◦ 장기 기억 (Long Term Memory)의 부재 ◦ 구체적이지 않은 답변 (몰라요. 알겠어요 등등) ◦ 일관된 페르소나의 부재 ◦ 상식의 부재 등등... • 질 높은 데이터셋의 부재가 원인 아닐까? ◦ 위의 문제들 중 일관된 페르소나의 부재를 데이터셋의 구축을 통해 극복하자! ◦ 클라우드 소싱으로 페르소나 데이터셋을 구축하자! →Personalizing Dialogue Agents: I have a dog, do you have pets too? (ACL 2018) ◦ 클라우드 소싱으로는 부족하다 ! Reddit 데이터를 이용해서 대량의 페르소나 데이터셋을 구축하자! →Training Millions of Personalized Dialogue Agents (EMNLP 2018) • 두 가지 방법으로 수집한 데이터셋으로 대화 모델을 학습시켰을 때 대답이 더 일관성 있고, 유저 만족도가 향상됨을 실험을 통해 검증 • 모델링 방법보단 데이터셋 구축 방법에 좀 더 초점을 맞춤.
더 매력적이고, 인간적인 chit-chat 대화를 가능하게 하는 것이 목표 ◦ Amazon Mechanical Turk를 이용하여 클라우드 소싱 ◦ 데이터 수집은 총 3가지 스테이지로 이루어짐 ▪ Personas: 1155개의 페르소나를 클라우드 소싱 ▪ Revised personas: 더 도전적인 데이터셋을 만들기 위해 문장을 Rephrase ▪ Persona chat: 두 명의 클라우드 소서들이 랜덤한 페르소나로 서로 대화하도록 • Next Utterance를 Prediction할 수 있는 몇 가지 모델들을 이용하여 PERSONA-CHAT 데이터셋의 효용성을 검증 ◦ Ranking ◦ Generation
관심사나 평범한 주제들을 포함시키는 것 • 방법 ◦ 하나의 페르소나에 대해 최소 5문장으로 이루어지도록 지시 ◦ 각 문장들이 최대 15단어 정도인 짧은 문장이 되도록 지시 ▪ 너무 길어지면 클라우드 소서들이 흥미를 잃고, 기계에게 너무 어려운 태스크가 되어버림 ◦ 단, 개인 정보 유출 방지 및 다양성을 위해 클라우드 소서 자신의 프로필을 쓰지 않도록 지시
어렵게 구축하지 않도록 하기 위함 ▪ 잘 알려진 QA 데이터셋인 SQuAD의 경우, 단순한 단어 overlap만으로 맞출 수 있는 케이스가 다수 존재 • 방법 ◦ 새로운 클라우드 소서들을 고용해서 문장을 새로운 문장으로 rephrase하도록 지시 ▪ ‘난 농구를 좋아해'→ ‘난 마이클 조던의 광팬이야’ ▪ 완전히 동일한 의미로 리프레이징하지 않고, 동일한 페르소나가 각각을 포함할 수 있도록 rephrase ◦ 원래 단어를 단순 카피해서 재구성하지 않도록 지시 ▪ ‘내 아빠는 현대 자동차에서 일했어' • ‘내 아버지는 자동차 업계에 종사하셨어’ (O) • ‘내 아빠는 현대 자동차에 몸 담으셨었어’ (X)
생성하기 위함 • 방법 ◦ 두 명의 랜덤 클라우드 소서가 주어진 페르소나로 연극하듯이 대화하도록 지시 ▪ “상대방과 자연스럽게 대화하면서 서로에 대해 알아가라”라고 지시 • 기존 연구에서 자신에 대해 너무 많이 말하려는 경향이 있다는 것을 발견했기 때문 • “상대방과 교대로 질문/답변해라”라고 지시 ▪ 고퀄 대화에는 보너스를 지급! ◦ 턴 베이스 기반이고, 각 문장은 15단어 미만이 되도록 지시 ◦ 페르소나 문장을 그대로 가져다 쓰지 못하도록 지시 ▪ 페르소나 문장과 단어 매칭이 되면 에러 메시지를 보냄 ◦ 각 대화는 6-8턴이 되도록
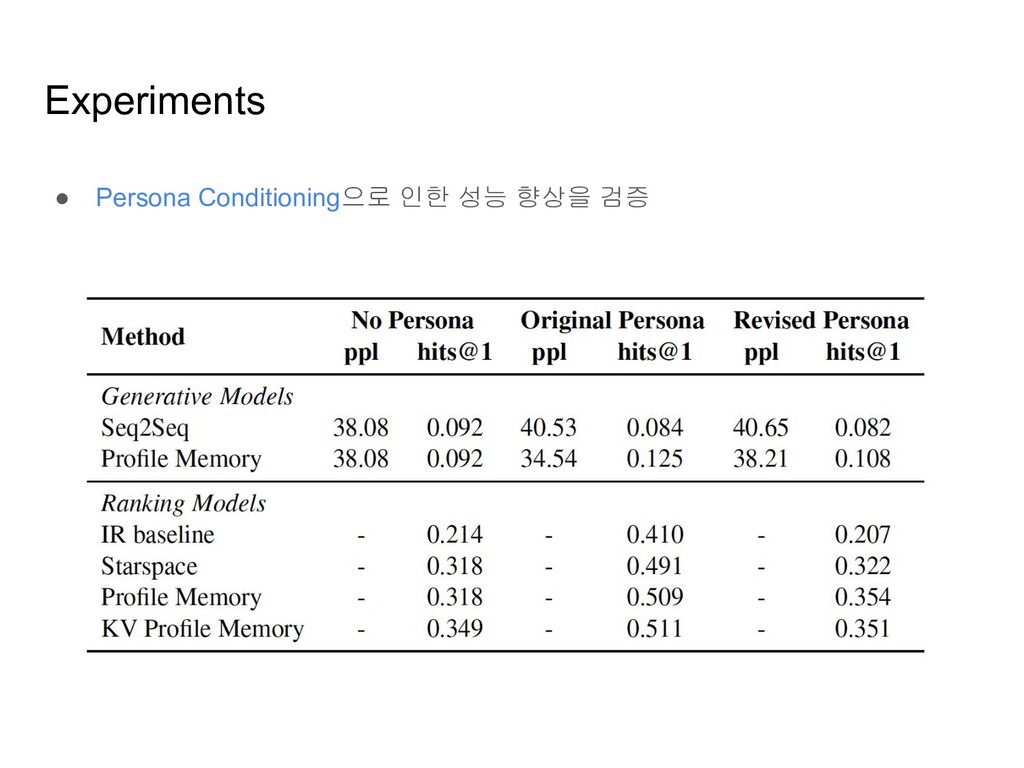
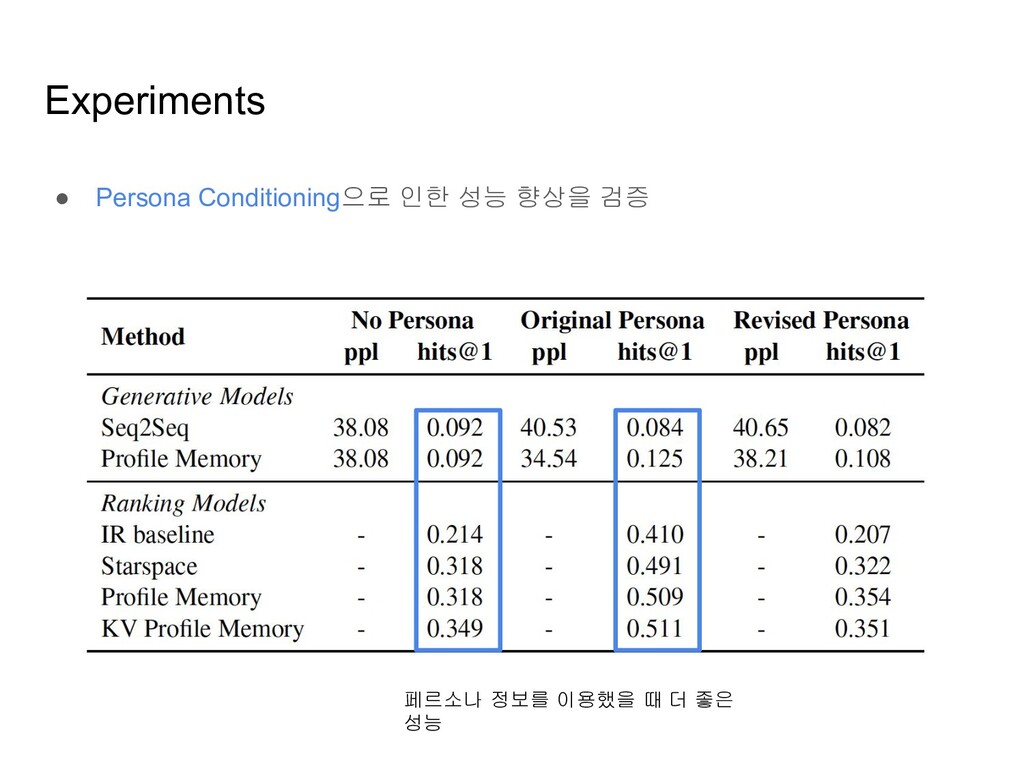
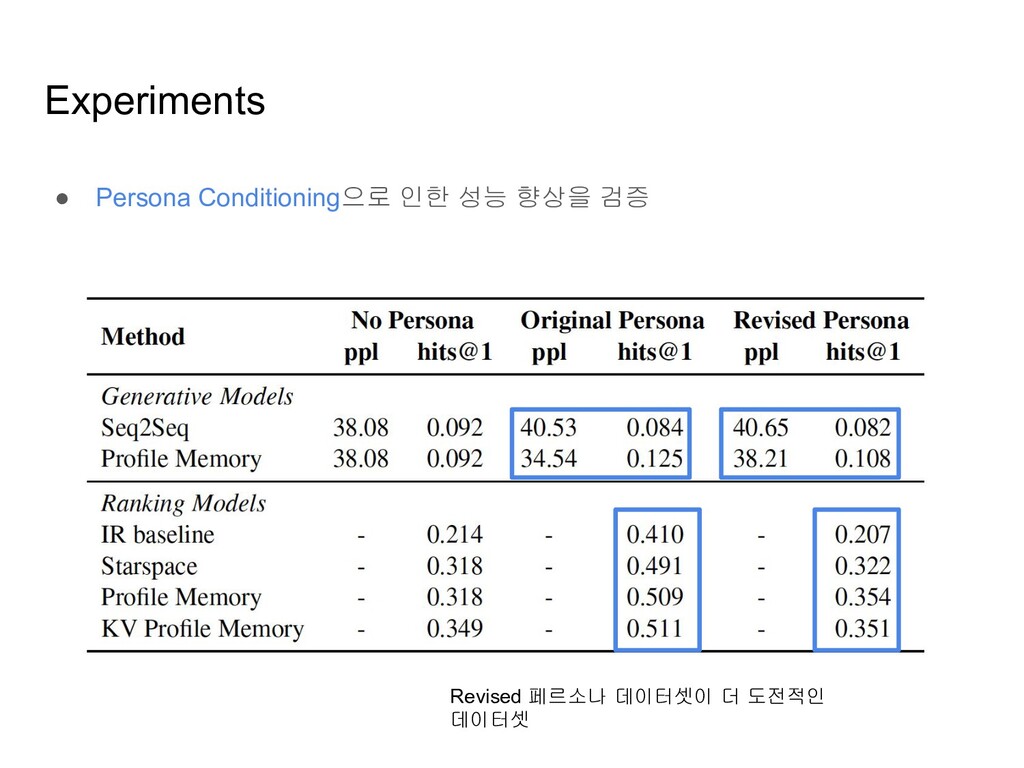
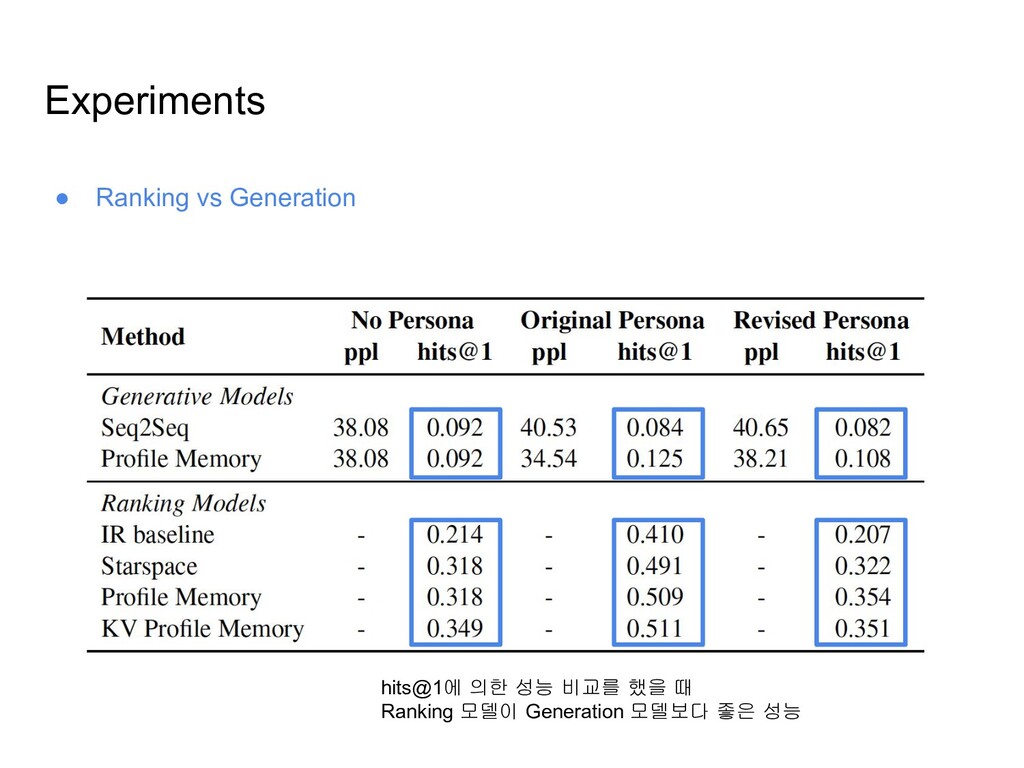
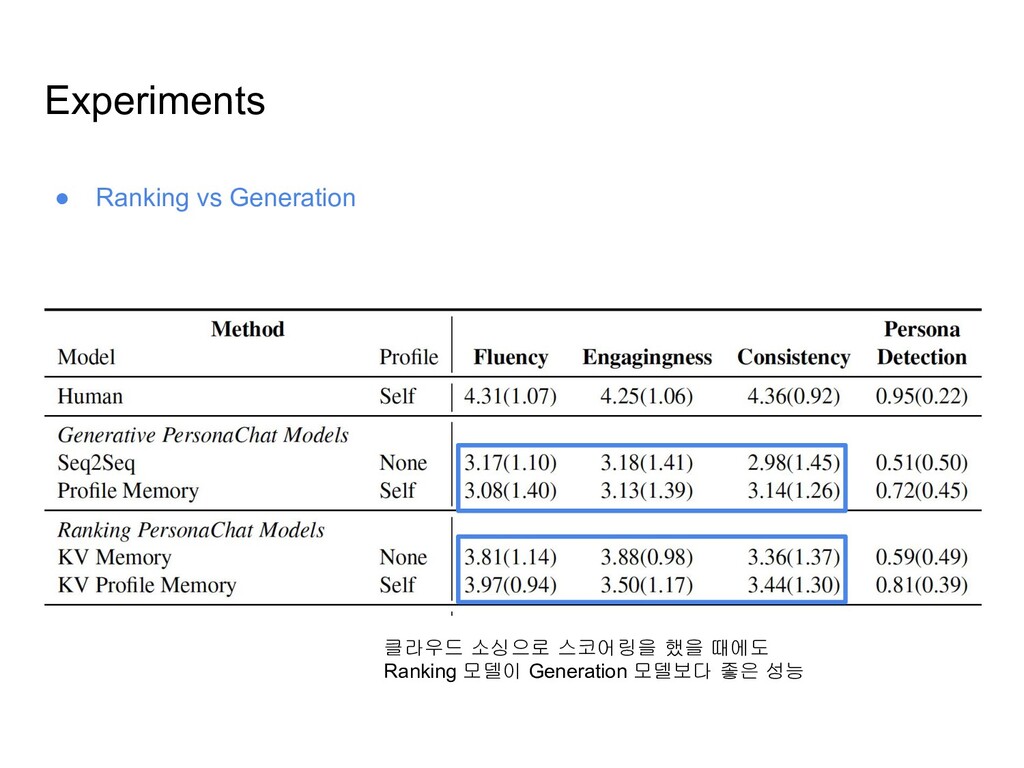
models ◦ 훈련 셋의 reply들을 possible candidates로 생각하고, 각 reply들에 점수를 매겨 순위를 매기는 모델 • Generation-based models ◦ Dialogue history와 Persona를 조건으로 하여, 답변 단어들을 순차적으로 생성해나가는 모델
셋 내에서 가장 유사한 Utterance를 tf-idf similarity를 이용하여 검색 ◦ Starspace ▪ (Dialog+Persona)와 Next Utterance간의 유사도를 단어 임베딩의 합 벡터의 cosine similarity를 이용하여 측정 후, 제일 유사한 Utterance를 선택 • Ranking Profile Memory Network ◦ Dialogue history를 input query로 입력하고, 각 profile sentence에 대한 Attention 값을 학습 ◦ candidates와 q+의 유사도를 이용하여 랭킹을 매김 • Key-Value Profile Memory Network ◦ Dialogue history를 Keys, Next Dialogue Utterances를 Values로 하는 메모리 네트워크 ◦ Ranking Profile Memory Network에서 구해진 q+를 이용하여 각 key에 대한 attention 값을 구하고, Value의 가중합을 만들어 새로운 query embedding q++를 생성
◦ Persona는 인풋 시퀀스에 concat하여 입력 • Generative Profile Memory Network ◦ Seq2seq 모델에서 디코딩을 할때 각 step에서 메모리 (여기서는 프로필 문장들)에 attend하여 persona context vector를 생성하고 이 벡터를 추가로 입력해주는 방식
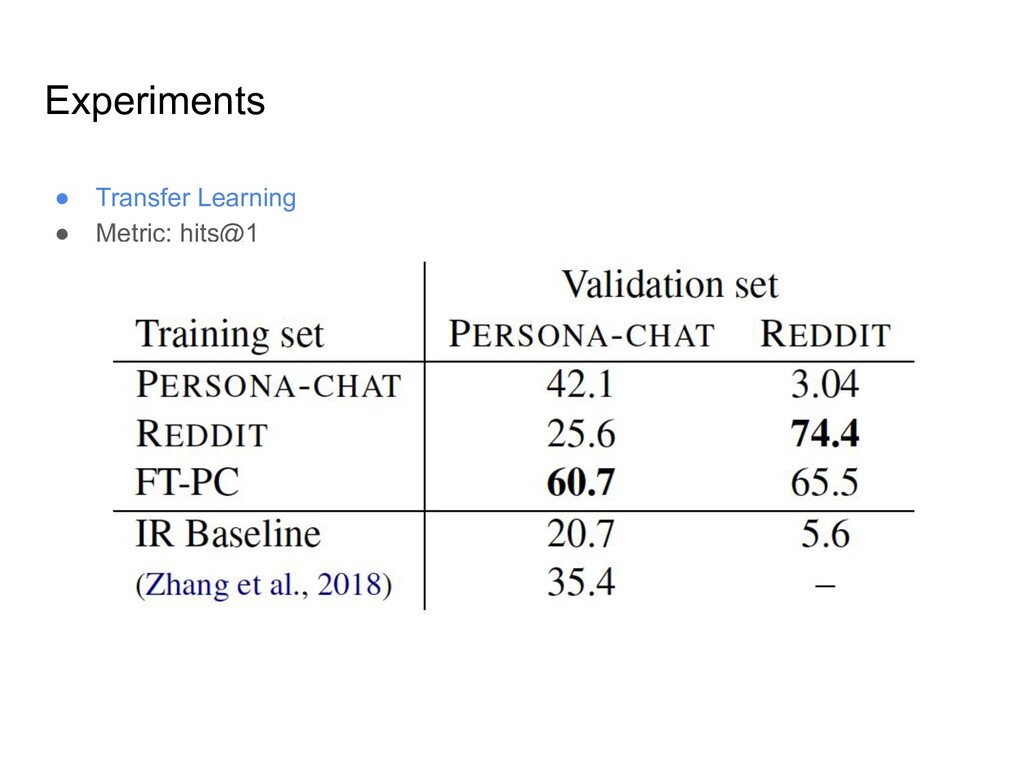
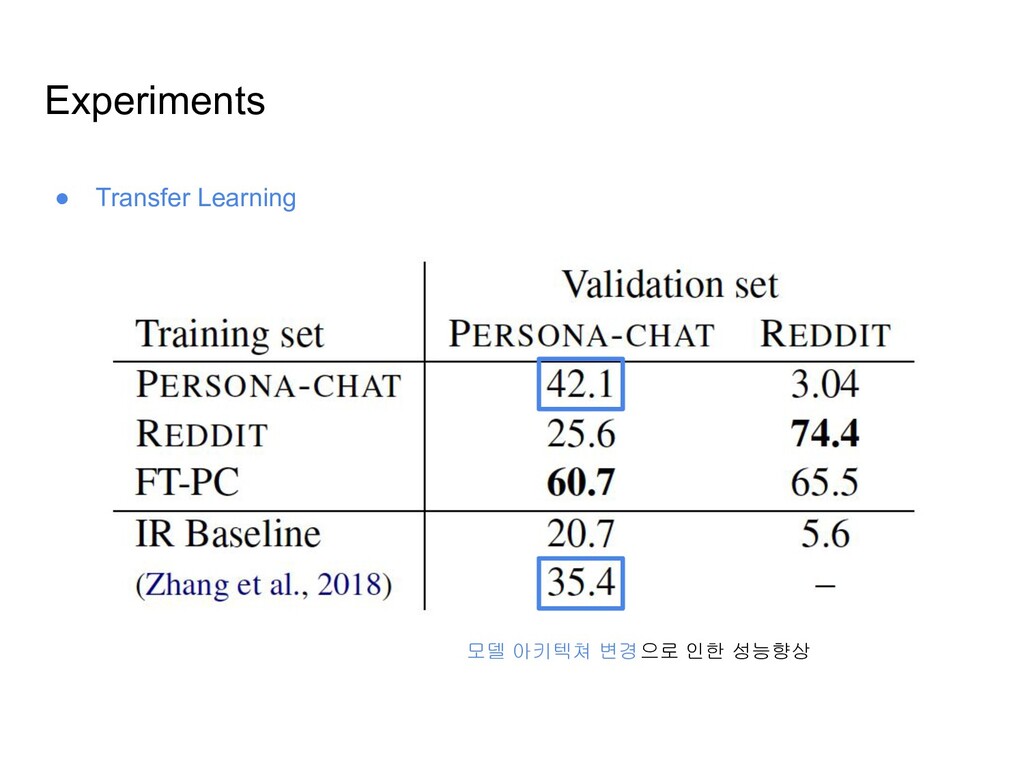
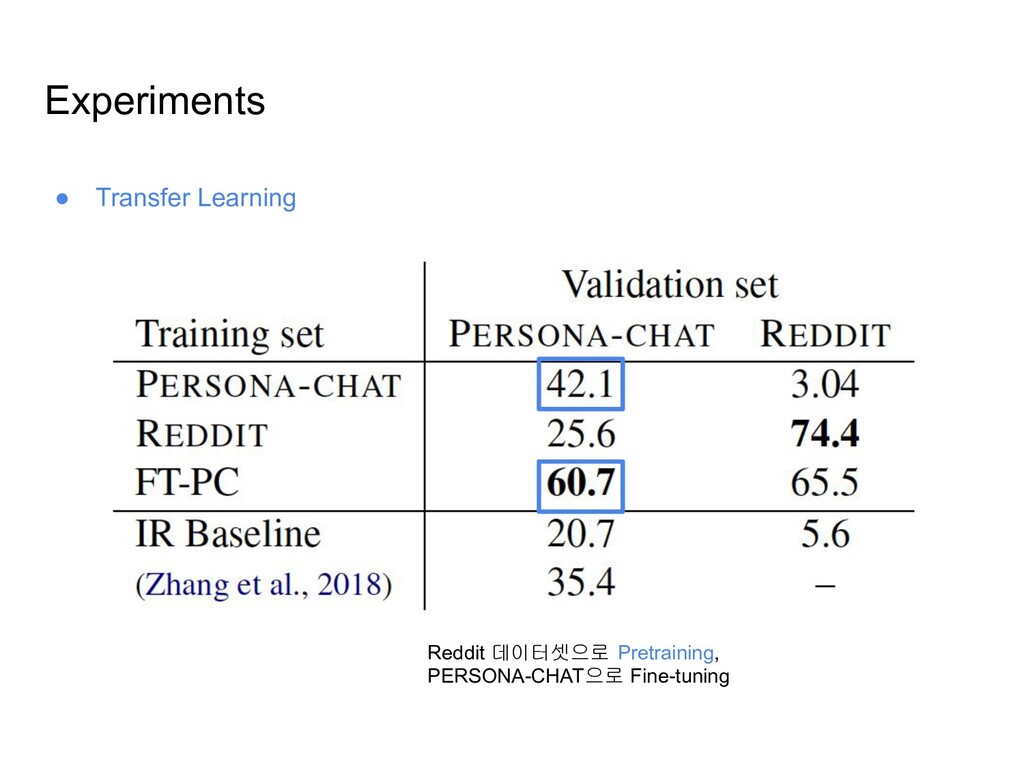
수집한 데이터셋이므로, 실제 human-bot 다이얼로그를 표현하지 못함 ◦ 데이터셋의 커버리지에 한계가 있음 • Reddit 코멘트 데이터를 이용하여 very large 스케일의 페르소나 데이터셋을 구축 ◦ 단순한 휴리스틱을 사용해서 500만개 이상의 페르소나를 생성하고, 7억 문장 이상으로 구성된 다이얼로그 데이터셋을 구축 • 이 데이터셋을 이용하여 pretraining후, PERSONA-CHAT 데이터로 finetuning한 모델이 PERSONA-CHAT 데이터셋에 대해 SOTA 성능을 보임
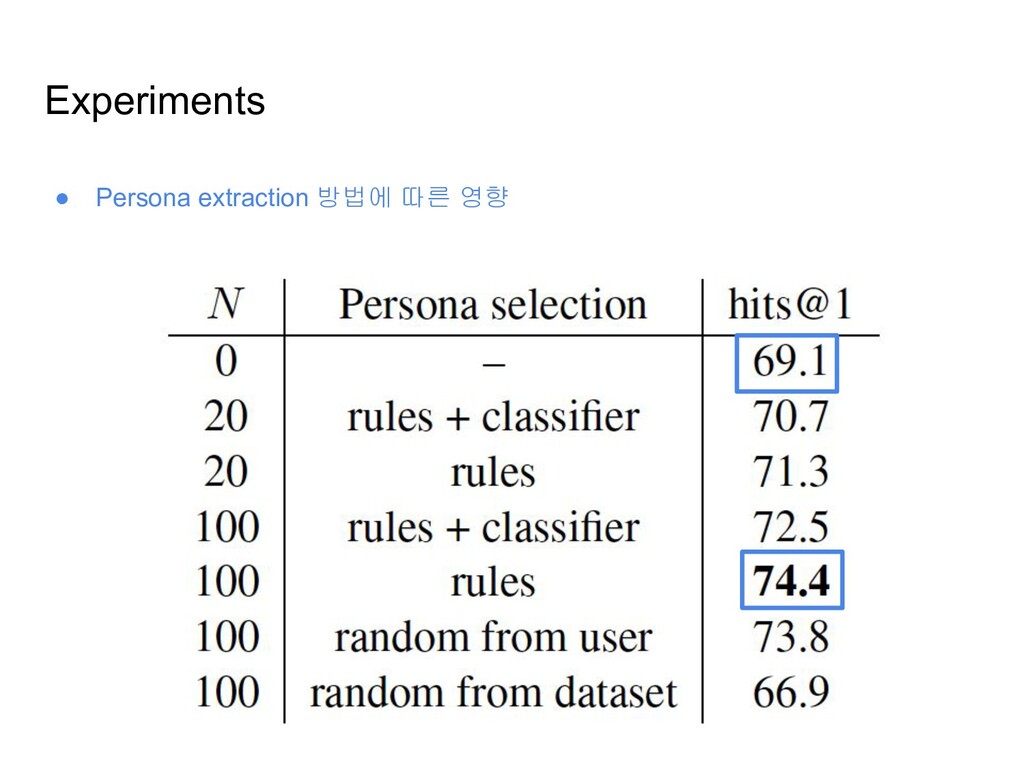
코멘트를 바탕으로 그 유저의 페르소나를 작성하기 위함 • 방법 ◦ 각 코멘트를 문장 단위로 분할 ▪ 각 문장은 4-20단어로 구성되고, 온점을 포함하도록 ◦ 각 문장은 I 혹은 my를 포함하도록 ◦ 각 문장은 적어도 하나의 동사를 포함하고, 적어도 (명사, 대명사, 형용사) 중 하나를 포함하도록 ◦ 데이터 양의 조절을 위해, 페르소나의 사이즈를 N개의 문장 이하로 제한: 4가지 설정으로 N개 문장을 선택 ▪ Rules: 위의 규칙을 만족하는 문장들을 N개 랜덤 선택 ▪ Rules+Classifier:위의 규칙을 만족하고, PERSONA-CHAT 데이터셋으로 학습한 분류기의 스코어가 일정 점수 이상인 문장들을 선택 ▪ Random from user: 위의 규칙 중 길이 규칙만 따르는 유저의 코멘트 문장을 랜덤 선택 ▪ Random from dataset: 전체 데이터셋 내의 문장을 랜덤으로 선택
이용하여 context, response를 구성 ◦ Validation/Test 데이터는 각각 50k의 다이얼로그로 구성 ◦ 훈련 데이터셋에 대해서만 페르소나를 추출 (Persona extraction 방법을 통해) ▪ 테스트 셋의 response에는 명시적인 페르소나가 존재하지 않음 ◦ 레딧 데이터셋 전체 유저 13.2m 가운데 ▪ 룰베이스 설정으로는 4.6m의 페르소나 생성 ▪ 랜덤 설정으로는 7.2m의 페르소나 생성
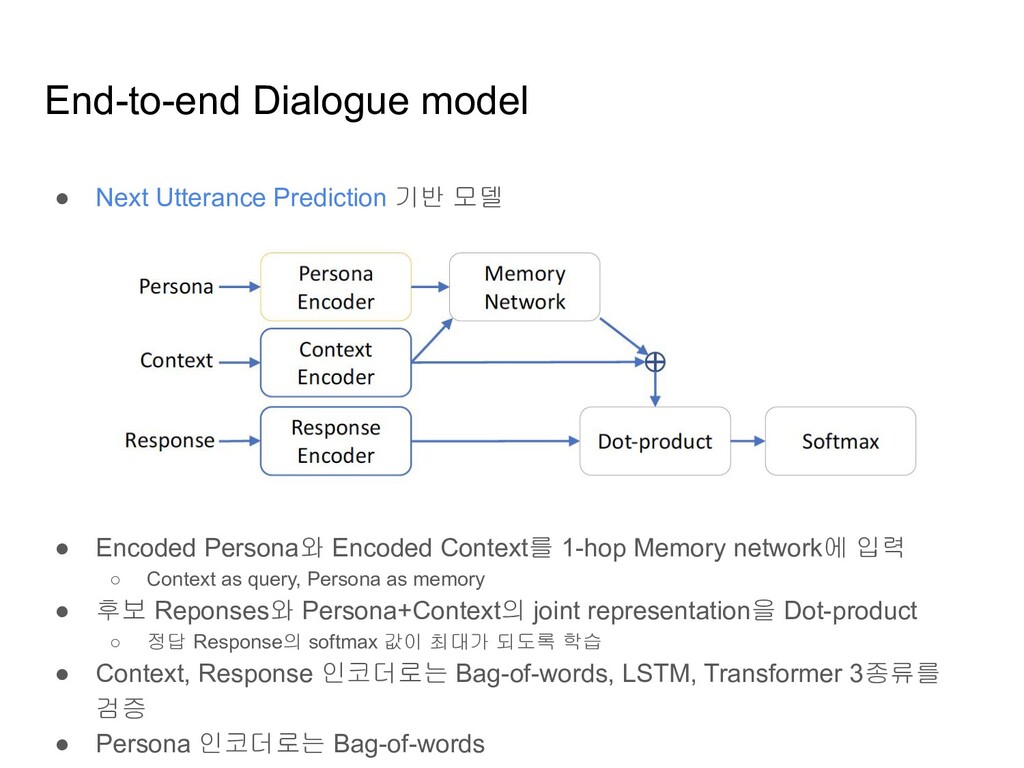
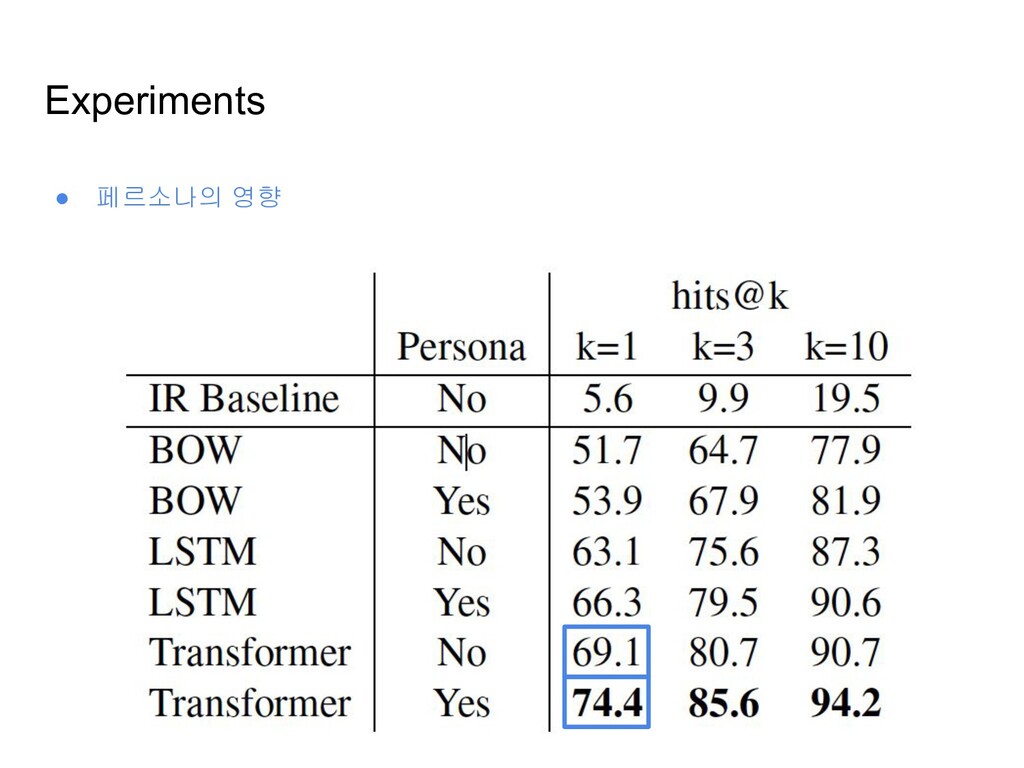
Encoded Persona와 Encoded Context를 1-hop Memory network에 입력 ◦ Context as query, Persona as memory • 후보 Reponses와 Persona+Context의 joint representation을 Dot-product ◦ 정답 Response의 softmax 값이 최대가 되도록 학습 • Context, Response 인코더로는 Bag-of-words, LSTM, Transformer 3종류를 검증 • Persona 인코더로는 Bag-of-words
학습시키기 위한 페르소나 데이터셋을 구축하는 방법을 2가지를 소개함 ◦ 클라우드 소싱 ◦ Reddit • 랭킹 모델/생성 모델을 이용하여 페르소나 데이터셋의 효용성을 검증함 ◦ 아직까진 랭킹 모델이 자동 평가/사람 평가에서 더 좋은 성능을 냄 ◦ 그러나, 랭킹 모델 역시 디테일한 정보가 일관적이지 못할 수도 있을거라 생각 ▪ Persona: “난 여자 아이돌을 좋아한다” ▪ Response: “난 아이돌 중에 방탄소년단이 제일 좋아” ???
방법을 우리도 적용할 수 있지 않을까? ◦ 우리가 갖고 있는 카톡 데이터는 썸타는 남녀, 커플 등등 서로를 알아가는 대화가 다수 포함되어 있음 • 논문에는 언급이 되어 있지 않으나, profile sentences를 수집하다보면 모순되는 profile sentences가 포함될 수도 있을 것 ◦ “난 여자 아이돌 중에 트와이스가 제일 좋아”: 아이즈원 데뷔 전 ◦ “난 여자 아이돌 중에 아이즈원이 제일 좋아": 아이즈원 데뷔 후 ◦ 이에 대한 처리도 필요할 듯 • Facebook(FAIR)에서 오픈 도메인 대화 태스크에 관한 논문을 활발히 발표하는 느낌 ◦ I Know The Feeling: Learning To Converse With Empathy (ICLR 2019) https://arxiv.org/pdf/1811.00207 ▪ 공감 능력을 학습하기 위한 데이터셋을 클라우드 소싱으로 구축 ◦ Wizard of Wikipedia: Knowledge-Powered Conversational Agents (ICLR 2019) https://arxiv.org/abs/1811.01241 ▪ 위키 정보를 활용하여 대화하는 능력을 학습하기 위해 위키피디아로 지식 데이터셋을 구축하고, End-to-end로 학습가능한 모델 아키텍쳐를 제안 ◦ 둘 다 오픈 데이터셋으로 웹에 공개되어 있음.
![Toward Personalized Dialogue Agent 2019.05.22 Machine Learning Engineer 정다운 [email protected]](https://files.speakerdeck.com/presentations/8d1ac46dcbc14c02a28a6e1c98b1dd30/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}