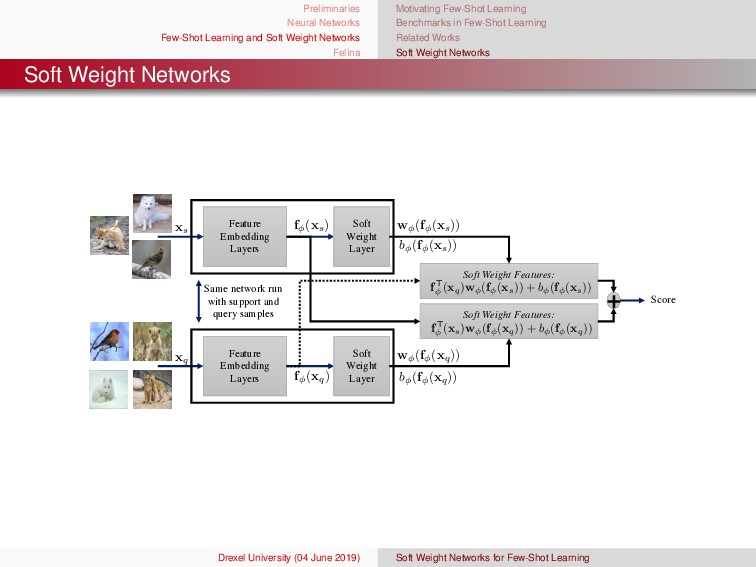
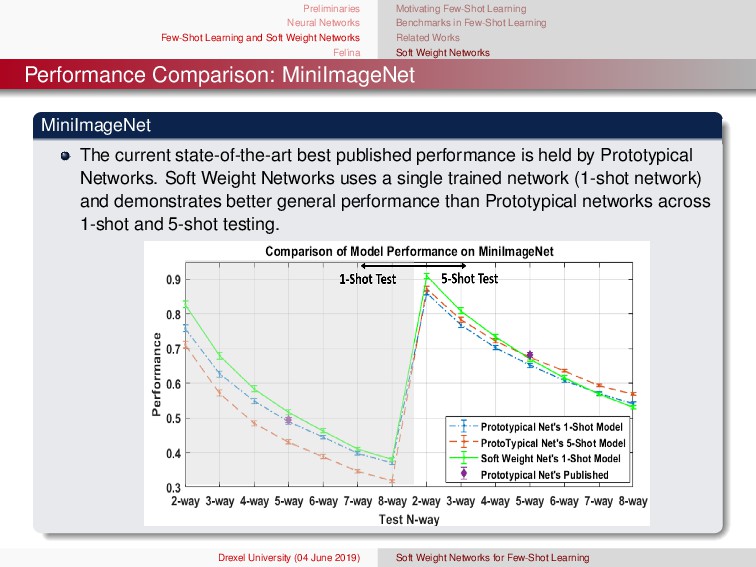
ına Motivating Few-Shot Learning Benchmarks in Few-Shot Learning Related Works Soft Weight Networks Soft Weight Networks Training Algorithm Input: Entire Training Set Tr = {(x1 , y1), ..., (xNTr , yNTr )}, number of support samples per episode N, number of query samples per episode M, number of classes per episode C, initial model φ, and model learning rate η Output: updated model φ, network loss J(φ), and class estimates yqm 1: for each episode in training data do 2: Create a set, E = {(x1 , y1), ..., (xNE , yNTE )}, of C different classes randomly chosen from Tr without replacement 3: Create disjoint sets, S = {(x1 , y1), ..., (xN , yN )} and Q = {(x1 , y1), ..., (xM , yM)}, of N support examples and M query samples from E 4: for m = 1, . . . , M do {Loop through query samples} 5: for c = 1, . . . , C do {Loop through class samples} 6: // Compute the classification scores for every query sample 7: αqm(c) = (xsi,ysi)∈Sc bφ(fφ(xsi)) + fT φ (xqm)wφ(fφ(xsi)) 8: βqm(c) = (xsi,ysi)∈Sc bφ(fφ(xqm)) + fT φ (xsi)wφ(fφ(xqm)) 9: end for 10: for c = 1, . . . , C do 11: pφ(y = c|xqm) = e(αqm(c)+βqm(c)) c ∈C e(αqm(c )+βqm(c )) {Estimate posterior via softmax} 12: end for 13: yqm =c∈C [pφ(y = c|xqm )] {Estimate class of query sample} 14: end for 15: J(φ) = − 1 CM C c =1 M q=1 log(pφ(y = c |xqm)) {Compute average loss of episode} 16: φ ← φ − η∇φJ(φ) {Update model} 17: end for Drexel University (04 June 2019) Soft Weight Networks for Few-Shot Learning
{kind=link}
{kind=link}
{kind=link}
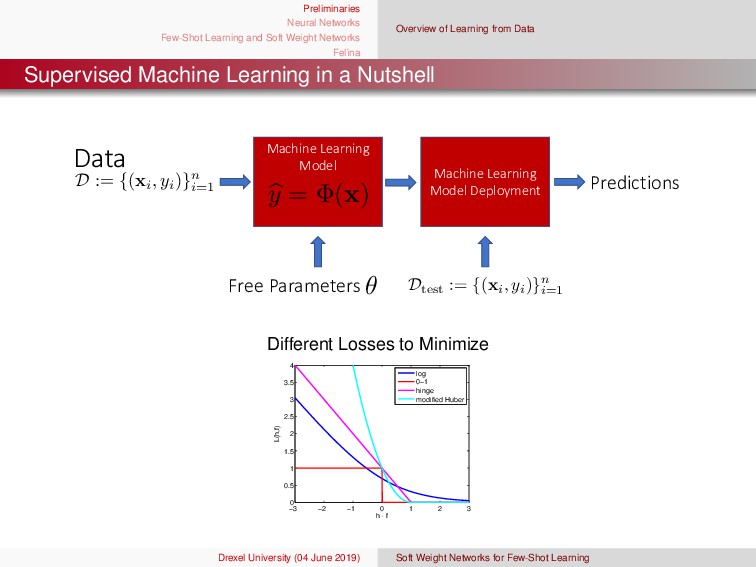{kind=link}
{kind=link}
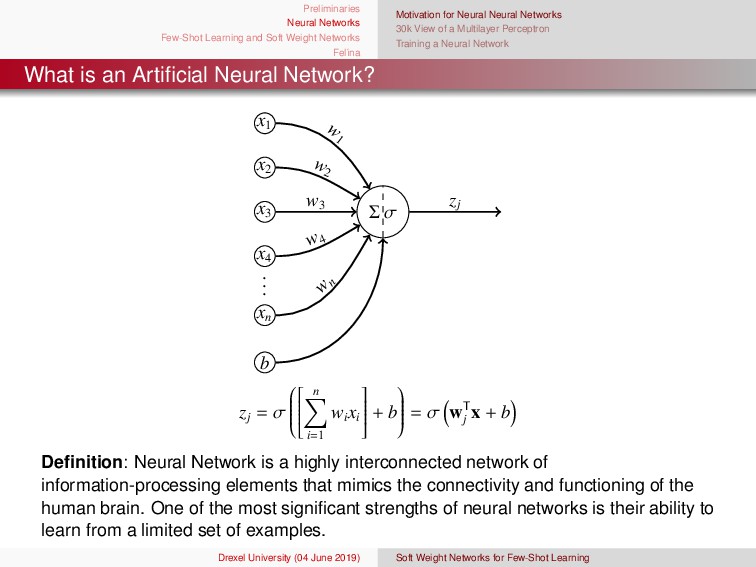{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}