Code: https://github.com/polymorpher/bittiger
Course (My Lectures + Tutorials): https://www.bittiger.io/livecourses/YQCMuXwL7fhHuQT5K
This is an introductory level course for theory, implementation, and applications of topic modeling (and NLP). It also includes some pointers to advanced topics and state-of-the-art research papers.
![Copyright 2017 Aaron Li ([email protected]) Modelling Aaron Li [email protected] for](https://files.speakerdeck.com/presentations/341c7749f3804254a9b38f59e80fddfd/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![News Recommendation Copyright 2017 Aaron Li ([email protected]) 6 Copyright 2017](https://files.speakerdeck.com/presentations/341c7749f3804254a9b38f59e80fddfd/slide_5.jpg){kind=link}
{kind=link}
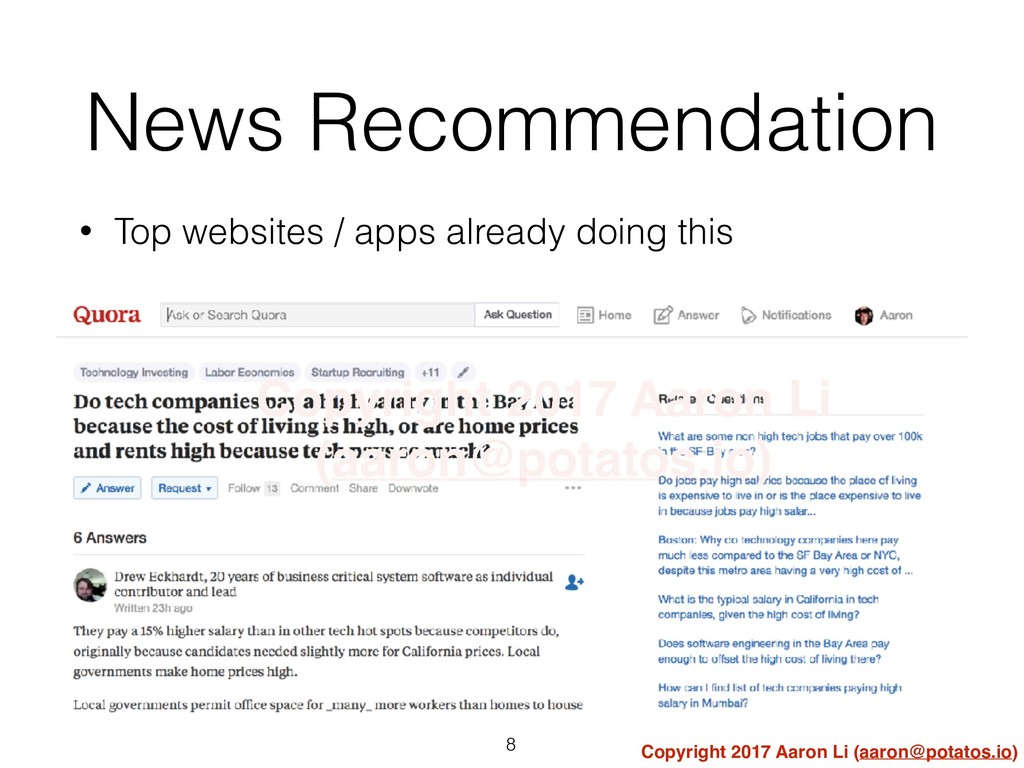{kind=link}
![News Recommendation Copyright 2017 Aaron Li ([email protected]) 9 Copyright 2017](https://files.speakerdeck.com/presentations/341c7749f3804254a9b38f59e80fddfd/slide_8.jpg){kind=link}
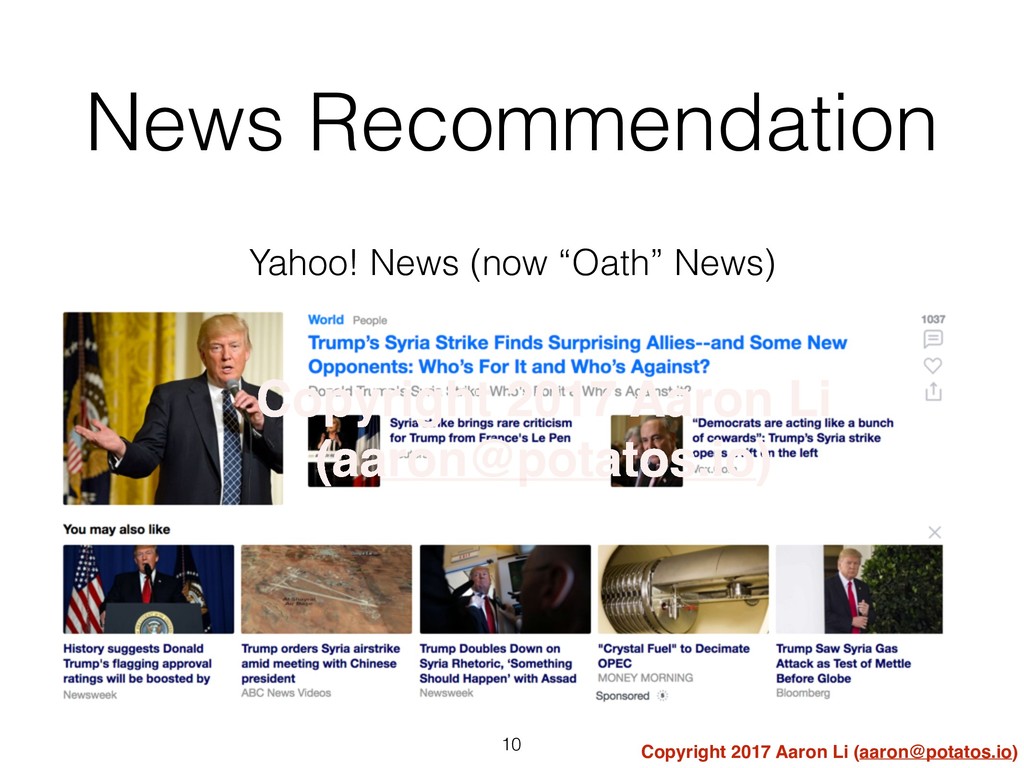{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Solutions Copyright 2017 Aaron Li ([email protected]) 14 Copyright 2017 Aaron](https://files.speakerdeck.com/presentations/341c7749f3804254a9b38f59e80fddfd/slide_13.jpg){kind=link}
{kind=link}
![NLP Preprocessing Copyright 2017 Aaron Li ([email protected]) 16 Copyright 2017](https://files.speakerdeck.com/presentations/341c7749f3804254a9b38f59e80fddfd/slide_15.jpg){kind=link}
![NLP Preprocessing Copyright 2017 Aaron Li ([email protected]) 17 Copyright 2017](https://files.speakerdeck.com/presentations/341c7749f3804254a9b38f59e80fddfd/slide_16.jpg){kind=link}
![NLP Preprocessing Copyright 2017 Aaron Li ([email protected]) 18 Copyright 2017](https://files.speakerdeck.com/presentations/341c7749f3804254a9b38f59e80fddfd/slide_17.jpg){kind=link}
![NLP Preprocessing Copyright 2017 Aaron Li ([email protected]) 19 Copyright 2017](https://files.speakerdeck.com/presentations/341c7749f3804254a9b38f59e80fddfd/slide_18.jpg){kind=link}
![NLP Preprocessing Copyright 2017 Aaron Li ([email protected]) 20 Copyright 2017](https://files.speakerdeck.com/presentations/341c7749f3804254a9b38f59e80fddfd/slide_19.jpg){kind=link}
![NLP Preprocessing Copyright 2017 Aaron Li ([email protected]) 21 Copyright 2017](https://files.speakerdeck.com/presentations/341c7749f3804254a9b38f59e80fddfd/slide_20.jpg){kind=link}
![NLP Preprocessing Copyright 2017 Aaron Li ([email protected]) 22 Copyright 2017](https://files.speakerdeck.com/presentations/341c7749f3804254a9b38f59e80fddfd/slide_21.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Copyright 2017 Aaron Li ([email protected]) 28 Copyright 2017 Aaron Li](https://files.speakerdeck.com/presentations/341c7749f3804254a9b38f59e80fddfd/slide_27.jpg){kind=link}
![Topic Models Copyright 2017 Aaron Li ([email protected]) 29 Copyright 2017](https://files.speakerdeck.com/presentations/341c7749f3804254a9b38f59e80fddfd/slide_28.jpg){kind=link}
{kind=link}
![LDA Copyright 2017 Aaron Li ([email protected]) 31 Copyright 2017 Aaron](https://files.speakerdeck.com/presentations/341c7749f3804254a9b38f59e80fddfd/slide_30.jpg){kind=link}
![LDA Copyright 2017 Aaron Li ([email protected]) 32 Copyright 2017 Aaron](https://files.speakerdeck.com/presentations/341c7749f3804254a9b38f59e80fddfd/slide_31.jpg){kind=link}
![LDA Copyright 2017 Aaron Li ([email protected]) 33 Copyright 2017 Aaron](https://files.speakerdeck.com/presentations/341c7749f3804254a9b38f59e80fddfd/slide_32.jpg){kind=link}
![Example Copyright 2017 Aaron Li ([email protected]) 34 Copyright 2017 Aaron](https://files.speakerdeck.com/presentations/341c7749f3804254a9b38f59e80fddfd/slide_33.jpg){kind=link}
![Example Copyright 2017 Aaron Li ([email protected]) 35 Copyright 2017 Aaron](https://files.speakerdeck.com/presentations/341c7749f3804254a9b38f59e80fddfd/slide_34.jpg){kind=link}
![Example Copyright 2017 Aaron Li ([email protected]) 36 Copyright 2017 Aaron](https://files.speakerdeck.com/presentations/341c7749f3804254a9b38f59e80fddfd/slide_35.jpg){kind=link}
{kind=link}
![Theory 1 Copyright 2017 Aaron Li ([email protected]) 38 Copyright 2017](https://files.speakerdeck.com/presentations/341c7749f3804254a9b38f59e80fddfd/slide_37.jpg){kind=link}
{kind=link}
![LDA Inference Copyright 2017 Aaron Li ([email protected]) 40 Copyright 2017](https://files.speakerdeck.com/presentations/341c7749f3804254a9b38f59e80fddfd/slide_39.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![LDA Inference Copyright 2017 Aaron Li ([email protected]) 44 Copyright 2017](https://files.speakerdeck.com/presentations/341c7749f3804254a9b38f59e80fddfd/slide_43.jpg){kind=link}
![LDA Inference Copyright 2017 Aaron Li ([email protected]) 45 Copyright 2017](https://files.speakerdeck.com/presentations/341c7749f3804254a9b38f59e80fddfd/slide_44.jpg){kind=link}
![LDA Inference Copyright 2017 Aaron Li ([email protected]) 46 Copyright 2017](https://files.speakerdeck.com/presentations/341c7749f3804254a9b38f59e80fddfd/slide_45.jpg){kind=link}
![Putting everything together LDA Inference Copyright 2017 Aaron Li ([email protected])](https://files.speakerdeck.com/presentations/341c7749f3804254a9b38f59e80fddfd/slide_46.jpg){kind=link}
![LDA Inference Copyright 2017 Aaron Li ([email protected]) 48 Copyright 2017](https://files.speakerdeck.com/presentations/341c7749f3804254a9b38f59e80fddfd/slide_47.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![Theory 2 Copyright 2017 Aaron Li ([email protected]) 52 Copyright 2017](https://files.speakerdeck.com/presentations/341c7749f3804254a9b38f59e80fddfd/slide_51.jpg){kind=link}