Deep Learning and Conventional Cla ssification Methods Sarvnaz Karimi, Xiang Dai, Hamed Hassanzadeh, and Anthony Nguyen Data61, CSIRO, Sydney, Australia School of Information Technologies, University of Sydney, Sydney, Australia The Australian e-Health Research Centre, CSIRO, Brisbane, Australia Proceedings of the BioNLP 2017 workshop, pages 328–332, Vancouver, Canada, August 4, 2017. c 2017 Association for Computational Linguistics 長岡技術科学大学 自然言語処理研究室 多田太郎 1
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
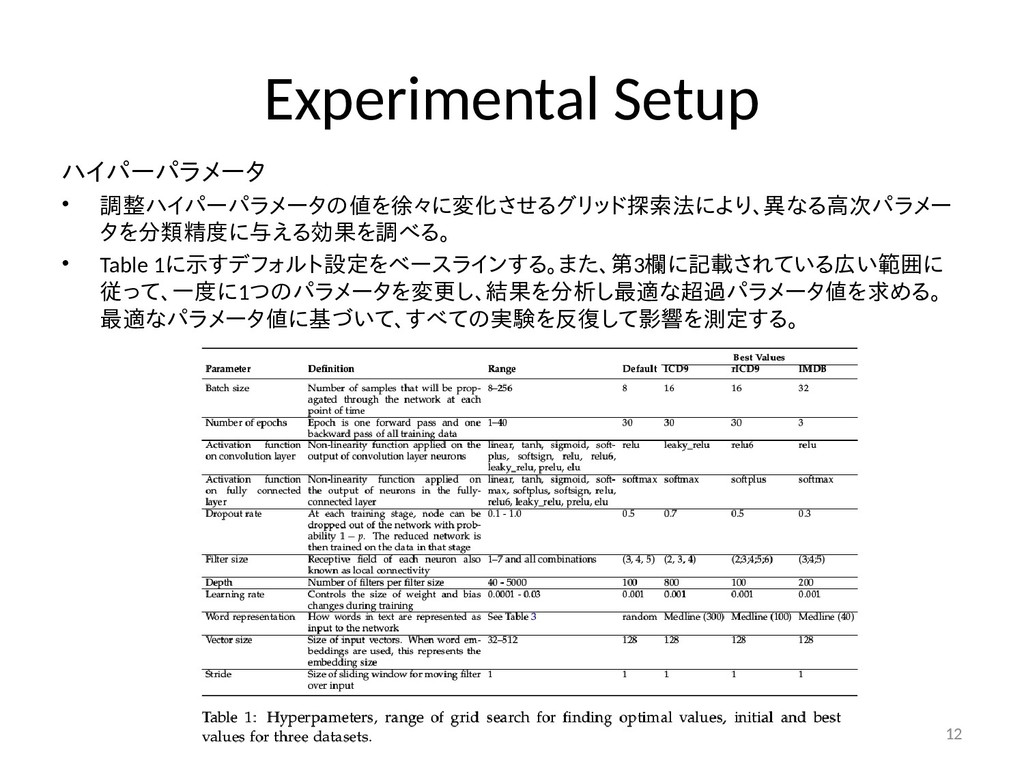{kind=link}
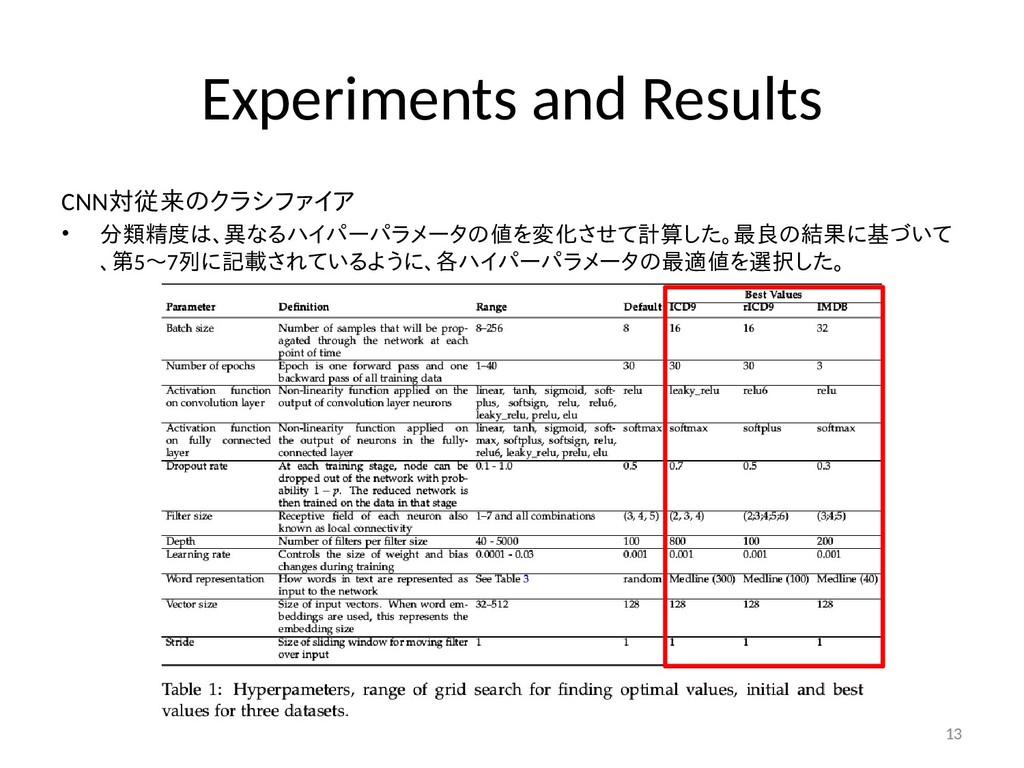{kind=link}
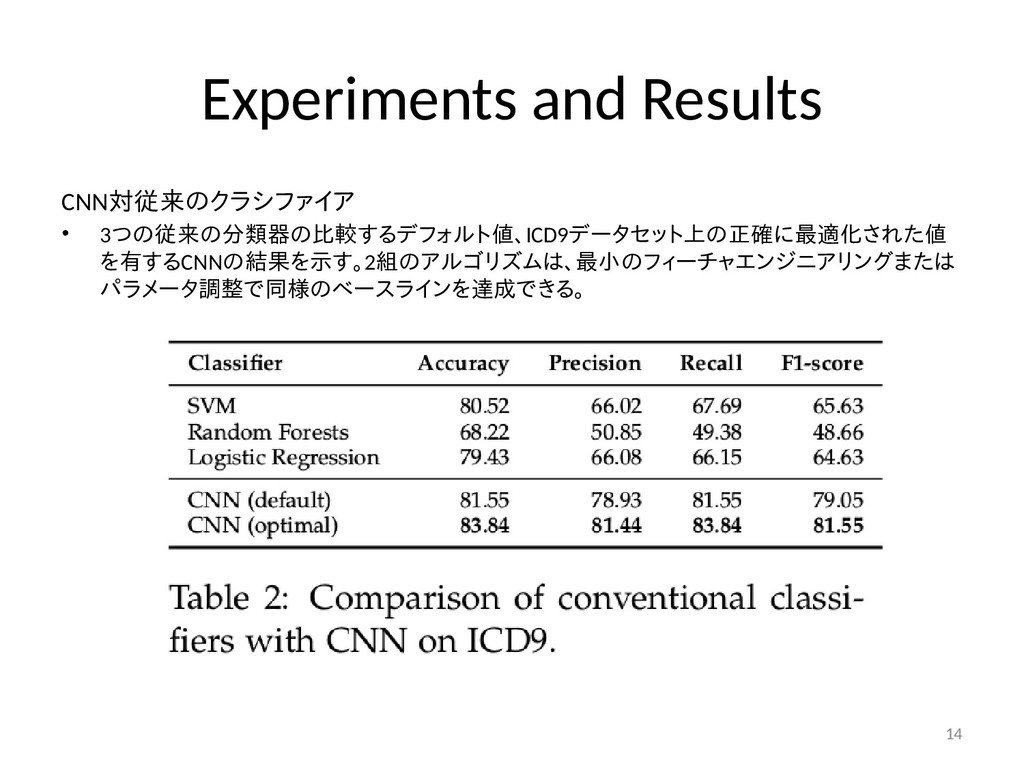{kind=link}
{kind=link}
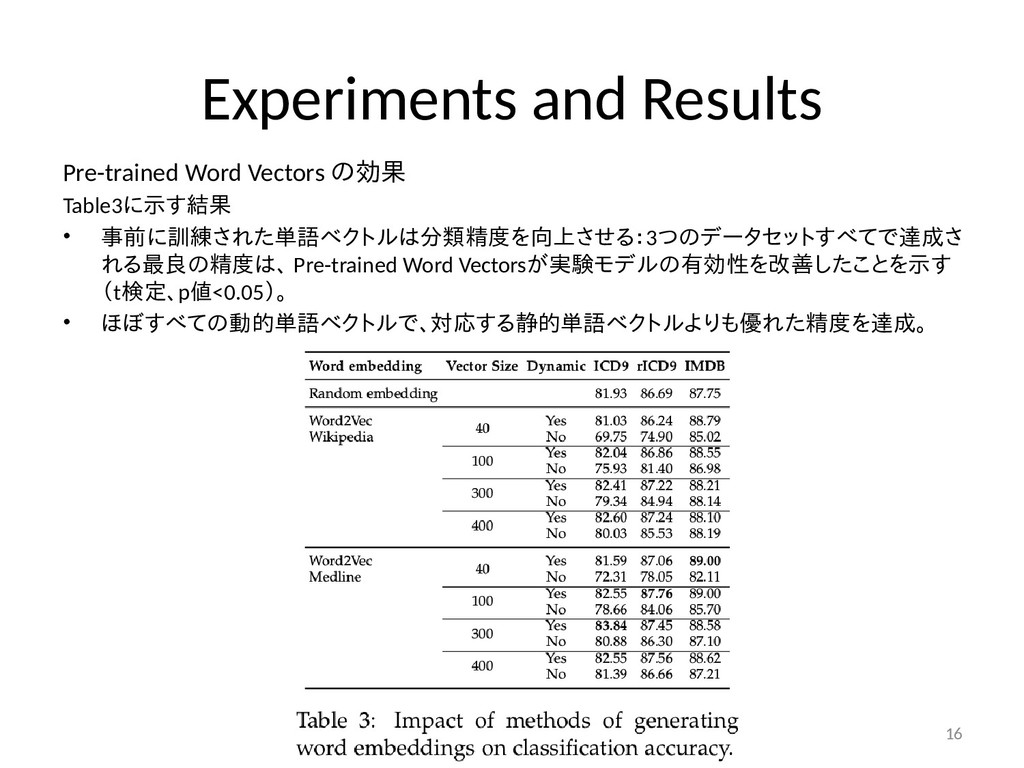{kind=link}
{kind=link}
{kind=link}
{kind=link}