Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
長くて覚えやすくて複雑なパスワードとemojiの話
Search
Sponsored
·
SiteGround - Reliable hosting with speed, security, and support you can count on.
→
Osumi, Yusuke
April 30, 2018
Technology
21k
21
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
長くて覚えやすくて複雑なパスワードとemojiの話
すみだセキュリティ勉強会2018その1での発表資料です。
http://ozuma.sakura.ne.jp/sumida/2018/03/22/38/
Osumi, Yusuke
April 30, 2018
More Decks by Osumi, Yusuke
See All by Osumi, Yusuke
本の紹介の補足
ozuma
1
420
gitサービス3兄弟
ozuma
0
420
簡体字は楽
ozuma
0
490
ソフトウェアは固定資産
ozuma
0
450
ASCIIコードの小話
ozuma
0
470
今いるディレクトリを消すとどうなる
ozuma
1
420
名前付きパイプ FIFO
ozuma
0
580
文章、作文技法 リモートワーク
ozuma
1
940
CentOSの今後のリリース(簡易説明)
ozuma
0
420
Other Decks in Technology
See All in Technology
Webアプリ認証の全体像 / The Big Picture of Web App Authentication
kitano_yuichi
1
480
全社でのソフトウェアサプライチェーン攻撃対策をやってみた with Takumi Guard
z63d
0
320
41歳でAWSが好きすぎてITエンジニアになったおっさんの話
yama3133
1
790
ここは地獄!つらい朝会を体験することで、チームとしてのより良い振る舞いに気づくワークショップ / The stand-up meeting from hell in the game industry
scrummasudar
0
410
それでも、技術なブログを書く理由 #kichijojipm / Why I Still Write Tech Blogs Even Now
shinkufencer
0
1.2k
AI驚き屋発見器
yama3133
1
380
NYC Summit 2026 における Amazon Bedrock AgentCore のアップデート
ren8k
1
250
最新IoT事例11選に学ぶ!現場の成功パターンと実践のコツ【SORACOM Discovery 2026】
soracom
PRO
0
120
AIQAのナレッジ構築について
qatonchan
1
110
AIエージェントがあれば技術書なんてすぐ書けるでしょ→無理でした
watany
6
1.1k
最高のシステムプロンプトを作るためにフィードバック機能を導入した話
alchemy1115
0
190
新たなDBアーキテクチャ「LTAP」にDeep Dive!!
inoutk
0
140
Featured
See All Featured
Producing Creativity
orderedlist
PRO
348
40k
The agentic SEO stack - context over prompts
schlessera
0
850
AI: The stuff that nobody shows you
jnunemaker
PRO
9
850
Visualizing Your Data: Incorporating Mongo into Loggly Infrastructure
mongodb
49
10k
The AI Revolution Will Not Be Monopolized: How open-source beats economies of scale, even for LLMs
inesmontani
PRO
3
3.7k
"I'm Feeling Lucky" - Building Great Search Experiences for Today's Users (#IAC19)
danielanewman
230
23k
Sam Torres - BigQuery for SEOs
techseoconnect
PRO
0
440
[SF Ruby Conf 2025] Rails X
palkan
2
1.2k
Information Architects: The Missing Link in Design Systems
soysaucechin
0
1k
Prompt Engineering for Job Search
mfonobong
0
380
What the history of the web can teach us about the future of AI
inesmontani
PRO
1
640
Bridging the Design Gap: How Collaborative Modelling removes blockers to flow between stakeholders and teams @FastFlow conf
baasie
0
620
Transcript
長くて覚えやすくて複雑なパスワードと emojiの話 マジ卍 すみだセキュリティ勉強会2018その1 (2018/04/30) すみだセキュリティ勉強会 @ozuma5119 1
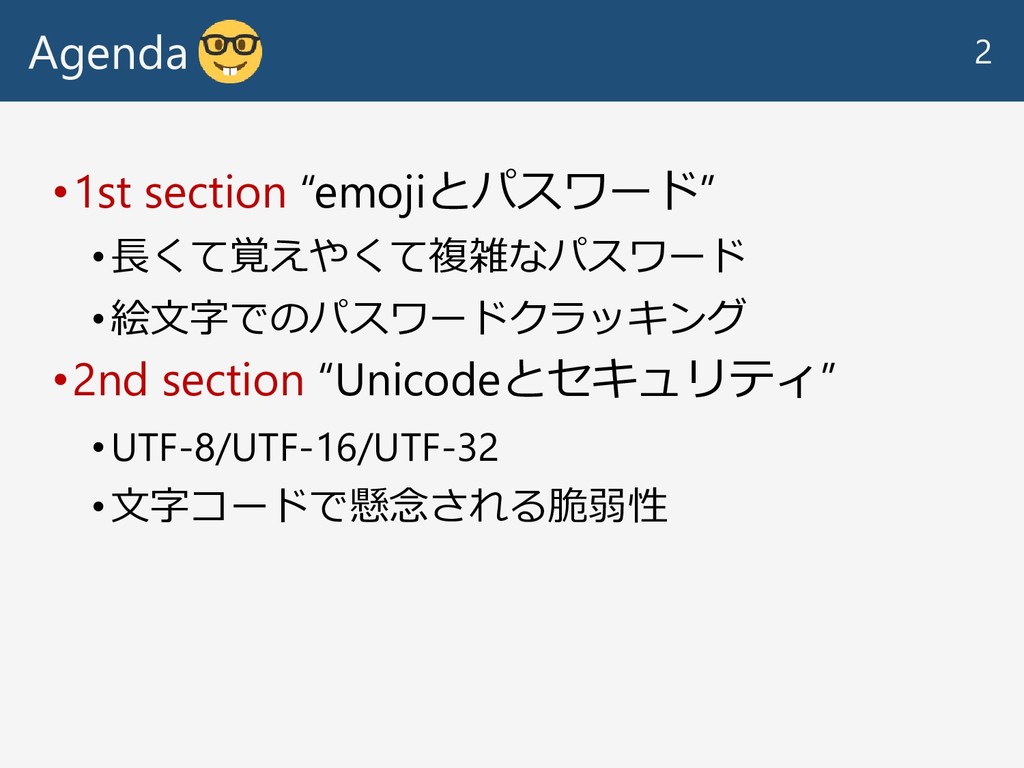
Agenda •1st section “emojiとパスワード” •長くて覚えやくて複雑なパスワード •絵文字でのパスワードクラッキング •2nd section “Unicodeとセキュリティ” •UTF-8/UTF-16/UTF-32
•文字コードで懸念される脆弱性 2
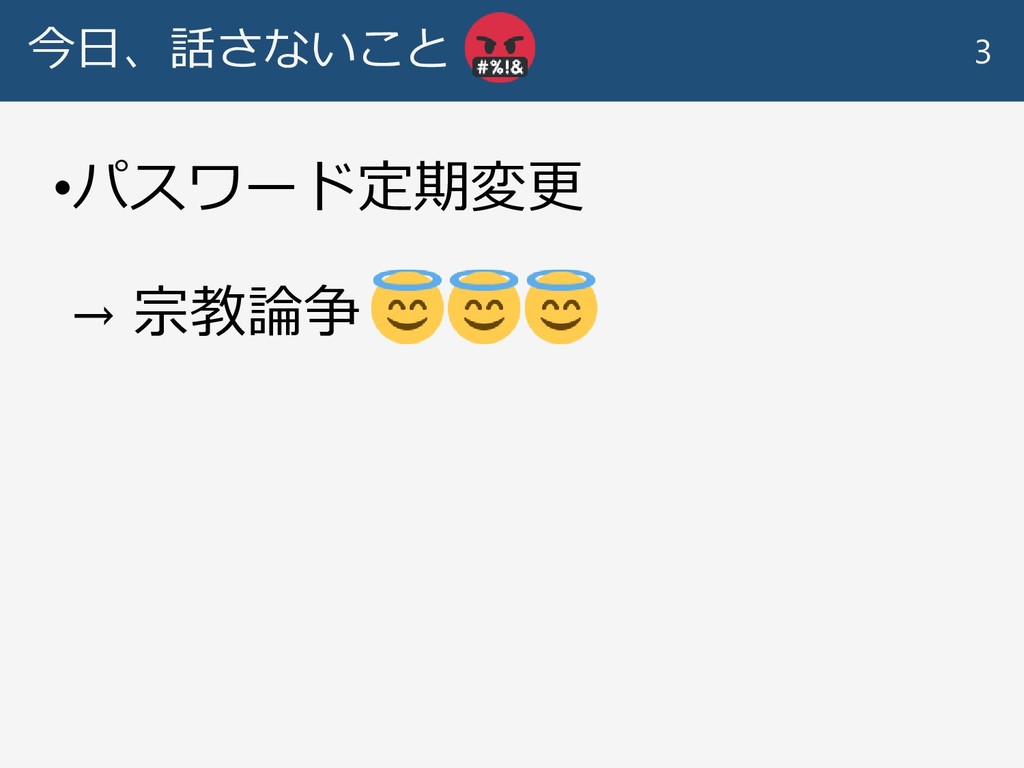
今日、話さないこと •パスワード定期変更 → 宗教論争 3
4 1st Section emojiとパスワード
攻撃しにくいパスワード •最近のトレンドは、 「とにかく文字数を多く」 •例) ${password}(自分の成年月日)-(定型 文字列) •Vn!px$2n •Vn!px$2n1990/01/01-SUMIDA 5
総当たりへの耐性 6 •たとえアルファベット小文字26種だけでも 文字数を増やせば、「べき乗」で効いてくる •a=26, n=文字数 •100文字のパスワードなら、26の100乗
でも今日は敢えて文字種に注目 7 •本日の勉強会に来ている人は、一般人 ではない 一般的な話以外も聞きたいと 思うので •「攻撃しにくい文字種」を考えてみる
8 本当にあった怖い話
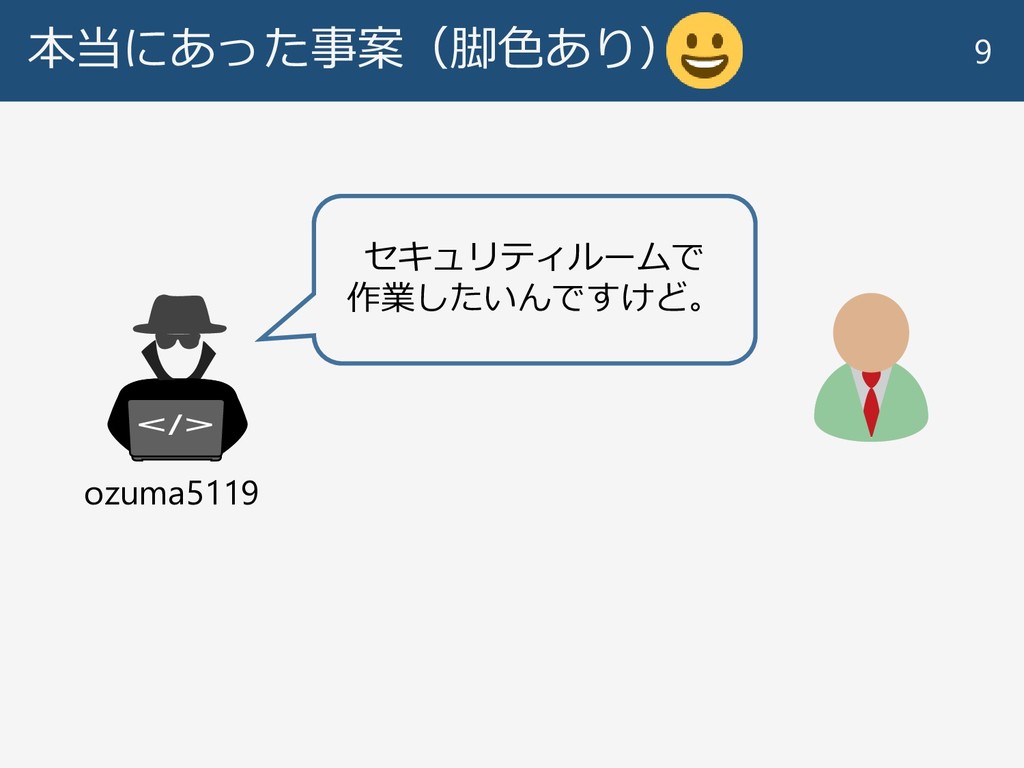
本当にあった事案(脚色あり) 9 セキュリティルームで 作業したいんですけど。 ozuma5119
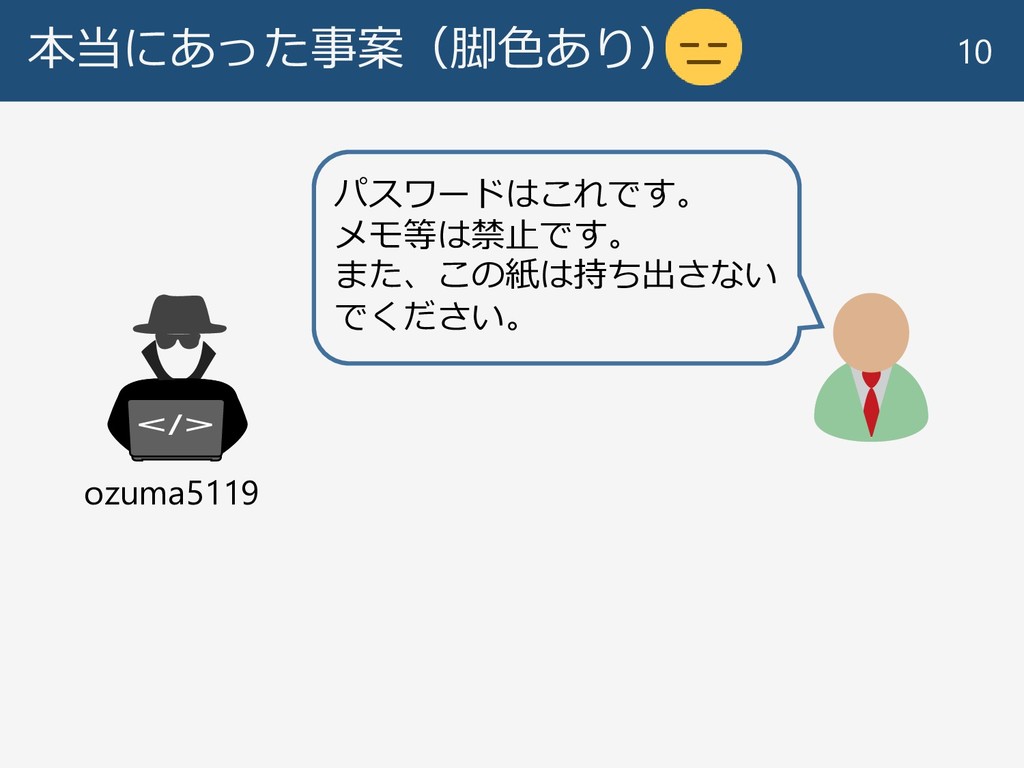
本当にあった事案(脚色あり) 10 パスワードはこれです。 メモ等は禁止です。 また、この紙は持ち出さない でください。 ozuma5119
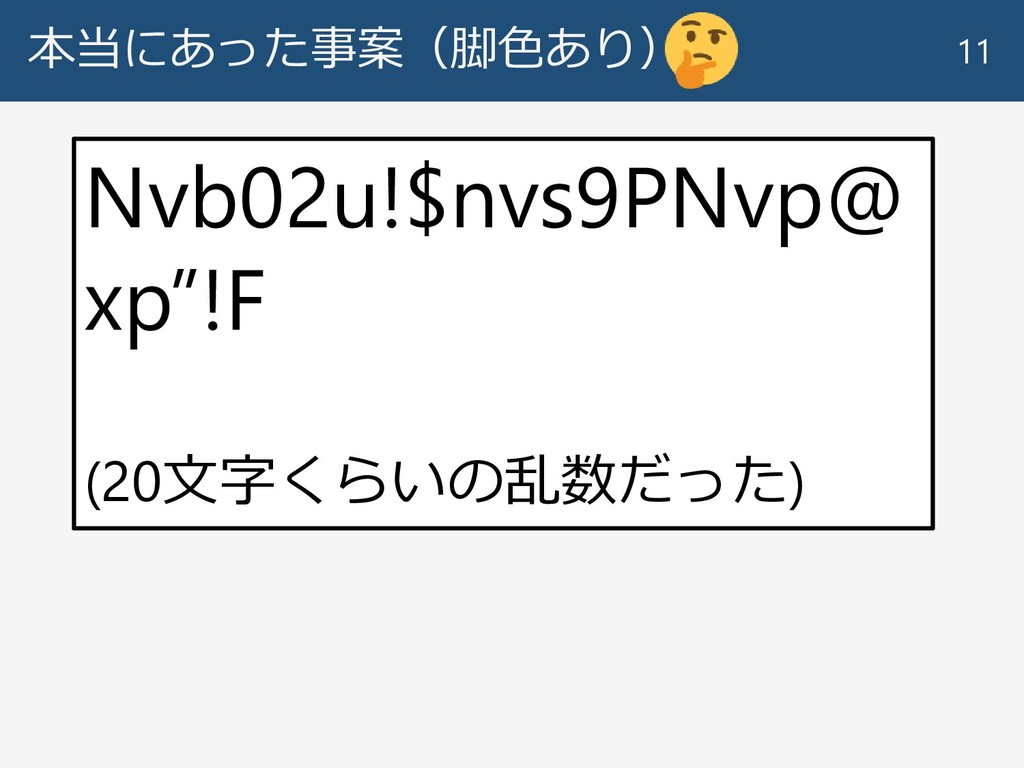
本当にあった事案(脚色あり) 11 パスワードはこれです。 メモ等は禁止です。 また、この紙は持ち出さない でください。 ozuma5119 Nvb02u!$nvs9PNvp@ xp”!F (20文字くらいの乱数だった)
本当にあった事案(脚色あり) 12 ムリですね。 ozuma5119
本当にあった事案(脚色あり) 13 うん。 ozuma5119
14 パスワード再考
I think about “Good Password”.... 15 ・適度に長くて ・覚えやすく ・複数の文字種を含んで ・推測されにくい
パスワード.....
I think about “Good Password”.... 16 ・適度に長くて ・覚えやすく ・複数の文字種を含んで ・推測されにくい
パスワード.....
I think about “Good Password”.... 17 ・適度に長くて ・覚えやすく ・複数の文字種を含んで ・推測されにくい
パスワード.....
18
19
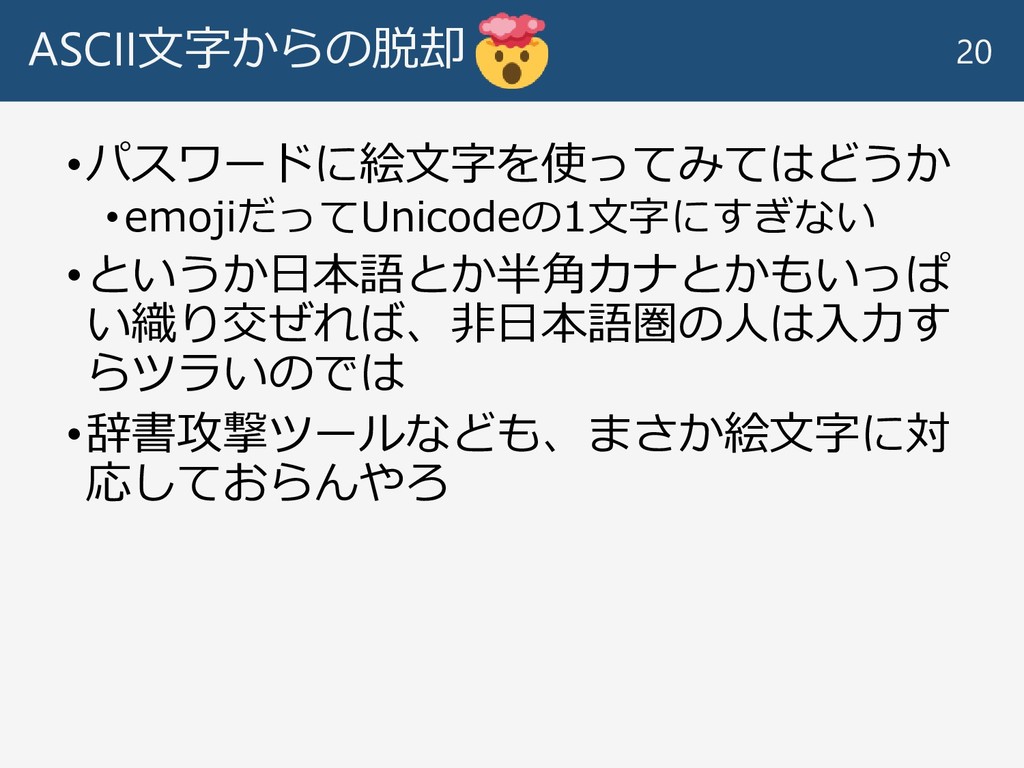
ASCII文字からの脱却 20 •パスワードに絵文字を使ってみてはどうか •emojiだってUnicodeの1文字にすぎない •というか日本語とか半角カナとかもいっぱ い織り交ぜれば、非日本語圏の人は入力す らツラいのでは •辞書攻撃ツールなども、まさか絵文字に対 応しておらんやろ
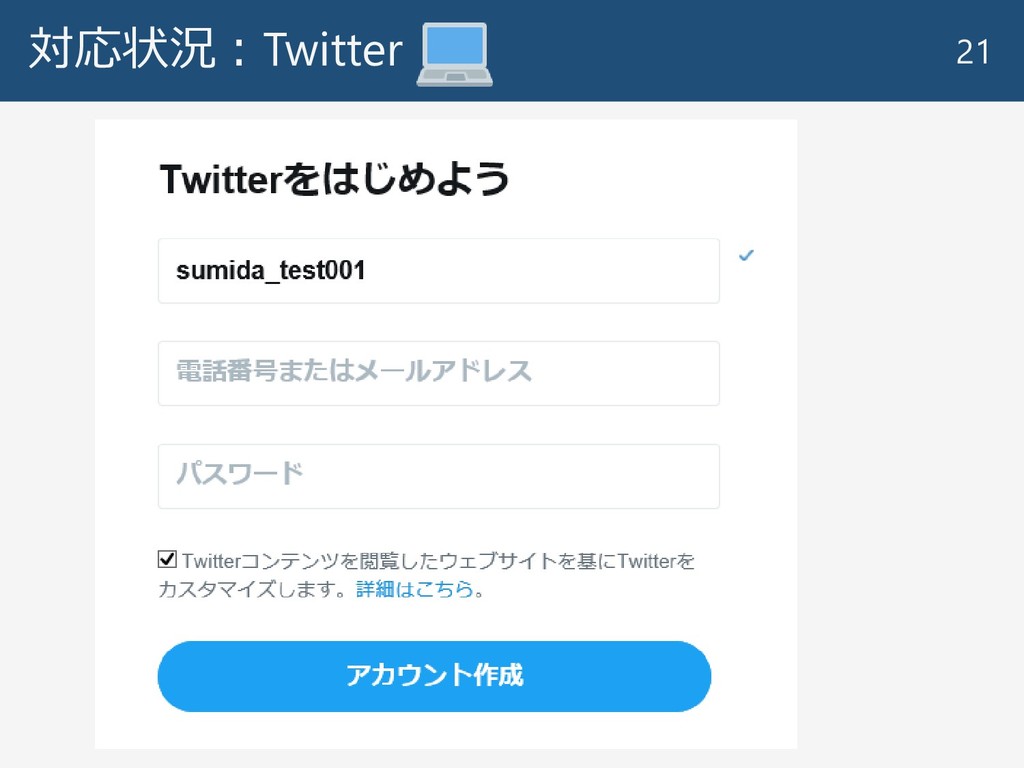
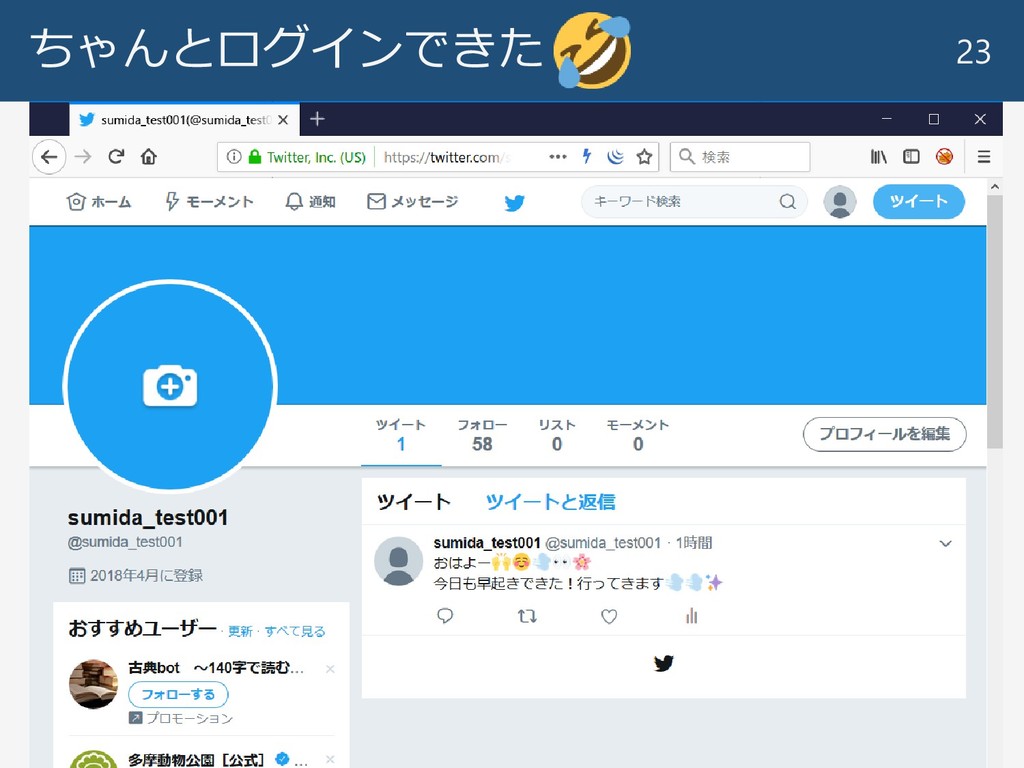
対応状況:Twitter 21
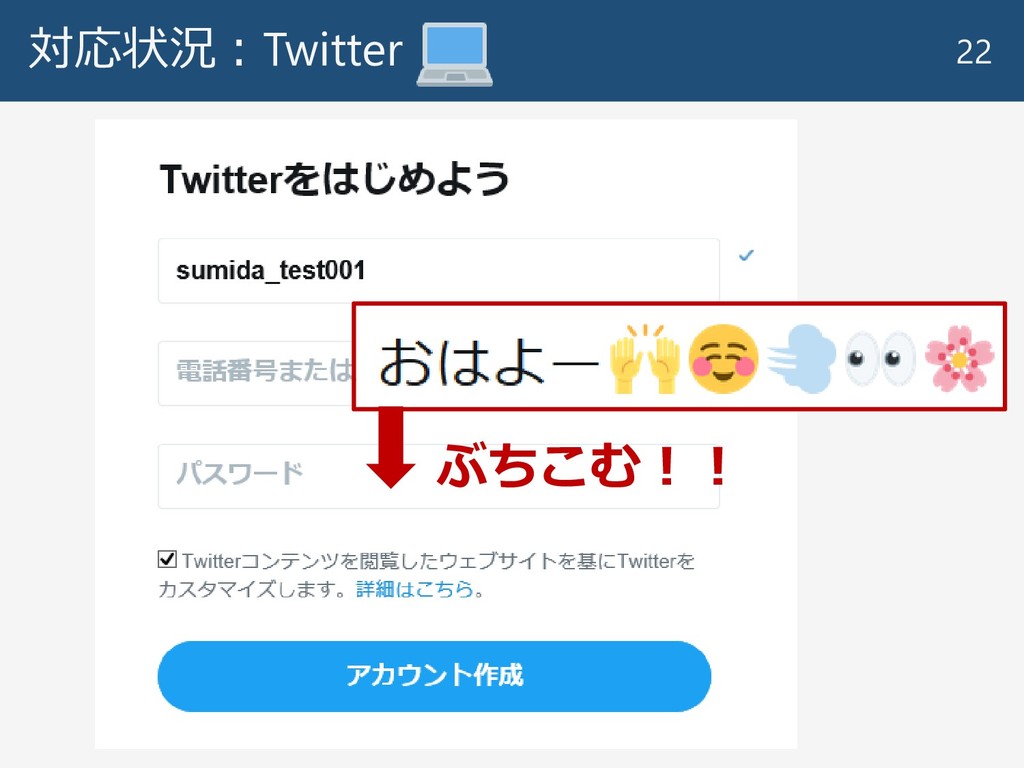
対応状況:Twitter 22 ぶちこむ!!
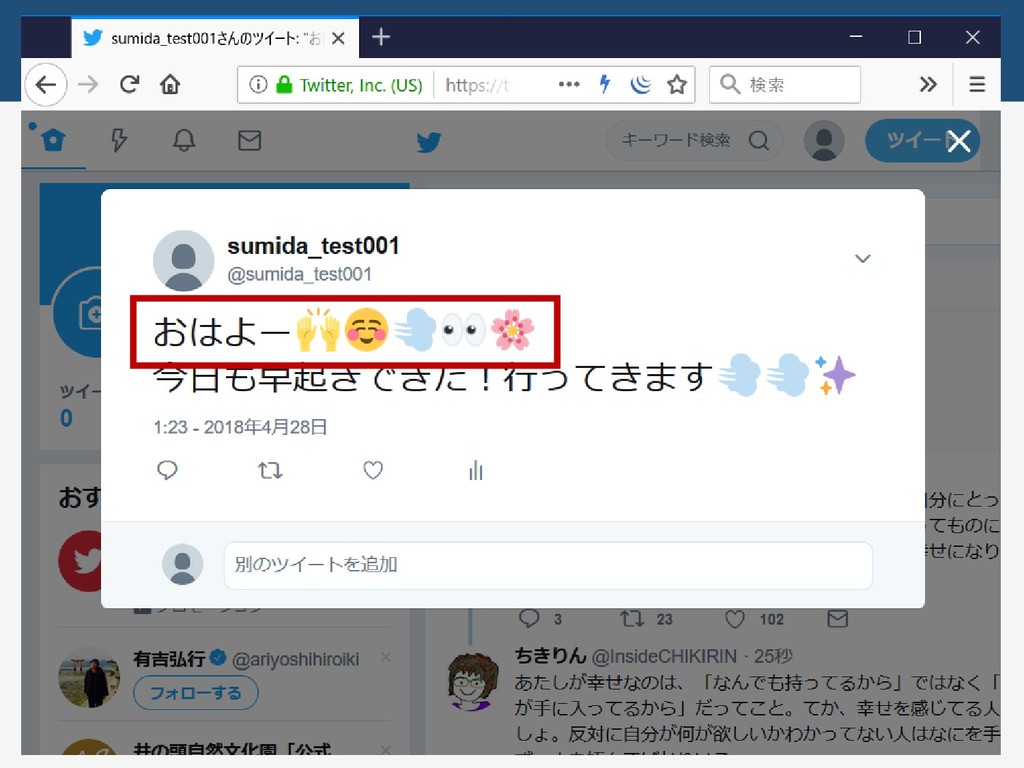
ちゃんとログインできた 23
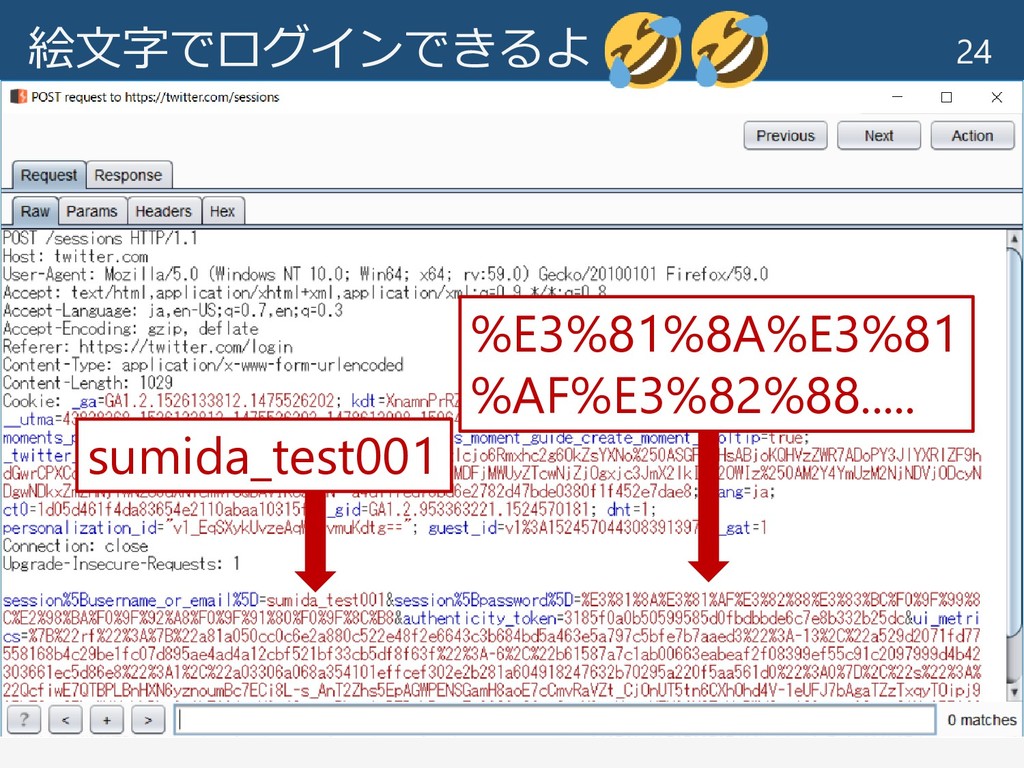
絵文字でログインできるよ 24 sumida_test001 %E3%81%8A%E3%81 %AF%E3%82%88.....
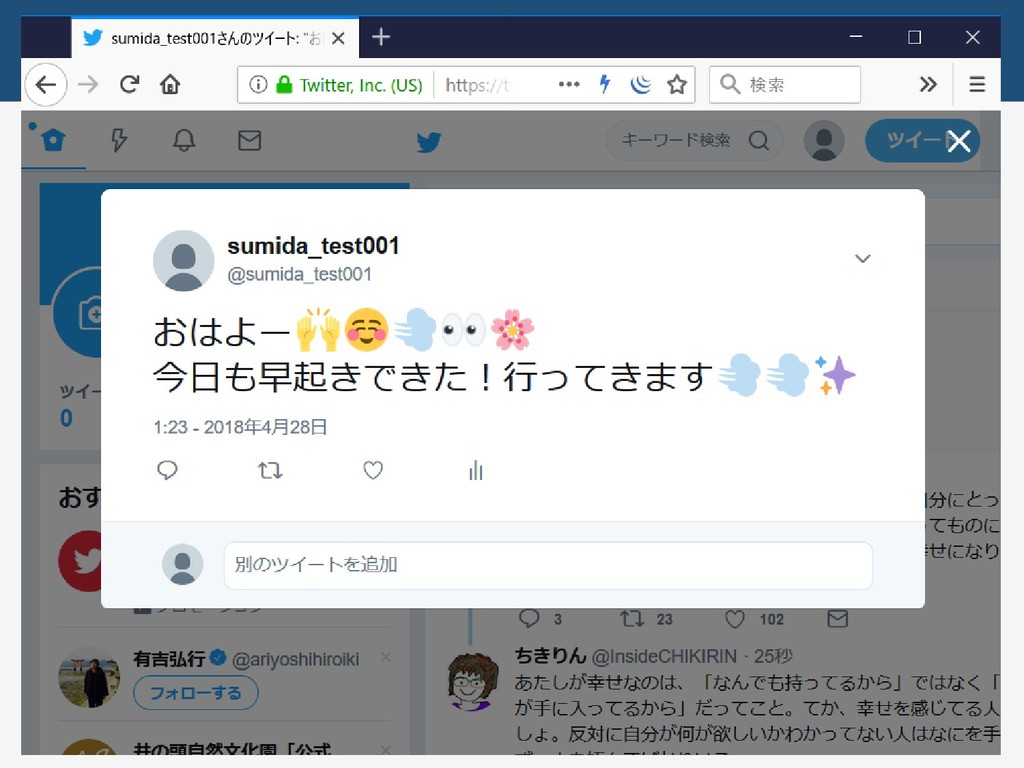
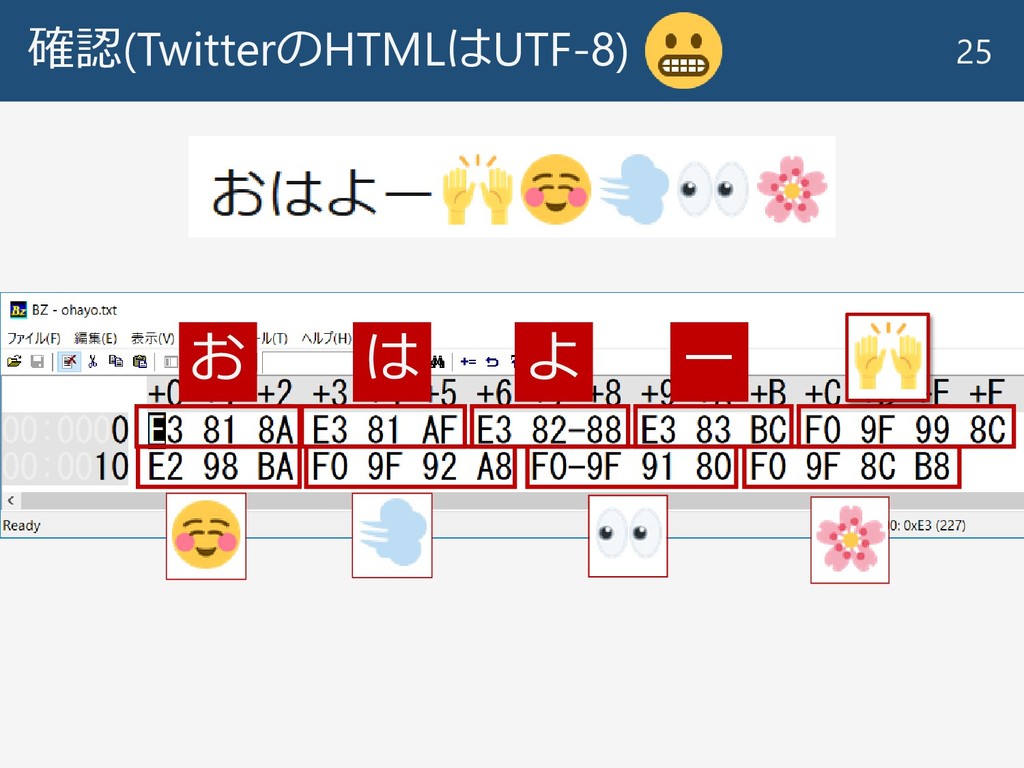
確認(TwitterのHTMLはUTF-8) 25 お は よ ー
パスワードPOST内容の確認 26 URLエンコードでは、絵文字とか特別な文字の 意識をする必要は無い。 単にバイト列をエンコードするだけ。 %E3%81%8A%E3%81%AF%E3%82%88%E3%83%BC %F0%9F%99%8C%E2%98%BA%F0%9F%92%A8%F0 %9F%91%80%F0%9F%8C%B8
パスワードに絵文字を使おう 27 うはwwwwっ楽しス これがパスワード
他サービスの対応状況 •WordPress •パスワードに絵文字使える •なおタイトルに絵文字など使う場合、 MySQLのutf8mb4設定(寿司ビール問 題)があるが、長い話になるので余裕 があれば語る 28
WordPressはビール脆弱 29
Yahoo! JAPAN:だめ 30
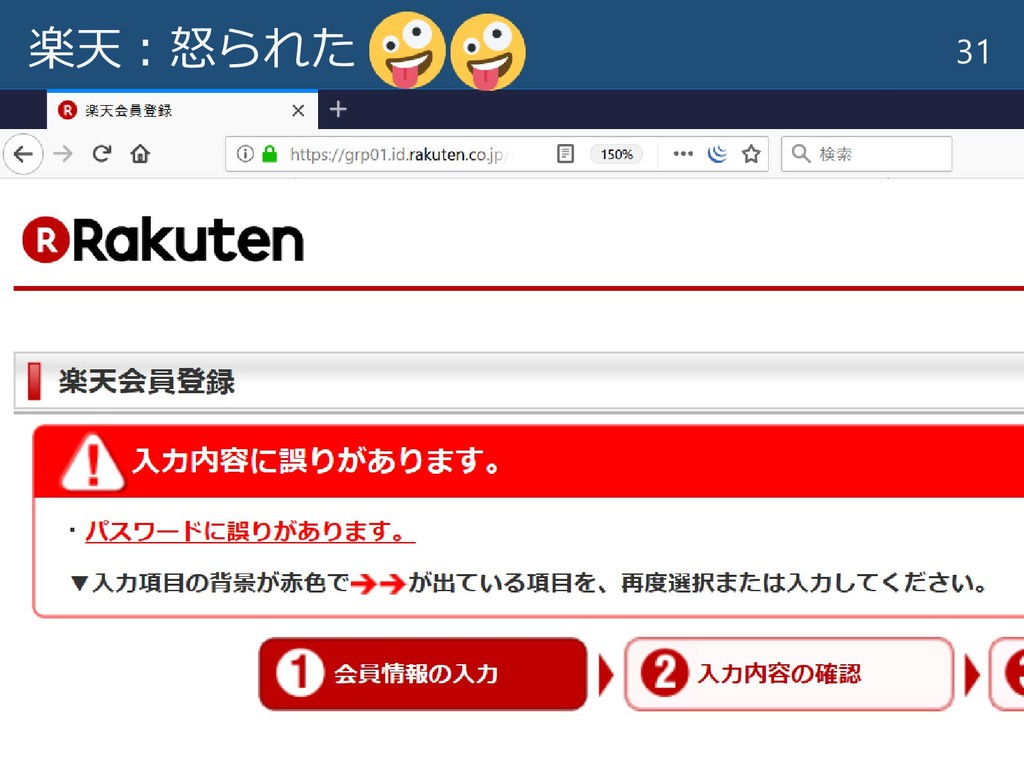
楽天:怒られた 31
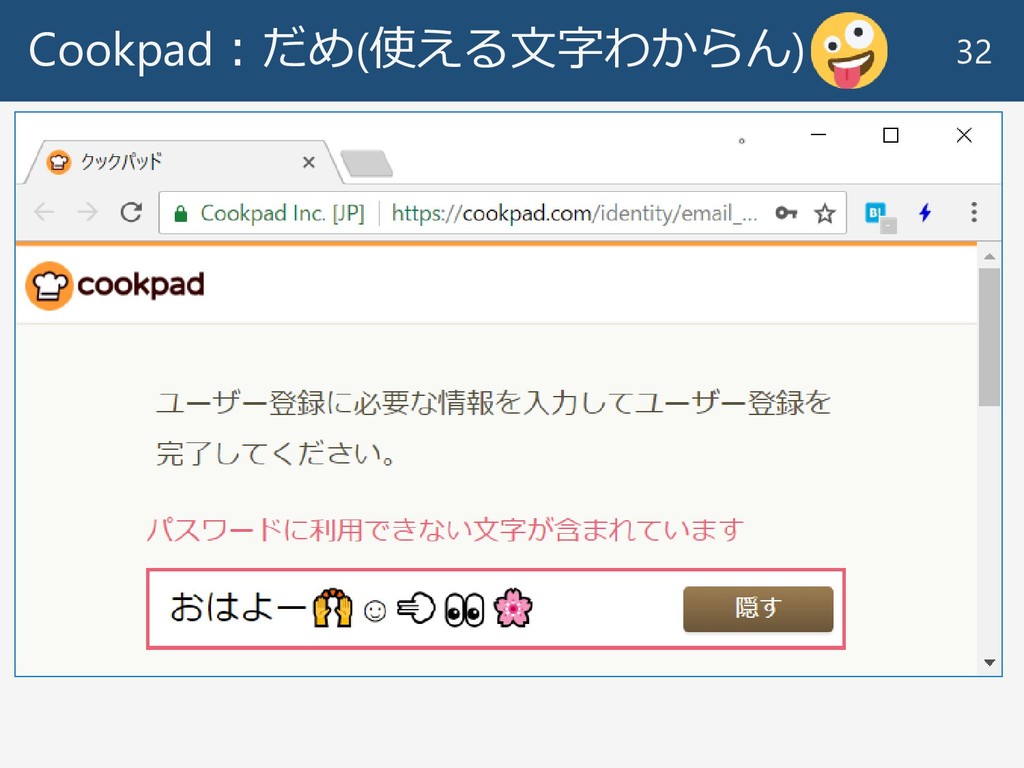
Cookpad:だめ(使える文字わからん) 32
Windows 7:詰むぞ! 33
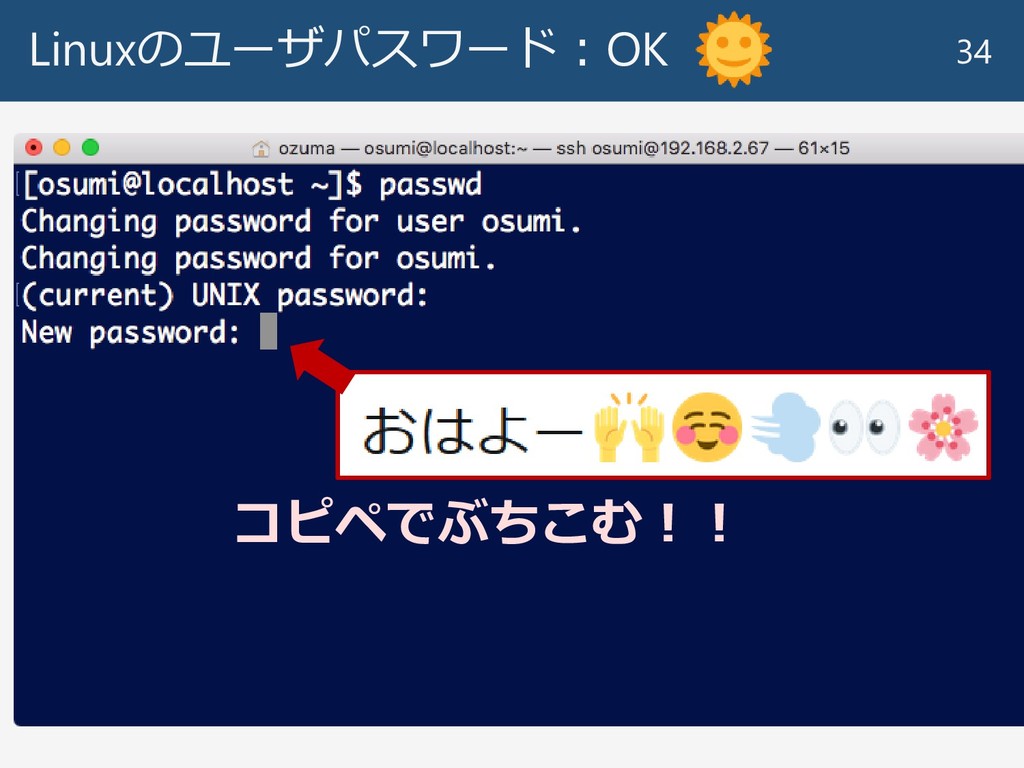
Linuxのユーザパスワード:OK 34 コピペでぶちこむ!!
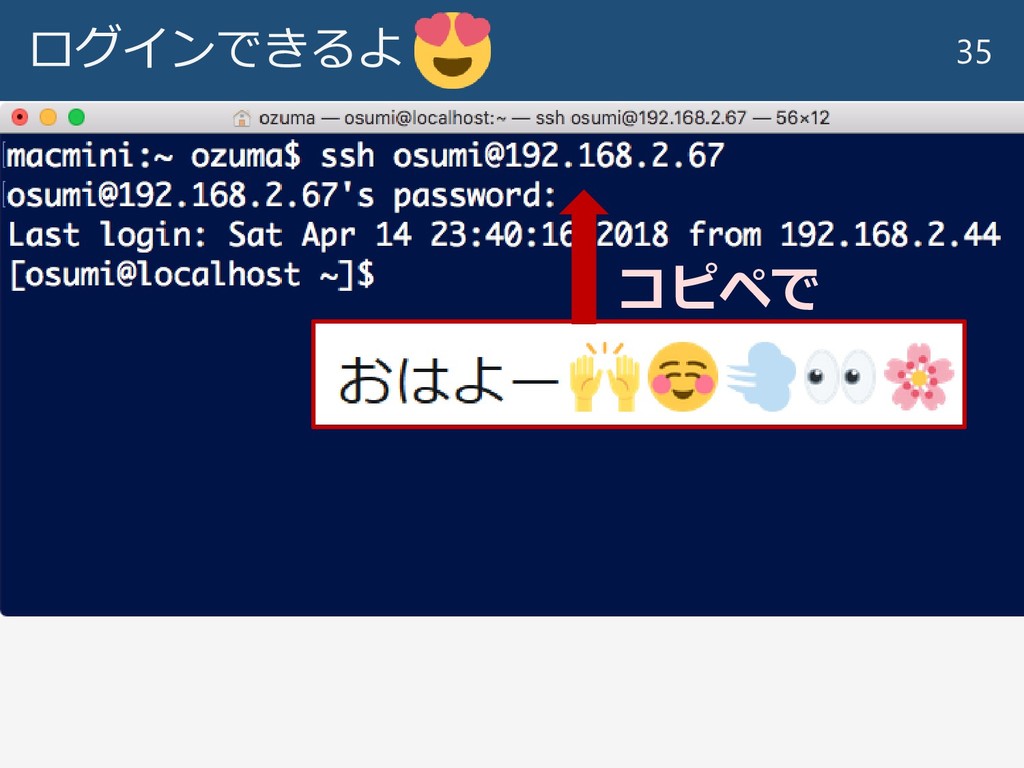
ログインできるよ 35 コピペで
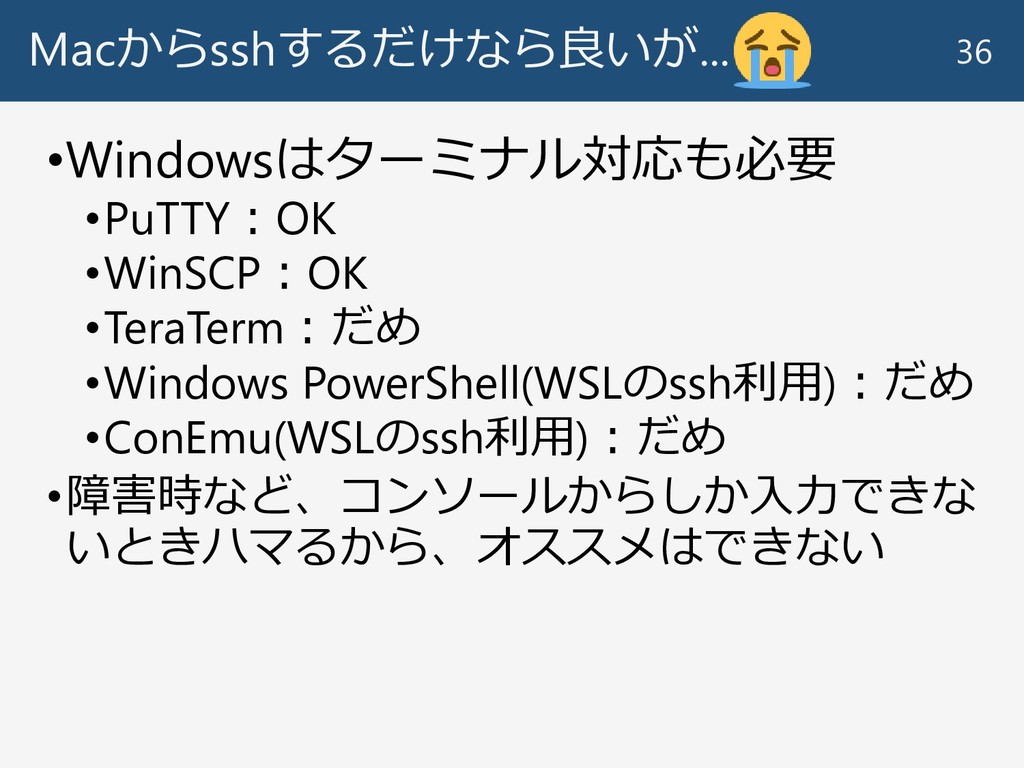
Macからsshするだけなら良いが... •Windowsはターミナル対応も必要 •PuTTY:OK •WinSCP:OK •TeraTerm:だめ •Windows PowerShell(WSLのssh利用):だめ •ConEmu(WSLのssh利用):だめ •障害時など、コンソールからしか入力できな いときハマるから、オススメはできない
36
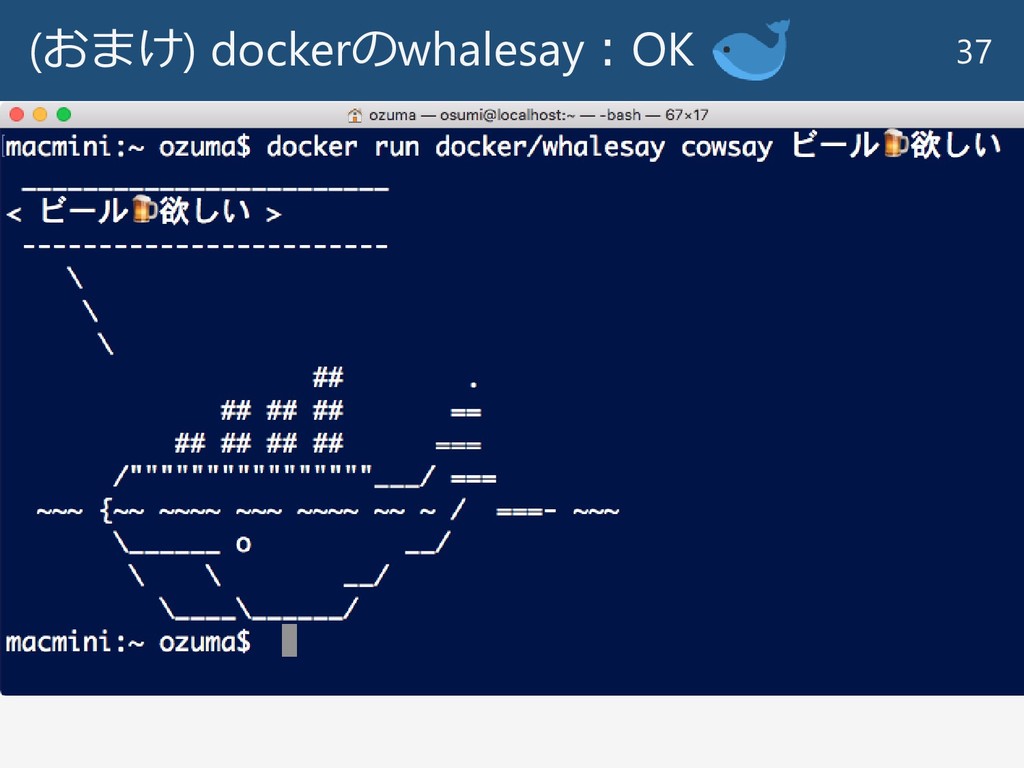
(おまけ) dockerのwhalesay:OK 37
38 クラッキングツールの対応
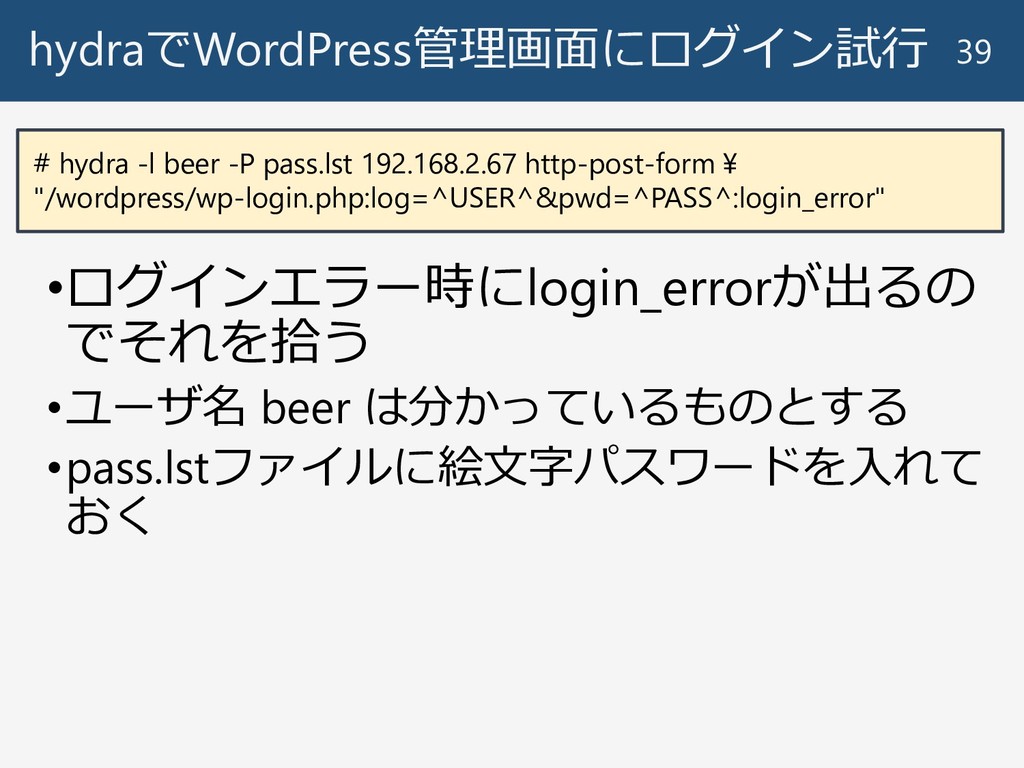
hydraでWordPress管理画面にログイン試行 39 # hydra -l beer -P pass.lst 192.168.2.67 http-post-form
¥ "/wordpress/wp-login.php:log=^USER^&pwd=^PASS^:login_error" •ログインエラー時にlogin_errorが出るの でそれを拾う •ユーザ名 beer は分かっているものとする •pass.lstファイルに絵文字パスワードを入れて おく
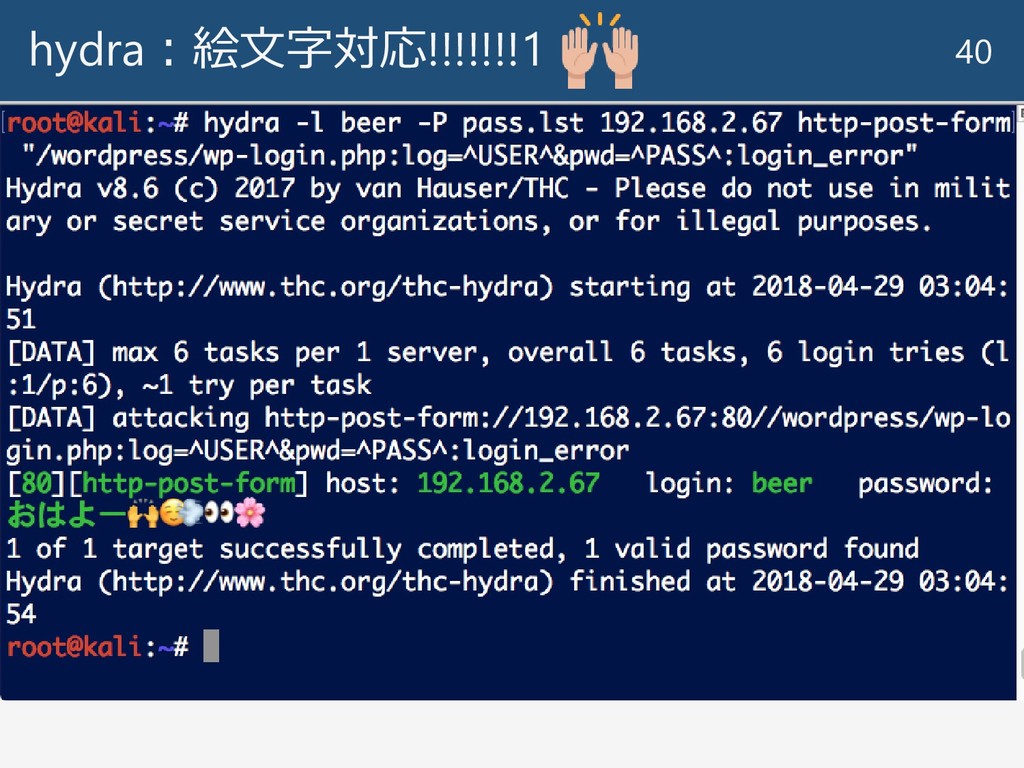
hydra:絵文字対応!!!!!!!1 40
wpscanでWordPress管理画面ログイン試行 41 # wpscan --url http://192.168.2.67/wordpress --wordlist /root/pass.lst --username beer
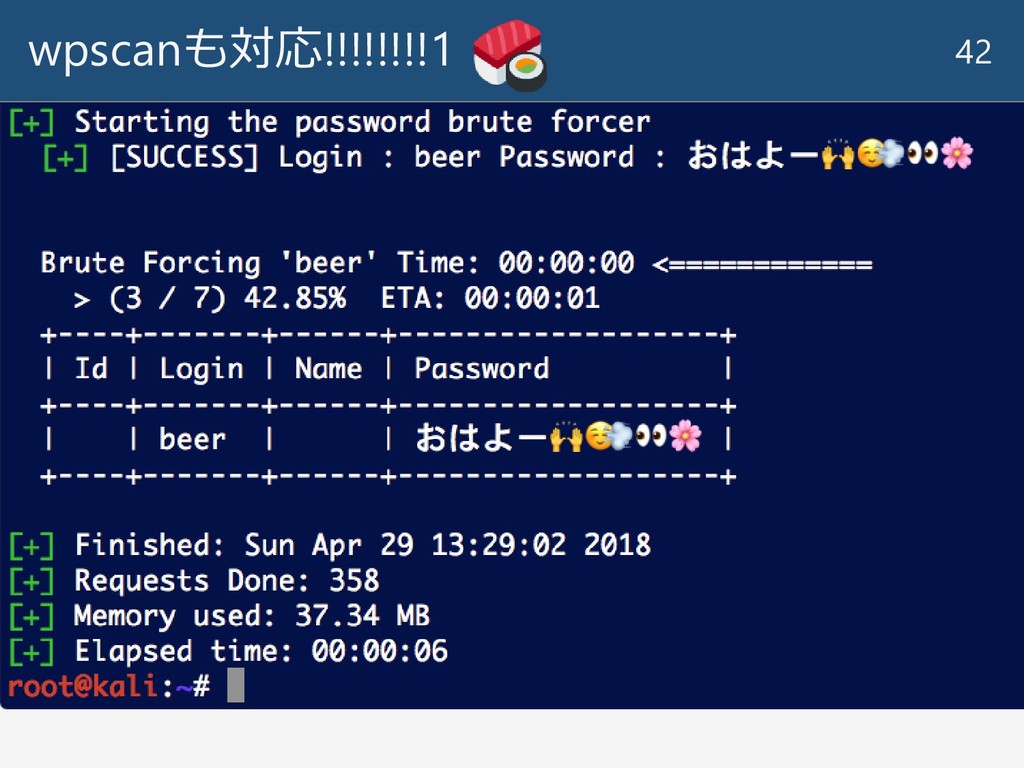
--threads 10 https://wpscan.org/
wpscanも対応!!!!!!!!1 42 # wpscan --url http://192.168.2.67/wordpress --wordlist /root/pass.lst --username beer
--threads 10
43 John the ripper
john the Ripper...の前におさらい 44 osumi:$6$tyRfXiDr$.Ygm5rlb0Pw8PPkkiVAOyZ40CQ3R Q9INbAMwEizuOZlcez1Q/LZwSU7yHK4Nt8UsfPw/bQ PiUghsvCkAyeDQa/:17607:0:99999:7::: Linuxのパスワードファイルは/etc/shadow ※FreeBSDは/etc/master.passwd ※他のUNIX系もだいたい同じだが、HP-UXだけは
独自の進化(話すと長いから省略)
john the Ripper...の前におさらい 45 osumi:$6$tyRfXiDr$.Ygm5rlb0Pw8PPkkiVAOyZ40CQ3 RQ9INbAMwEizuOZlcez1Q/LZwSU7yHK4Nt8UsfPw/b QPiUghsvCkAyeDQa/:17607:0:99999:7::: Linuxのパスワードファイルは/etc/shadow ソルト ハッシュ形式,
$6$はSHA512 ログイン名 ハッシュ化された パスワード
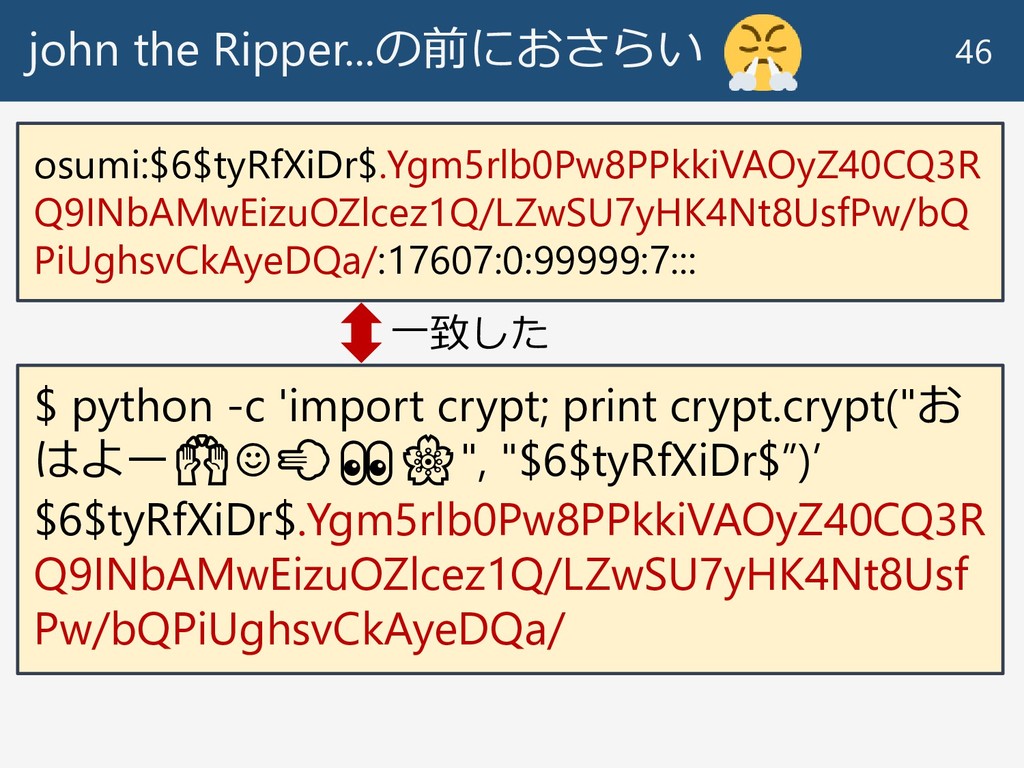
john the Ripper...の前におさらい 46 osumi:$6$tyRfXiDr$.Ygm5rlb0Pw8PPkkiVAOyZ40CQ3R Q9INbAMwEizuOZlcez1Q/LZwSU7yHK4Nt8UsfPw/bQ PiUghsvCkAyeDQa/:17607:0:99999:7::: $ python -c
'import crypt; print crypt.crypt("お はよー☺", "$6$tyRfXiDr$”)’ $6$tyRfXiDr$.Ygm5rlb0Pw8PPkkiVAOyZ40CQ3R Q9INbAMwEizuOZlcez1Q/LZwSU7yHK4Nt8Usf Pw/bQPiUghsvCkAyeDQa/ 一致した
John the Ripperのつかいかた1 47 # unshadow passwd shadow > passwd.db
# cat passwd.db root:$6$mO0Bqohl$Z03.tTtOUumg7UXfQ43u0JxLtkna OyM6YrteTa9sfdJltfZhYcqlkOV43.1Zfvq0fHX.FYNypaoZ qDlkQQ3yT0:0:0:root:/root:/bin/bash ....(省略).... osumi:$6$tyRfXiDr$.Ygm5rlb0Pw8PPkkiVAOyZ40CQ3R Q9INbAMwEizuOZlcez1Q/LZwSU7yHK4Nt8UsfPw/bQ PiUghsvCkAyeDQa/:1001:1001::/home/osumi:/bin/bas h ....(省略).... unshadowして/etc/passwdとshadowを結合
John the Ripperのつかいかた2 48 # cat p.lst password 1234567890 キャハがんばろ〜
pa$$word おはよー☺ PA$SWORD パスワードファイル(p.lst)を用意
John the Ripperのつかいかた3 49 # john --wordlist=p.lst passwd.db 辞書モードでハッシュをクラック #
john --show passwd.db クラックできたパスワードを表示
johnも絵文字対応してた 50
1部まとめ •とりあえずパスワードに絵文字入れても意外に 通る •これからは絵文字パスワードが流行る[要出典] ハニーポットで、非ASCII文字のパスワードで来 ている例がある方はぜひ教えてください (私はまだ観測していません) 51
52 2nd Section Unicodeとセキュリティ
Unicodeのcode point 53 墨 U+58A8 UTF-8 0xE5A2A8 UTF-16LE 0xA858 UTF-16BE
0x58A8 UTF-32BE 0x000058A8 code point(文字コード表の位置)は、U+58A8 LE: リトルエンディアン BE: ビッグエンディアン
Unicodeのcode point 54 a U+0061 UTF-8 0x61 UTF-16LE 0x6100 UTF-16BE
0x0061 UTF-32BE 0x00000061 code point(文字コード表の位置)は、U+0061
Unicodeのcode point 55 U+1F62D UTF-8 0xF09F98AD UTF-16LE 0x3DD82DDE UTF-16BE 0xD83DDE2D
UTF-32BE 0x0001F62D code point(文字コード表の位置)は、U+1F62D Loudly Crying Face ※面1(SMP)の文字
Unicodeの群、面 •基本多言語面(BMP: Basic Multilingual Plane) • 面0(ゼロ)と呼ばれる • code pointは16進4ケタとなる(例:U+58A8)
•補助多言語面(SMP: Supplementary Multilingual Plane) • 面1と呼ばれる • codepointは16進5ケタ、先頭は1となる(例:U+1F62D) • 面の上位に「群」もあるが、群0しか使われない 56 ※UTF-8などはいったん忘れて、code point(規格での文字表 の位置)だけ考える
BMP面の文字 57 群 0 (Unicodeでは常にゼロ) 面 0 (BMP) 墨 U+58A8
※一般的な文字はほぼBMPに入っている
SMP面の文字 58 U+1F62D Loudly Crying Face 群 0 (Unicodeでは常にゼロ) 面
1 (SMP)
UnicodeとUTF-8/16/32 •Unicodeでは、文字表のcode pointに対して 複数のコード値がある •UTF-8 •UTF-16 (ビッグ|リトル)エンディアン + BOM有無 •UTF-32
(ビッグ|リトル)エンディアン + BOM有無 •ここにわかりにくさのポイントがあると思う 59
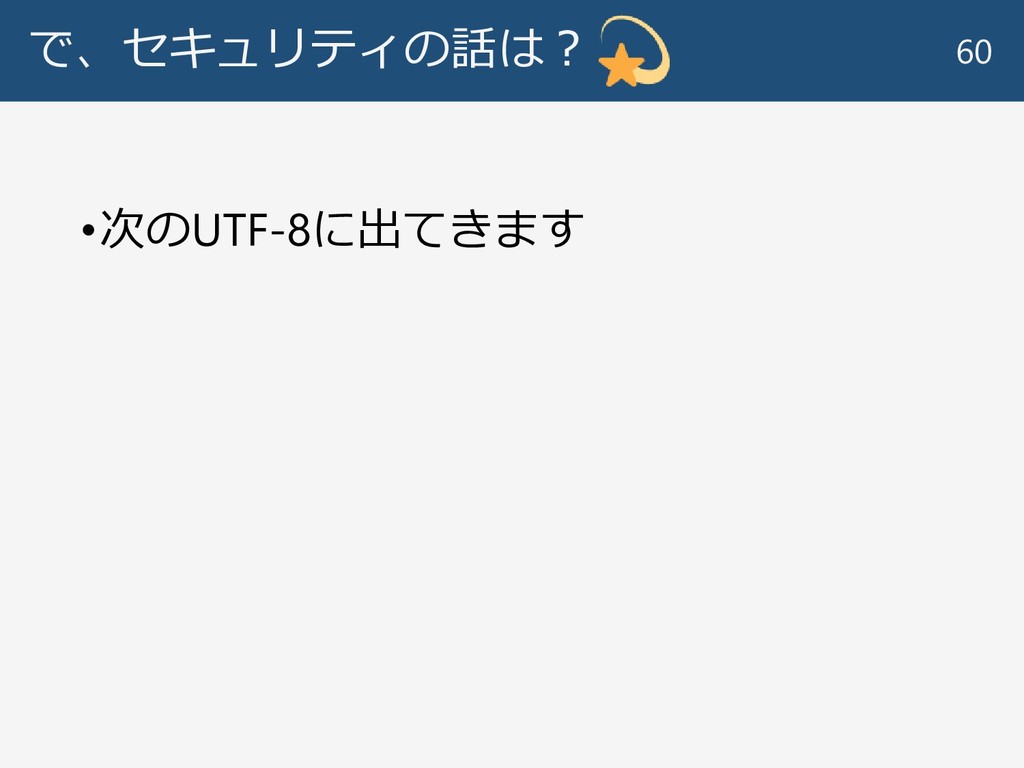
で、セキュリティの話は? •次のUTF-8に出てきます 60
61 UTF-8
UTF-8の特徴 •8bitを単位とし、code pointに独自演算をほどこし てコード値を生成する • どう計算するか話すと長いので省略 •ASCIIコードとの互換性が最大の魅力 • ASCII文字しかない文書は、ASCIIでもUTF-8でも全く同じ バイト列になる
•ASCIIは1バイト、日本語や絵文字などは3〜4バイ トとなる可変長 • BMPは3バイト、面0以外のSMPなどは4バイト •2018年現在、ファイルやWebアプリ入出力(外部 コード)はほぼUTF-8で統一されている 62
UTF-8のセキュリティ問題 63 1つのcode pointに対して、複数のコード値が存在する / U+002F UTF-8 0x2F 0xC0AF (規格上は不正)
0xE080AF (〃) 0xF08080AF (〃) 本当は怖い文字コードの話 第4回 UTF-8の冗長なエンコード http://gihyo.jp/admin/serial/01/charcode/0004 文字をビット比較して「0x2F禁止」など安易に書くと、 ディレクトリトラバーサルの脆弱性を引き起こす
64 UTF-16
UTF-16の特徴 •16ビットを単位とし、歴史的にはもっとも正統(?)な 表現 • JavaやWindowsの内部コードとして利用されていることで 有名 •BMP(面0)では、code pointとコード値が一致する •SMPなど面0以外を扱うために魔改造がほどこされ、 とても分かりにくい[要出典]
• サロゲートペアの利用 •エンディアンを明示するため、データの先頭にバイ ト順マーク(Byte Order Mark; BOM)が利用される • ビッグエンディアン:U+FEFF • リトルエンディアン:U+FFFE 65
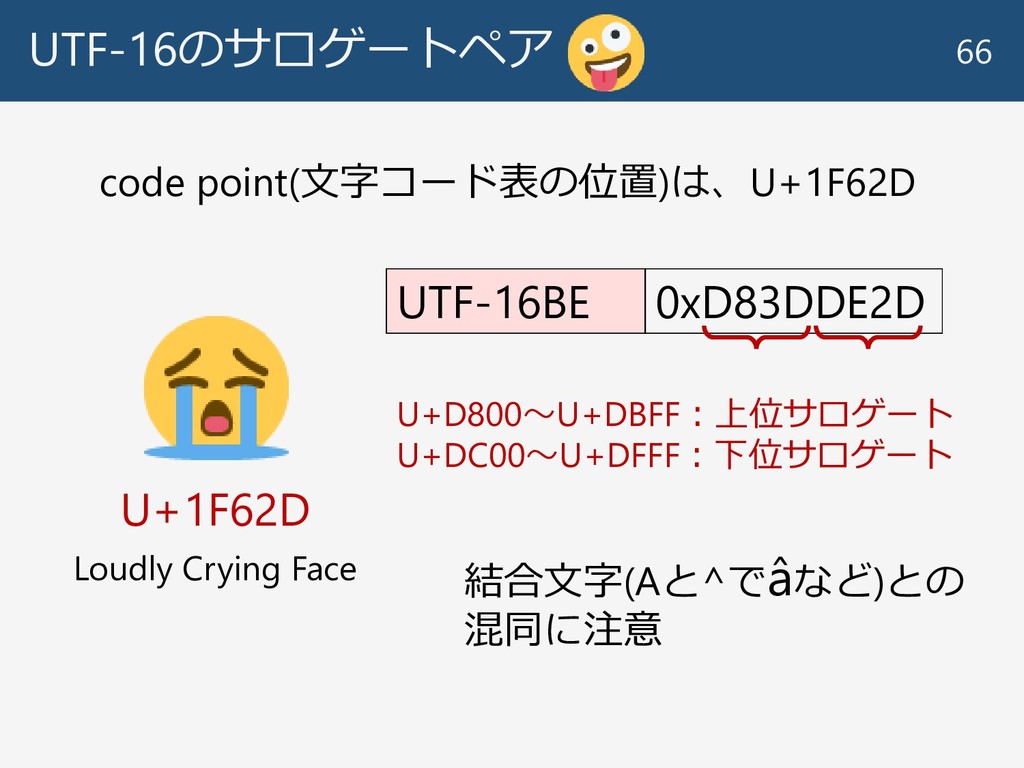
UTF-16のサロゲートペア 66 U+1F62D UTF-16BE 0xD83DDE2D code point(文字コード表の位置)は、U+1F62D Loudly Crying Face
U+D800〜U+DBFF:上位サロゲート U+DC00〜U+DFFF:下位サロゲート 結合文字(Aと^でâなど)との 混同に注意
Javaの内部コードはUTF-16 67 String str = "あいうえお"; for (char c :
str.toCharArray()) { System.out.println(c + " => 0x" + Integer.toHexString(c)); } UTF-8でソースコードを書いて実行しても あ => 0x3042 い => 0x3044 う => 0x3046 え => 0x3048 お => 0x304a UTF-16のバイト列が得られる
68 UTF-32
UTF-32の特徴 •名前のとおり、32bit(4バイト)で表現する固定長 •code pointとコード値が完全一致 • エンディアンの問題は残るため、BOMが利用される •固定長のため扱いやすい •ASCII文字も4バイトになるため、特にASCII文字が多 い文書のサイズが膨れ上がる 69
70 補足:絵文字豆知識
emoji = emotion icon ? 71 海外では、emojiを日本語の”絵文字”と知らずに、emotion icon(emoticon)からの造語と思っている人が結構多い[要出典] https://www.reddit.com/r/todayilearned/comments/6fwuxi/til_the_word_emoji_has_no_connection_to_emotion/
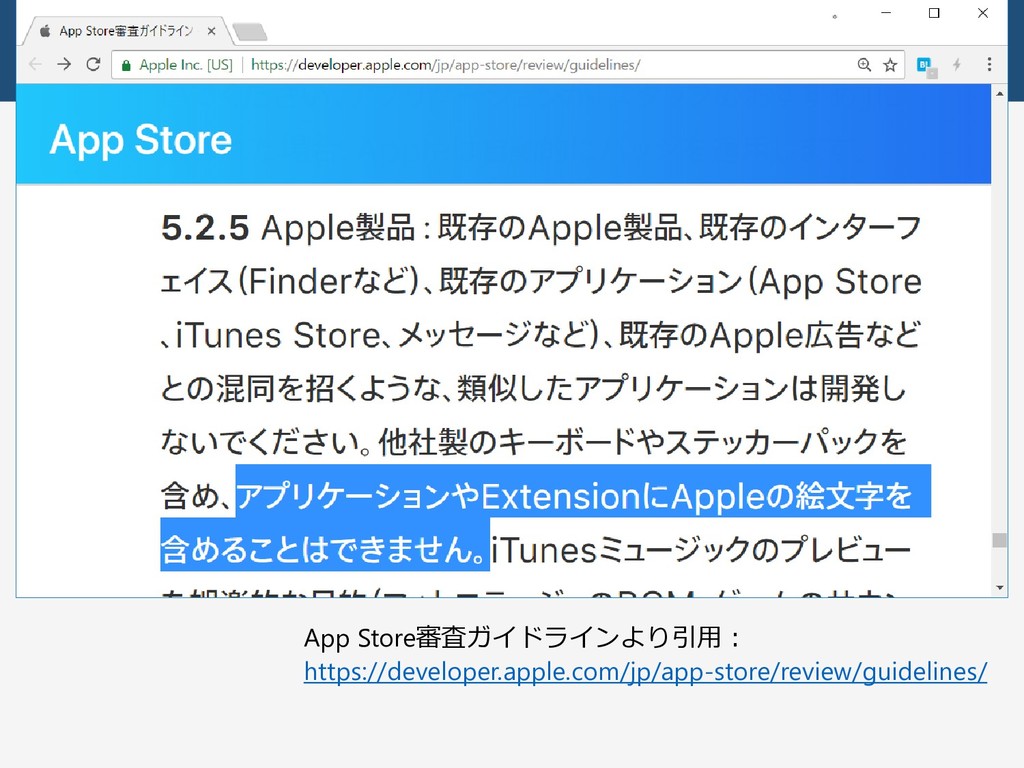
Appleの絵文字の著作権 •iPhoneなどの絵文字を、そのままアプリのアイコ ンやデザインに使うことは禁止されている •絵文字を自由に使いたい場合は、Twitterがクリエ イティブ・コモンズとして提供しているアイコン を使うのがオススメ •https://github.com/twitter/twemoji 72
73 App Store審査ガイドラインより引用: https://developer.apple.com/jp/app-store/review/guidelines/
Agenda •1st section “emojiとパスワード” •長くて覚えやくて複雑なパスワード •絵文字でのパスワードクラッキング •2nd section “Unicodeとセキュリティ” •UTF-8/UTF-16/UTF-32
•文字コードで懸念される脆弱性 74
参考文献 • プログラマのための文字コード技術入門,矢野 啓介, 技術評論社 • 楽しい文字コード入門 知っておきたいUnicode Emoji編 •
https://speakerdeck.com/todokr/le-siiwen-zi-kodoru-men-zhi- tuteokitaiunicode-emojibian • 本当は怖い文字コードの話 第4回 UTF-8の冗長なエンコード • http://gihyo.jp/admin/serial/01/charcode/0004 75
著作権表示 • 本スライド内の絵文字画像の著作権は、以下に帰属します。 Copyright 2018 Twitter, Inc and other contributors
/ CC BY 4.0 https://github.com/twitter/twemoji 76
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![1部まとめ •とりあえずパスワードに絵文字入れても意外に 通る •これからは絵文字パスワードが流行る[要出典] ハニーポットで、非ASCII文字のパスワードで来 ている例がある方はぜひ教えてください (私はまだ観測していません) 51](https://files.speakerdeck.com/presentations/a956cc3786fa41f8a2fa7592547995d5/slide_50.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![UTF-16の特徴 •16ビットを単位とし、歴史的にはもっとも正統(?)な 表現 • JavaやWindowsの内部コードとして利用されていることで 有名 •BMP(面0)では、code pointとコード値が一致する •SMPなど面0以外を扱うために魔改造がほどこされ、 とても分かりにくい[要出典]](https://files.speakerdeck.com/presentations/a956cc3786fa41f8a2fa7592547995d5/slide_64.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![emoji = emotion icon ? 71 海外では、emojiを日本語の”絵文字”と知らずに、emotion icon(emoticon)からの造語と思っている人が結構多い[要出典] https://www.reddit.com/r/todayilearned/comments/6fwuxi/til_the_word_emoji_has_no_connection_to_emotion/](https://files.speakerdeck.com/presentations/a956cc3786fa41f8a2fa7592547995d5/slide_70.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}