축소시켜서 document의 subset을 candidate으로 반환 - High recall, high efficiency 이 핵심 - 아직 옛날 기법(TF-IDF, BM25)을 사용하고 있음 2. Scoring phase - Retrieval을 통해 찾은 document를 reranking함 - BERT를 필두로 비교적 많은 발전을 이룸
축소시켜서 document의 subset을 candidate으로 반환 - High recall, high efficiency 이 핵심 - 아직 옛날 기법(TF-IDF, BM25)을 사용하고 있음 2. Scoring phase - Retrieval을 통해 찾은 document를 reranking함 - BERT를 필두로 비교적 많은 발전을 이룸
를 구하는 문제 - (Retrieval의 output은 이 relevance가 높은 것들) - 추천 시스템이면 가 추천 상품(item) 후보 - Multi-label classification이라면, 는 input document, 는 category나 hashtag - 핑퐁은 가 session(context, reply) q d f(q, d) d q d d
그럼 어떻게?? - BERT-style (e.g., BERT, XLNET, RoBERTa) 모델들이 상당히 좋은 성능을 보임 - 하지만 이들은 모두 cross-attention model*들임 - 따라서, large-scale retrieval에 이를 적용하기에는 비용(속도) 문제가 있음 - 그래서 보통 retrieval phase에서는 간단히 돌리고 scoring phase에서 BERT를 씀 q d f * 와 를 concat해서 modeling하는 구조 q d
(IR) - 보통 classic한 information retrieval (IR) 기법을 사용함 - BM25 (Robertson et al., 2009), TF-IDF 2. Embedding-based Retrieval - 와 각각을 encoding해서 embedding을 뽑고, 내적 or cosine sim을 통해 relevance를 계산 - Inference stage에는 에 대해서 embedding space 상의 nearest neighbors를 찾으면 됨 - Document Candidate의 embedding을 모두 미리 계산(pre-computed)할 수 있다는 게 장점 q d q
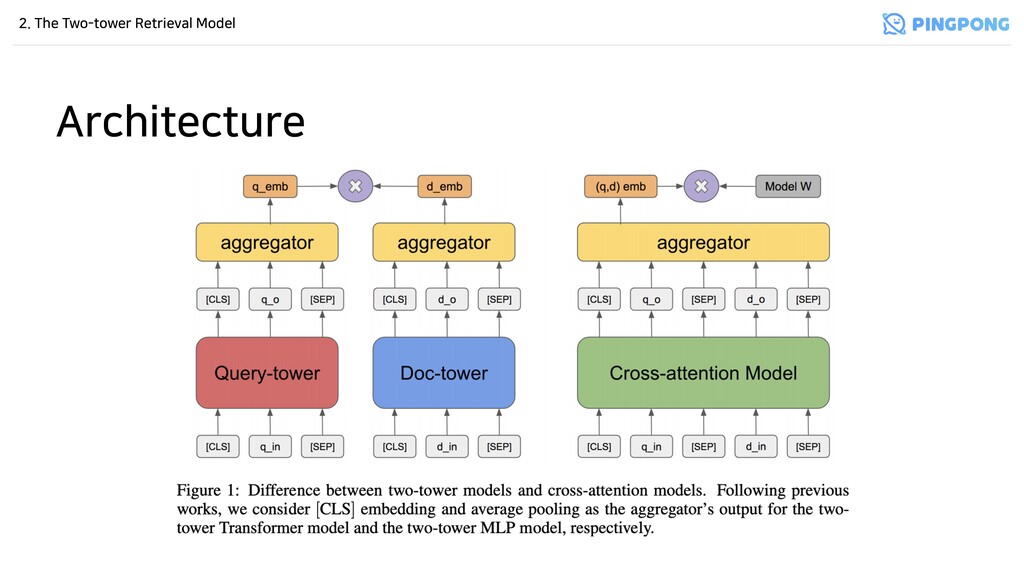
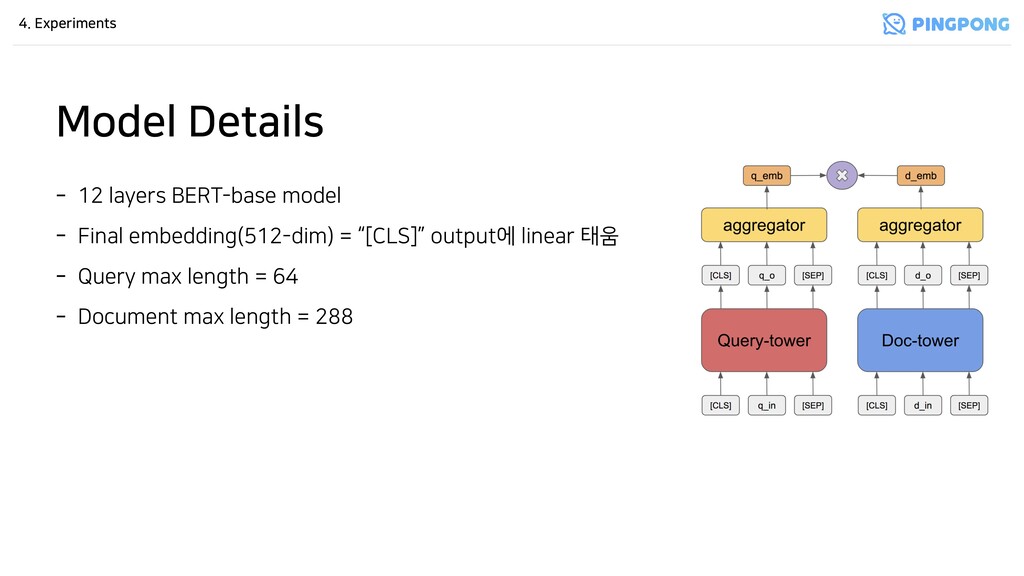
심플함 - Query-tower(query encoder)와 Doc-tower(document encoder)가 독립적으로 query와 document를 encoding함 - 두 embedding vector에 대한 inner product(cosine similarity)로 relevance를 계산함 - Aggregation은 average pooling을 사용.
대한 CE가 아니고, 하나의 와 여러 개의 에 대한 CE라는 게 특이 - 계산 비용을 줄이기 위해 Sampled Softmax라는 full-Softmax의 approximation을 사용함 - Sampled Softmax: 를 전체 document가 아니라 batch 내의 document로 구성된 작은 subset으로 치환하여 approaximation을 하는 것 (q, d) q d pθ (d|q) = exp(fθ (q, d)) ∑ d′ ∈ exp(fθ (q, d′ ))
Granularities 1. Downstream task와 관련이 있어야 함 - QA retrieval 문제를 풀려면, pre-training에서 query와 document 간의 미묘한 의미적 차이를 모델이 잡아낼 수 있게 해줘야 함 2. 수집하는 비용이 적어야 함 - 사람이 직접 supervision할 수 없음
Inverse Cloze Task (Lee et al., 2019) 2. Body First Selection (newly proposed) 3. Wiki Link Prediction (newly proposed) 4. Masked Language Modeling (Devlin et al., 2019)
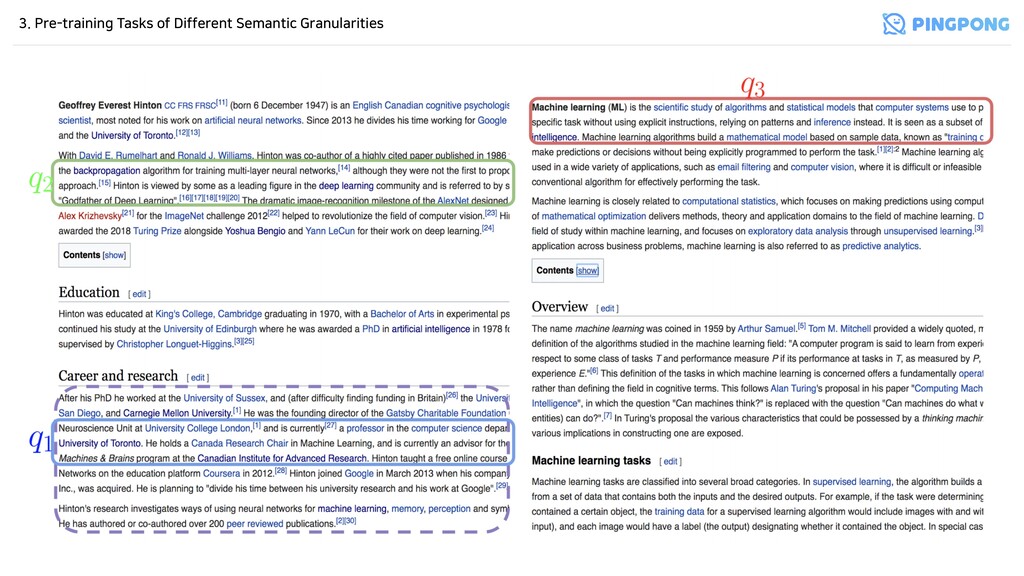
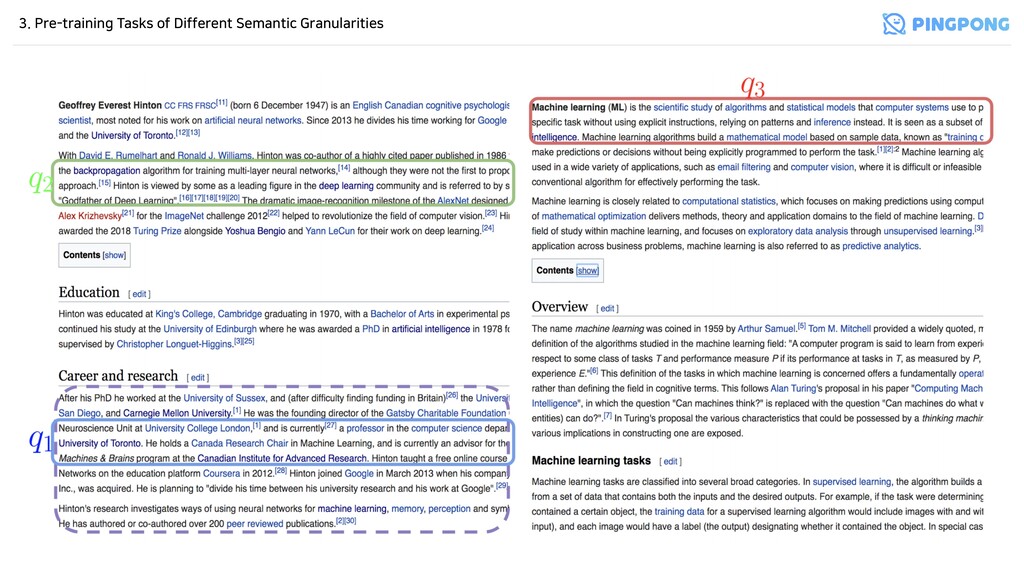
Semantic Granularities - Local context within a paragraph - 주어진 개의 문장으로 구성된 passage 에 대해서 - 임의의 한 문장 (where ) 를 뽑고, 나머지 문장들의 집합을 document 로 만들어서, 최종 (positive) sample 를 만듬 - Figure 2에서 에 해당됨 n p = {s1 , s2 , . . . , sn } q = si i ∼ [1,n] d = {s1 , . . . , si−1 , si+1 , . . . , sn } (q, d) (q1 , d)
Semantic Granularities - Global consistency within a document - ICT와 같이 local paragraph가 아닌 외부 passage와의 관계를 학습 - Wiki 특정 페이지의 첫 section에서 하나의 를 뽑고, 해당 페이지의 passage 중 임의로 를 뽑음 - 첫 section에서 를 뽑는 이유: - 주로 해당 페이지의 전반적인 description이나 summary가 적혀있음 → 해당 페이지의 내용을 대부분 커버할 수 있기 때문 - Figure 2에서 에 해당됨 q2 d q (q2 , d)
Semantic Granularities - Semantic relation between two documents - Wiki 특정 페이지의 첫 section에서 하나의 를 뽑고, 해당 페이지로 hyperlink가 걸려있는 문서 중 하나에서 document 를 뽑음 - Figure 2에서 에 해당됨 q3 d (q3 , d)
corpus로부터 생성함 - ICT의 경우 를 Doc-tower로 encoding할 때, article의 title과 passage를 "[SEP]"로 분리하여 input을 구성함 - Two-tower Transformer를 위의 세가지 paragraph-level pro-training task에 대해서 jointly 학습을 함 (Multi-task Learning) - 모두 쌍으로 training sample이 존재하며, 각 sample은 uniformly sampling 됨 d (q, d) * #tokens는 WordPiece로 tokenizing된 sub-words의 수를 의미함
Natural Question - 원래 QA에서는 형태로 sample이 구성됨 - : question - : answer span - : evidence passage containing - 문제: 주어진 에서 에 대한 정답 찾기 ( ) (q, a, p) q a p a p q a q, p → a
아니라 retrieval 성능! - 그래서 를 로 sample 구성을 바꿈 - : question - : sentence containing answer span - : evidence passage containing - 문제: 주어진 에 대해서 모든 중에 적절한 찾기 ( ) (q, a, p) (q, si , p) q si a p = {s1 , s2 , . . . , sn } a q (s, p) (si , p) q → si , p
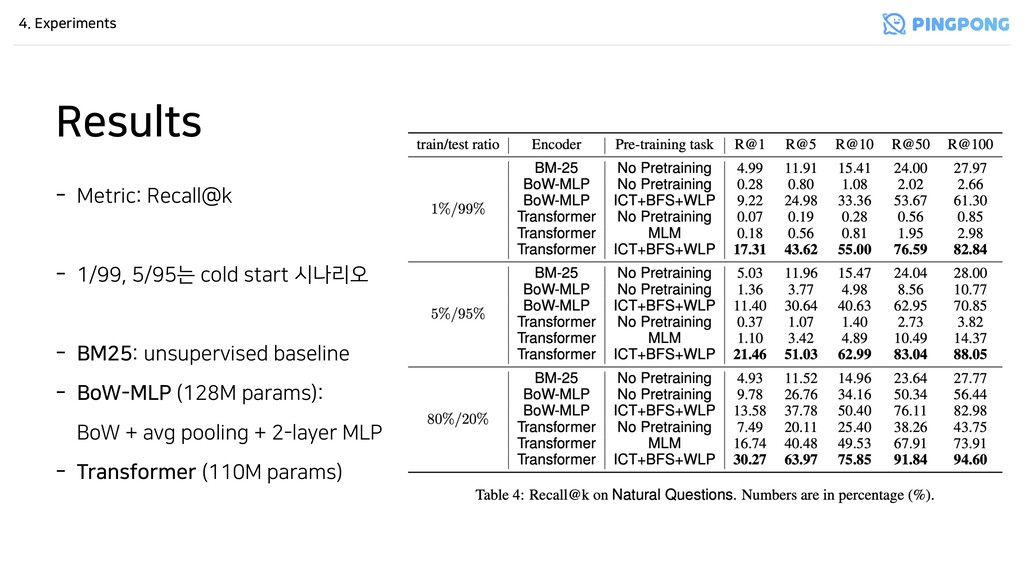
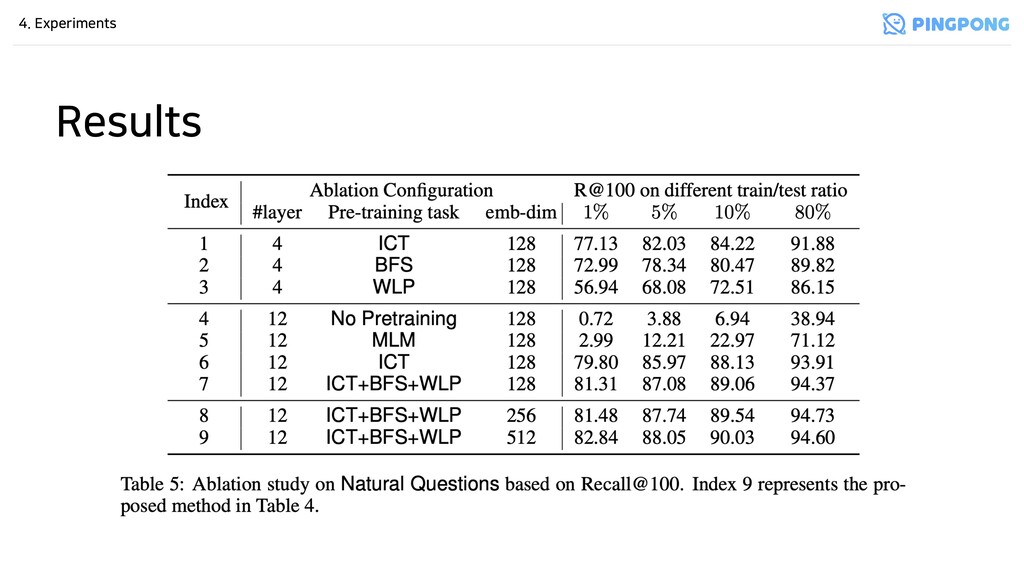
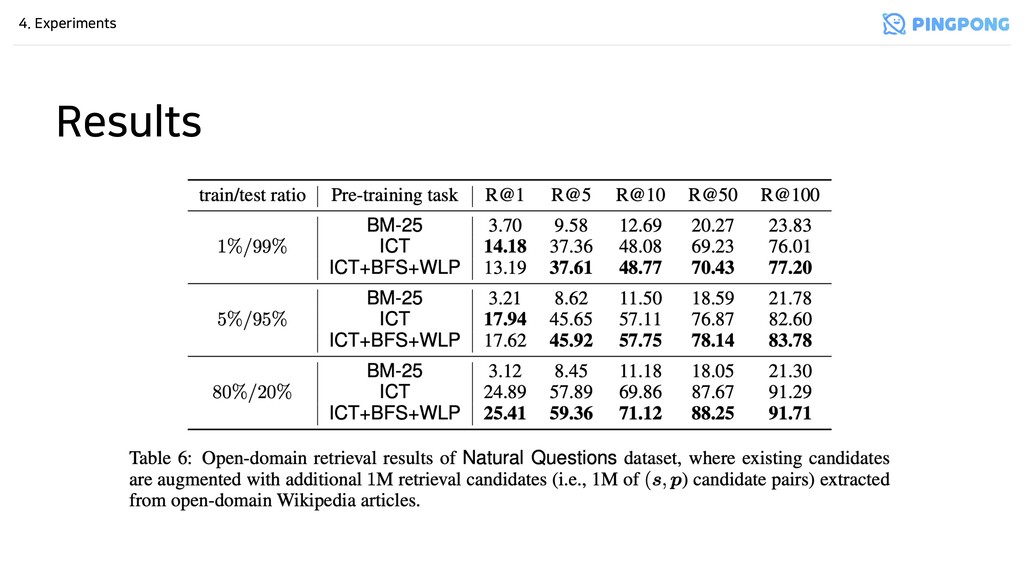
별로일 수 있음 - 그만큼 BM25가 심플하지만 tough-to-beat - ICT, BFS, WLP로 pre-training을 하면 Two-tower Transformer가 더 성능이 좋음 - Future Work - 어떻게 다른 유형의 encoder architecture에도 이 pre-training tasks를 적용할지 - Wikipedia 말고 다른 corpus에서 pre-training data를 생성할 방법
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}