This talk is just what the title says. I will demonstrate how to run a neural net on a GPU because neural nets are solving some interesting problems and GPUs are a good tool to use.
Neural networks have regained popularity in the last decade plus because there are real world applications we are finally able to apply them to (e.g. Siri, self driving cars, facial recognition). This is due to significant improvements in computational power and the amount of data that is available for building the models. However, neural nets still have a barrier to entry as a useful tool in companies because they can be computationally expensive to obtain value and implement.
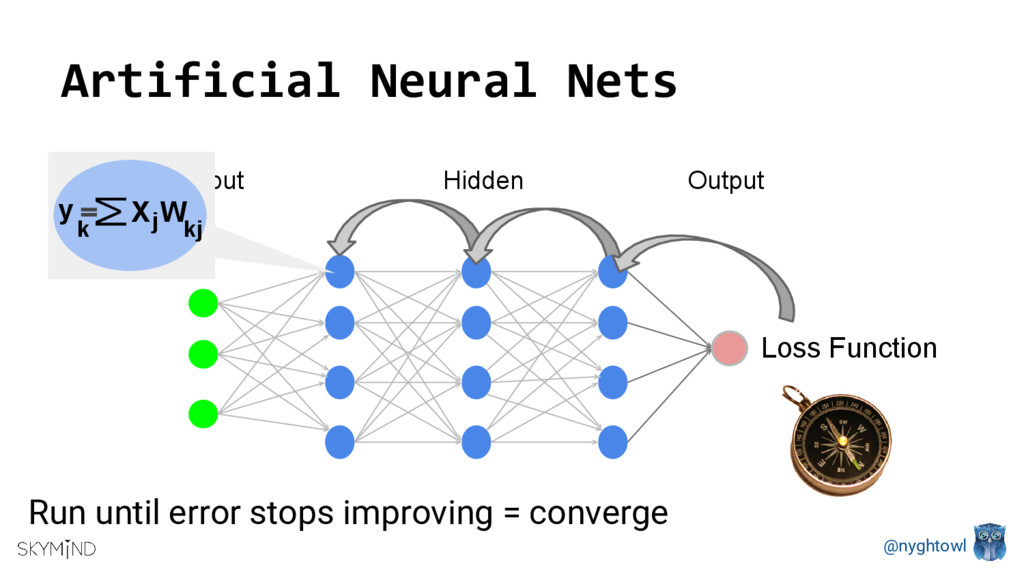
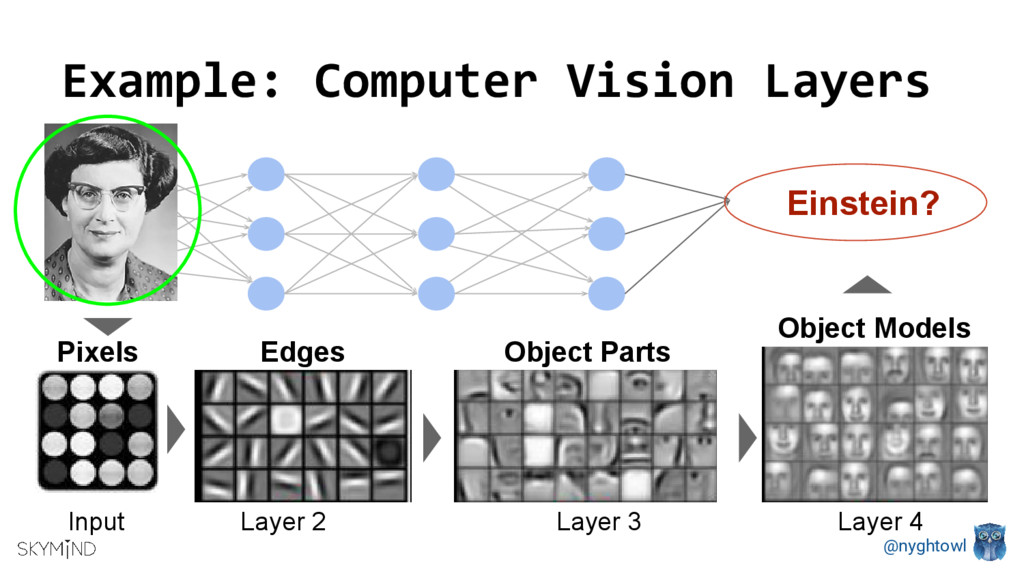
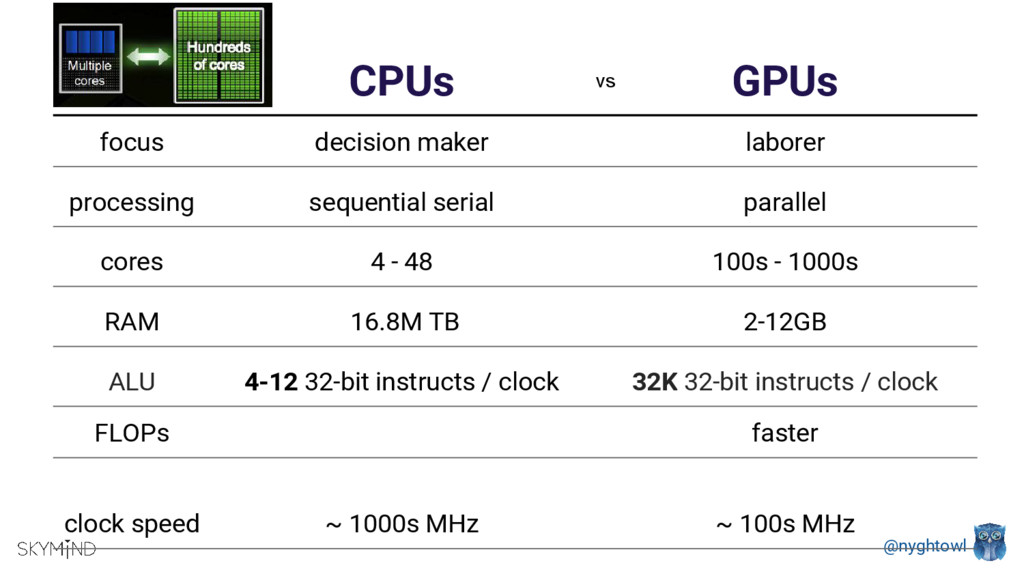
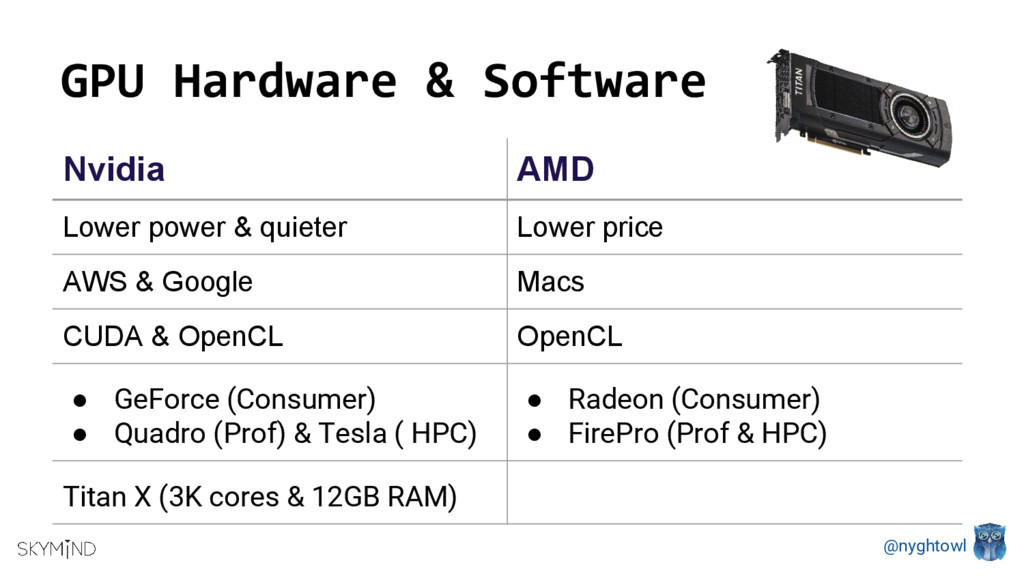
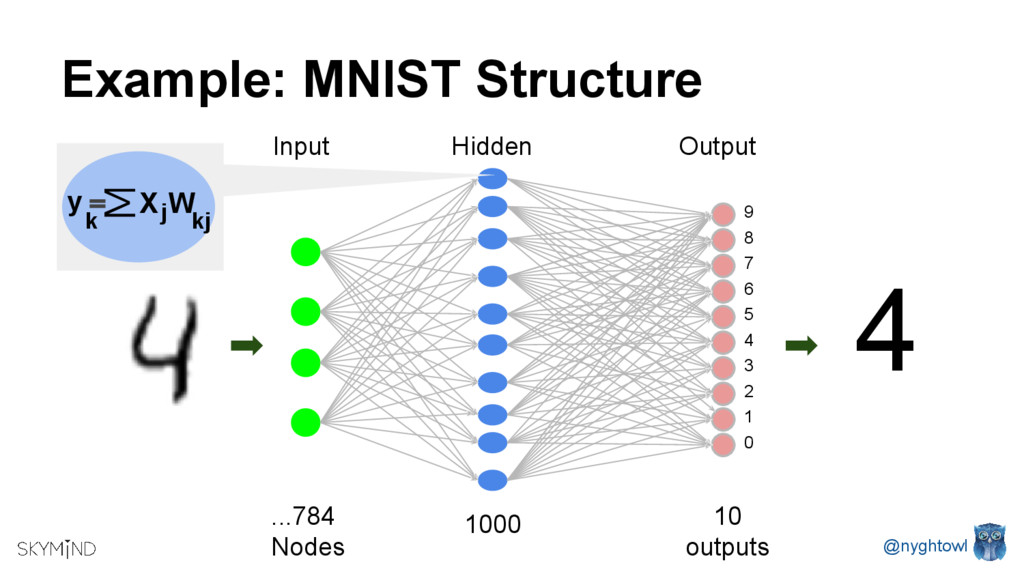
GPUs are popular processors in gaming and research due to their computational speed. Deep Neural Net’s parallel structures (millions of identical nodes that perform the same operation on different data), are ideal for GPU’s. Depending on the neural net, you can use a single server with GPUs vs. a CPU cluster and improve communication latency as well as reduces size and power consumption. Running an optimization method (training algorithm) like Stochastic Gradient Descent on a CPU vs. a GPU can be up to 40 times faster.
This talk will briefly explain what neural nets are and why they’re important, as well as give context about GPUs. Then I will walk through the code and actually launch a neural net on a GPU. I will cover key pitfalls you may hit and techniques to diagnose and troubleshoot. You will walk away understanding how to approach using GPUs on your own and have some resources to dive into for further understanding.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
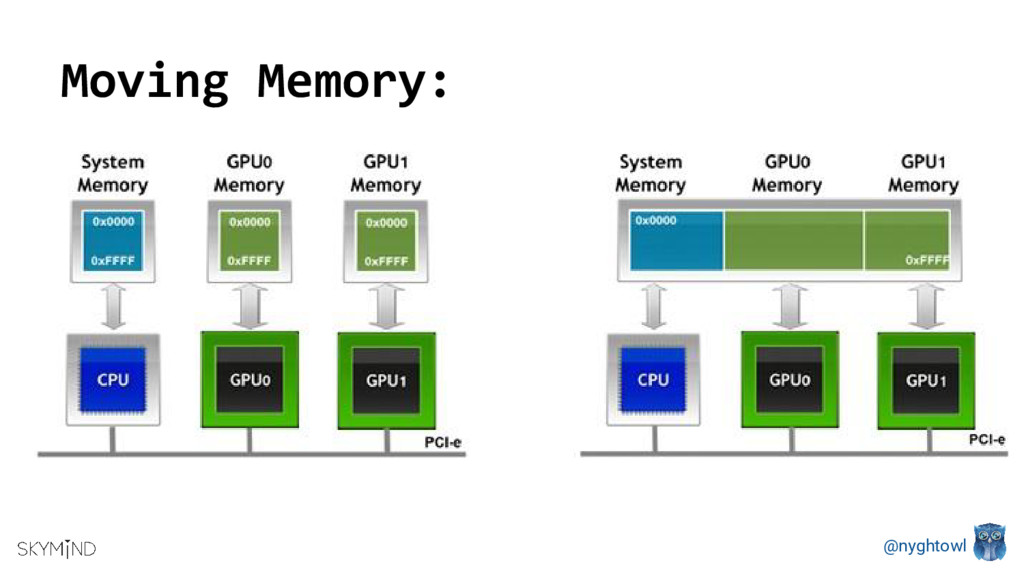{kind=link}
{kind=link}
{kind=link}
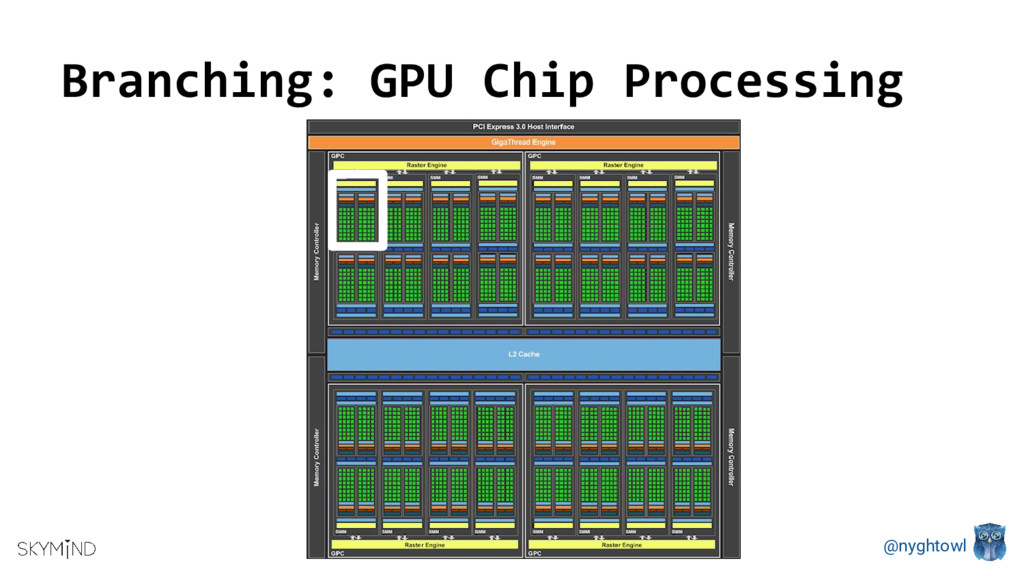{kind=link}
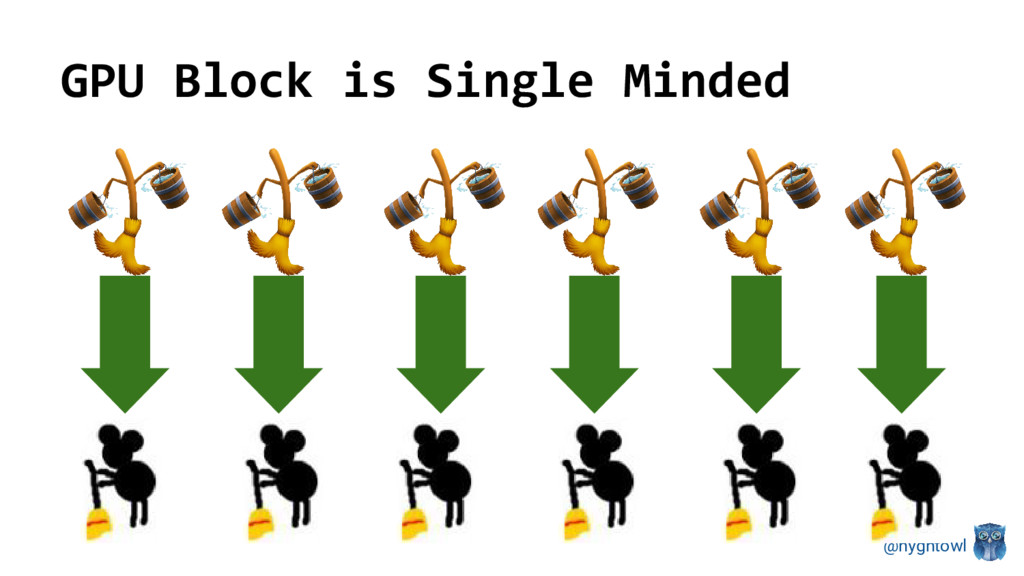{kind=link}
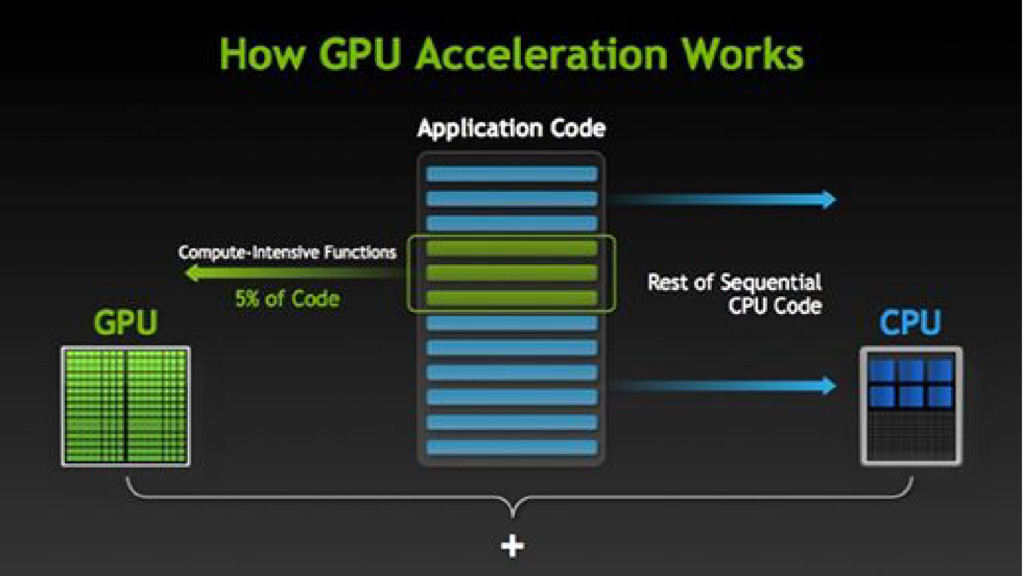{kind=link}
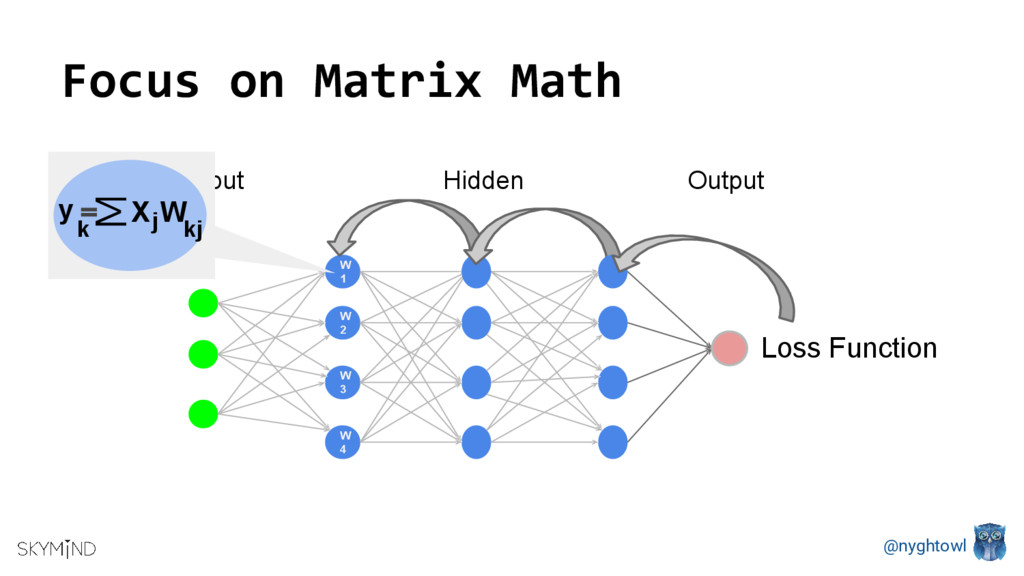{kind=link}
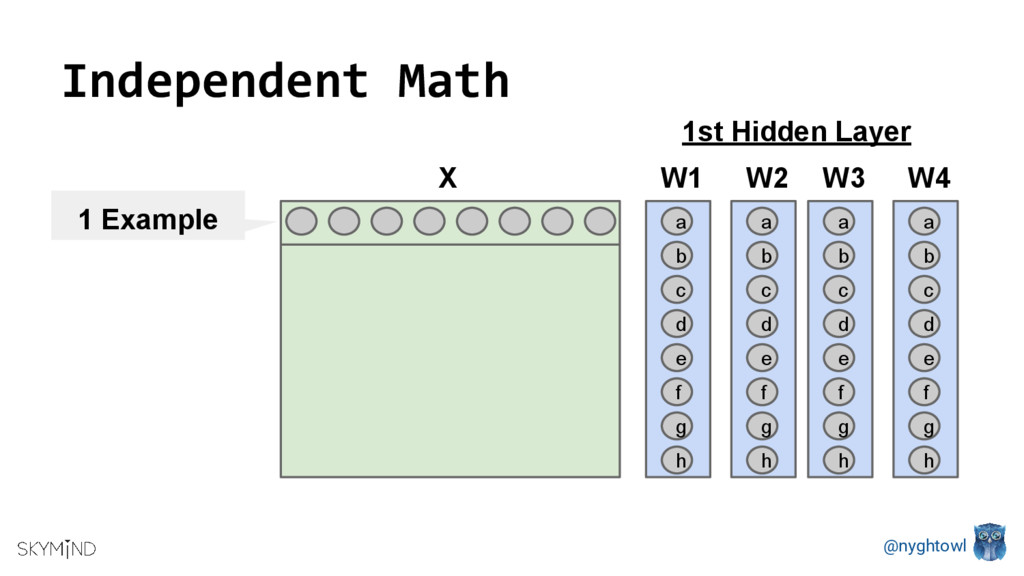{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
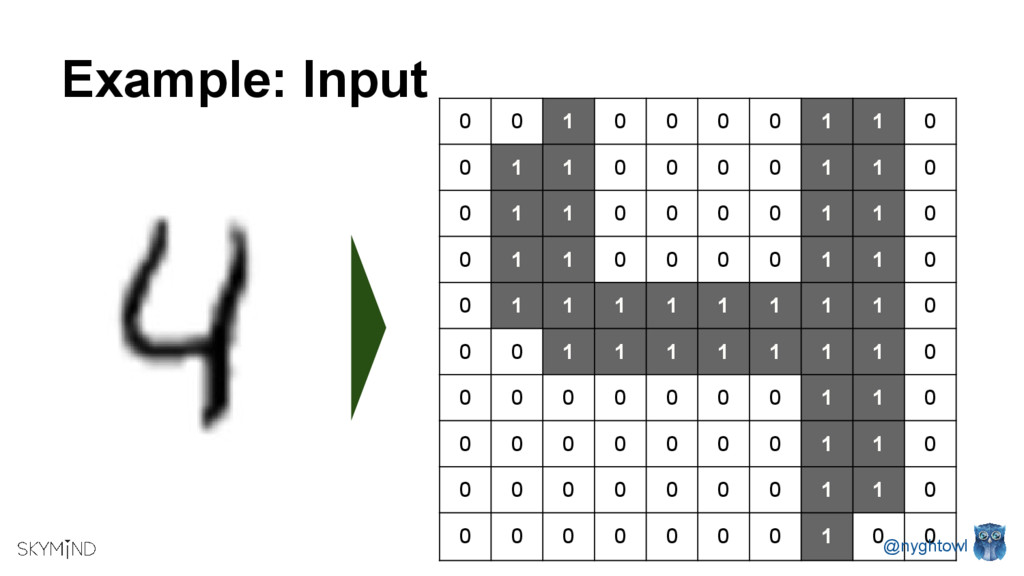{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}