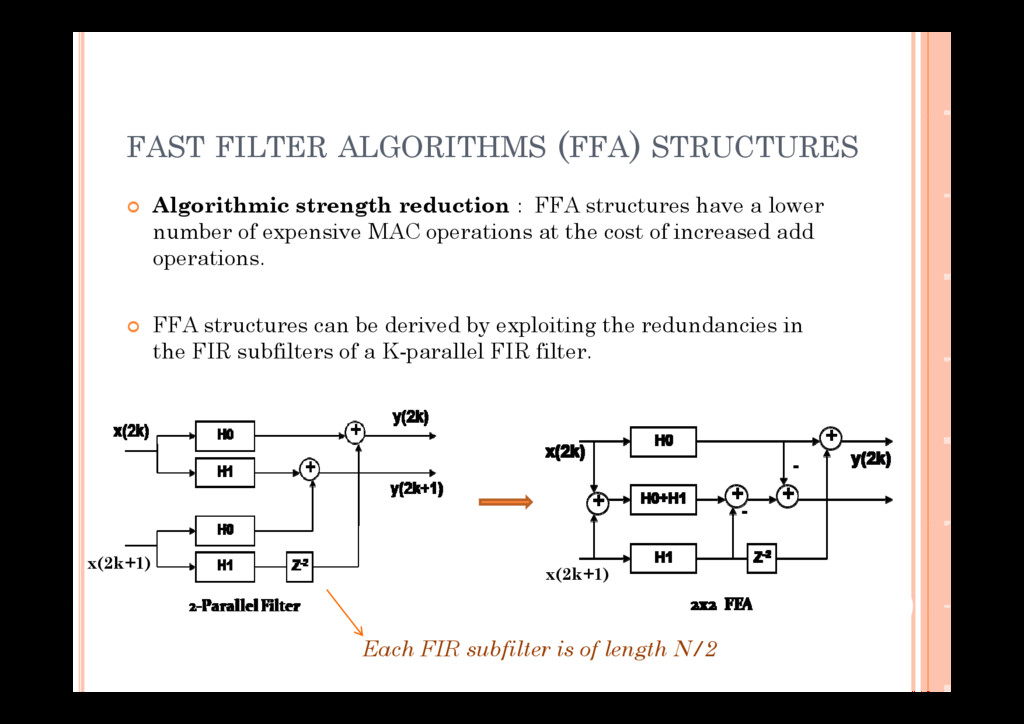
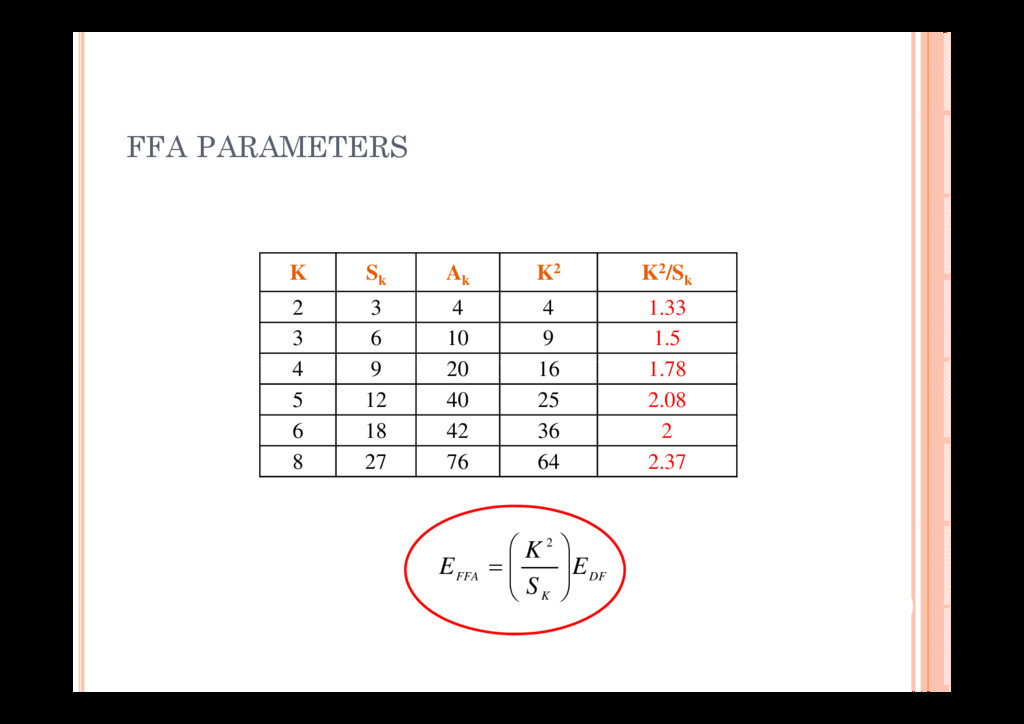
Moy and Jacques Palicot, “Flexibility and reusability in the digital front-end of cognitive radio terminals,” Circuits, Systems and Signal Processing Journal, Springer Accepted in August 2010 Springer, Accepted in August 2010. [2] Navin Michael, Christophe Moy, A. P. Vinod and Jacques Palicot, “Area-Power tradeoffs for flexible filtering in green radios,” Journal of Communications and Networks, vol.12, no.2, pp. 158-167, April 2010. International Conferences [1] Christophe Moy, Wassim Jouini, Navin Michael, “Cognitive Radio Equipments Supporting Spectrum Agility,” International Workshop on Cognitive Radio and Advanced Spectrum M t (C ART 2010) It l 7 10 N b 2010 Management (CogART 2010), Italy, 7-10 November 2010. [2] Navin Michael, A. P. Vinod, Christophe Moy and Jacques Palicot, “Low power, flexible FIR filters in the digital front-end of green radios,” Proceedings of IEEE International Symposium on Personal, Indoor and Mobile Radio Communications, Istanbul, Turkey, September 2010. [3] Navin Michael, A. P. Vinod, Christophe Moy and Jacques Palicot, “Area-efficient time-shared FIR fil i l C OS ” di f i l C f G Ci i d filters in nanoscale CMOS,” Proceedings of IEEE International Conference on Green Circuits and Systems, Shanghai, China, June 2010. [4] Navin Michael, A. P. Vinod, Christophe Moy and Jacques Palicot, “Design paradigm for standard agnostic channelization in flexible mobile radios,” Proceedings of IEEE International Symposium on Circuits and Systems, Paris, France, May-June 2010. [5] Navin Michael, A. P. Vinod, Christophe Moy and Jacques Palicot, “Design of low power multimode time-shared filters,” Proceedings of 7th IEEE International Conference on Information, Communications and Signal Processing, pp. 1-5, Macau, December 2009. [6] Navin Michael and A. P. Vinod, “Reconfigurable architecture for arbitrary sample rate conversion in software defined radios,” Proceedings of 19th IEEE International Symposium on Personal, I d d M bil R di C i ti 1 6 C F S t b 2008 Indoor and Mobile Radio Communications, pp. 1-6, Cannes, France, September 2008.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![PUBLICATIONS International Journals [1] Navin Michael, A. P. Vinod, Christophe](https://files.speakerdeck.com/presentations/d618f7754c7e4e74982a719d7e227511/slide_55.jpg){kind=link}
{kind=link}