Automatic Post-Editing by Multi-Source Levenshtein Transformer for the Restricted Translation Task of WAT 2022
maskcott
0
53
論文紹介2022前期_Redistributing Low Frequency Words: Making the Most of Monolingual Data in Non-Autoregressive Translation
maskcott
0
66
論文紹介2021後期_Analyzing the Source and Target Contributions to Predictions in Neural Machine Translation
maskcott
0
83
WAT2021_Machine Translation with Pre-specified Target-side Words Using a Semi-autoregressive Model
maskcott
0
60
NAACL/EACL読み会2021_NEUROLOGIC DECDING: (Un)supervised Neural Text Generation with Predicate Logic Constraints
maskcott
0
47
論文紹介2021前期_Bilingual Dictionary Based Neural Machine Translation without Using Parallel Sentences
maskcott
0
54
Other Decks in Research
See All in Research
英語教育 “研究” のあり方:学術知とアウトリーチの緊張関係
terasawat
1
1k
第64回CV・PRML勉強会 論文紹介:Linguistic Priors for Visual Decoupling: Towards Symmetric Vision-Brain Alignment
sokikatayama
0
120
敵対生成プロンプト同時探索による内省型プロンプト最適化
kinoue_smarthr
0
250
AIを叩き台として、 「検証」から「共創」へと進化するリサーチ
mela_dayo
0
290
Research Engineerという仕事 / Research Engineering: Bridging Research and Business
chck
1
220
[IR Reading 2026春 論文紹介] LLM-based Listwise Reranking under the Effect of Positional Bias (ECIR 2026) /IR-Reading-2026-Spring
koheishinden
PRO
0
160
LLM Compute Infrastructure Overview
karakurist
2
1.5k
AY 2026 Guide to Academic Writing Using Generative AI - Workshop
ks91
PRO
0
120
言語モデルから言語について語る際に押さえておきたいこと
eumesy
PRO
5
2.4k
LLMアプリケーションの透明性について
fufufukakaka
0
240
適応的スパムフィルタのための軽量な類似メッセージカウンタ / jsai2026-adaptive-spam-filter
monochromegane
0
3.9k
Data Visualization Tools in the Age of AI
flekschas
0
160
Featured
See All Featured
WENDY [Excerpt]
tessaabrams
11
38k
Building Applications with DynamoDB
mza
96
7.1k
Art, The Web, and Tiny UX
lynnandtonic
304
22k
Navigating the moral maze — ethical principles for Al-driven product design
skipperchong
2
400
Docker and Python
trallard
47
3.9k
Responsive Adventures: Dirty Tricks From The Dark Corners of Front-End
smashingmag
254
22k
More Than Pixels: Becoming A User Experience Designer
marktimemedia
3
450
Data-driven link building: lessons from a $708K investment (BrightonSEO talk)
szymonslowik
1
1.1k
The Illustrated Guide to Node.js - THAT Conference 2024
reverentgeek
1
400
Making the Leap to Tech Lead
cromwellryan
135
9.9k
4 Signs Your Business is Dying
shpigford
187
22k
The State of eCommerce SEO: How to Win in Today's Products SERPs - #SEOweek
aleyda
2
11k
Transcript
1
Abstract ・様々な自然言語処理のタスクで注目を集めているmasked languageモデルをseq2seqモデルに適用し た ”jointly masked seq2seq” モデルを提案しNATに適用した ・具体的にはトレーニング時にエンコーダーへの入力をマスキングし、デコーダーではn-gramのロス関数 で連続的にマスキングすることで学習するもの
・ WMT14 en-de/de-en で 27.69/32.24 のBLEUスコアを達成し、自己回帰モデルの5倍の速度を実現 2
Introduction ・NATモデルの精度が落ちる理由として次の二つが先行研究で主に挙げられている 1.ソース側の情報が適切にエンコードされていないこと 2.デコーダーがタスクをうまく処理できず、繰り返しや長文における性能が低下したりする →NATモデルのエンコーダーとデコーダーの機能を実験的に研究するとエンコーダーの方がデコーダーよ りも翻訳結果に影響を与えることが判明 ・BERTに倣ってエンコーダ―でマスキングを行うことでエンコーダーを徹底的に学習させる ・デコーダーの入力に対して連続的なマスキングを行う手法とn-gramロス関数の実装を提案 ・二つの方法を統合してjointly masked
seq2seqモデルを実装 3
Related Work ・Non-Autoregressive Machine Translation ターゲット文の文脈情報を捨てて全トークンを独立に出力することによって、ターゲット文の文長nに依存 しない、O(k)の計算量での翻訳が可能になった(kは定数) ・Masked Language Model
・BERT (Devlin et al., 2018)で提案され、トランスフォーマーのエンコーダー側を扱うモデル ・XLM (Lample and Conneau, 2019)では、ソース文とターゲット文をコンキャットしてエンコーダーの入 力とすることでクロスリンガルな情報を学習した ・MASS (Song et al., 2019)ではseq2seqにおける事前学習が提案されたが、モノリンガルなフレーム ワークだった →この論文ではATモデルのaccuracyとNATの推論速度を維持できるようなモデルに基づいた seq2seq のフレームワークでクロスリンガルな情報を扱う 4
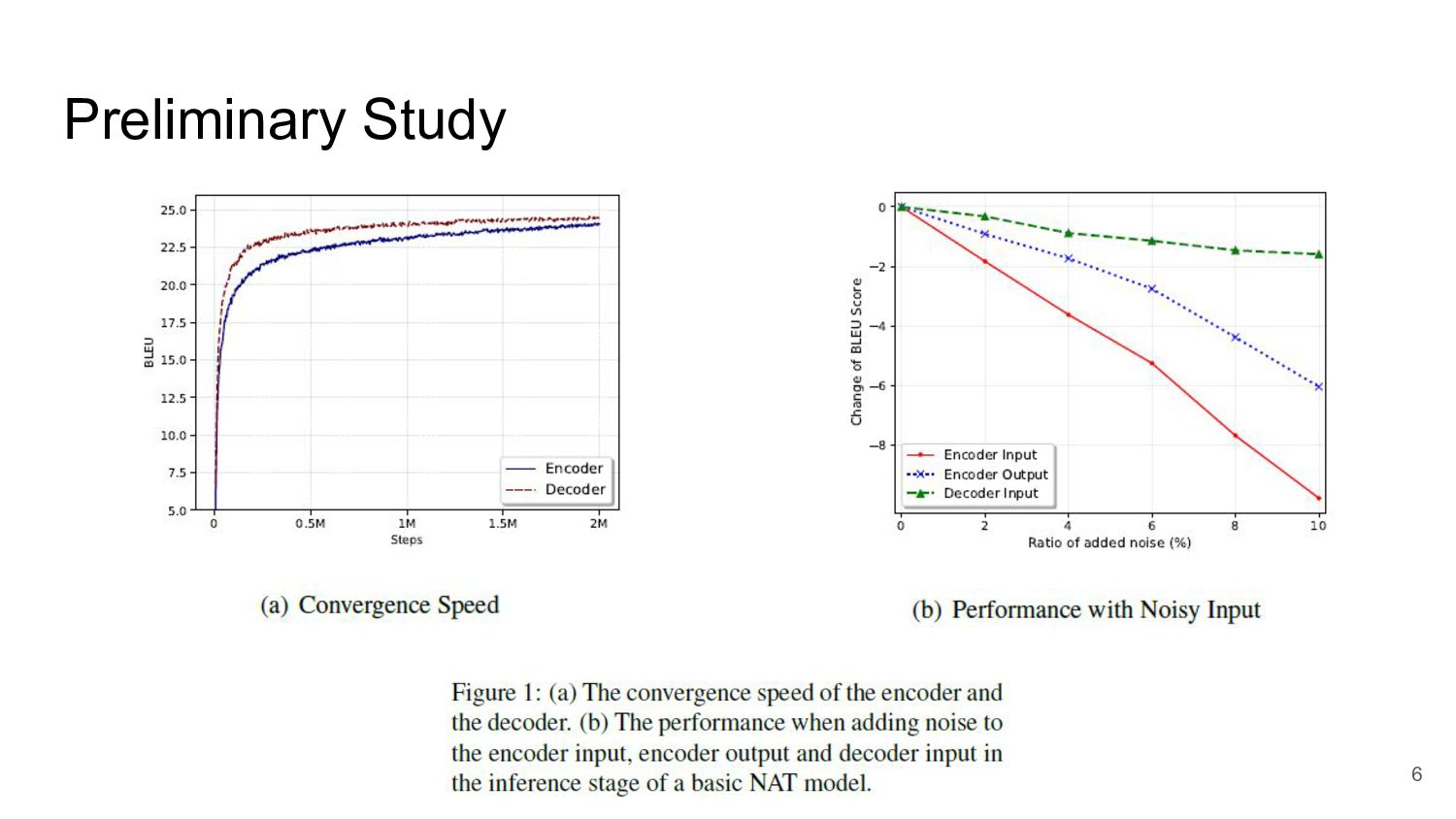
Preliminary Study NATにおけるエンコーダーデコーダーモデルの構造を探るための実験的な研究 Nonautoregressive neural machine translation(Gu et al., 2017)で提案されたベーシックなNATモデル
を利用 データセット: IWSLT14 German to English エンコーダーとデコーダーの重要性を3つの観点から調べる 5
Preliminary Study 6
Methodology 問題設定 ・ソース文とターゲット文 ロス関数 エンコーダーマスキング 個の単語をランダムに選択して とする のうち80%を[mask], 10%をvocabからランダムに別の単語に置き換える 置き換えた後の文を とする
ロス関数 7
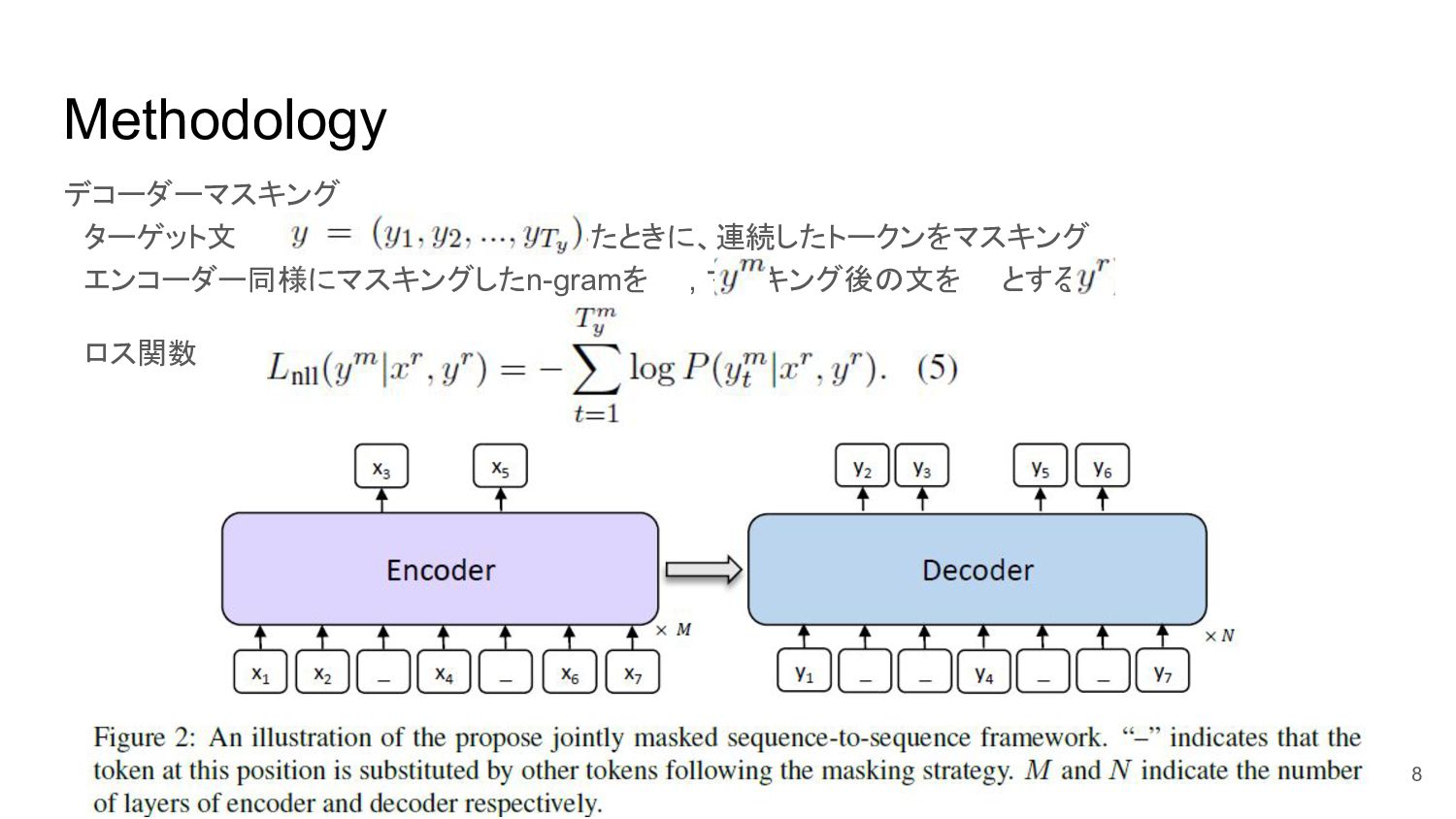
Methodology デコーダーマスキング ターゲット文 が与えられたときに、連続したトークンをマスキング エンコーダー同様にマスキングしたn-gramを , マスキング後の文を とする ロス関数 8
Methodology 連続的なn-gramベースのロス関数(Ma et al., 2018; Shao et al., 2018, 2019)も利用(デコーダー)
与えられるn-gram 9
Methodology 目的関数 デコード方法 エンコーダーの入力に特殊なトークンを加えて、そのトークンに相当する隠れベクトルから文長を予測する (Ghazvininejad et al., 2019) この文長に関するロスも上式に加えて計算 文長が決まったらターゲット文を[mask]で初期化してデコーダーに入力
出力のうち確率の低かった単語を選び、隣接する単語とともにマスクをしてデコーダーに入力を繰り返す (選ぶ単語の数は線形関数的に減衰させる) 事前に決めたイテレーション数回すか結果が変わらなくなったら終了 10
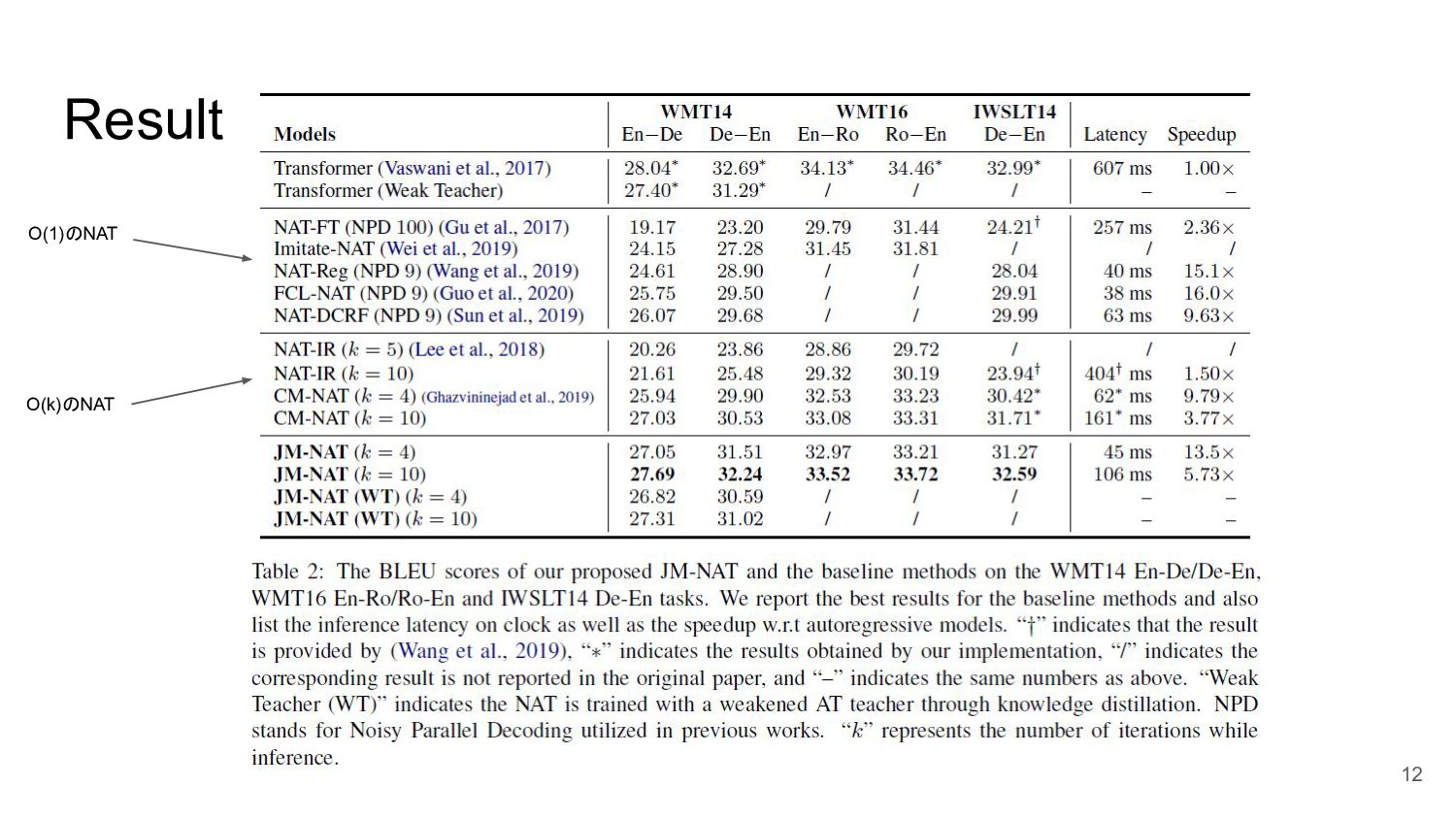
実験 データセット IWSLT14 German→English WMT16 English↔Romanian WMT14 English↔German Moses (Koehn
et al.,2007)でトークナイズ, Byte-Pair Encoding (BPE) (Sennrich et al., 2015)をかけて ソース文、ターゲット文で32kのvocabularyになった モデル Transformer (Vaswani et al., 2017) (IWSLTにはsmall, その他にはbase) NATモデル O(1)で推論できるものが5種類、O(k)で推論できるのを2種類先行研究から用意 sequence-level knowledge distillation(Kim and Rush, 2016)を適用 11
Result 12 O(1)のNAT O(k)のNAT
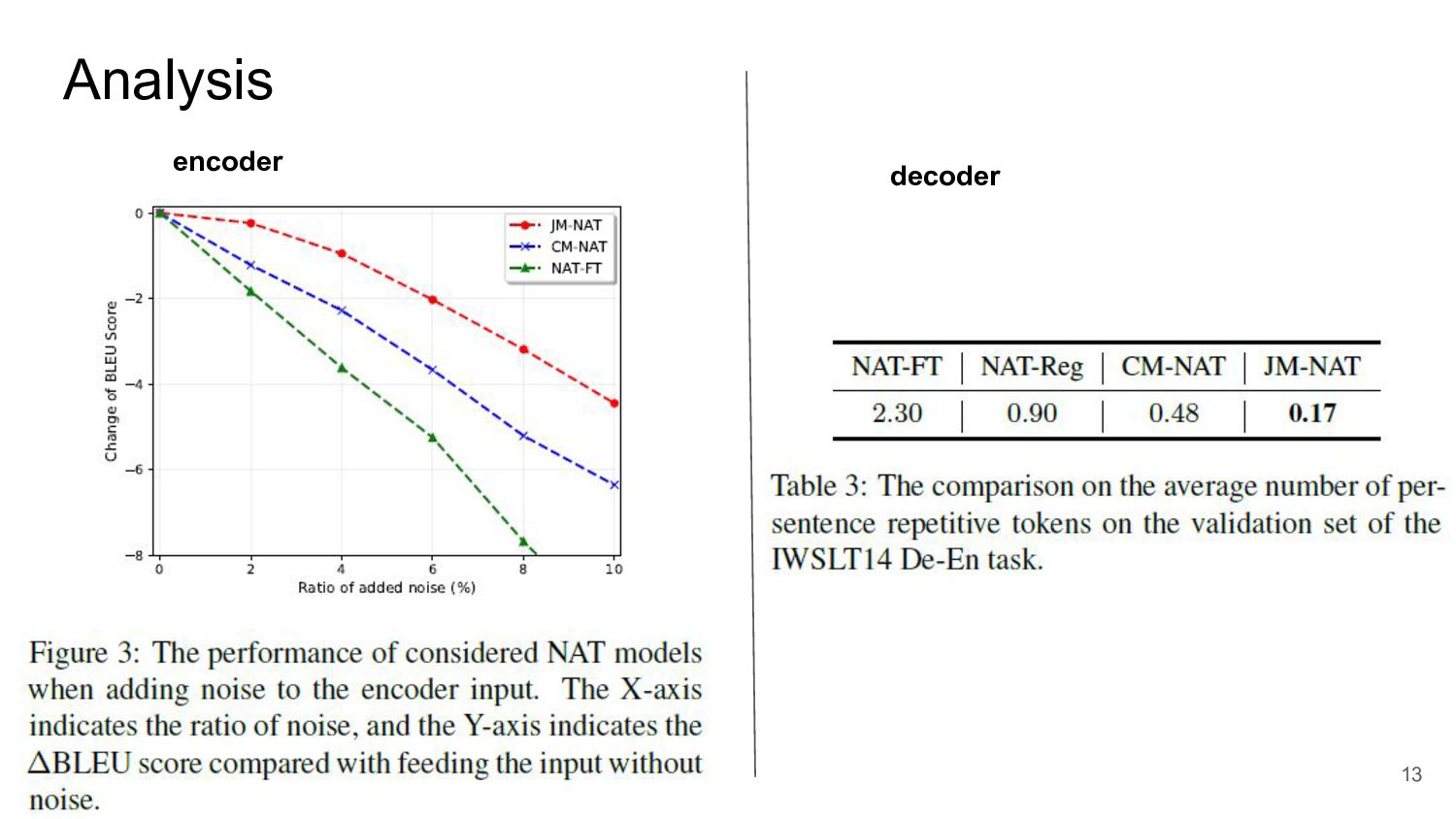
Analysis 13 encoder decoder
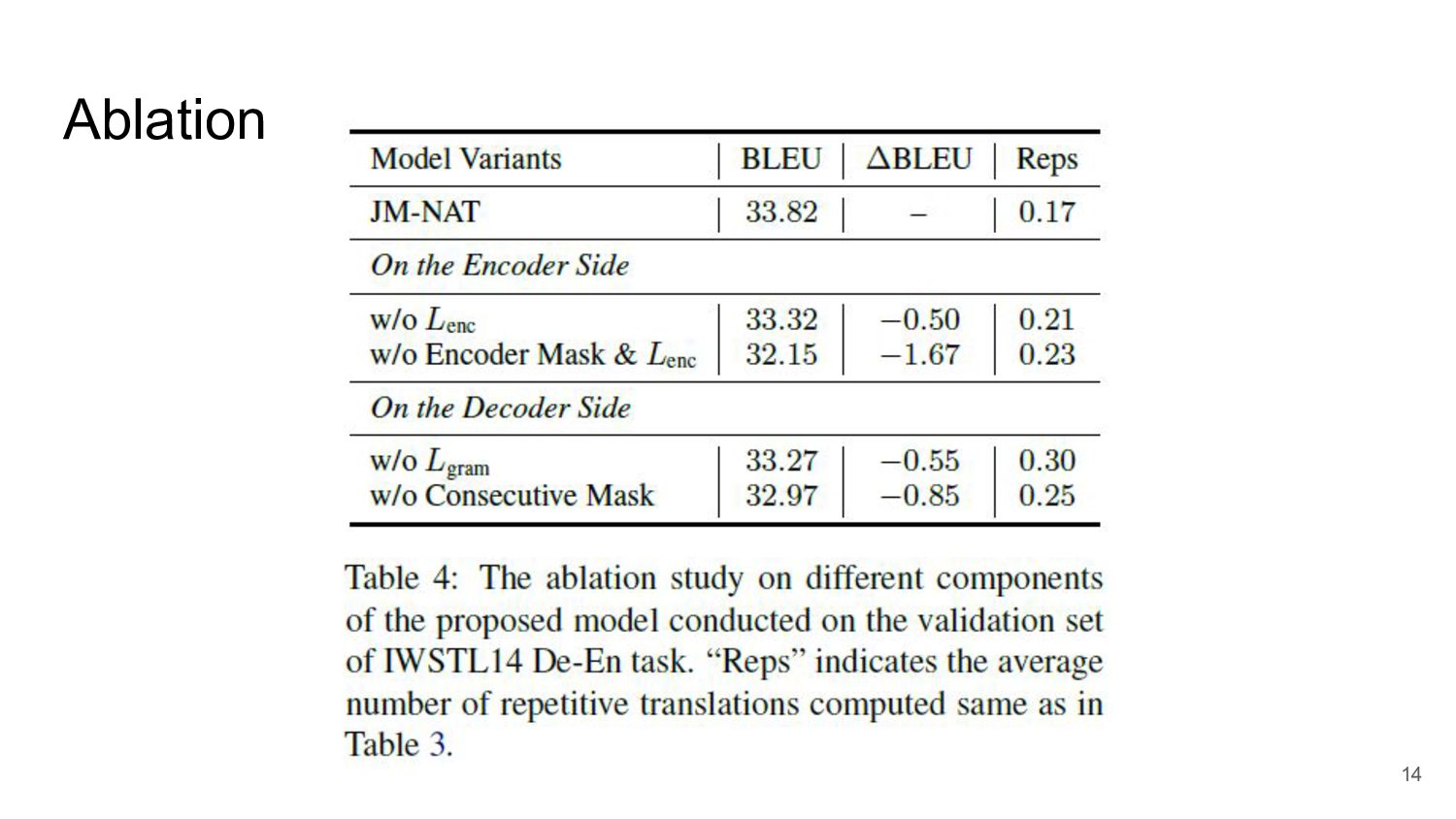
Ablation 14
Conclusion NATモデルの機能を実験的に調べ、エンコーダ―の学習の重要性を発見した エンコーダーの入力にマスキングを施しロス関数に基づく予測を提案することでエンコー ダ―の学習を向上させた デコーダー側ではn-gram単位のマスキングとn-gramロス関数を提案し、連続して出力 してしまう問題を和らげた 比較対象のベースラインにした全てのNATモデルよりも提案手法は優れたスコアを出 し、ATモデルの5倍以上の推論速度を達成した 15
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Methodology 問題設定 ・ソース文とターゲット文 ロス関数 エンコーダーマスキング 個の単語をランダムに選択して とする のうち80%を[mask], 10%をvocabからランダムに別の単語に置き換える 置き換えた後の文を とする](https://files.speakerdeck.com/presentations/bf2963bb20394f53ae1fc9370571e455/slide_6.jpg){kind=link}
{kind=link}
{kind=link}
![Methodology 目的関数 デコード方法 エンコーダーの入力に特殊なトークンを加えて、そのトークンに相当する隠れベクトルから文長を予測する (Ghazvininejad et al., 2019) この文長に関するロスも上式に加えて計算 文長が決まったらターゲット文を[mask]で初期化してデコーダーに入力](https://files.speakerdeck.com/presentations/bf2963bb20394f53ae1fc9370571e455/slide_9.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}