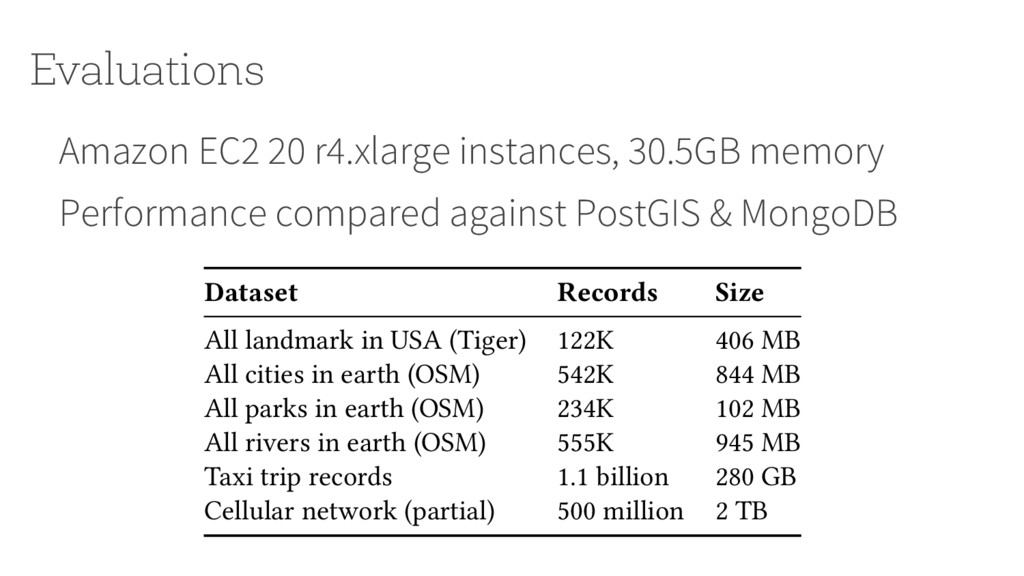
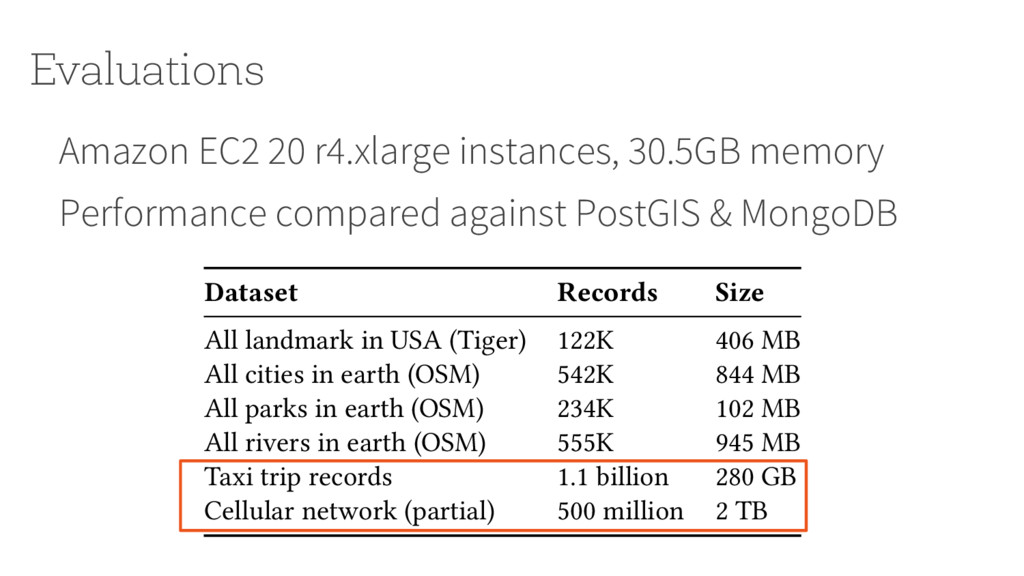
PostGIS & MongoDB Evaluations Dataset Records Size All landmark in USA (Tiger) 122K 406 MB All cities in earth (OSM) 542K 844 MB All parks in earth (OSM) 234K 102 MB All rivers in earth (OSM) 555K 945 MB Taxi trip records 1.1 billion 280 GB Cellular network (partial) 500 million 2 TB Table 2: Real-world datasets used in evaluations (from [27, 45, 49]).
PostGIS & MongoDB Evaluations Dataset Records Size All landmark in USA (Tiger) 122K 406 MB All cities in earth (OSM) 542K 844 MB All parks in earth (OSM) 234K 102 MB All rivers in earth (OSM) 555K 945 MB Taxi trip records 1.1 billion 280 GB Cellular network (partial) 500 million 2 TB Table 2: Real-world datasets used in evaluations (from [27, 45, 49]).
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
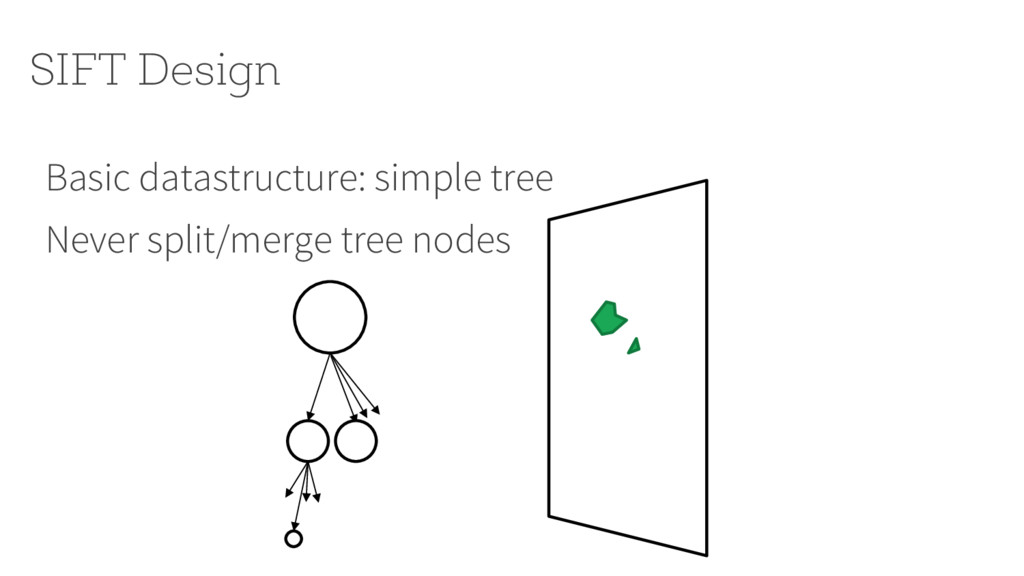{kind=link}
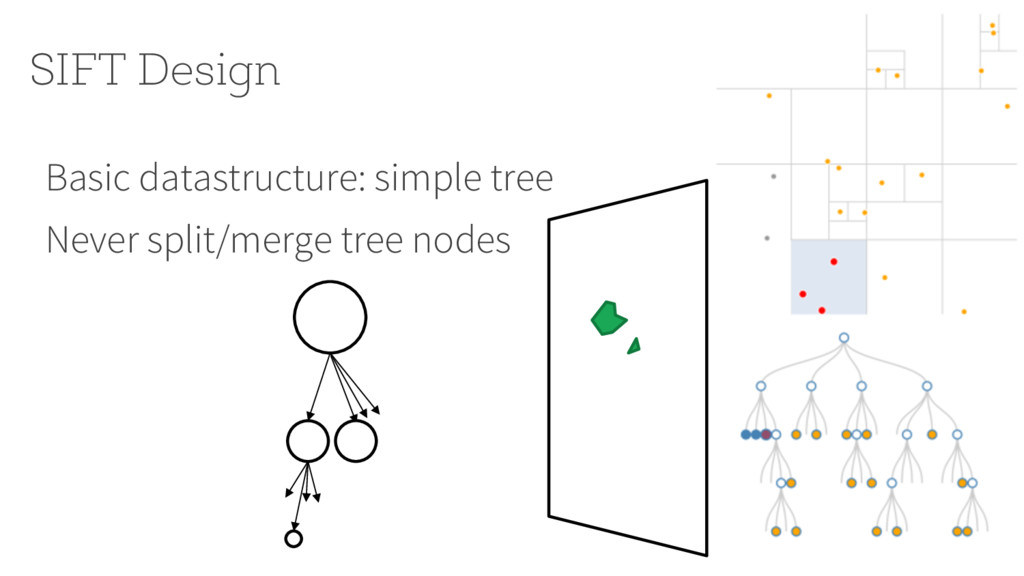{kind=link}
{kind=link}
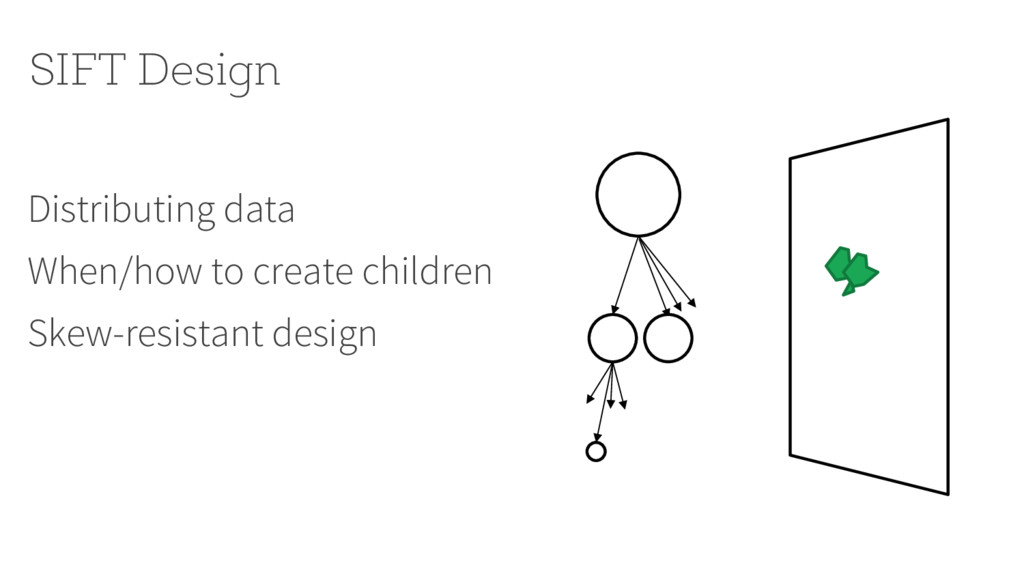{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
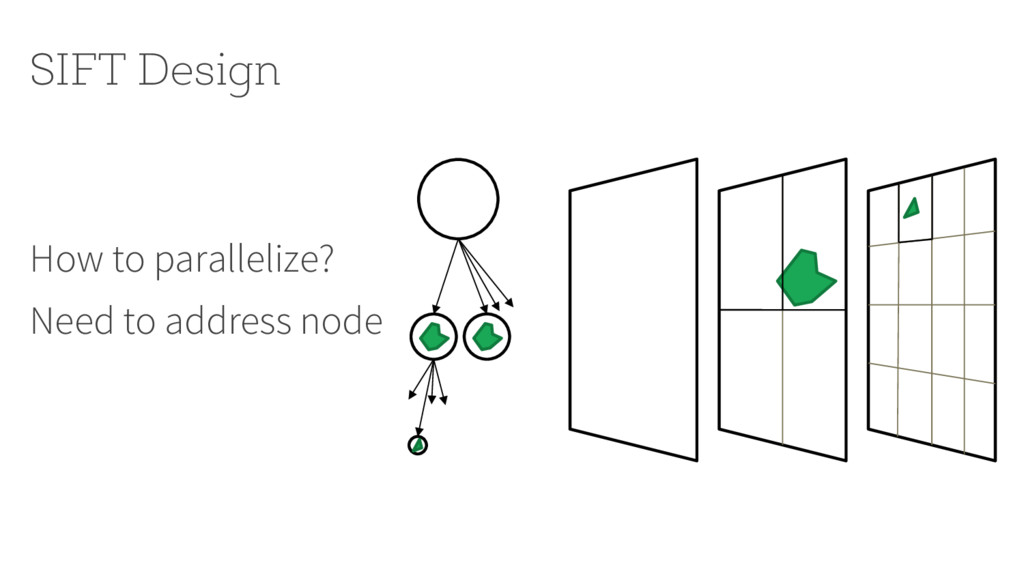{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}