Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
NLP2015-大会報告会
Search
MIKAMI-YUKI
March 23, 2015
Education
65
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
NLP2015-大会報告会
MIKAMI-YUKI
March 23, 2015
More Decks by MIKAMI-YUKI
See All by MIKAMI-YUKI
2016年_年次大会_発表資料
mikamiy
0
140
文献紹介_10_意味的類似性と多義解消を用いた文書検索手法
mikamiy
0
350
文献紹介_9_コーパスに基づく動詞の多義解消
mikamiy
0
140
文献紹介_8_単語単位による日本語言語モデルの検討
mikamiy
0
100
文献紹介_7_自動獲得した未知語の読み・文脈情報による仮名漢字変換
mikamiy
0
120
文献紹介_6_複数の言語的特徴を用いた日本語述部の同義判定
mikamiy
0
120
文献紹介_5_マイクロブログにおける感情・コミュニケーション・動作タイプの推定に基づく顔文字の推薦
mikamiy
0
160
文献紹介_4_結合価パターンを用いた仮名漢字変換候補の選択
mikamiy
0
420
文献紹介_3_絵本のテキストを対象とした形態素解析
mikamiy
1
430
Other Decks in Education
See All in Education
解決策を教えても次期リーダーは育たない ─ 器の発達に伴走するために / Partnering with leaders in their vertical development
matsu0228
1
560
Course Review - Lecture 13 - Next Generation User Interfaces (4018166FNR)
signer
PRO
0
2.3k
Curso de Consagração ao Sagrado Coração de Jesus - O Sagrado Coração na História (Aula 01)
cm_manaus
0
250
[2026前期火5] 論理学(京都大学文学部 前期 第8回)「正規化定理の証明」
yatabe
0
240
Info Session MSc Computer Science & MSc Applied Informatics
signer
PRO
0
300
AIには考えられないことを考えられる人になるために
iqbocchi
1
200
輻射安全管理系統2.0暨輻防e++學園平台說明會
aecrp
0
1.8k
Soluciones al examen de Geografía 2026. JUNIO (Convocatoria Ordinaria)
juanmartin2026
1
6.8k
2026年度春学期 統計学 第14回 分布についての仮説を検証する ― 仮説検定(1) (2026. 7. 2)
akiraasano
PRO
0
110
「答えを出す」より「わかる」をつくる
kzkmaeda
1
230
0513
cbtlibrary
0
220
2026年度春学期 統計学 第9回 確からしさを記述する ー 確率 (2026. 5. 28)
akiraasano
PRO
0
160
Featured
See All Featured
Impact Scores and Hybrid Strategies: The future of link building
tamaranovitovic
0
340
The MySQL Ecosystem @ GitHub 2015
samlambert
251
13k
Refactoring Trust on Your Teams (GOTO; Chicago 2020)
rmw
35
3.7k
Why You Should Never Use an ORM
jnunemaker
PRO
61
9.9k
Introduction to Domain-Driven Design and Collaborative software design
baasie
1
910
Abbi's Birthday
coloredviolet
3
8.8k
Save Time (by Creating Custom Rails Generators)
garrettdimon
PRO
32
3.9k
Building AI with AI
inesmontani
PRO
1
1.1k
My Coaching Mixtape
mlcsv
0
170
How to Talk to Developers About Accessibility
jct
2
420
The innovator’s Mindset - Leading Through an Era of Exponential Change - McGill University 2025
jdejongh
PRO
1
220
Pawsitive SEO: Lessons from My Dog (and Many Mistakes) on Thriving as a Consultant in the Age of AI
davidcarrasco
0
190
Transcript
長岡技術科学大学 三上侑城 2015年3月23日 年次大会報告会 自然言語処理研究室 1
特に気になった発表 B1-4:文節機能部の確率的書き換えによるキャラクタ性変換 B4-4:高次脳機能障害スクリーニング調査支援ツールの開発 2
B1-4: 文節機能部の確率的書き換えによるキャラクタ性変換 近年、ユーザの意図に応じて応答を返す対話型エージェントが普及して きている。 エージェントを会話相手とする際に、何らかの人物像(キャラクタ設定) を与えることで、より人間らしく、親しみやすいものとなる。 しかし、キャラクタ毎に人手で発話データを作成するのはコストがかかる。
そこで、特定のキャラクタらしさを持った発話の自動生成を目指している。 3
B1-4: 文節機能部の確率的書き換えによるキャラクタ性変換 4 処理の流れ
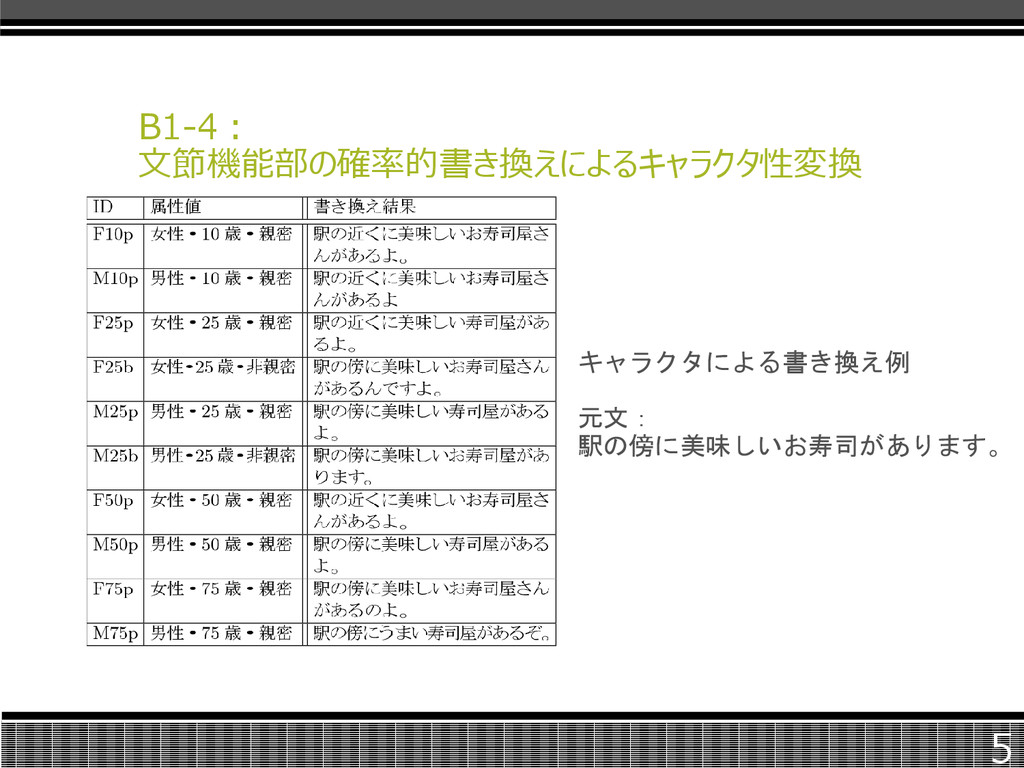
B1-4: 文節機能部の確率的書き換えによるキャラクタ性変換 5 キャラクタによる書き換え例 元文: 駅の傍に美味しいお寿司があります。
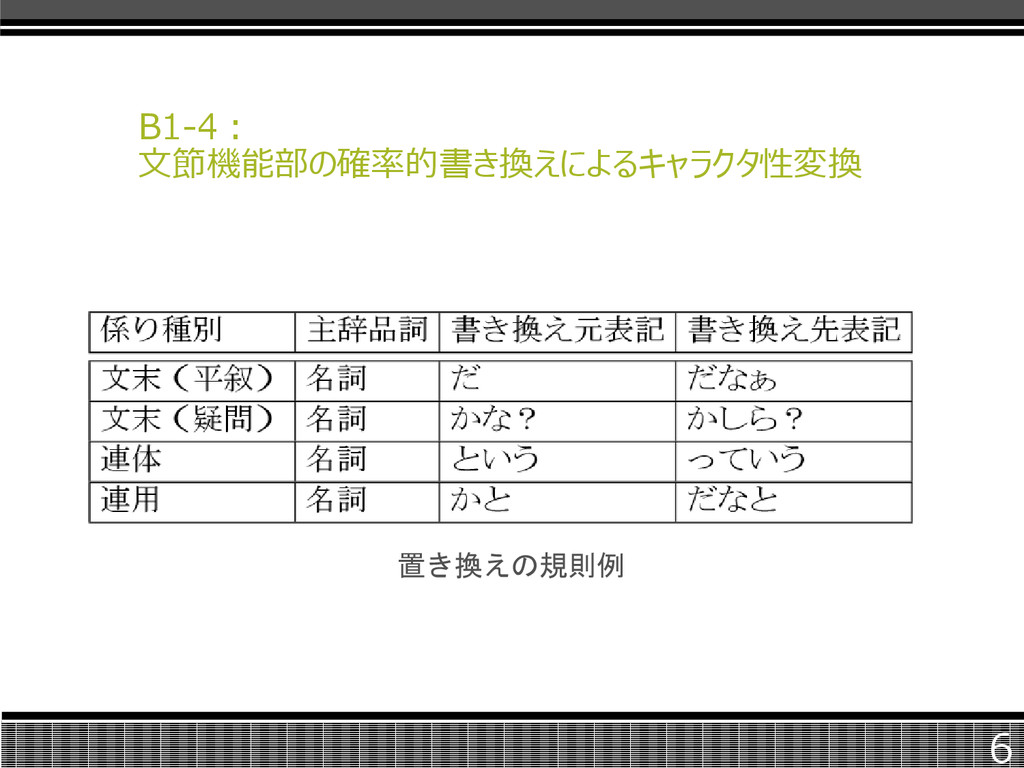
B1-4: 文節機能部の確率的書き換えによるキャラクタ性変換 6 置き換えの規則例
B1-4: 文節機能部の確率的書き換えによるキャラクタ性変換 結果 違和感のある出力を10%程度に抑えつつ、80%以上の正解率で、 キャラクタを判断可能な付与を行なうことができている。 7
B4-4 高次脳機能障害スクリーニング調査支援ツールの開発 高次脳障害患者の障害度や回復度をはかるために、スクリーニング検査 というものが行われる。 スクリーニング検査は脳を使う問題を出題し、それに答えられるかを見て 症状を判断するもの。 その中でも「三単語復唱」という、3つの単語を覚える問題がある。
しかしこの3つの単語は、ほぼ変えられずに長い間使用され続けており、 被験者がこの単語を暗記してしまい、正確な症状の判断ができない問 題がある。 厳格な決まりがあり、勝手にこの単語を変更することが一般的に許されて いない。 そこで、厳格な決まりを守りつつ、単語を作成できるものを作成することを 試みている。 8
B4-4 高次脳機能障害スクリーニング調査支援ツールの開発 3単語の生成ルール ・性別、年代に関係なくよく知られていること。 ・短い音数であること。 ・単語間の連想性、相似性が低いこと。 このルールより、童話や童謡から名詞を取り出して使うことにした。
取り出した名詞をカテゴリ別に分類。 「食べ物」,「乗り物」,「植物」,「動物」,「建築物」,「日用品」, 「スポーツ」,「空想物」 任意のカテゴリから一つずつ単語を選び、3つを選出する。 9
B4-4 高次脳機能障害スクリーニング調査支援ツールの開発 問題点1 例として「猫・こたつ・みかん」という組み合わせができてしまった時に、連 想が非常に容易にできてしまう。 解決策 ・連想語辞書(renso)による判定 単語の連想語を検索し、選ばれた残り2つが含まれないことを確認す
る。これを3単語全てのペアで行ない、問題ないものだけをクリアとする。 問題点2 例として「ハチ・柿・臼」という組み合わせができてしまった時に、さるかに 合戦として容易に記憶できてしまう。 解決策 ・共起率による連想性の判定を用いる。対象のコーパスには単語抽出で 利用した、童話・童謡を使用する。2つの単語が同じ物語・歌の中に含 まれた時には、候補から破棄する。 10
B4-4 高次脳機能障害スクリーニング調査支援ツールの開発 問題点3 例として「自動車・馬・刺身」という組み合わせができてしまった時に、馬 は乗り物でもあり、食べ物でもあるので、連想できてしまう。 解決策 ・単語間の類似度判定を行う。 単語間の類似度判定を行い、ある程度類似度が高いものがある場合
には、破棄する。 問題点4 例として「やかん・図鑑・ようかん」という組み合わせができてしまった時に、 全て最後が「かん」で終わるため覚えやすくなってしまう。 解決策 ・3つの単語全ての始音、終音が異なるもののみクリアし、同じ物がある 場合には破棄する。 11
B4-4 高次脳機能障害スクリーニング調査支援ツールの開発 結果 300組の3単語を出力した結果、96.7%が実際の検査で使用可 能であるという高評価を得た。 12
見たもの(17日) B1:対話 B1-1:地方議会会議録に含まれる地域課題を論題とした ディベート型対話システムの提案 B1-2:雑談対話システムにおける単語分散表現を用いた 話題展開手法 B1-3:ユーザ情報抽出のための自己開示文の人物属性分類
B1-4:文節機能部の確率的書き換えによるキャラクタ性変換 B1-5:雑談対話データへの複数人でのタグ付与における 曖昧タグの評価値の推定 13
見たもの(17日) A2:情報抽出(1) A2-1:ブートストラップ法を用いたTwitter からの不具合文抽出 A2-2:推理小説の難易度評価のための犯人推定 A2-3:ブログページからのウェブサイト情報・作成者情報の抽出
A2-4:言語横断手法による日本語時間的順序関係推定 14
見たもの(18日) B3:評判・感情解析 B3-1:文脈を考慮した観点に基づく意見ツイートクラスタリング B3-2:意見文の対象読者を限定する条件の抽出 B3-3:Word2Vecを用いた顔文字の感情分類 B3-4:うつ傾向推定に向けた抗うつ剤服用の投稿を起点とした
Twitter解析の初期検討 B3-5:顔文字のパーツの種類と表情の強弱に着目した 顔文字表情推定 15
見たもの(18日) B4:情報抽出(2) B4-1:動画サービスにおける外国動画に付与されたタグの分析 B4-2:中間言語との Dice 係数ベクトルを用いた対訳抽出 B4-3:時間情報を用いた文書への自動タグ付与モデルに関する検討
B4-4:高次脳機能障害スクリーニング検査支援ツールの開発 16
見たもの(19日) C5:機械学習(2) C5-1:単語のベクトル表現による文脈に応じた単語の同義語拡張 C5-2:辞書と文脈情報を用いた対義語モデルの学習 C5-3:語順と共起を考慮したニューラル言語モデルによる英文穴埋め C5-4:隠れ状態を用いたホテルレビューのレーティング予測
17
見たもの(19日) B6:テキストマイニング B6-1:Improving Churn Prediction with Voice of the
Customer B6-2:大量のつぶやきから日本酒の美味しい店を発掘する: 知識源としてのマイクロブログ活用の試み B6-3:識別子中の自然言語使用に基づくプログラム 実装技術解析に関する調査 B6-4:Computationalizing a Toulmin Model for Argumentation Generation B6-5:発達心理学の観点から見た絵本レビュー中の 子供の反応の分析 18
見たもの(19日) E7:要約 E7-1:分散表現を用いたヤフー知恵袋の要約 E7-2:木刈込みに基づく文書要約のためのZDDを用いた 動的計画法 E7-3:施設配置問題に基づく同一料理のレシピ集合 からの基本手順の抽出
E7-4:テレビ番組をより楽しむための実時間ツイート選択システム E7-5:文書の重要箇所抽出及び重み付け要約課題の 解決方策についての分析 19
見たもの(17日) P1:ポスター(1) P1-6:英語学習者コーパスのための句構造アノテーション P1-11:テキスト分類のための単語分割 P1-14:事象間の接続関係に基づく時間的順序関係推定 P1-18:SignWriting表記の手話文を対象とした簡単な
アメリカ手話-日本手話翻訳の検討 P1-20:法令対訳コーパスからの複単語表現抽出 P1-27:マイクロブログに対する文境界推定および係り受け解析 20
見たもの(17日) P2:ポスター(2) P2-19:方言コーパスに基づく発話者の地域推定 P2-22:風邪に罹ったのは誰か? --- 疾患・症状を保有する主体の推定 P2-24:キーワードの自動拡張に基づくイベント言及ツイートの収集
P2-25:インフルエンザ流行検出のための事実性解析 21
見たもの(18日) P3:ポスター(3) P3-3:文のカテゴリと極性の度合いの推定を行う 評判分析システムの研究 P3-9:機械翻訳の活用を見据えた文書構造と言語表現の対応づけ ―自治体手続き型文書を対象とした予備的報告― P3-10:多言語リアルタイム会話における日本語動詞語尾崩れの検出
P3-18:GAによる機械加工メモの自動要約に関する予備検討 P3-23:確率的トピックモデルを用いた評判文書における 意外な評価視点の発見とそれに基づく情報推薦 P3-27:高専関連報道記事を活用した活動情報の獲得と分析 22
見たもの(19日) P4:ポスター(4) P4-10:分散表現を用いた動詞・フレーズの含意関係認識 P4-14:絵本レビューにおける子供の反応記述検出のための 特徴的表現の分析 P4-19:表層的な統語素性を用いたチャンキングによる 対訳フレーズの抽出
P4-21:日本語人名辞書を用いた中国語文書からの人名抽出 P4-26:既存小説に依存しない小説の自動生成に関する一考察 23
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}