Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Chainerによる深層学習(3)
Search
youichiro
March 08, 2017
Technology
160
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Chainerによる深層学習(3)
長岡技術科学大学
自然言語処理研究室
B3ゼミ発表(第7回)
youichiro
March 08, 2017
More Decks by youichiro
See All by youichiro
日本語文法誤り訂正における誤り傾向を考慮した擬似誤り生成
youichiro
0
1.6k
分類モデルを用いた日本語学習者の格助詞誤り訂正
youichiro
0
140
Multi-Agent Dual Learning
youichiro
1
200
Automated Essay Scoring with Discourse-Aware Neural Models
youichiro
0
150
Context is Key- Grammatical Error Detection with Contextual Word Representations
youichiro
1
170
勉強勉強会
youichiro
0
100
Confusionset-guided Pointer Networks for Chinese Spelling Check
youichiro
0
220
A Neural Grammatical Error Correction System Built On Better Pre-training and Sequential Transfer Learning
youichiro
0
200
An Empirical Study of Incorporating Pseudo Data into Grammatical Error Correction
youichiro
0
230
Other Decks in Technology
See All in Technology
ソニー銀行におけるビジネスアジリティ向上のためのクラウドシフト戦略
srenext
0
340
kintone の AI コワーカーを、 Anthropic にエージェントを"ホストさせて"作った話 #devkinmeetup
sugimomoto
0
110
はじめてのWDM
miyukichi_ospf
1
150
公式ドキュメントの歩き方etc
coco_se
0
110
【Claude Code】鹿野さんに聞く 私の推しの並行開発環境 大公開 / claude-code-parallel-2026-07-15
tonkotsuboy_com
12
8.2k
なぜ私たちのSREプラクティスはなかなか機能しないのか 〜システムより先に組織を見る〜 / Why our SRE practices aren't really working
vtryo
3
3.8k
Claude Codeとハーネスについて考えてみる
oikon48
19
9.5k
非定型なドキュメントを効率よくリファクタする 〜えぇ!?仕様書27本の移行が1日で終わったって!?〜
subroh0508
2
470
DMM.com 購入改善推進チーム におけるCodeRabbitを用いた レビューフロー改善の一例
ysknsid25
2
640
2年前に削除したPHPクラスが、 ある日突然決済をエラーにした
ykagano
1
140
SRE Next 2026 何でも屋からの脱却
bto
0
800
SRE本の知られざる名シーン / The Hidden Gems of Google SRE Book
nari_ex
1
410
Featured
See All Featured
Git: the NoSQL Database
bkeepers
PRO
432
67k
Darren the Foodie - Storyboard
khoart
PRO
3
3.4k
Producing Creativity
orderedlist
PRO
348
40k
Balancing Empowerment & Direction
lara
6
1.2k
Embracing the Ebb and Flow
colly
88
5.1k
Making Projects Easy
brettharned
120
6.7k
Become a Pro
speakerdeck
PRO
31
6k
Agile Leadership in an Agile Organization
kimpetersen
PRO
0
190
Jess Joyce - The Pitfalls of Following Frameworks
techseoconnect
PRO
1
190
Bridging the Design Gap: How Collaborative Modelling removes blockers to flow between stakeholders and teams @FastFlow conf
baasie
0
610
30 Presentation Tips
portentint
PRO
1
350
Context Engineering - Making Every Token Count
addyosmani
9
1k
Transcript
Chainerによる深層学習 (3) 平成29年3月9日 長岡技術科学大学 自然言語処理研究室 小川耀一朗
Chainerによる分類問題 1/26
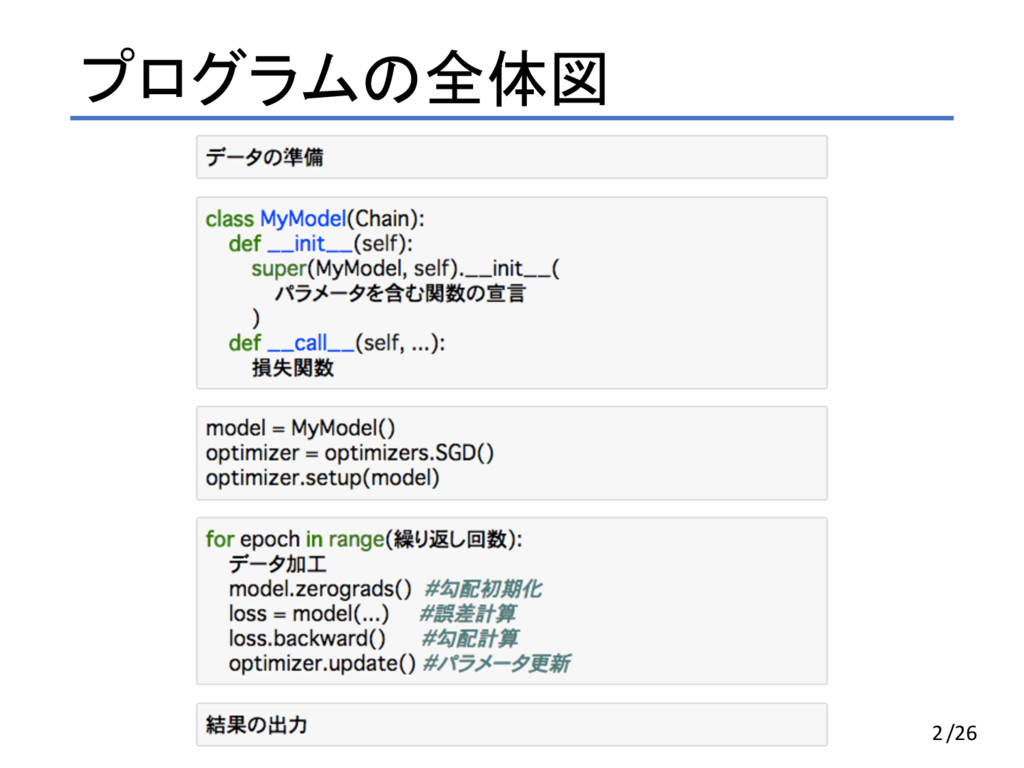
プログラムの全体図 2/26
Irisデータ • 150個のアヤメのデータ • データ: 花びらの長さ、幅、がく片の長さ、幅 • アヤメの種類: setosa(0)、versicolor(1)、virginica(2) 例)
[ 5.0999999 3.5 1.39999998 0.2 ] => 0 [ 7. 3.20000005 4.69999981 1.39999998] => 1 [ 6.30000019 3.29999995 6. 2.5 ] => 2 訓練データ → 奇数番目のデータ75個 テストデータ → 偶数番目のデータ75個 3/26
Irisデータの用意 4/26
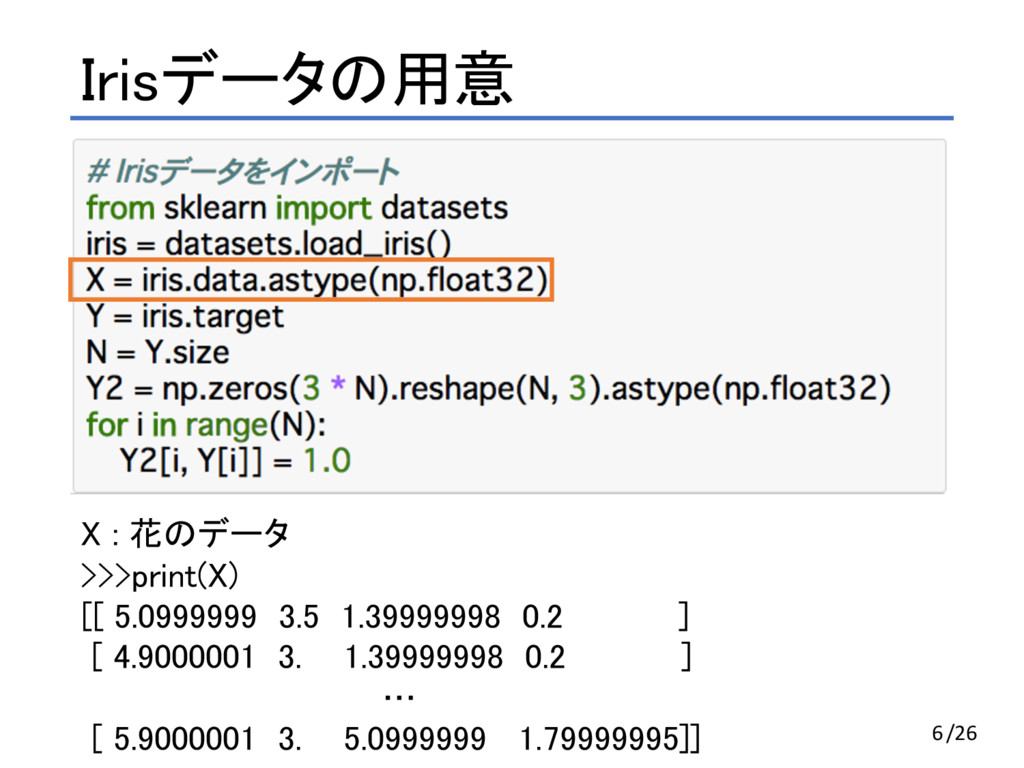
Irisデータの用意 Irisデータはscikit-learnに付属しているものを使う scikit-learn: 機械学習ライブラリ 分類や回帰、クラスタリングなどの機能が実装されている 5/26
Irisデータの用意 X : 花のデータ >>>print(X) [[ 5.0999999 3.5 1.39999998 0.2
] [ 4.9000001 3. 1.39999998 0.2 ] … [ 5.9000001 3. 5.0999999 1.79999995]] 6/26
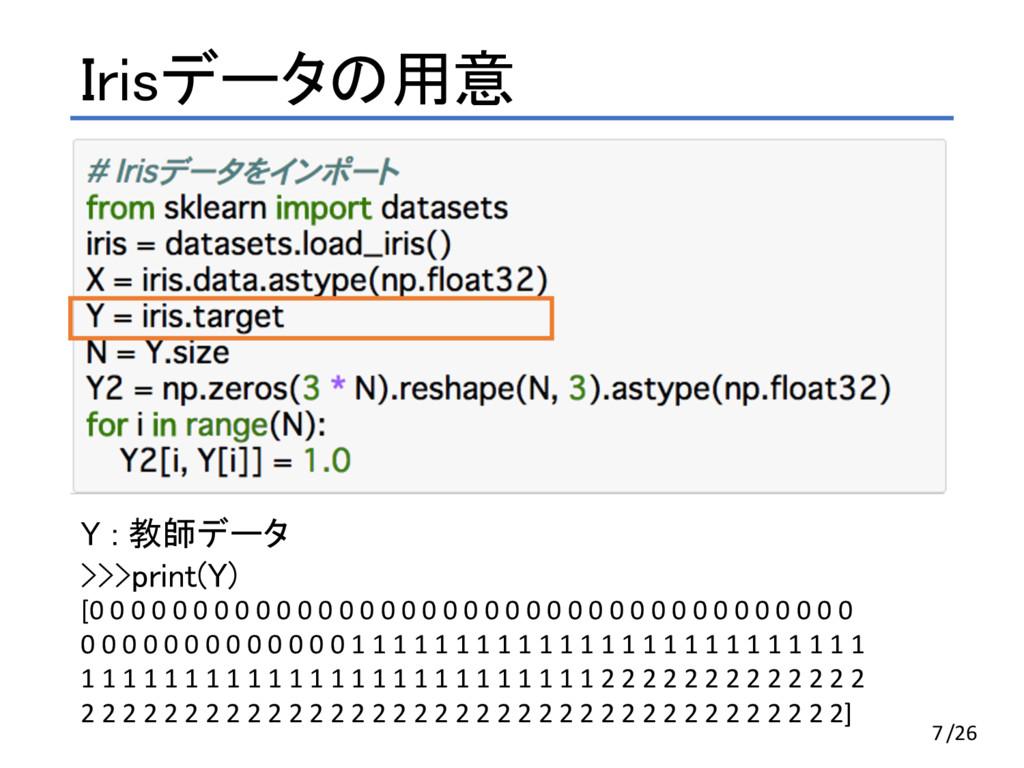
Irisデータの用意 Y : 教師データ >>>print(Y) [0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2] 7/26
Irisデータの用意 Y2 : 教師データ(変形) >>>print(Y2) [[ 1. 0. 0.] [
1. 0. 0.] … [ 0. 0. 1.]] 8/26
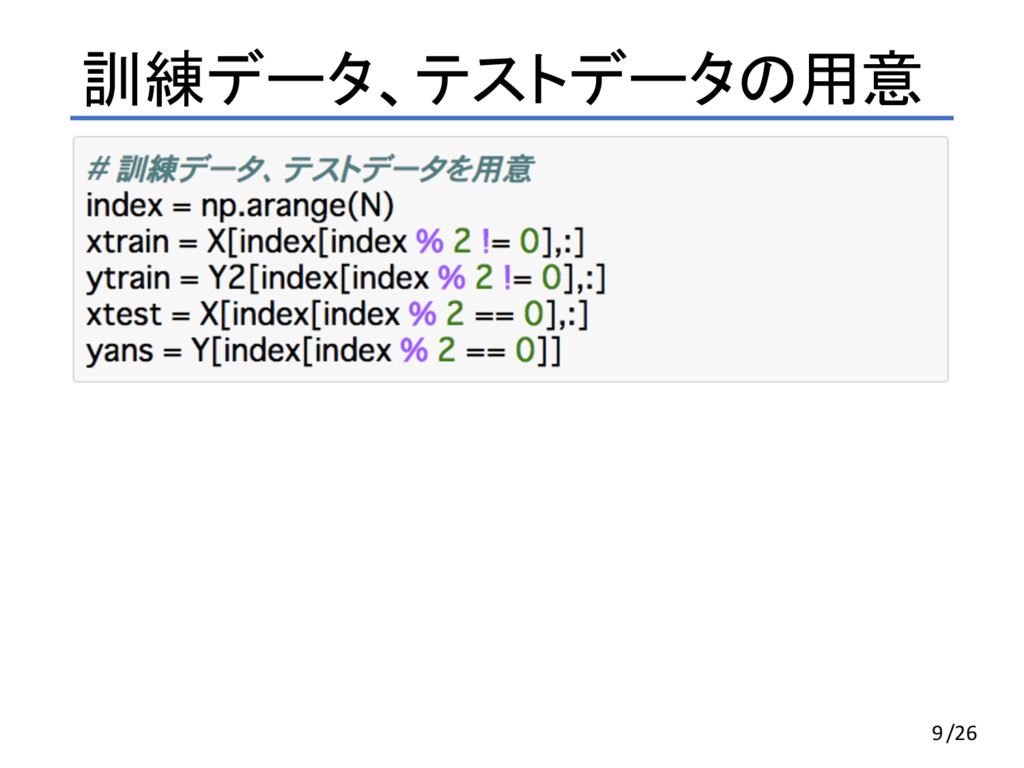
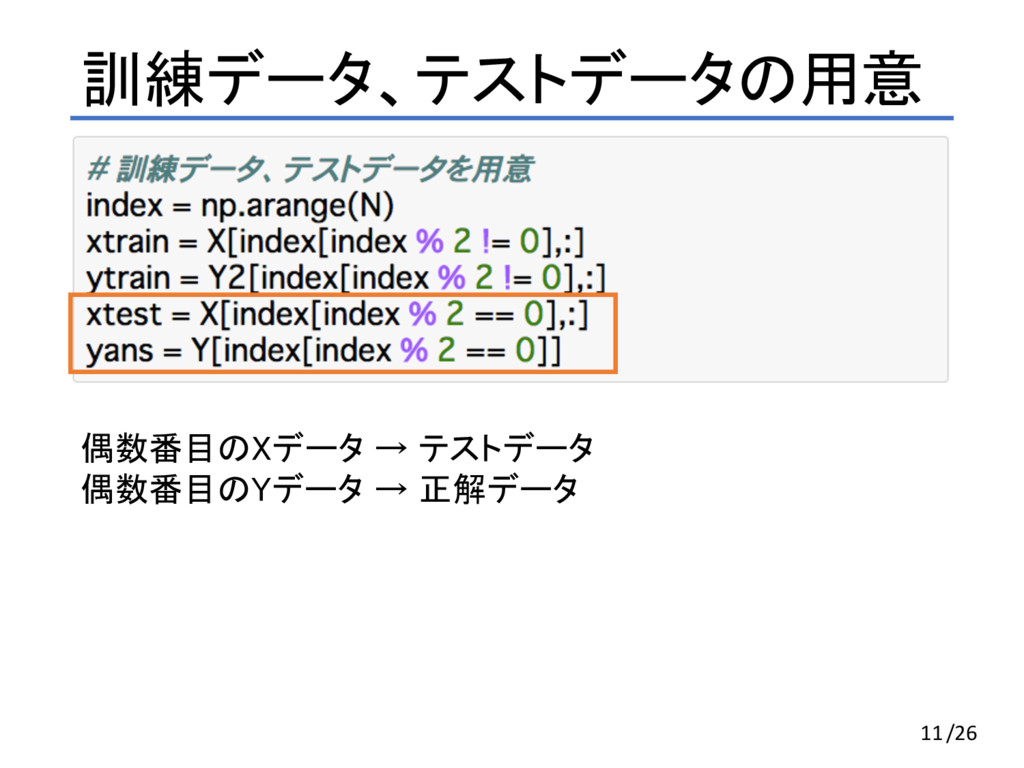
訓練データ、テストデータの用意 9/26
訓練データ、テストデータの用意 奇数番目のXデータ → 訓練データ 奇数番目のY2データ → 訓練用の教師データ 10/26
訓練データ、テストデータの用意 偶数番目のXデータ → テストデータ 偶数番目のYデータ → 正解データ 11/26
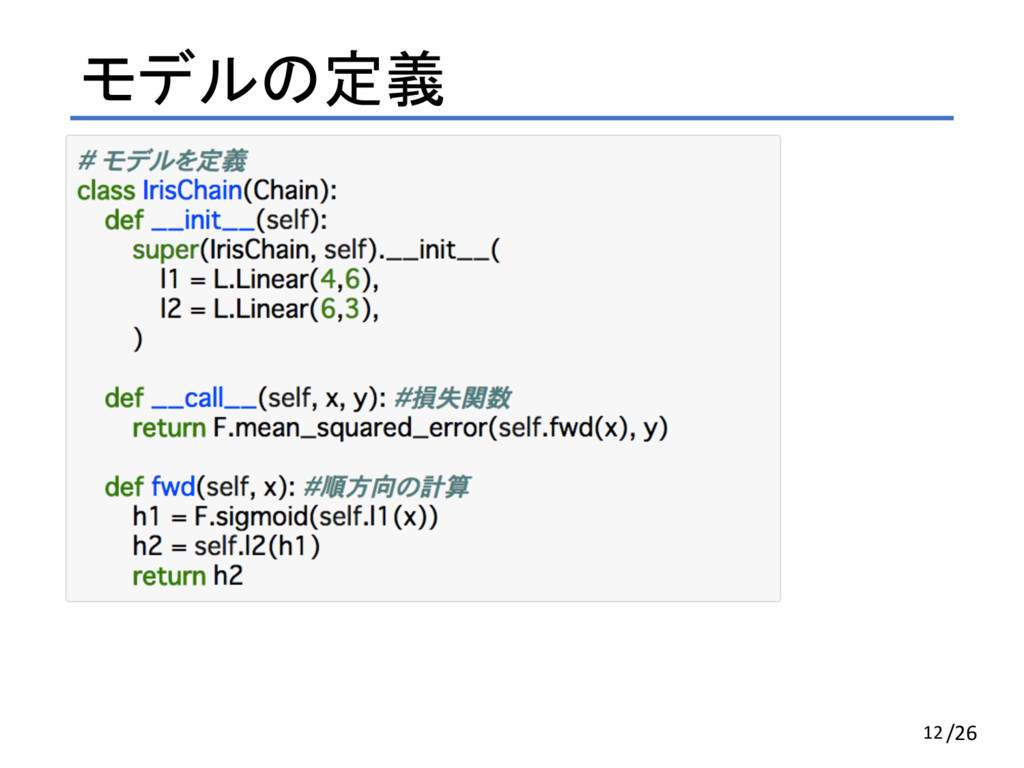
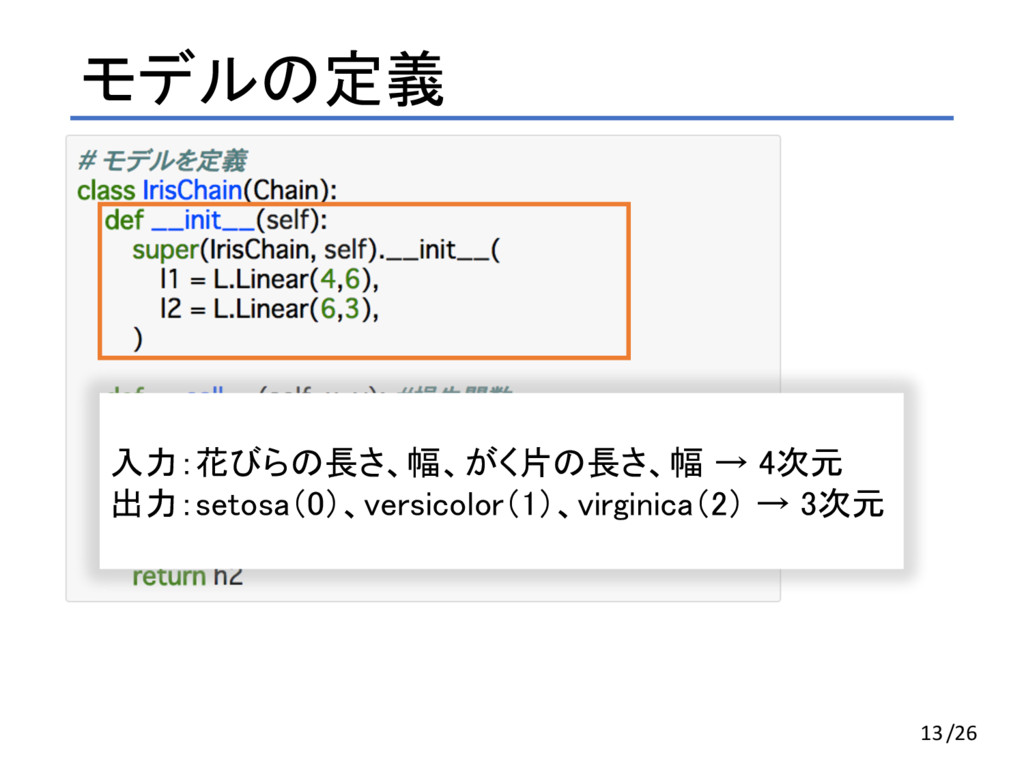
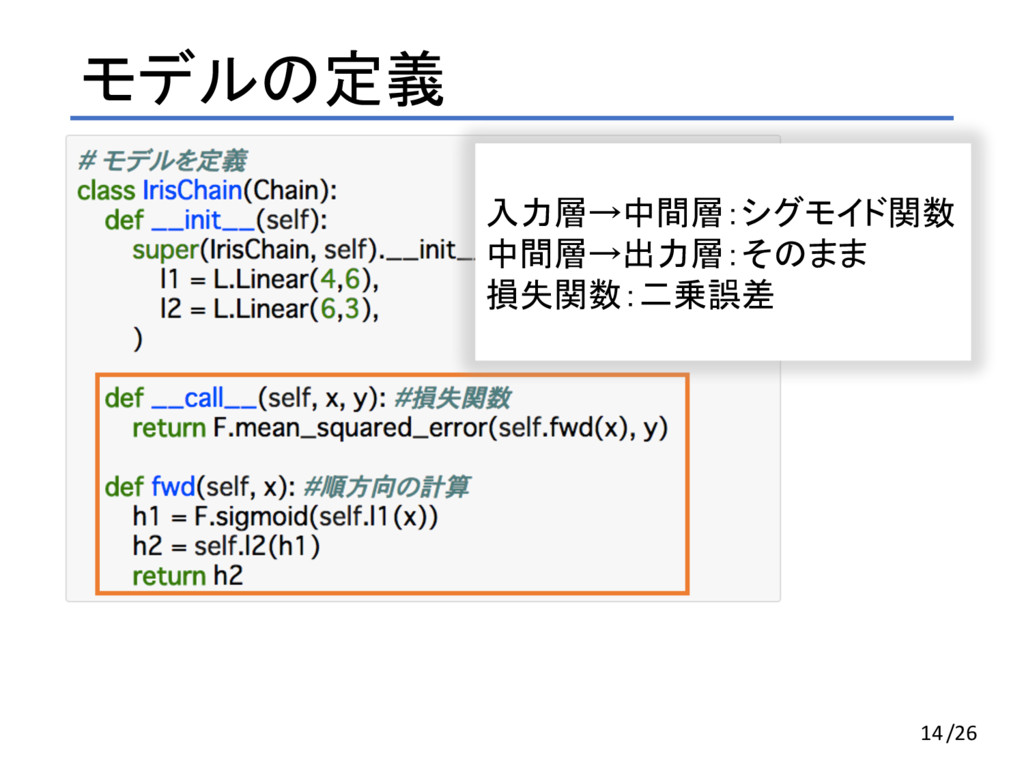
モデルの定義 12/26
モデルの定義 13 入力:花びらの長さ、幅、がく片の長さ、幅 → 4次元 出力:setosa(0)、versicolor(1)、virginica(2) → 3次元 /26
モデルの定義 14 入力層→中間層:シグモイド関数 中間層→出力層:そのまま 損失関数:二乗誤差 /26
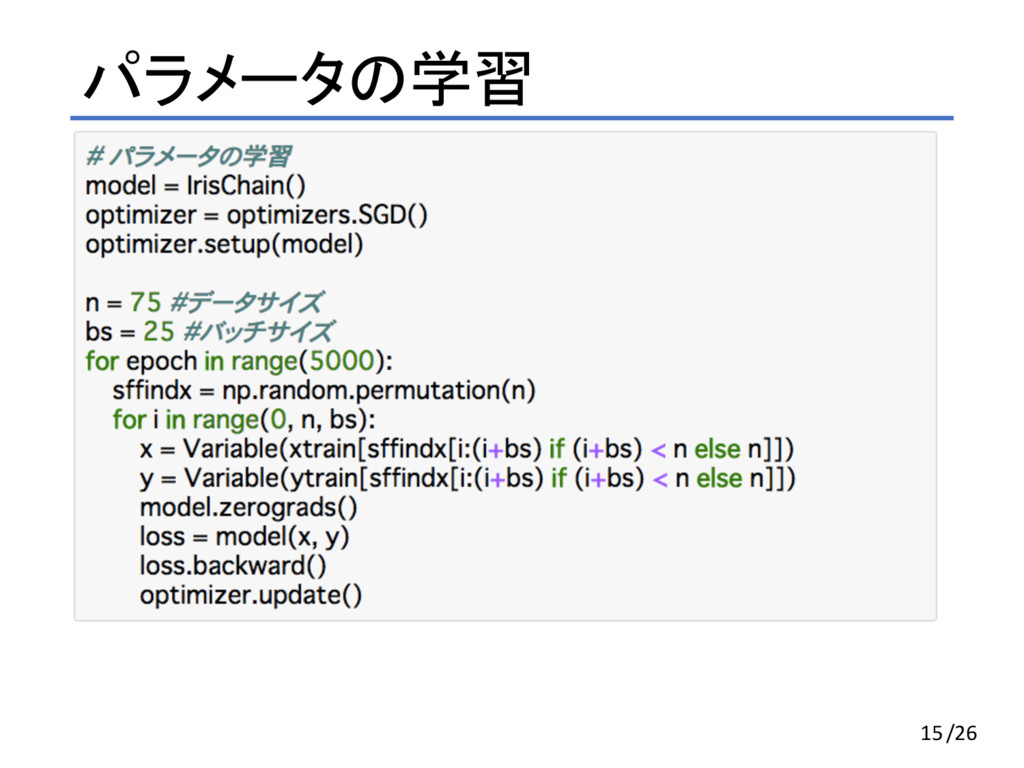
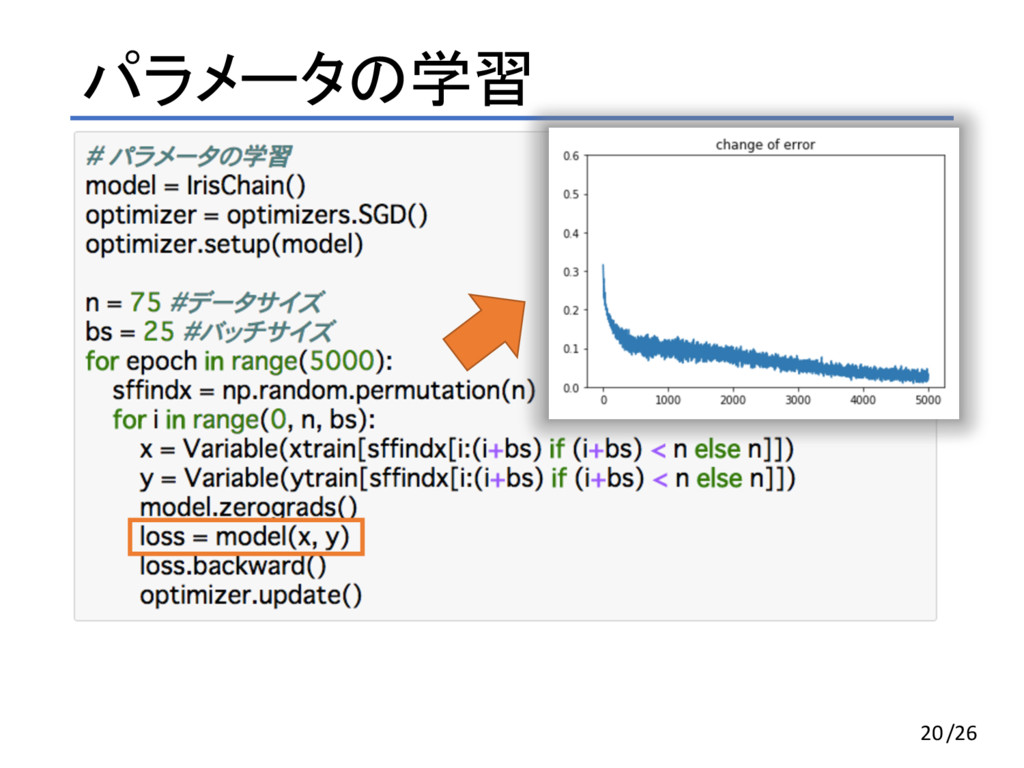
パラメータの学習 15/26
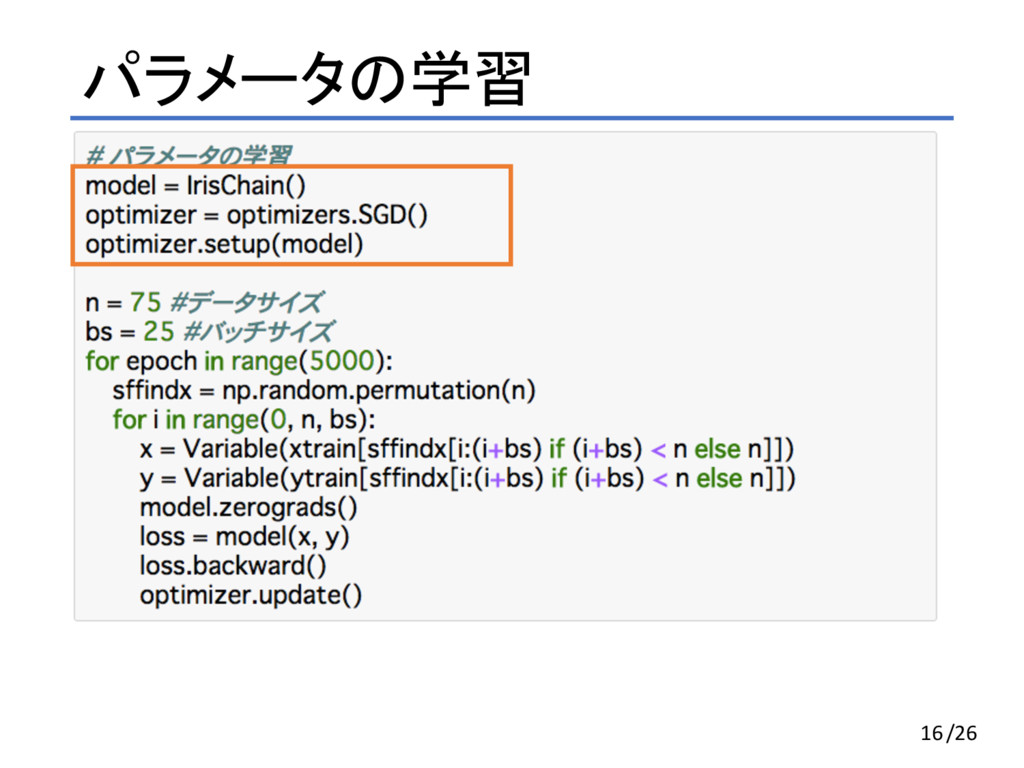
パラメータの学習 16/26
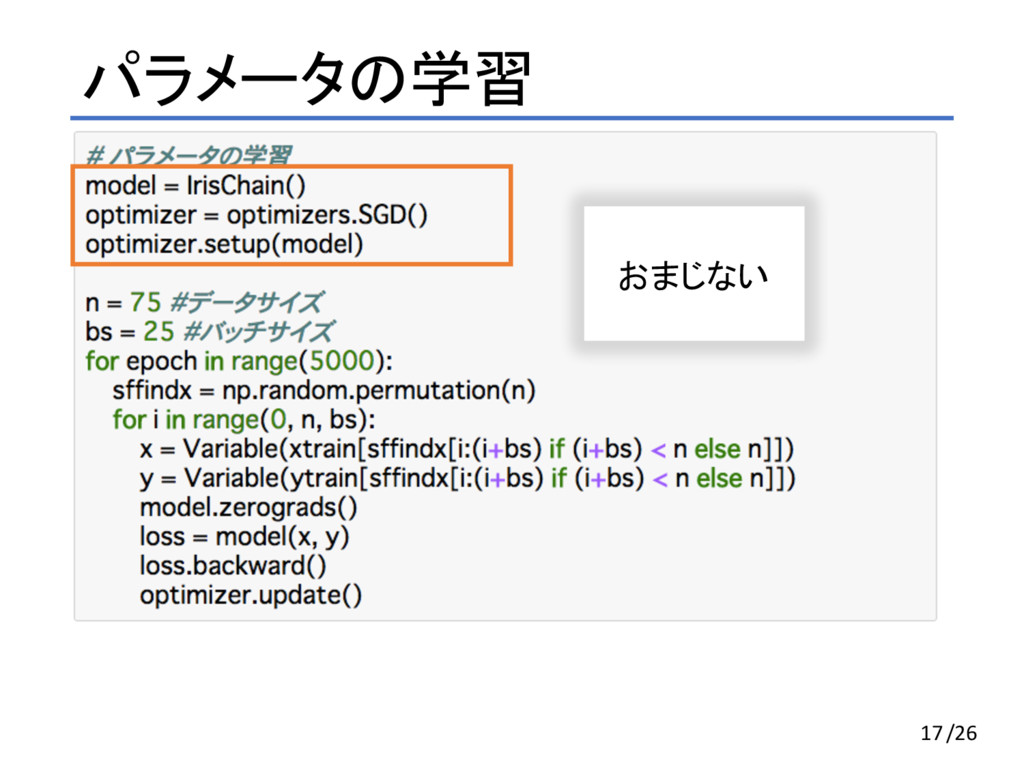
パラメータの学習 17 おまじない /26
パラメータの学習 18 ミニバッチ処理 1回のパラメータ更新にランダムに 取り出した25個の訓練データを使う /26
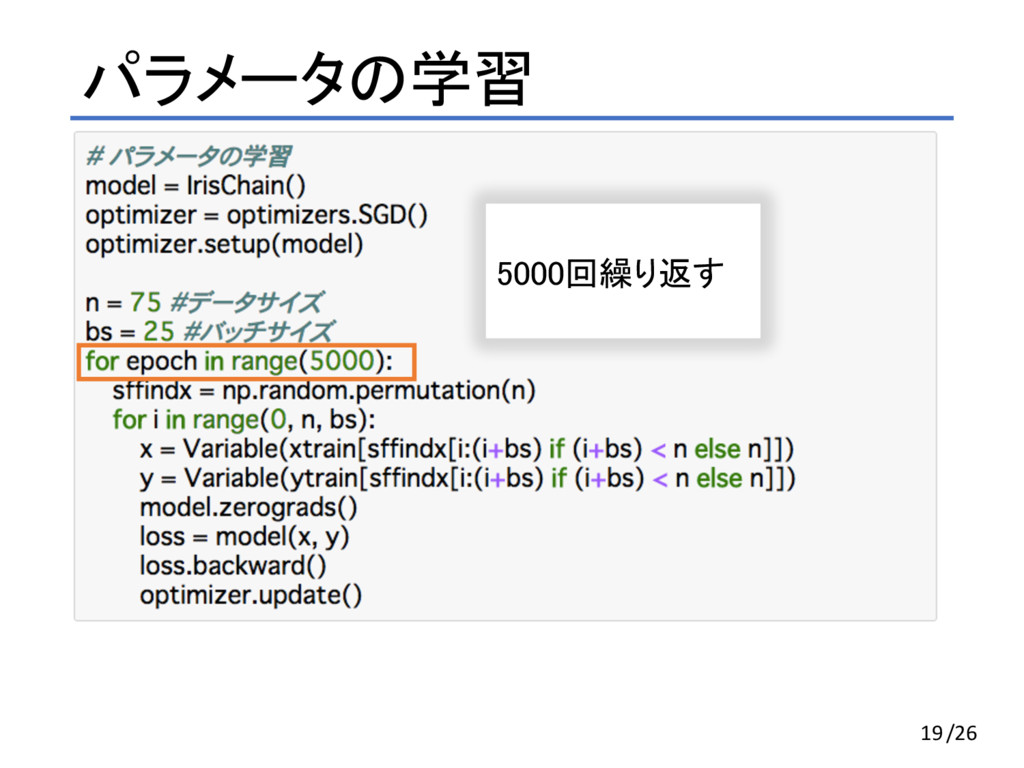
パラメータの学習 19 5000回繰り返す /26
パラメータの学習 20/26
評価 21/26
評価 22 テストデータをモデルに投入し、予測データを得る テストでは勾配を求める必要はないので Variable変数をvolatile=‘on’にする >>>print(ans) [[ 1.01755786e+00 1.39655769e-02 -2.12547127e-02]
[ 9.83523667e-01 3.55108976e-02 -3.01905852e-02] [ 1.03329992e+00 -1.48231089e-02 -1.54979099e-02] … [ -1.24957561e-01 2.79694885e-01 8.36571217e-01]] /26
評価 23 nrow = 75 ncol = 3 /26
評価 24 予測の最大が正解データと一致したら ok+1 >>>print(“{} {}”.format(ans[30], yans[30])) [ 0.0668037 0.80043787
0.15562642] 1 /26
評価 25/26
発表内容 26 • ChainerによるIrisデータの分類 参考文献 「Chainerによる実践深層学習」第4章 新納 浩幸 著 オーム社
/26
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Irisデータの用意 Y2 : 教師データ(変形) >>>print(Y2) [[ 1. 0. 0.] [](https://files.speakerdeck.com/presentations/59854fb178824ca98161e65ef959b60c/slide_8.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![評価 22 テストデータをモデルに投入し、予測データを得る テストでは勾配を求める必要はないので Variable変数をvolatile=‘on’にする >>>print(ans) [[ 1.01755786e+00 1.39655769e-02 -2.12547127e-02]](https://files.speakerdeck.com/presentations/59854fb178824ca98161e65ef959b60c/slide_22.jpg){kind=link}
{kind=link}
![評価 24 予測の最大が正解データと一致したら ok+1 >>>print(“{} {}”.format(ans[30], yans[30])) [ 0.0668037 0.80043787](https://files.speakerdeck.com/presentations/59854fb178824ca98161e65ef959b60c/slide_24.jpg){kind=link}
{kind=link}
{kind=link}