Giampiero Marra 2 Rosalba Radice 3 1,2Department of Statistical Science, University College London 3Department of Economics, Mathematics and Statistics, Birkbeck, University of London July 4, 2017 SAM conference, University of Liverpool
accounts for several types of covariate effects (e.g., linear, non-linear and spatial effects) residual dependence between the responses. Example: model jointly multiple births (i.e., twins, triplets, etc.) premature birth (i.e., infant was born before completing the 37 gestational week) low birth weight (i.e., infant’s birth weight is ≤ 2500 grams). Trivariate probit models deal with these problems.
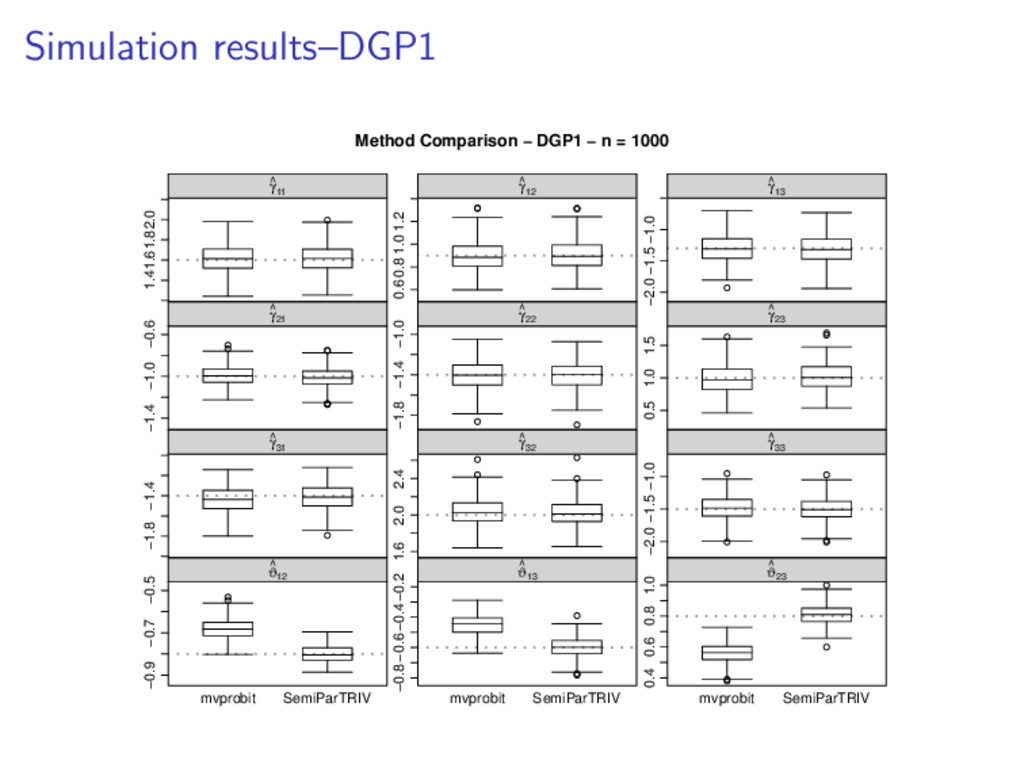
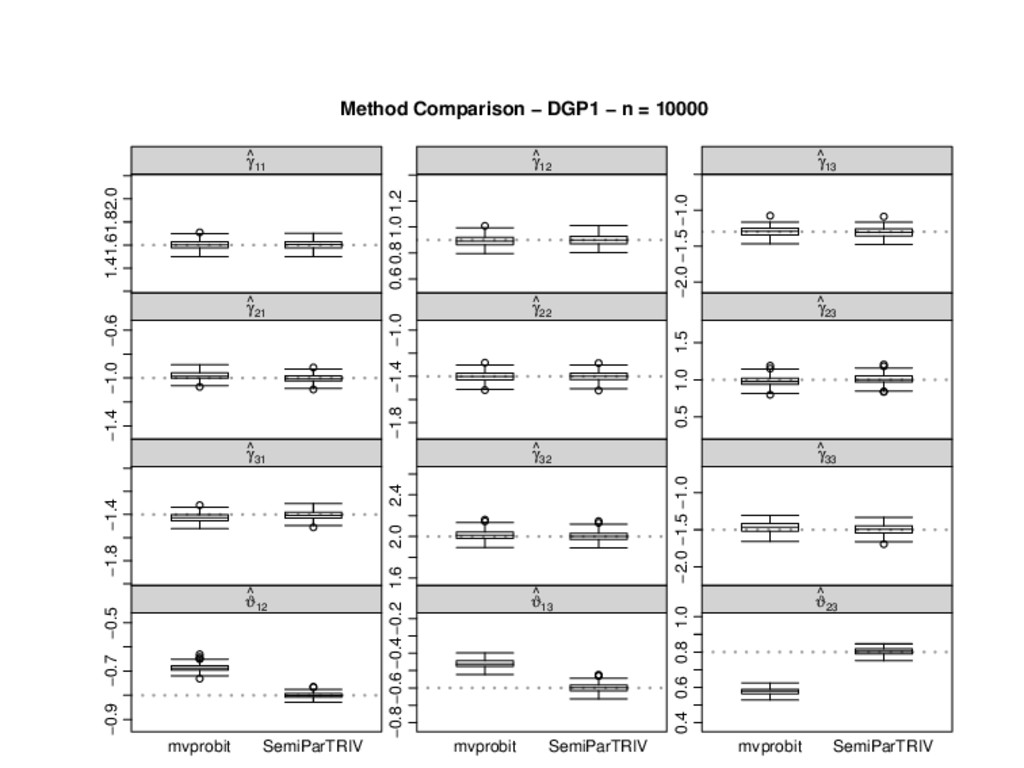
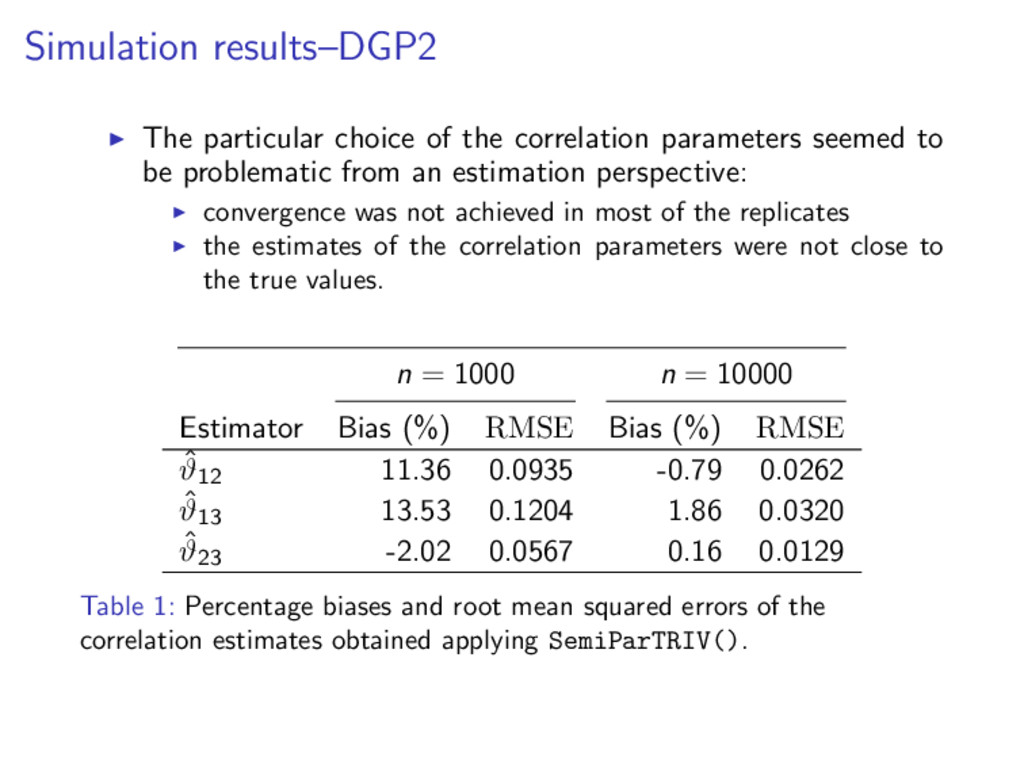
to be problematic from an estimation perspective: convergence was not achieved in most of the replicates the estimates of the correlation parameters were not close to the true values. n = 1000 n = 10000 Estimator Bias (%) RMSE Bias (%) RMSE ˆ ϑ12 11.36 0.0935 -0.79 0.0262 ˆ ϑ13 13.53 0.1204 1.86 0.0320 ˆ ϑ23 -2.02 0.0567 0.16 0.0129 Table 1: Percentage biases and root mean squared errors of the correlation estimates obtained applying SemiParTRIV().
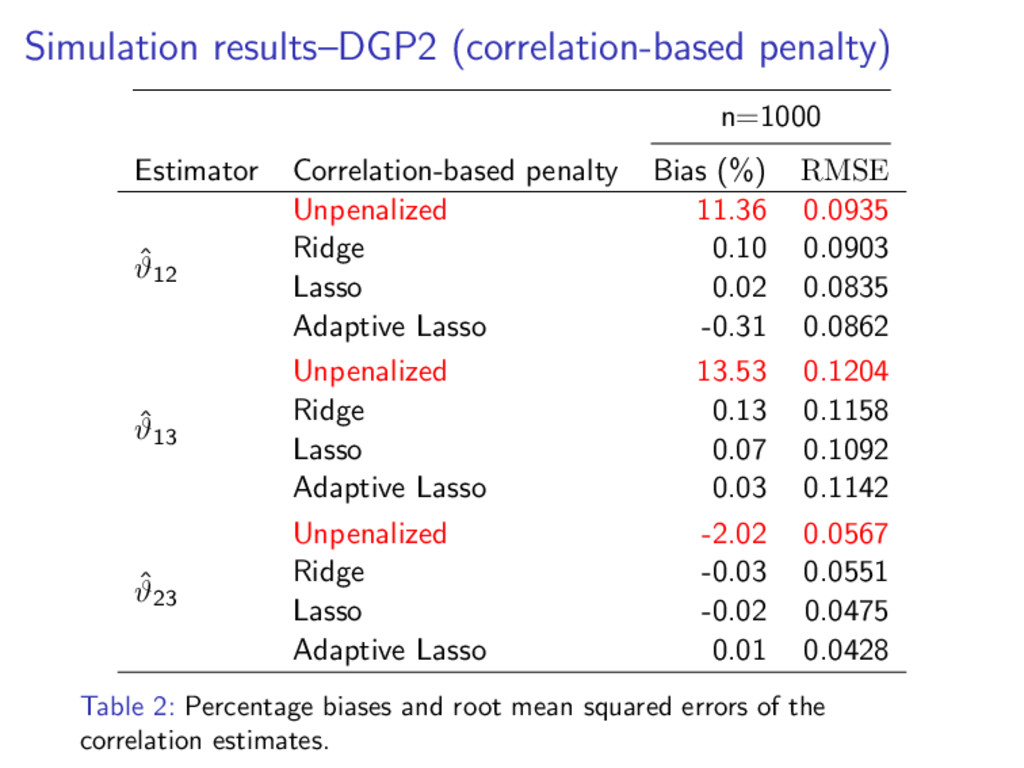
be addressed by optimization of ˆ δ := arg min δ − (δ) − 1 2 δ ˜ Sλδ − Pλϑ (δ) , where Pλϑ (δ) is a penalty acting on the correlations. In this work, we employ the Ridge, Lasso and Adaptive Lasso ap- proaches. The non-differentiability of the Lasso and Adaptive Lasso can be avoided by employing the local quadratic approximation ap- proach Pλϑ (δ) ≈ 1 2 δ Λλϑ δ, where Λλϑ = 0Q×Q 0Q×3 03×Q Aλϑ .
which provides details on infant and maternal health, and parental characteris- tics using 2007−2008 birth data from the North Carolina Center of Health Statistics (http://www.schs.state.nc.us/). Aim: analyse jointly multiple births (= 1 if singleton and = 0 if twins, triplets, quadruplets and quintuplets) premature birth (= 1 if infant was born before completing the 37 gestational week and = 0 otherwise) low birth weight (= 1 if infant’s birth weight is ≤ 2500 grams and = 0 otherwise). Parameter estimation was carried out without the need of im- posing a penalty on the correlation coefficients.
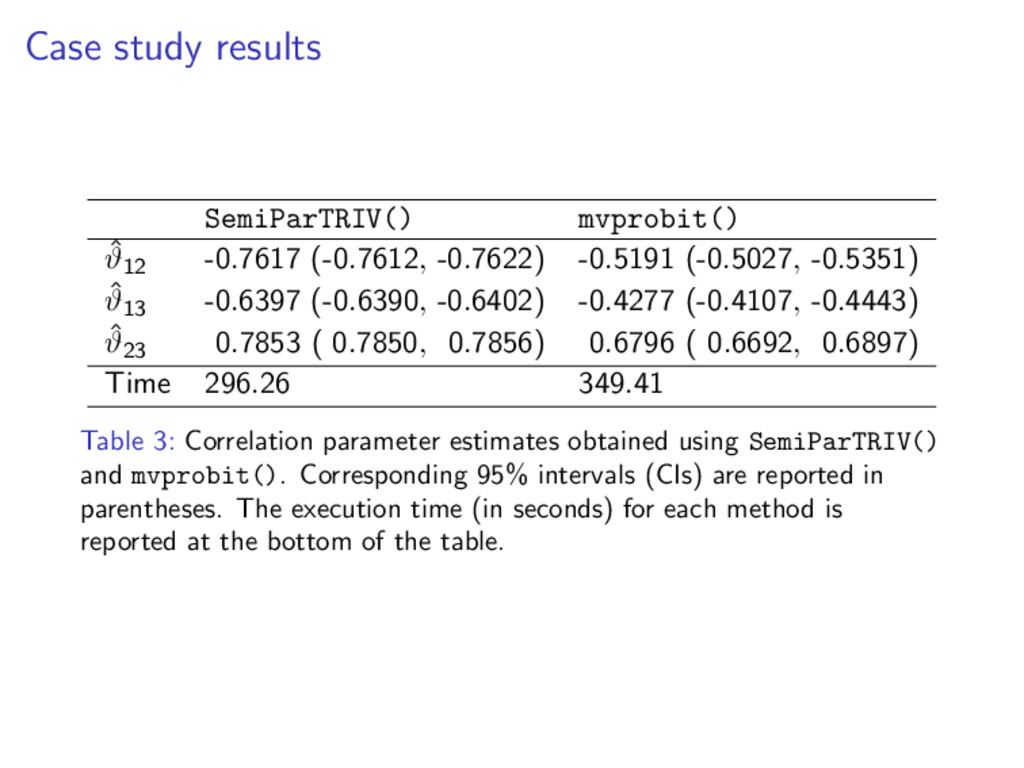
-0.5191 (-0.5027, -0.5351) ˆ ϑ13 -0.6397 (-0.6390, -0.6402) -0.4277 (-0.4107, -0.4443) ˆ ϑ23 0.7853 ( 0.7850, 0.7856) 0.6796 ( 0.6692, 0.6897) Time 296.26 349.41 Table 3: Correlation parameter estimates obtained using SemiParTRIV() and mvprobit(). Corresponding 95% intervals (CIs) are reported in parentheses. The execution time (in seconds) for each method is reported at the bottom of the table.
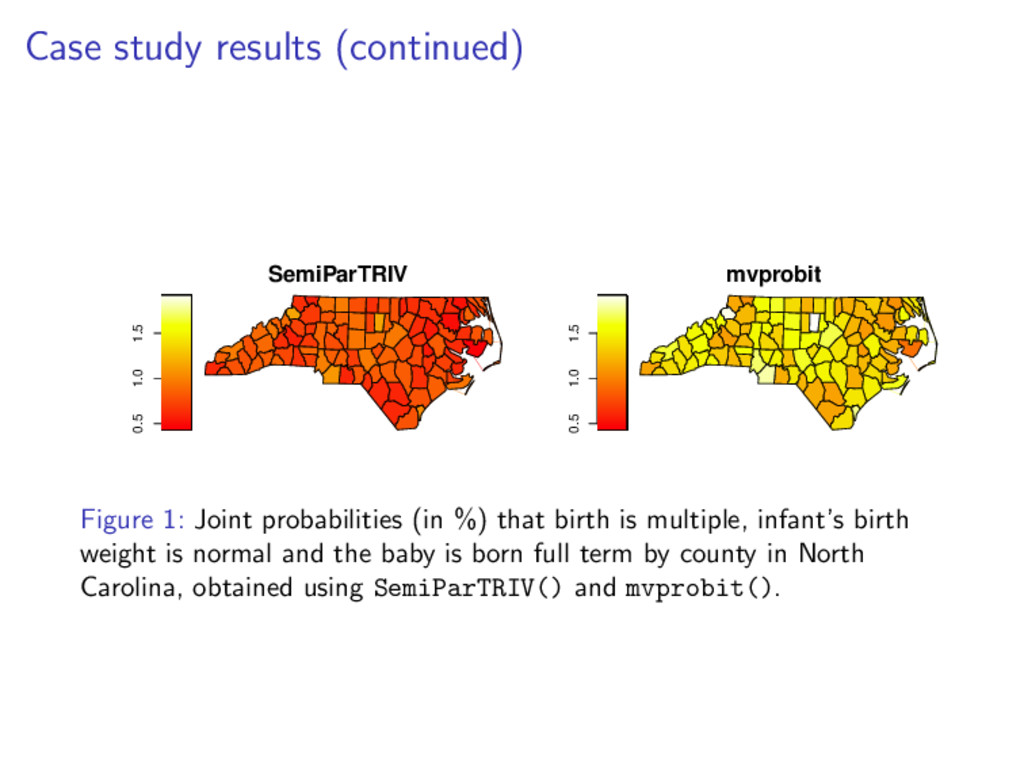
1.5 mvprobit Figure 1: Joint probabilities (in %) that birth is multiple, infant’s birth weight is normal and the baby is born full term by county in North Carolina, obtained using SemiParTRIV() and mvprobit().
Endogeneity of a treatment variable Non-random sample selection of individuals into (or out) of sample. Trivariate Models deal with these problems: Endogenous trivariate model Double sample selection model Endogenous–sample selection model. Extension II: Trivariate Gaussian copula models with arbitrary margins Φ3 Φ−1(F1 (η1i )), Φ−1(F2 (η2i )), Φ−1(F3 (η3i )) , where Fm (ηmi ) can be either the normal, logistic or Gumbel univariate cdf, ∀m = 1, 2, 3.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}