Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
文献紹介20181211_On Learning Better Word Embeddings...
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
T.Tada
December 11, 2018
Technology
110
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
文献紹介20181211_On Learning Better Word Embeddings from Chinese Clinical Records: Study on Combining In-Domain and Out-Domain Data
T.Tada
December 11, 2018
More Decks by T.Tada
See All by T.Tada
文献紹介_202002_Is artificial data useful for biomedical Natural Language Processing algorithms?
tad
0
76
文献紹介_202001_A Novel System for Extractive Clinical Note Summarization using EHR Data
tad
0
190
文献紹介_201912_Publicly Available Clinical BERT Embeddings
tad
0
180
文献紹介_201911_EDA: Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks
tad
0
230
文献紹介_201910_Do Neural NLP Models Know Numbers? Probing Numeracy in Embeddings
tad
0
110
文献紹介_201909_Sentence Mover’s Similarity_ Automatic Evaluation for Multi-Sentence Texts
tad
0
170
文献紹介_201908_Medical Word Embeddings for Spanish_ Development and Evaluation
tad
0
73
文献紹介_201907_Is Word Segmentation Necessary for Deep Learning of Chinese Representations
tad
0
120
文献紹介_201906_Predicting Annotation Difficulty to Improve Task Routing and Model Performance for Biomedical Information Extraction
tad
0
110
Other Decks in Technology
See All in Technology
Mastraエージェント、どのクラウドにデプロイする?
minorun365
PRO
2
180
知見・人・API・DB・予算 ─ ナイナイ尽くしだった人事データ整備 with dbt、5年間の学び
ken6377
1
170
ポストモーテム! DDoSからサイトは守れた。 でもビジネスは守れなかった。
bengo4com
0
2.1k
AIで政治は変わるのか? — 中高生と考えたAI時代の民主主義(東海高校サタデープログラム)
eitarosuda
0
410
“ID沼入口” - 基本とセキュリティから始める、考え続けるためのID管理技術勉強会 告知&イントロ
ritou
0
450
最近評価が難しくなった
maroon8021
0
260
AI駆動開発におけるQAエンジニアの役割事例 〜AI駆動開発の現場から〜
kobayashiyorimitsu
0
420
Docker Desktop不要の時代が来る? WSL標準の「wslc」で Linuxコンテナを動かしてみた.
ueponx
0
830
型は壁、Rustでもバグを直すな、表現できなくせよ
nwiizo
12
1.9k
ZOZOTOWNの進化と信頼性を両立する負荷試験
zozotech
PRO
0
150
知らん間に、回ってる
ming_ayami
0
360
環境凍結という Toil を倒す -セルフサービス型 Ephemeral テスト環境の 設計と実践
shirouz
1
1.8k
Featured
See All Featured
4 Signs Your Business is Dying
shpigford
187
22k
GitHub's CSS Performance
jonrohan
1033
470k
エンジニアに許された特別な時間の終わり
watany
107
250k
Self-Hosted WebAssembly Runtime for Runtime-Neutral Checkpoint/Restore in Edge–Cloud Continuum
chikuwait
0
640
Visual Storytelling: How to be a Superhuman Communicator
reverentgeek
2
590
30 Presentation Tips
portentint
PRO
1
340
Impact Scores and Hybrid Strategies: The future of link building
tamaranovitovic
0
330
How To Speak Unicorn (iThemes Webinar)
marktimemedia
1
500
Lightning Talk: Beautiful Slides for Beginners
inesmontani
PRO
2
600
Organizational Design Perspectives: An Ontology of Organizational Design Elements
kimpetersen
PRO
1
760
Mobile First: as difficult as doing things right
swwweet
225
10k
A designer walks into a library…
pauljervisheath
211
24k
Transcript
- 文献紹介 2018/12/11 - On Learning Better Word Embeddings from
Chinese Clinical Records: Study on Combining In-Domain and Out-Domain Data 長岡技術科学大学 自然言語処理研究室 多田太郎
About the thesis 2
Introduction ・単語エンベディングはバイオメディカル分野において多くの有望な結果を得ている. ・中国の臨床記録を用いた分野においては大きく遅れがある. ・中国の臨床記録から埋め込みを学習することに焦点を当てる. 3
Introduction 貢献: ・より良い学習をするためのドメイン内およびドメイン外のデータ結合方法の提案 ・追加の標準的な医学用語データセットを用いて単語エンベディングを評価する方法を提案 ・良い訓練サンプルの選択,適切な量の外部ドメインデータを収集することで質の向上を確 認 Skip-gramを用いて学習していく 4
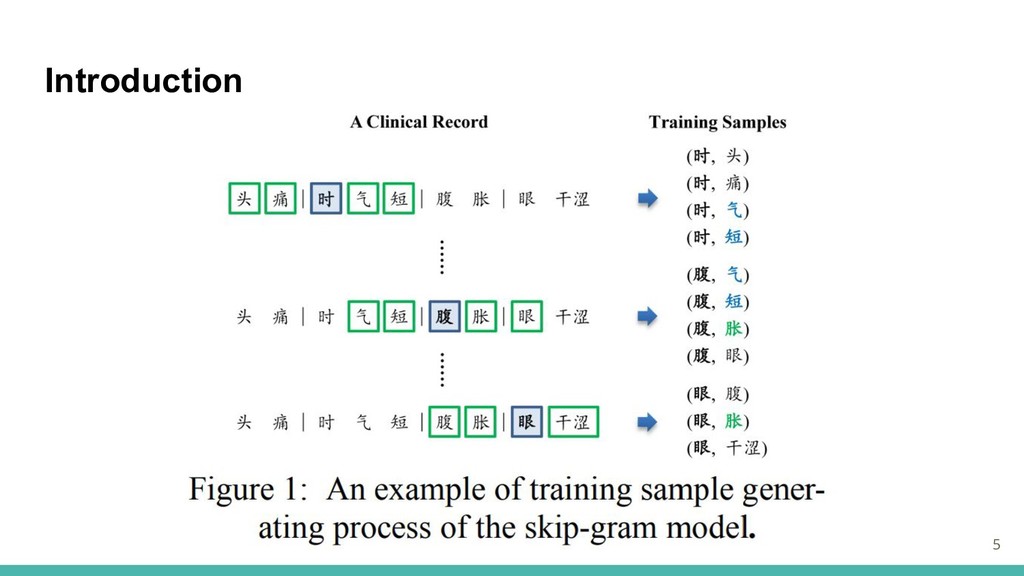
Introduction 5
Skip-Gram Model for Learning Embeddings from Chinese Clinical Records -
Observation - ・中国の臨床記録の内容は通常簡潔であり,症状と病気は一定の相関関係を持つ. ・一般的なドメインの単語に,医学語と類似または同一の文脈語がある →単語埋め込みを作成することの障害に ・主な課題は,医学的単語と一般的なドメインの単語とをより明確に区別すること. 6
Skip-Gram Model for Learning Embeddings from Chinese Clinical Records -
Usage of Out-Domain Data - ・2つのターゲットワード間の明確な区別は,差異を示すコンテキストワードを要とする. ・ドメイン内データ(中国の臨床記録)に,ドメイン外データ(一般ドメイン中国語テキスト)を 追加することにより,中国の臨床記録からの単語エンベディングの学習を容易にすると仮 定. ・組み合わせることで,一般的なドメイン単語の文脈語の多様性を向上 →医学用語の文脈を損なう副作用はなく,より優れた埋め込みを学ぶことができる. 7
Skip-Gram Model for Learning Embeddings from Chinese Clinical Records -Learning
Process and Embedding Quality Evaluation Method - 前処理 Stanford CoreNLP tool1の最新バージョン 単語分割,句読点削除 学習 DeepLearning4J2のスキップグラムモデル 階層的SoftMax,window size 5,次元数 200 ・ドメイン外データには医学用語がないと仮定 ・中国医学概念類似性尺度(CMCSM)を用いて評価 8
Learning Process and Embedding Quality Evaluation Method 9
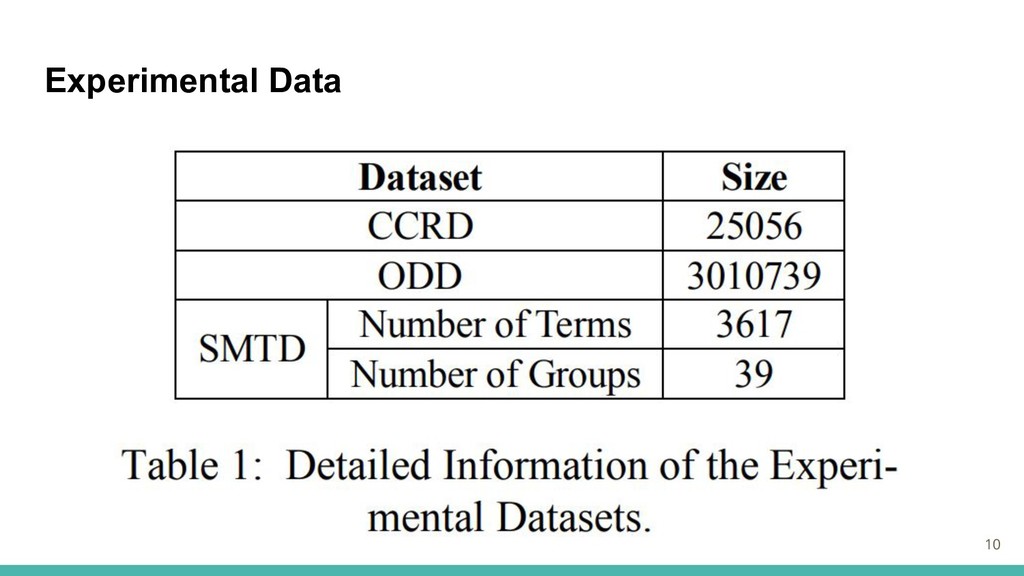
Experimental Data 10
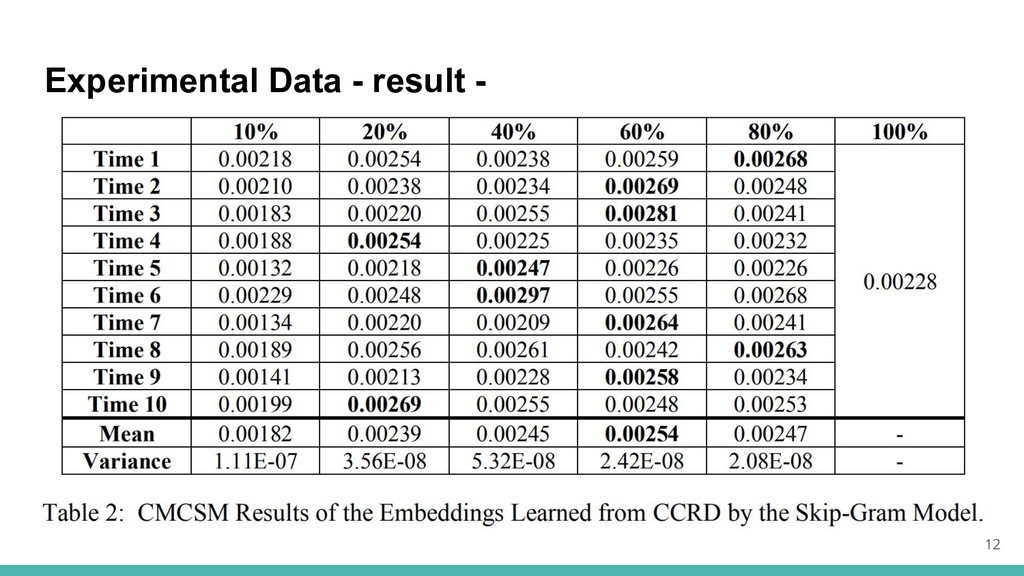
Experimental Data ・スキップグラムモデルを適用してCCRDを学習し,CMCSMで評価. ・異なるサイズのデータセットの効果を評価. CCRDから5つのサブデータセットをサンプリング(80%,60%,40%,20%,10%) ・ドメイン内のデータのみを使用する場合,以下の必要がある. 可能な限り多くのトレーニングデータを収集 有益なサンプルを選択する 11
Experimental Data - result - 12
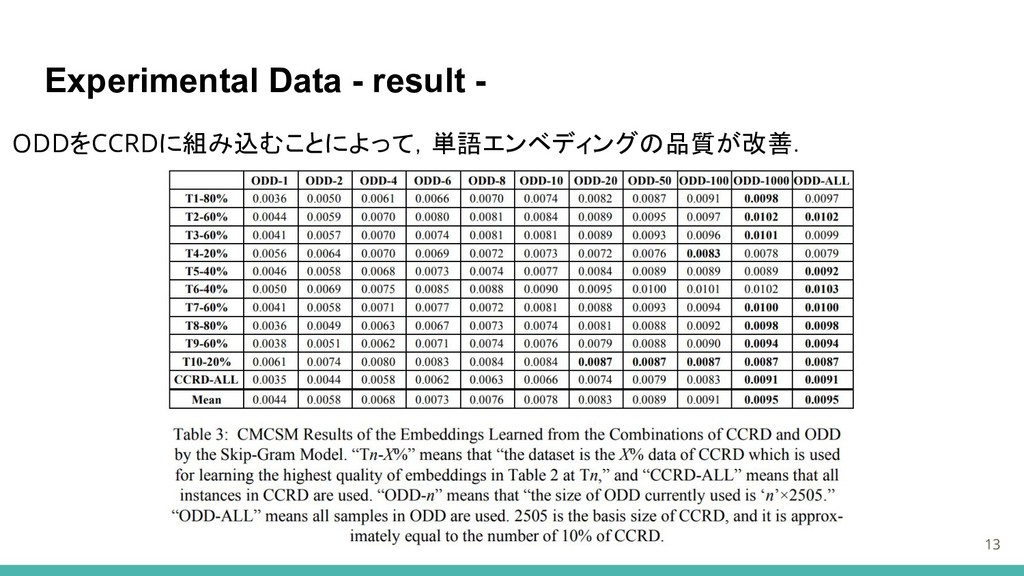
Experimental Data - result - 13 ODDをCCRDに組み込むことによって,単語エンベディングの品質が改善.
Discussion / Conclusions ・良好な単語ベクトルを学習する方法に関する既存の研究の大部分は,同じ領域内のデータ に基づいている(Chiu et al. 2016, Lai et
al. 2016) →さらなる探求は多くの面で継続される必要がある. ・ドメイン外データを用いて,中国の臨床記録からのより良い単語ベクトルを学習方法を提示. ・ 適切な量のドメイン外データを収集し,良好なトレーニングサンプルを選択することで単語ベ クトルの質の向上を確認. 14
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}