Speaker: Vincent Chabot, Meteo France
"Comment gérer ses expériences de machine learning avec Sacred ou comment rendre ses expériences (quasi) reproductible sans effort."
Dans cette présentation les principes de sacred, une librairie python, seront présentés.
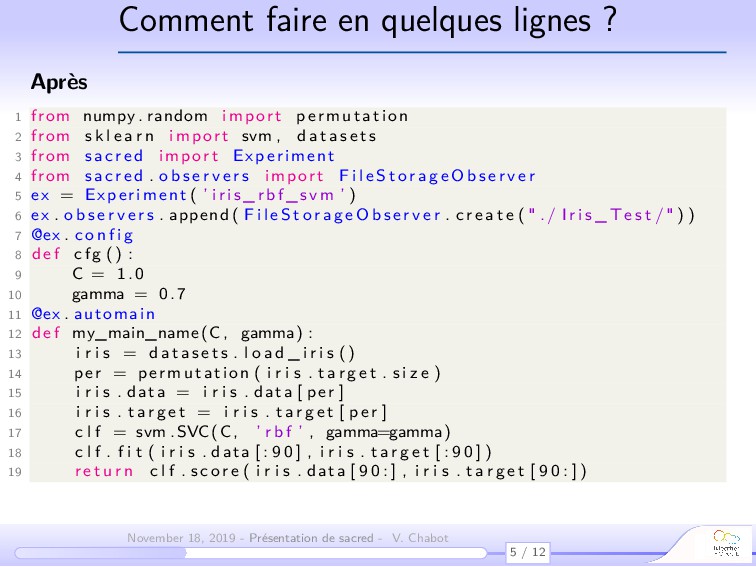
Sacred permet via l’utilisation de décorateur (et de la “magie” liée à sacred) de :
- conserver une trace de l’ensemble des paramètres d’une expérience,
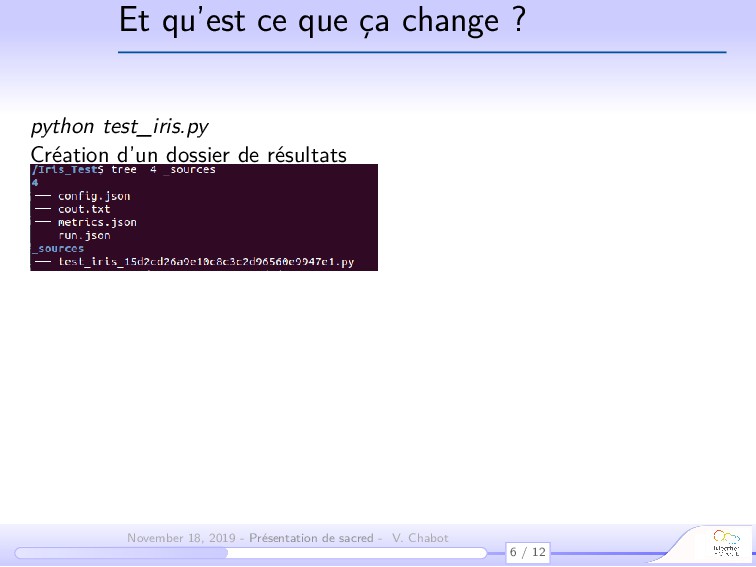
- sauver les configurations utilisées et les résultats dans des bases de données,
- gérer et combiner différentes configurations pour former de nouvelles expériences.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
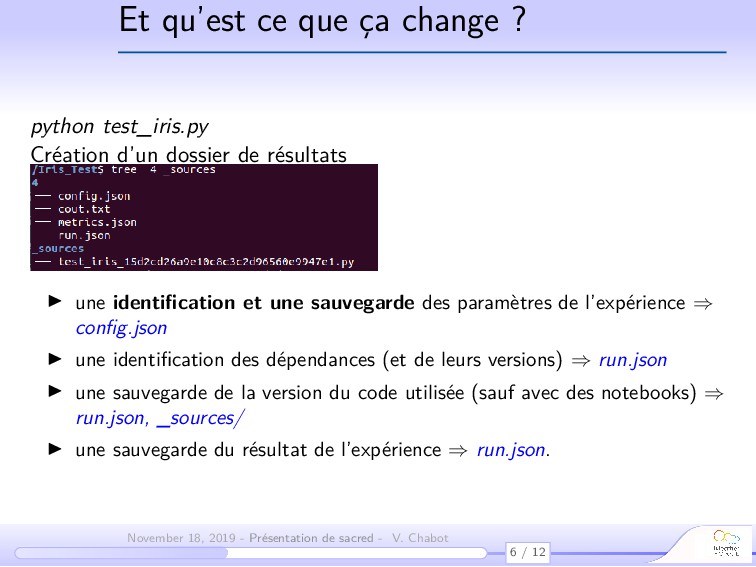{kind=link}
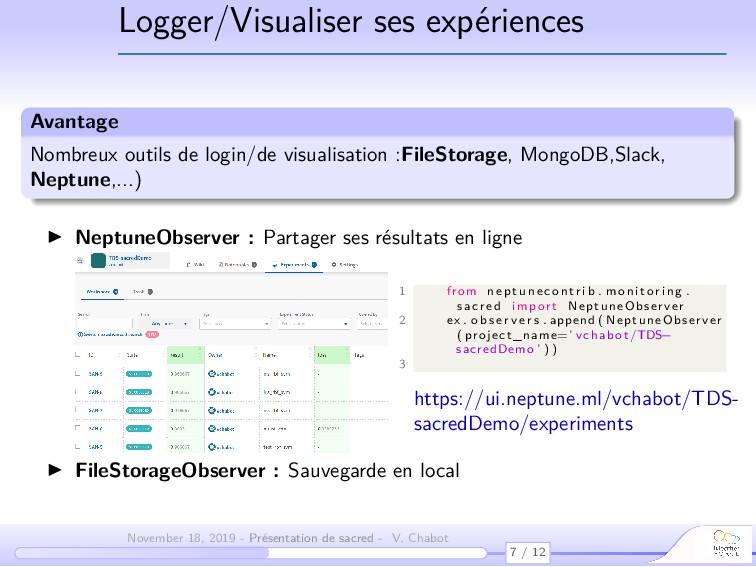{kind=link}
{kind=link}
{kind=link}
{kind=link}
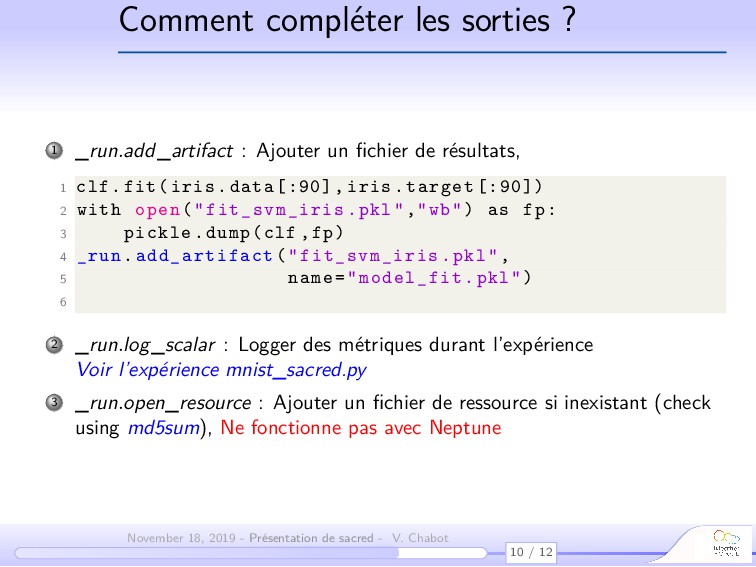{kind=link}
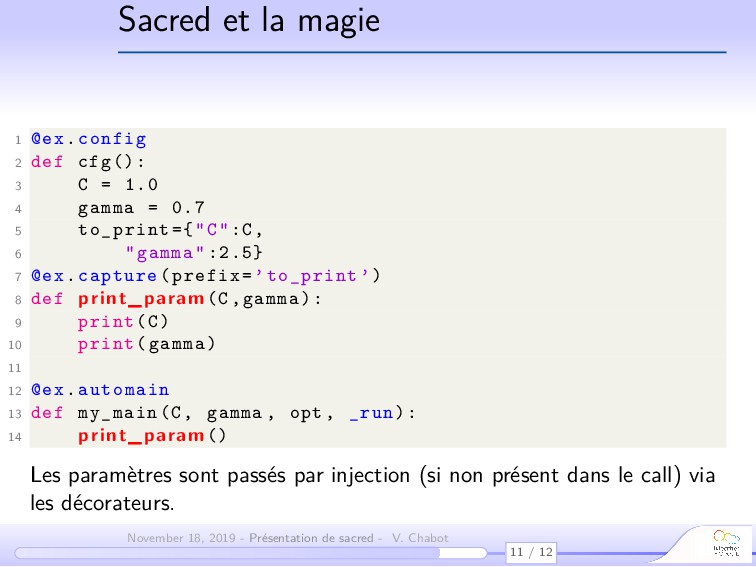{kind=link}
{kind=link}