Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
論文紹介2020前期_UNDERSTANDING KNOLEDGE DISTILLATION ...
Search
maskcott
July 08, 2020
Research
17
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
論文紹介2020前期_UNDERSTANDING KNOLEDGE DISTILLATION IN NON-AUTOREGRESSIVEMACHINE TRANSLATION
maskcott
July 08, 2020
More Decks by maskcott
See All by maskcott
論文紹介2022後期(EMNLP2022)_Towards Opening the Black Box of Neural Machine Translation: Source and Target Interpretations of the Transformer
maskcott
0
77
論文紹介2022後期(ACL2022)_DEEP: DEnoising Entity Pre-training for Neural Machine Translation
maskcott
0
43
PACLIC2022_Japanese Named Entity Recognition from Automatic Speech Recognition Using Pre-trained Models
maskcott
0
46
WAT2022_TMU NMT System with Automatic Post-Editing by Multi-Source Levenshtein Transformer for the Restricted Translation Task of WAT 2022
maskcott
0
53
論文紹介2022前期_Redistributing Low Frequency Words: Making the Most of Monolingual Data in Non-Autoregressive Translation
maskcott
0
66
論文紹介2021後期_Analyzing the Source and Target Contributions to Predictions in Neural Machine Translation
maskcott
0
83
WAT2021_Machine Translation with Pre-specified Target-side Words Using a Semi-autoregressive Model
maskcott
0
60
NAACL/EACL読み会2021_NEUROLOGIC DECDING: (Un)supervised Neural Text Generation with Predicate Logic Constraints
maskcott
0
47
論文紹介2021前期_Bilingual Dictionary Based Neural Machine Translation without Using Parallel Sentences
maskcott
0
54
Other Decks in Research
See All in Research
Research Engineerという仕事 / Research Engineering: Bridging Research and Business
chck
1
220
討議:RACDA設立30周年記念都市交通フォーラム2026
trafficbrain
0
1k
多様なデータを許容し学習し続ける模倣学習 / Advanced Imitation Learning for VLA
prinlab
0
230
NII S. Koyama's Lab Research Overview AY2026
skoyamalab
0
350
論文紹介:HalluCitation Matters
wasyro
0
110
老舗ものづくり企業でリサーチが変革を起こすまで - 三菱重工DXの実践
skydats
0
200
人間中心の意思決定支援AI
yukinobaba
PRO
6
3.1k
進学校の生徒にはア行の苗字が多いのか
ozekinote
0
460
世界モデルにおける分布外データ対応の方法論
koukyo1994
7
2.2k
Fukui Shibiten 39 - AI Art
butchi
0
130
AIを叩き台として、 「検証」から「共創」へと進化するリサーチ
mela_dayo
0
290
Claude Code × autoresearch 実践
mathbullet
0
170
Featured
See All Featured
Information Architects: The Missing Link in Design Systems
soysaucechin
0
980
The Organizational Zoo: Understanding Human Behavior Agility Through Metaphoric Constructive Conversations (based on the works of Arthur Shelley, Ph.D)
kimpetersen
PRO
0
370
Facilitating Awesome Meetings
lara
57
7k
30 Presentation Tips
portentint
PRO
1
330
Responsive Adventures: Dirty Tricks From The Dark Corners of Front-End
smashingmag
254
22k
RailsConf & Balkan Ruby 2019: The Past, Present, and Future of Rails at GitHub
eileencodes
141
35k
Bootstrapping a Software Product
garrettdimon
PRO
307
120k
HU Berlin: Industrial-Strength Natural Language Processing with spaCy and Prodigy
inesmontani
PRO
0
420
How to Talk to Developers About Accessibility
jct
2
260
Lightning talk: Run Django tests with GitHub Actions
sabderemane
0
200
Reality Check: Gamification 10 Years Later
codingconduct
0
2.2k
Building Better People: How to give real-time feedback that sticks.
wjessup
370
20k
Transcript
紹介者: B4 今藤 誠⼀郎 2020/7/8 @論⽂紹介
概要 既存の⾮⾃⼰回帰モデル(NAT)は知識蒸留を⽤いたモデルになっている 知識蒸留というものが経験的にNATの正解率の向上に有効であることが確 認されているがその理由は明らかになっていない 知識蒸留がなぜNATモデルの学習に重要なのかを実験 →データの複雑さを軽減し、出⼒データをモデル化するのに役⽴つ +NATモデルの性能と知識蒸留後のデータの複雑さに強い相関関係 NATモデルの性能を向上させるためにデータセットの複雑さを変化させら れるいくつかのアプローチを提案
導⼊ 知識蒸留とは... 訓練データのターゲット⽂を事前訓練済みのATモデルの出⼒に置き換える ほぼ全ての既存NATモデルの学習における重要な要素の⼀つとなっている →訓練データのモード(⼊⼒に対する出⼒の種類)の削減がNATの訓練にい いのではないかという仮定 →直感的なイメージに過ぎず、厳密に検証されていない
導⼊ 検証が不⼗分ゆえの3つの重要な未解決問題 ・どのようにモードが削減されていて、どのようにその削減を量的に計測 できるのか、そしてなぜ削減がNATモデルの性能を引き上げるのか? ・NAT(⽣徒モデル)とAT(教師モデル)の関係はどうなっているのか?NAT モデルによって蒸留データの種類を変える⽅がいいのか? ・知識蒸留を⾏う上でNATの性能は教師モデルであるATの選択に⼤きく左 右されるが、標準的なATモデルとの性能差をさらに縮める⽅法はないのか
導⼊ 様々な種類のAT, NATの分析を⾏い、知識蒸留の理解を深めるために3つ の貢献 ・⼈⼿のデータセット上で蒸留によってどのようモードが減少するのかを 明⽰的に可視化する データセットの複雑さや忠実さを測定するメトリクスも提案する ・4つの教師モデルと6つの⽣徒モデルに対して様々なアーキテクチャを持 つ体系的な解析を⾏った ・モデルの能⼒に適合する蒸留データの複雑さをさらに調整するアプロー
チを提案
背景 標準的な⾮⾃⼰回帰モデルは⼀度デコーダーを通すだけで⽂を⽣成する →単⼀の⼊⼒⽂に対して複数の翻訳があるため出⼒トークン間の依存関係 系を補⾜できない(先⾏研究でマルチモーダル問題と呼ばれる) →トークンを何度も出⼒するなどのミスをする傾向にある 処理能⼒を向上させるためNATには様々なアプローチが取り⼊れられてい る →ATと競えるような性能を達成しているものはいづれの場合も事前学習を ⾏ったATモデルの蒸留データを本来のトレーニングセットの代わりに使っ ている
実験 知識蒸留がどのようにNATの精度を上げているのか 学習データに複数のモードを明⽰的に含めたデータセットを⽤いて出⼒ データにおけるマルチモダリティによるNATの難しさを調査 データセット ・Europarl parallel corpusよりEn-De, En-Fr, En-Es
の3つの⾔語ペア ・すべての⾔語にアラインメントされた⽂を抽出し、En-De/Fr/Esコーパ スを作成 →3つの明⽰的な出⼒モードが形成される ・翻訳する際にどの⾔語に翻訳するかという信号を付加しない
実験 知識蒸留がどのようにNATの精度を上げているのか モデル ・データセットをコンキャットしてATとNATを学習させて⽐較 ・AT: 標準的なTransformerモデル(Vaswani et al, 2017) ・NAT:
(Gu et al, 2018)のモデルを単純にしたもの (デコーダーの⼊⼒はエンコーダーの⼊⼒を単純にコピー、 ⽂⻑を予測出来るように学習) 両モデル300,000ステップで最尤推定を⽤いて学習した後、英⽂を検証、 テストセットとする
結果 各出⼒がどの⾔語類に属しているかの確率をプロット ⾔語クラスliの中で単語yの出現頻度 ⼀様分布に従うと仮定
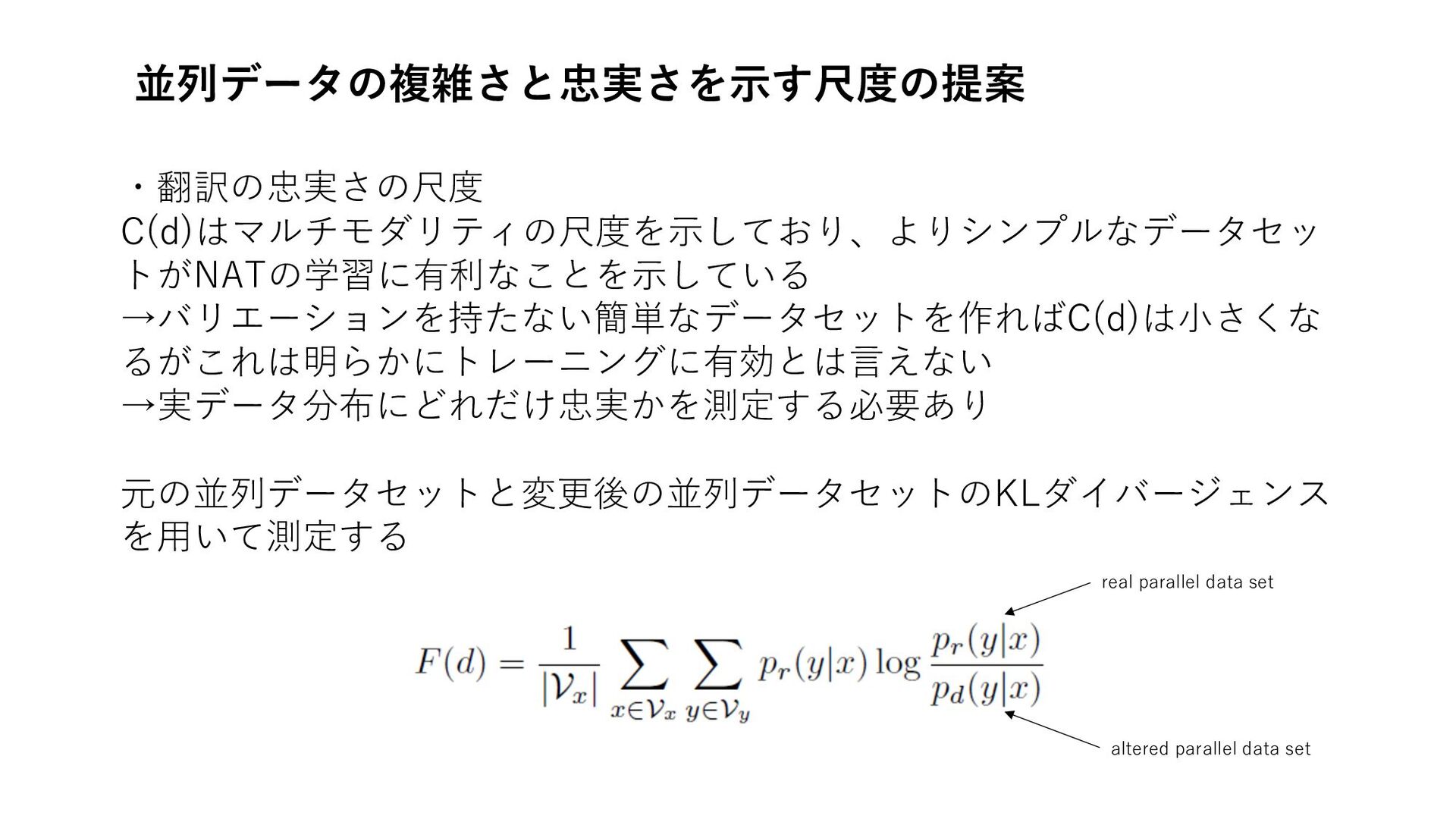
並列データの複雑さ(Complexity)と忠実さ(faithfulness)を⽰す尺度の提案 ・翻訳の複雑さの尺度
並列データの複雑さと忠実さを⽰す尺度の提案 ・翻訳の忠実さの尺度 C(d)はマルチモダリティの尺度を⽰しており、よりシンプルなデータセッ トがNATの学習に有利なことを⽰している →バリエーションを持たない簡単なデータセットを作ればC(d)は⼩さくな るがこれは明らかにトレーニングに有効とは⾔えない →実データ分布にどれだけ忠実かを測定する必要あり 元の並列データセットと変更後の並列データセットのKLダイバージェンス を⽤いて測定する real
parallel data set altered parallel data set
実験 知識蒸留がNATモデルにどのように影響するのか 異なる教師モデルから得られたデータで学習したNATモデルを⽐較 データセット:WMT14 English-German (En-De) 検証セットにnewstest2013 テストセットにnewstest2014 BPE(Sennrich et
al., 2016)でトークナイズされた37,000語を学習 ATモデル tiny, small, base, bigの4種類を⽤いる いづれもTransformerに基づいたものでパラメータを変えている ⼩さい⽅が弱い教師モデルといえる トレーニングにはAdam optimizer (Kingma & Ba, 2014)を⽤いる 訓練後にビームサイズ5で訓練セットをデコードして 新しい並列コーパスを作成
実験 知識蒸留がNATモデルにどのように影響するのか NATモデル 6種類を⽤いる
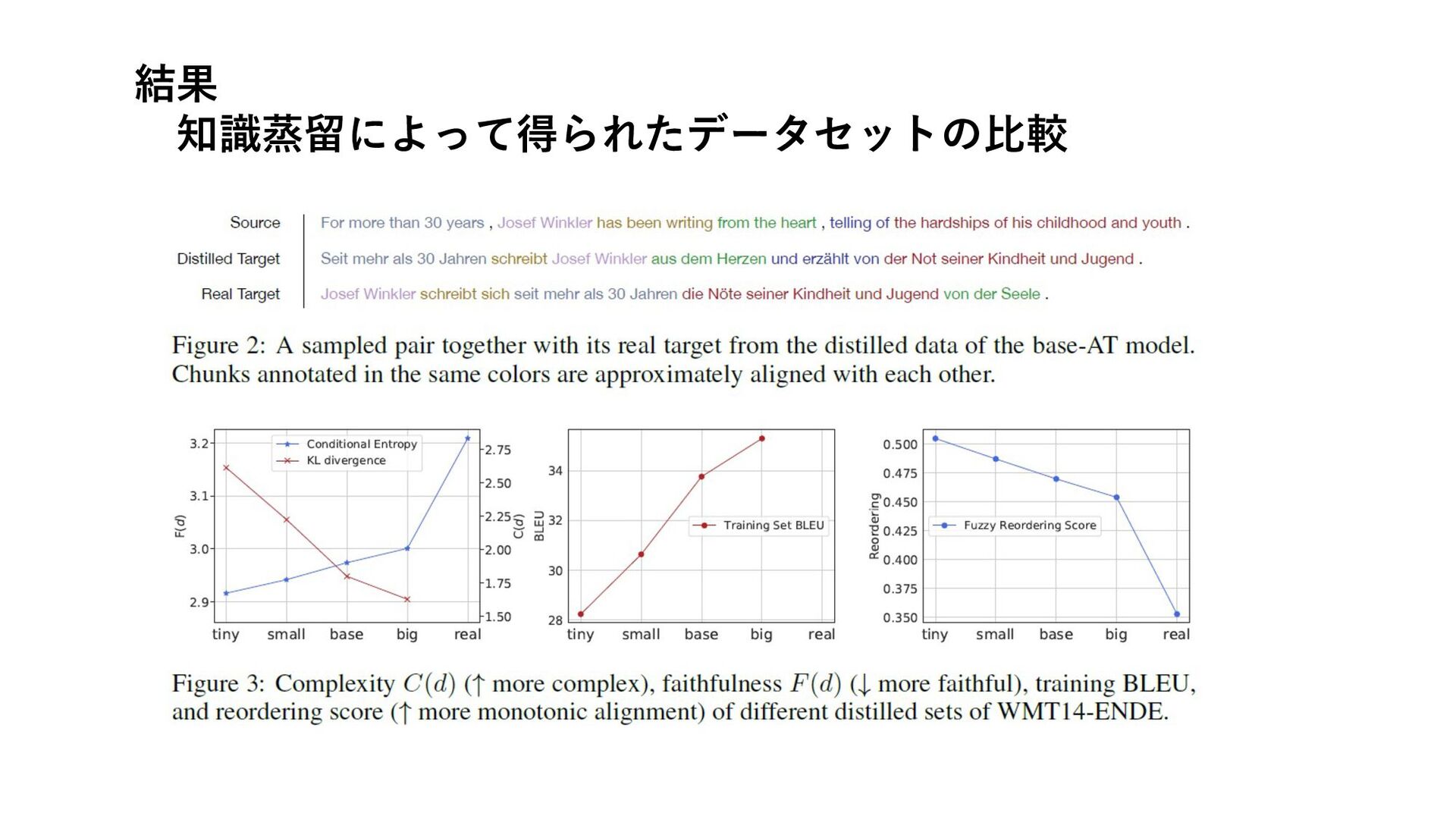
結果 知識蒸留によって得られたデータセットの⽐較
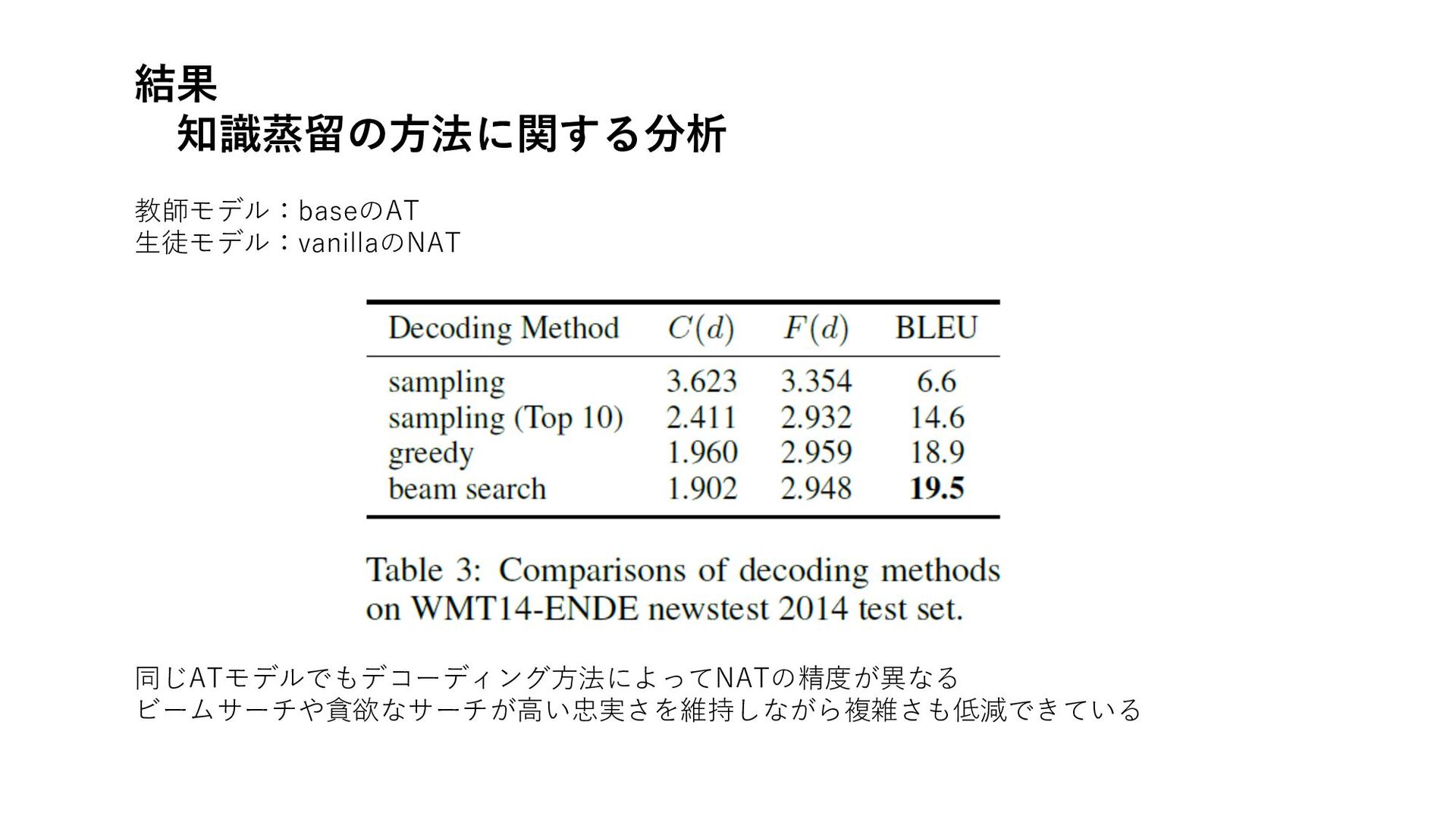
結果 知識蒸留の⽅法に関する分析 教師モデル:baseのAT ⽣徒モデル:vanillaのNAT 同じATモデルでもデコーディング⽅法によってNATの精度が異なる ビームサーチや貪欲なサーチが⾼い忠実さを維持しながら複雑さも低減できている
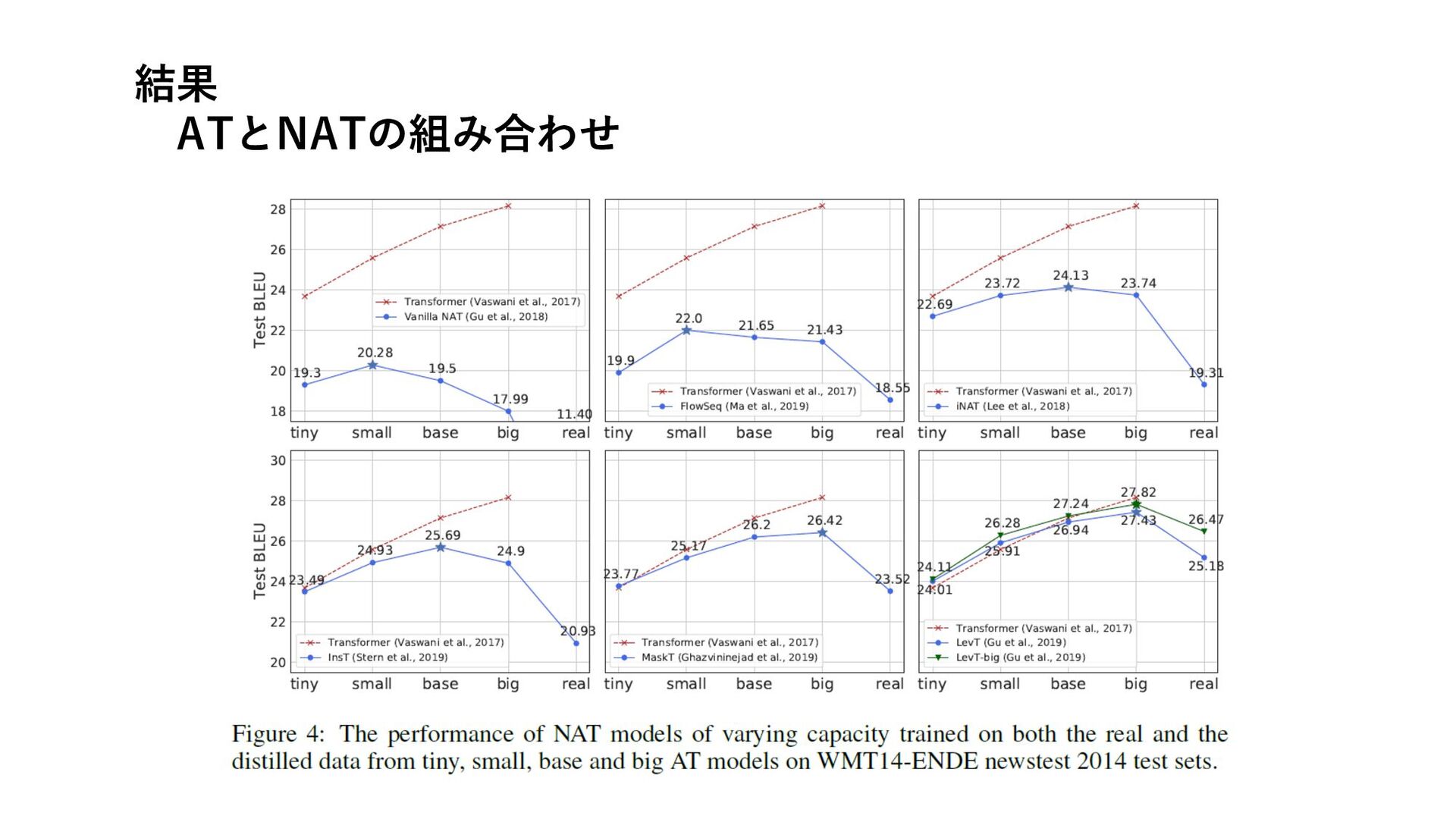
結果 ATとNATの組み合わせ
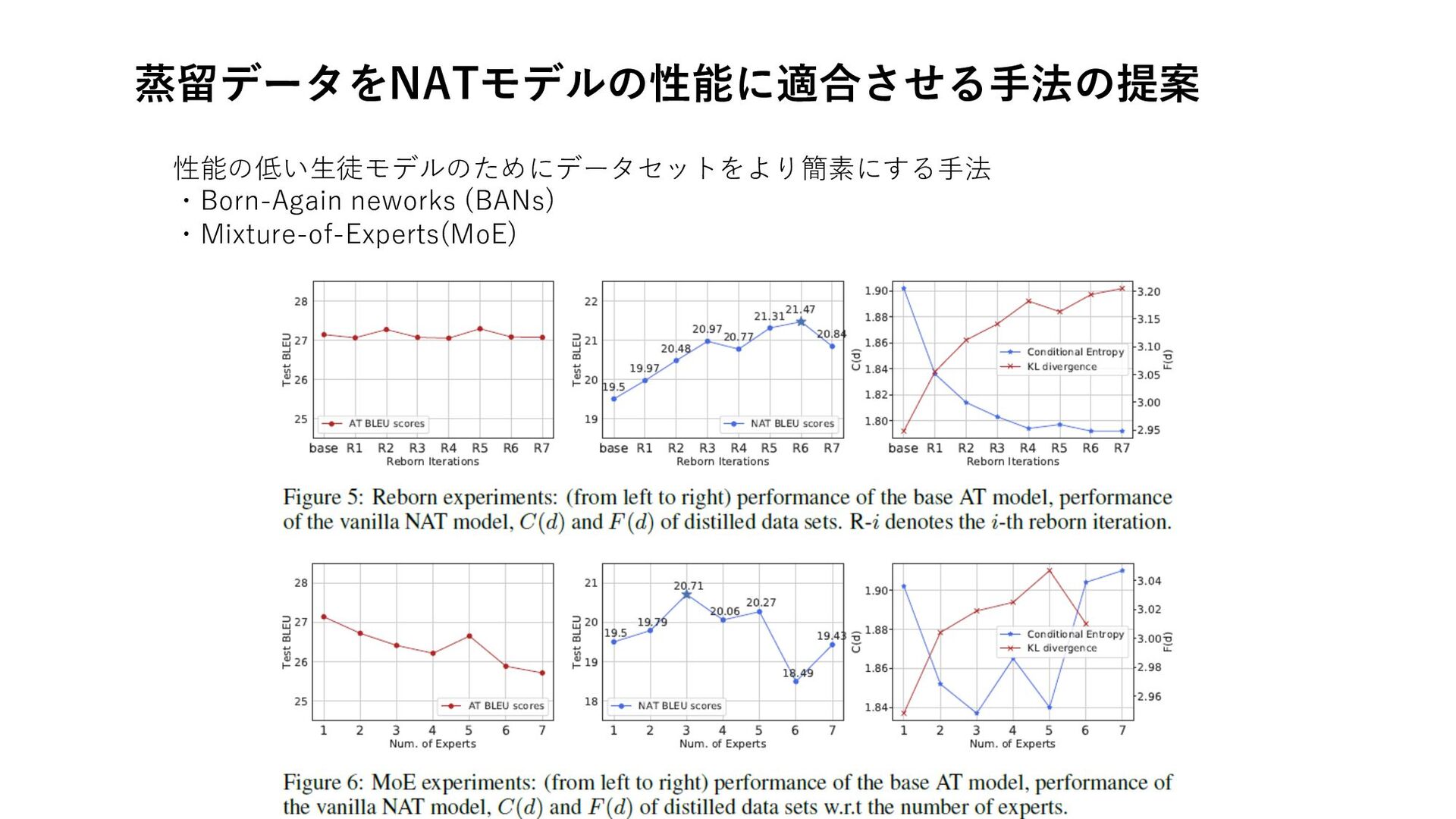
蒸留データをNATモデルの性能に適合させる⼿法の提案 性能の低い⽣徒モデルのためにデータセットをより簡素にする⼿法 ・Born-Again neworks (BANs) ・Mixture-of-Experts(MoE)
蒸留データをNATモデルの性能に適合させる⼿法の提案 性能の⾼い⽣徒モデルのためにデータセットの忠実さを上げる⼿法 ・Sequence-Level Interpolation
Conclusion 知識蒸留がNATの性能を⼤きく上げるのはデータセットの複雑さ、マルチモダリティを削 減していることによるものであることを系統的に⽰した 性能の異なるATモデル、広範なNATモデルを⽤いて実験をし、さらにデータセットの複雑 さを定量的に測定するメトリクスを定義した →より⾼性能なNATほどより複雑な蒸留データを必要とし、より良い性能が引き出せる より良いパフォーマンスを引き出せるように、NATの性能に合った蒸留データの複雑さを 調整するテクニックを紹介
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}