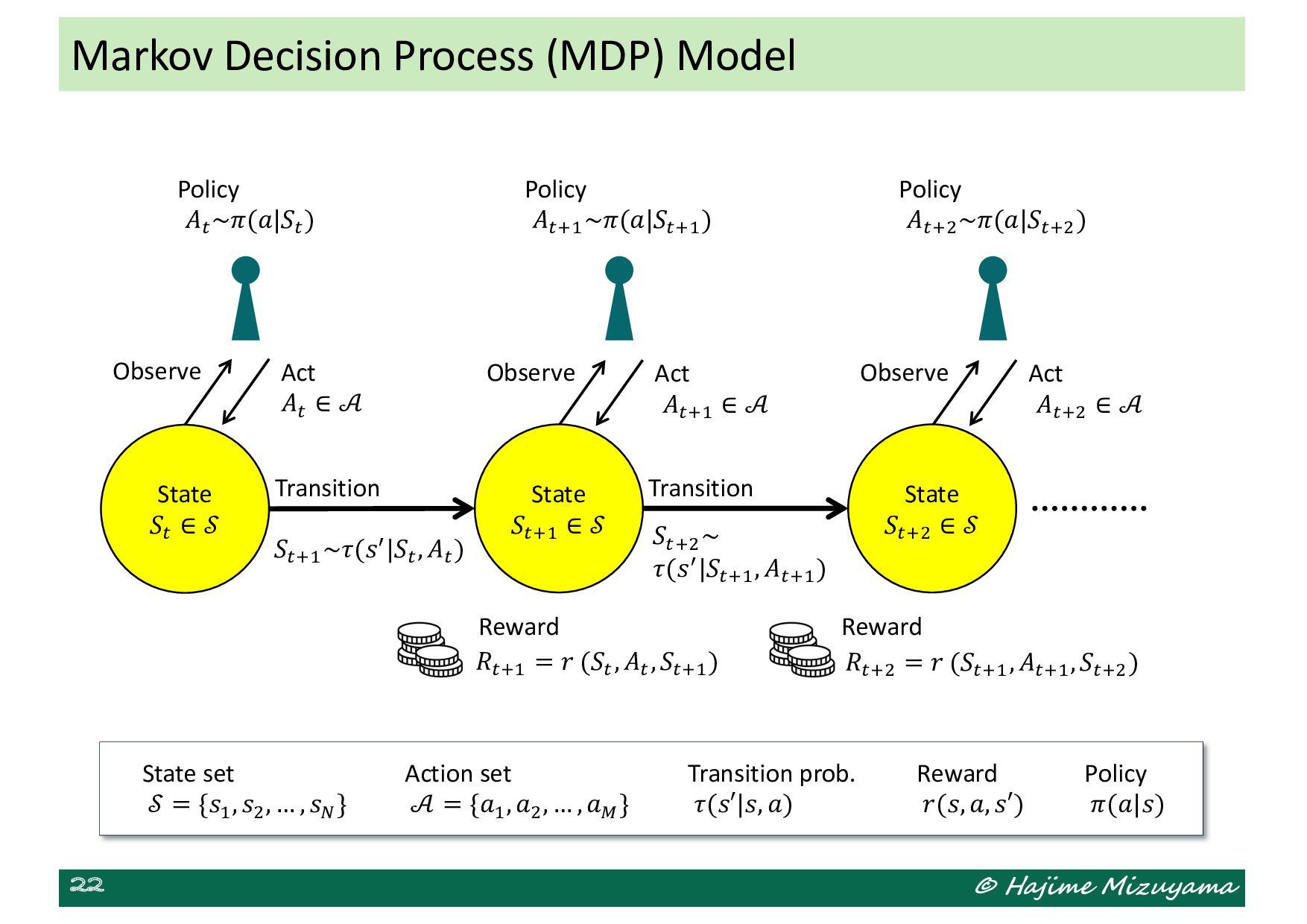
and control (1): Dynamic scheduling environment, discrete-event simulation (DES), and online job shop scheduling Dynamic scheduling and control (2): Discrete-time simulation (DTS), black-box optimization, and reinforcement learning Scheduling games and mechanisms (1): Game theoretical scheduling environment, and price of anarchy (POA) Scheduling games and mechanisms (2): Mechanism design, VCG mechanism, and scheduling auction Supply chain management (1): Bullwhip effect, and supply chain simulation Supply chain management (2): Double marginalization, and game theoretical analysis Summary and review
of the system changes only at specific intervals, and there are no (need to consider) changes between those intervals. • A discrete-event simulation model can be simplified to a discrete-time one if we can assume that relevant events occur only periodically at specific intervals. • To establish a discrete-time simulation model for a system, the following questions need to be answered: – What is the relevant state of the system and how to encode it? – What is the suitable length of intervals for discretizing time axis? – How the state of the system changes at each discrete time point? Discrete-Time Simulation (DTS)
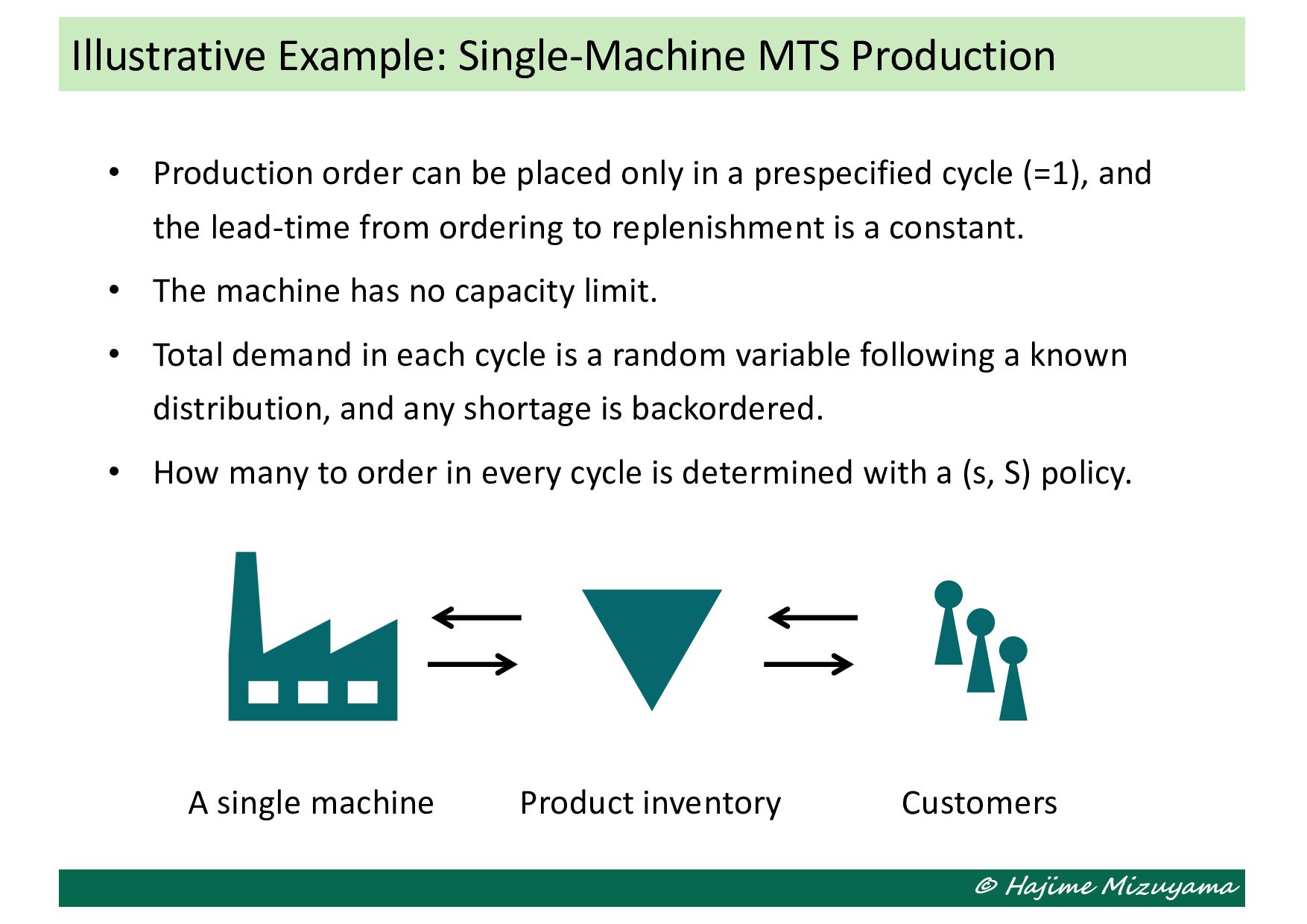
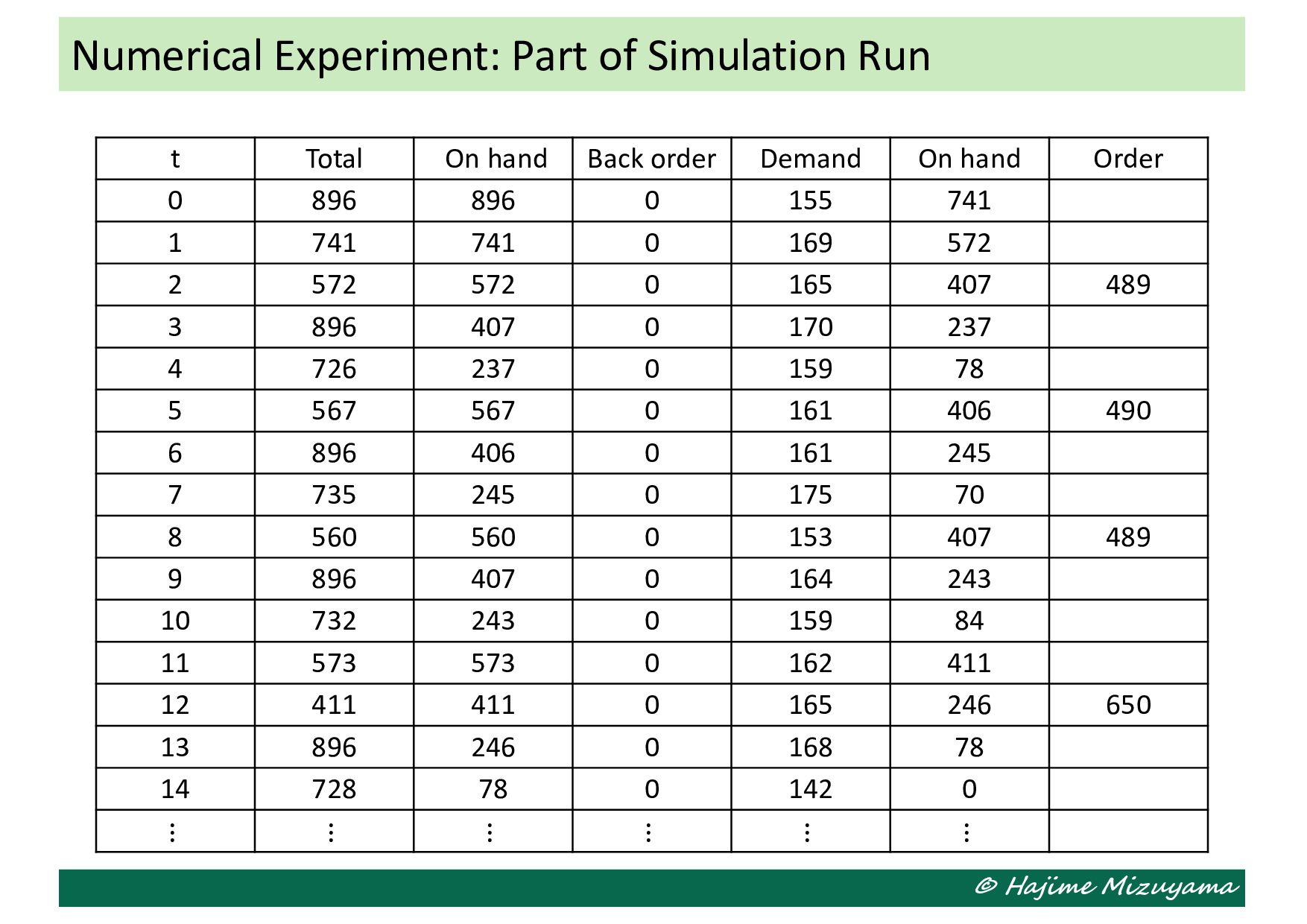
in a prespecified cycle (=1), and the lead-time from ordering to replenishment is a constant. • The machine has no capacity limit. • Total demand in each cycle is a random variable following a known distribution, and any shortage is backordered. • How many to order in every cycle is determined with a (s, S) policy. Illustrative Example: Single-Machine MTS Production A single machine Product inventory Customers
replenishment • 𝑠: Ordering point (reorder level) • 𝑆: Order-up-to level • ) 𝐼!: Initial stock level System state • 𝐼%: Level of stock on hand in current period 𝑡 • 𝐵%: Level of back order in current period 𝑡 • 𝑜%& &∈{!,*,+,⋯,-.}: Unreplenished order quantities placed in period 𝑡 − 𝑙 DTS Model: System State
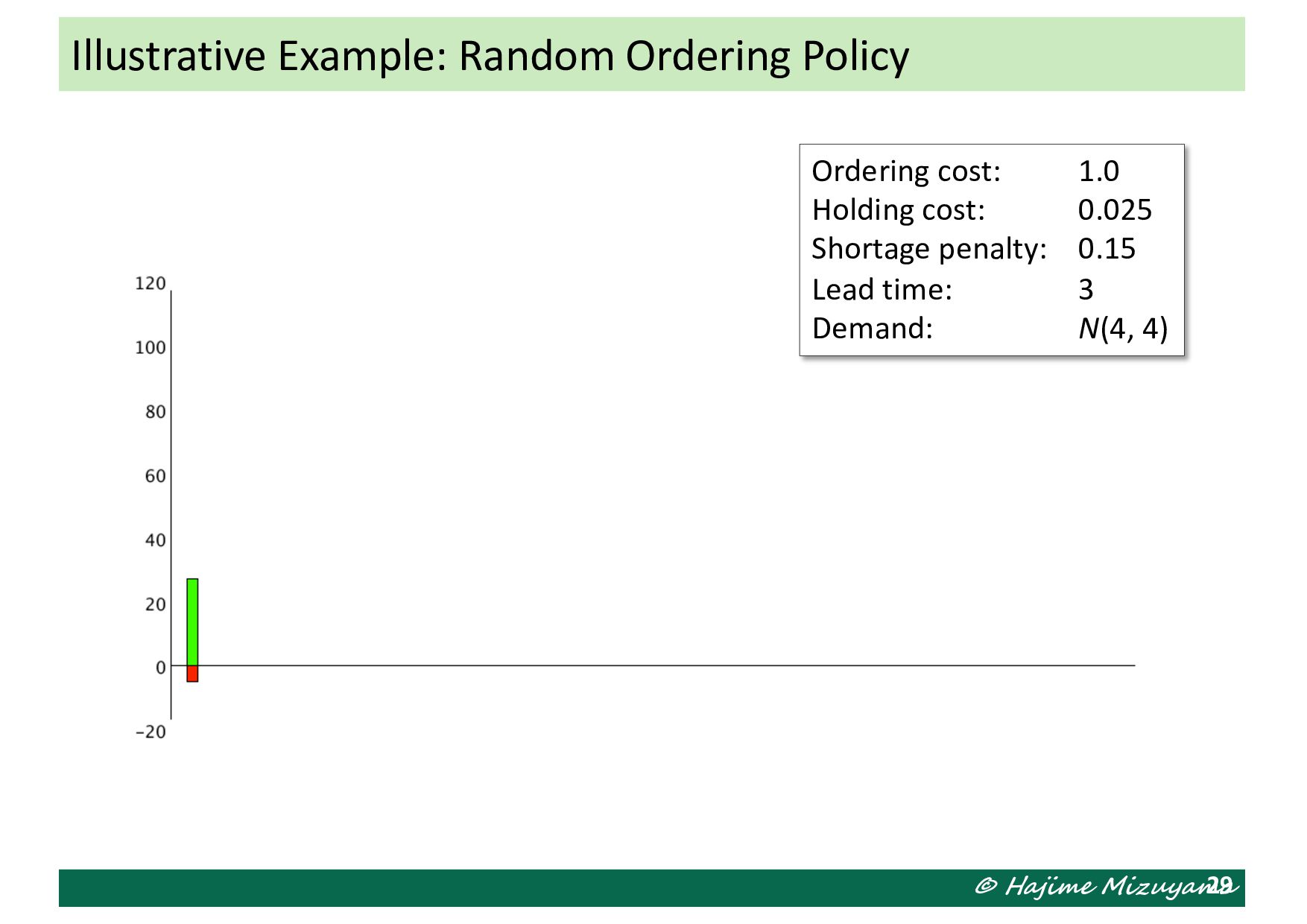
is incurred each time an order is placed • Inventory holding cost: Proportional to the average levels of stock on hand before and after shipment in each period • Shortage cost (penalty): Proportional to the level of back order in each period Total cost incurred in period 𝒕 𝐶% . = 𝐶4 + (𝐼%1* + 𝑜% -. − 𝐵%1* ) + 𝐼% 2 𝐶5 + 𝐵% 𝐶6 (𝑜%! > 0) (𝐼%1* + 𝑜% -. − 𝐵%1* ) + 𝐼% 2 𝐶5 + 𝐵% 𝐶6 (𝑜%! = 0) Assumption on Relevant Costs
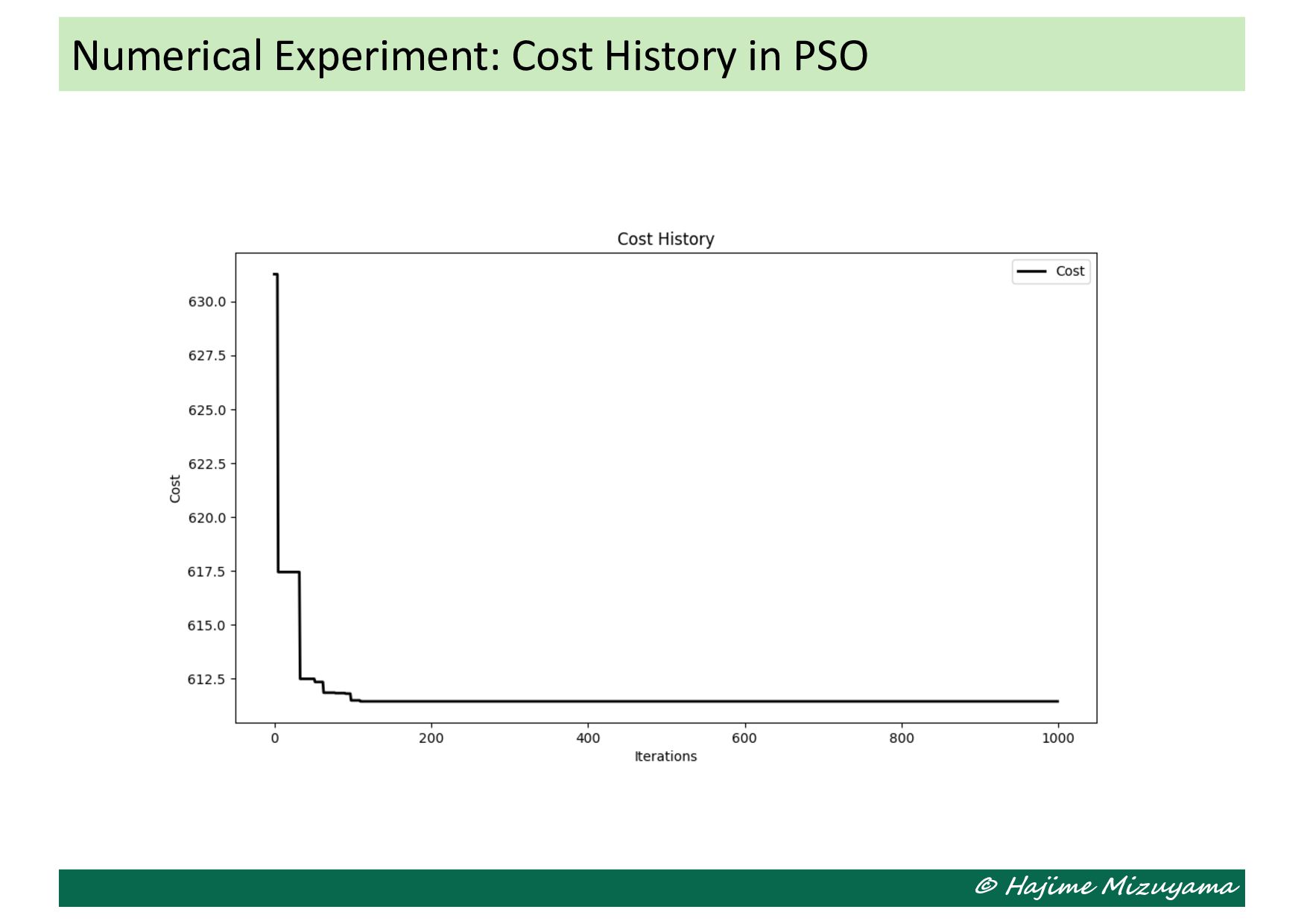
argmin (=, 6) 𝐶% . Black-box optimization • The objective function of this optimization problem is an unknown function of the decision variables, and its (noisy) value at a specified values of the variables can only be obtained by running a simulation. • An optimization problem of this kind is a typical example of the black- box optimization problem, which needs to be addressed without relying on, for example, the gradient of the objective function. Black-Box Optimization of Ordering Policy (s, S)
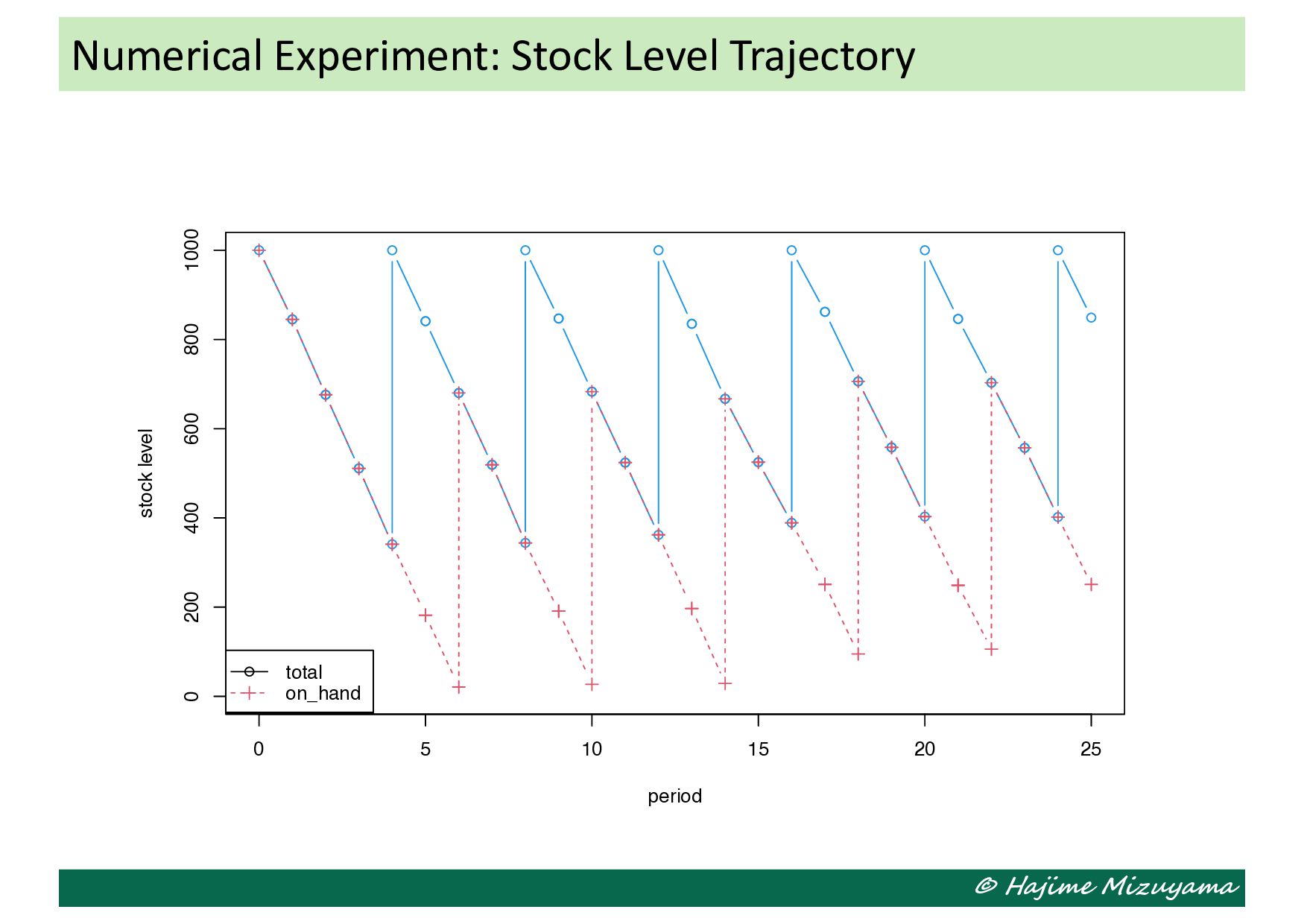
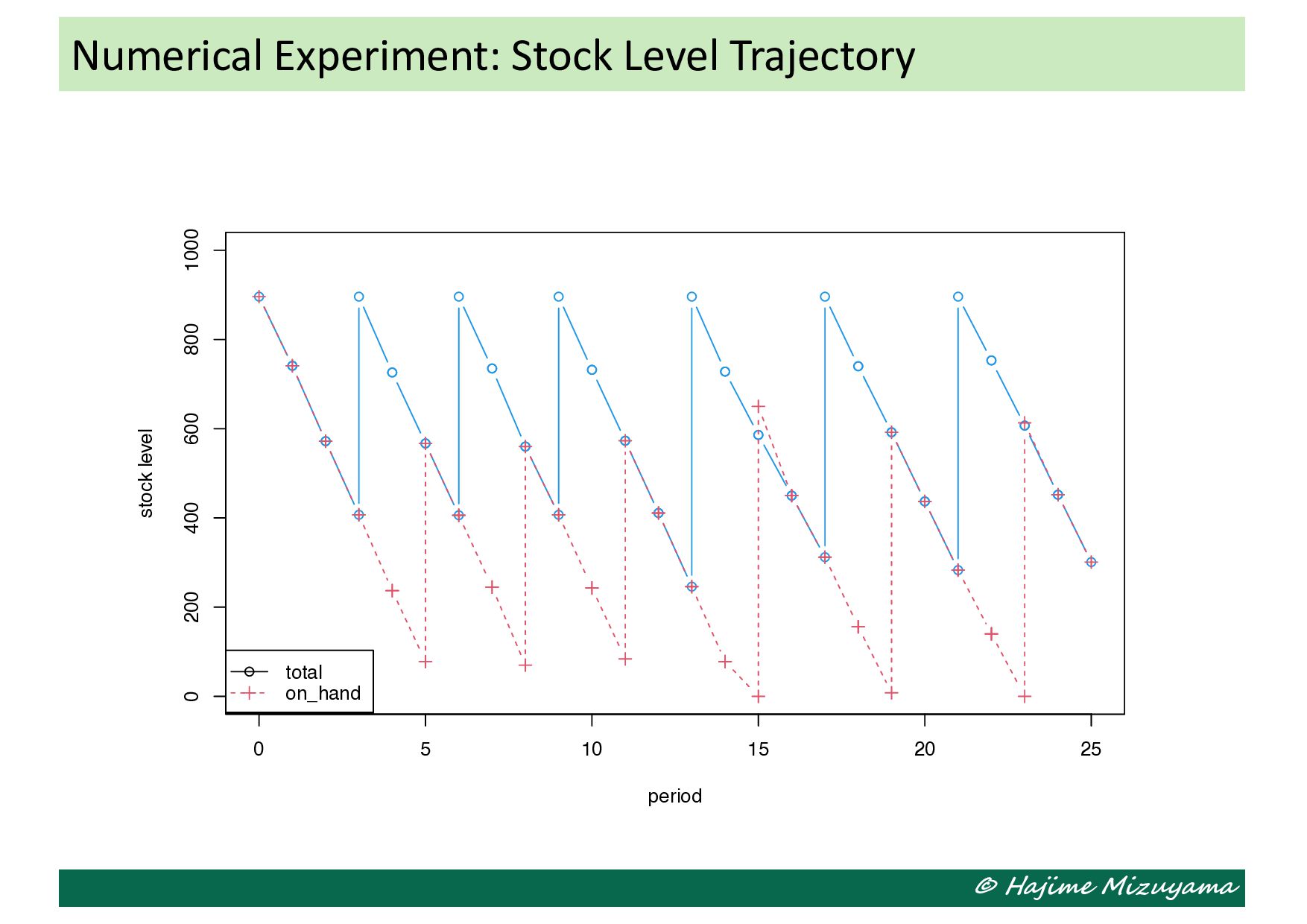
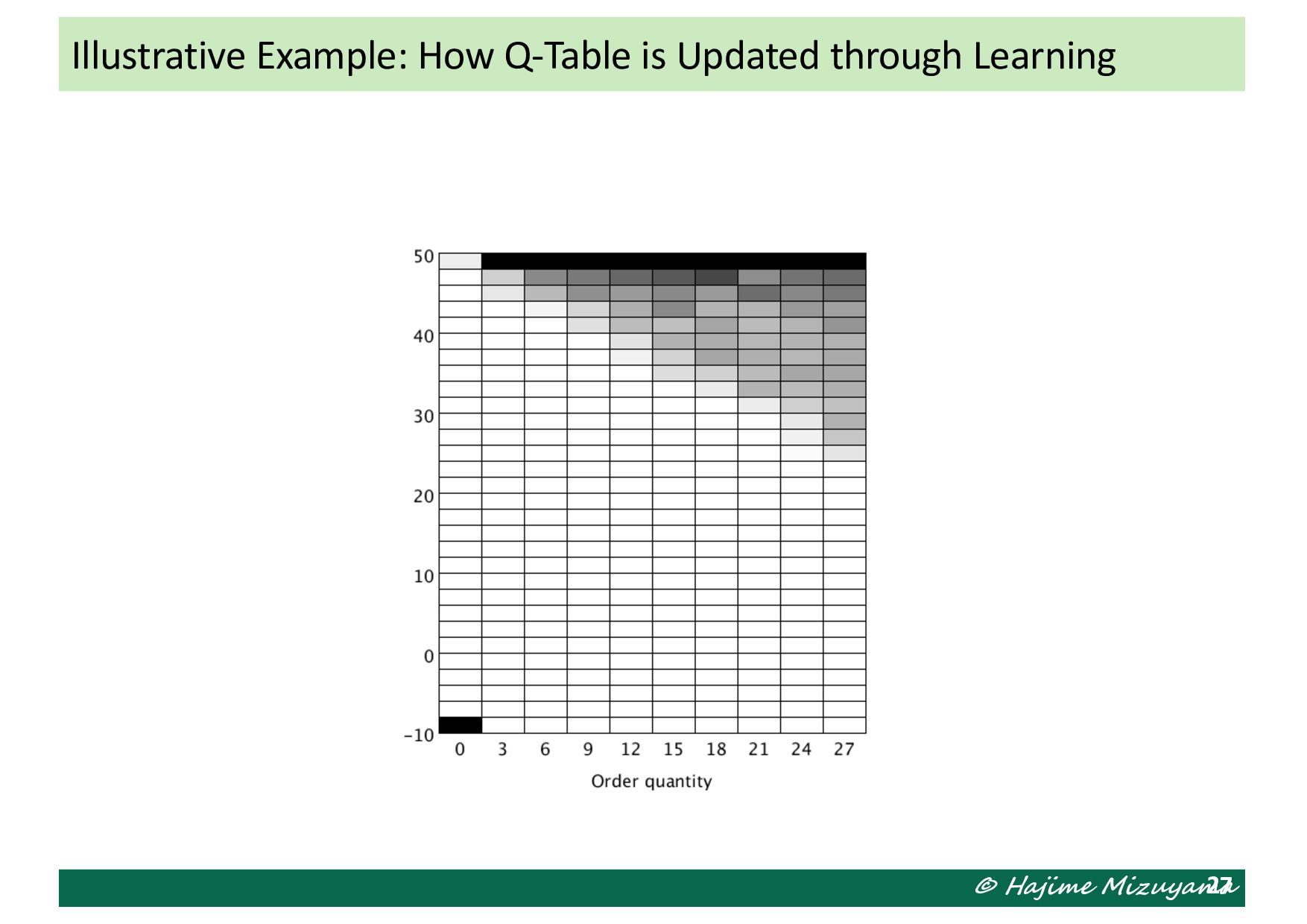
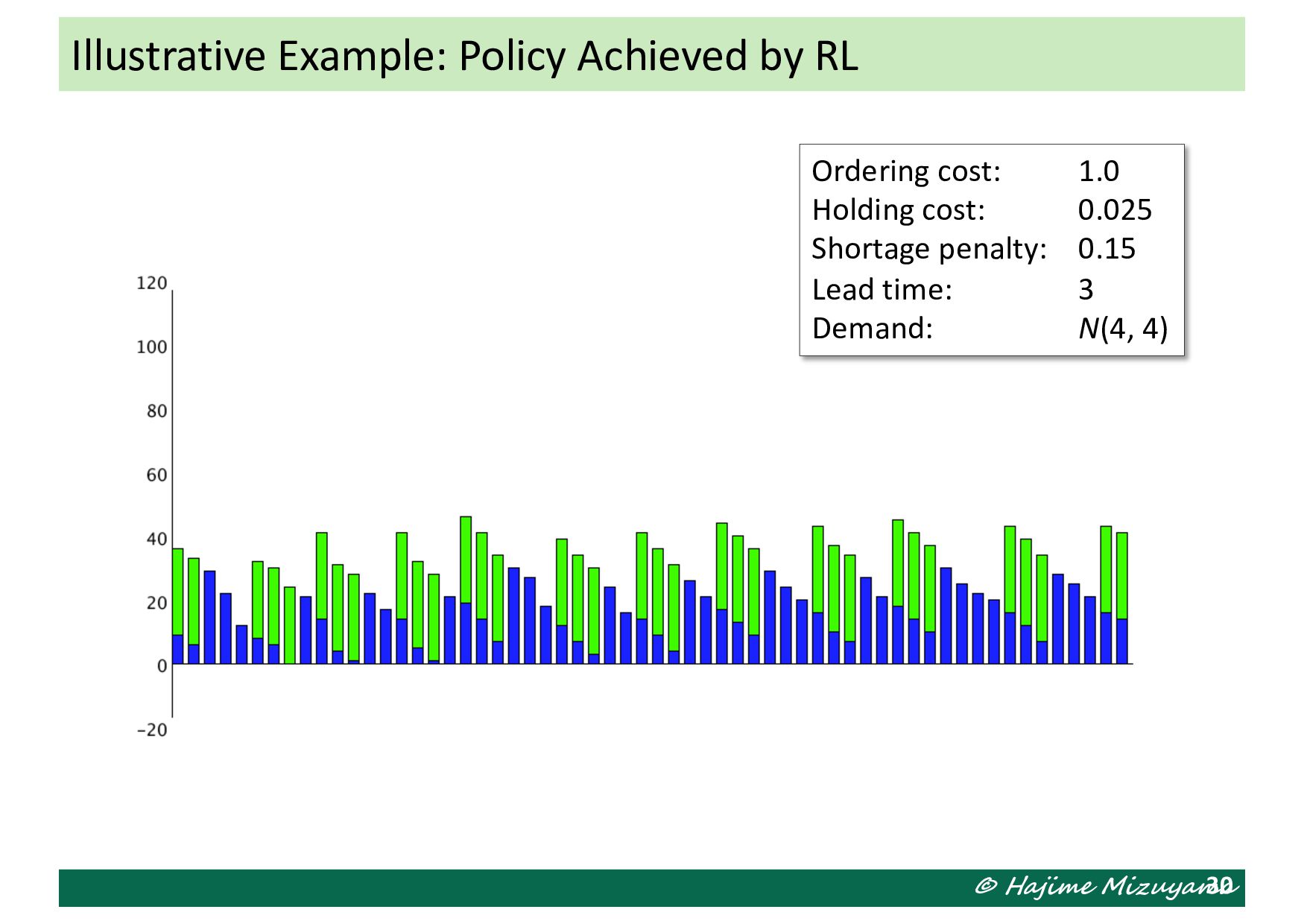
we define 𝑥 = = *!!! , 6 +!!! and 𝑓 𝑥 = 𝐶% .(𝑥) • The objective function value at each particle 𝑥> is evaluated by running the simulation for 5000 periods (after 50 periods of dry run). • As the result, the following solution is obtained: 𝑥∗ = (0.549, 0.506) (𝑠∗, 𝑆∗ ) = 549, 1012 𝐶% . = 656.5961 Numerical Experiment: Application of PSO
discrete-time simulator for single-machine MTS production and to (semi)optimize policy parameter values using the simulator and PSO is available from the following link. Push “Open in Colab” button, then you can test it in Google Colaboratory environment. https://github.com/j54854/myColab/blob/main/pom2_10.ipynb Discrete-Time Simulator for Sigle-Machine MTS Production
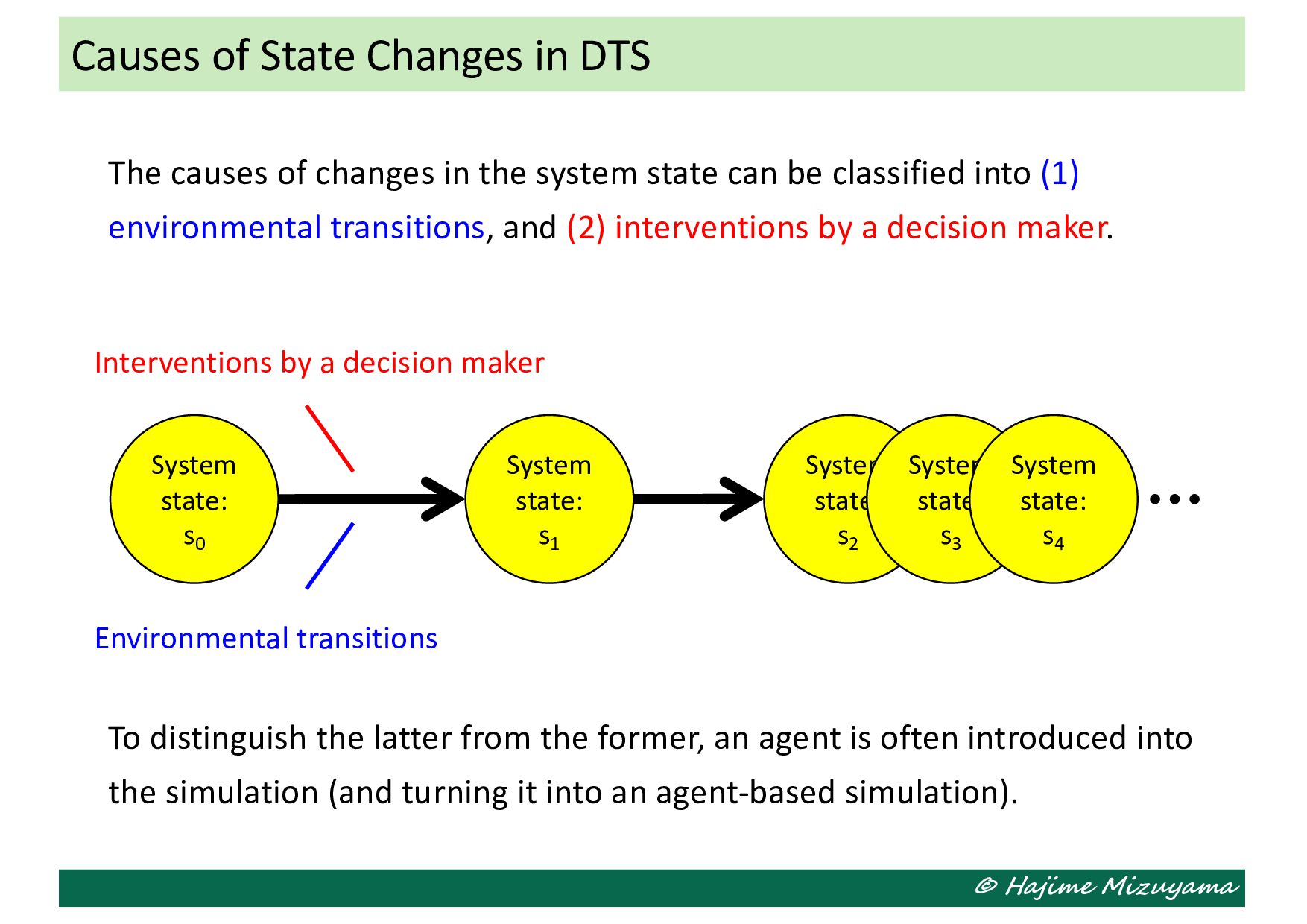
state can be classified into (1) environmental transitions, and (2) interventions by a decision maker. To distinguish the latter from the former, an agent is often introduced into the simulation (and turning it into an agent-based simulation). Causes of State Changes in DTS System state: s0 System state: s2 System state: s3 System state: s4 System state: s1 Environmental transitions Interventions by a decision maker
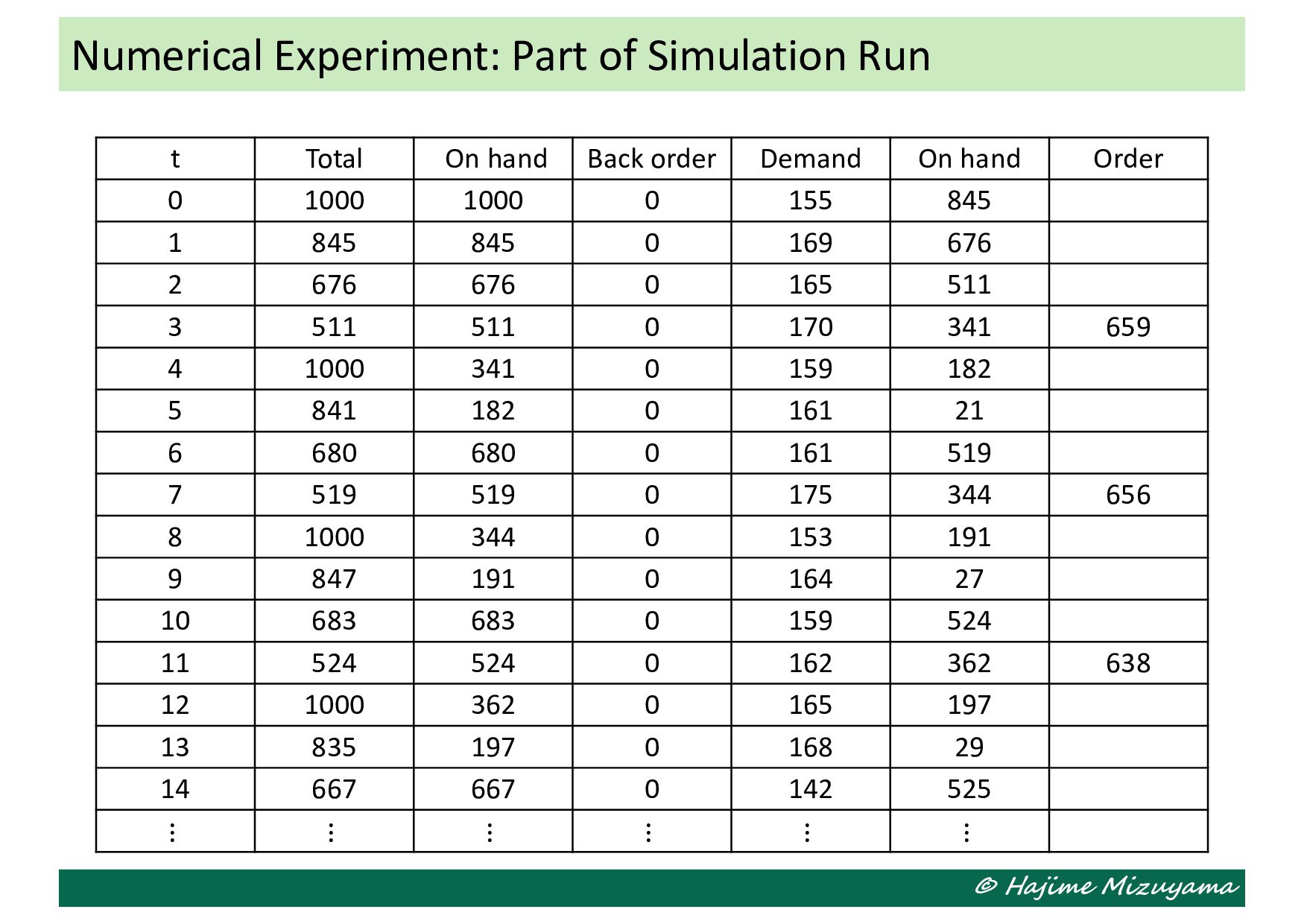
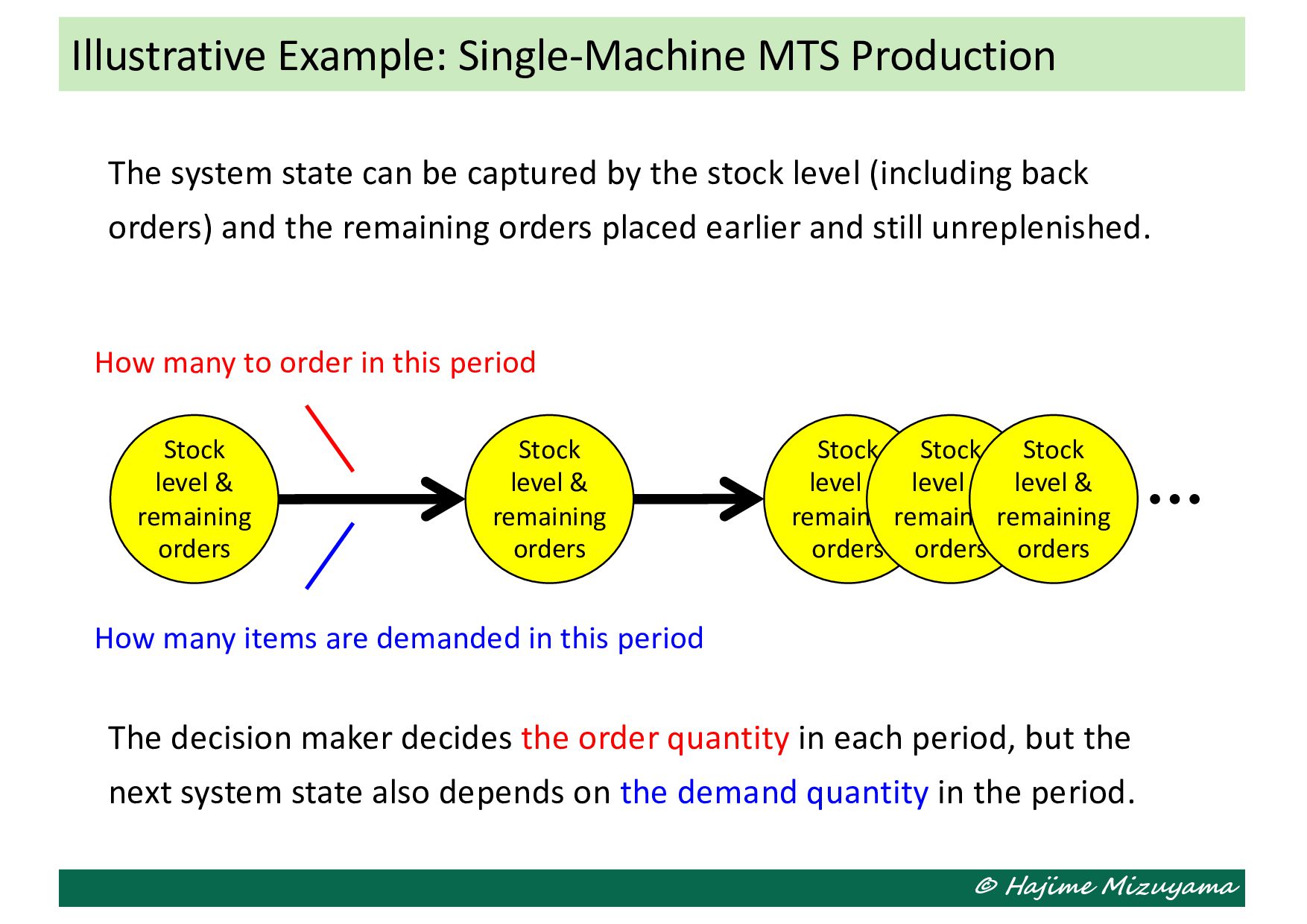
the stock level (including back orders) and the remaining orders placed earlier and still unreplenished. The decision maker decides the order quantity in each period, but the next system state also depends on the demand quantity in the period. Illustrative Example: Single-Machine MTS Production Stock level & remaining orders Stock level & remaining orders Stock level & remaining orders Stock level & remaining orders Stock level & remaining orders How many items are demanded in this period How many to order in this period
In each state, take the action which gives the maximum Q value in the corresponding row. When state is parameterized as 𝒙 = (𝑥* , 𝑥+ , … ), Q-table can be generalized to a Q- function 𝑄 𝑠, 𝑎 = 𝑓(𝒙, 𝑎). The famous DQN uses a deep neural network (a deep leaning model) for approximating this function. 24 a1 a2 a3 … s1 s2 s3 s4 s5 …
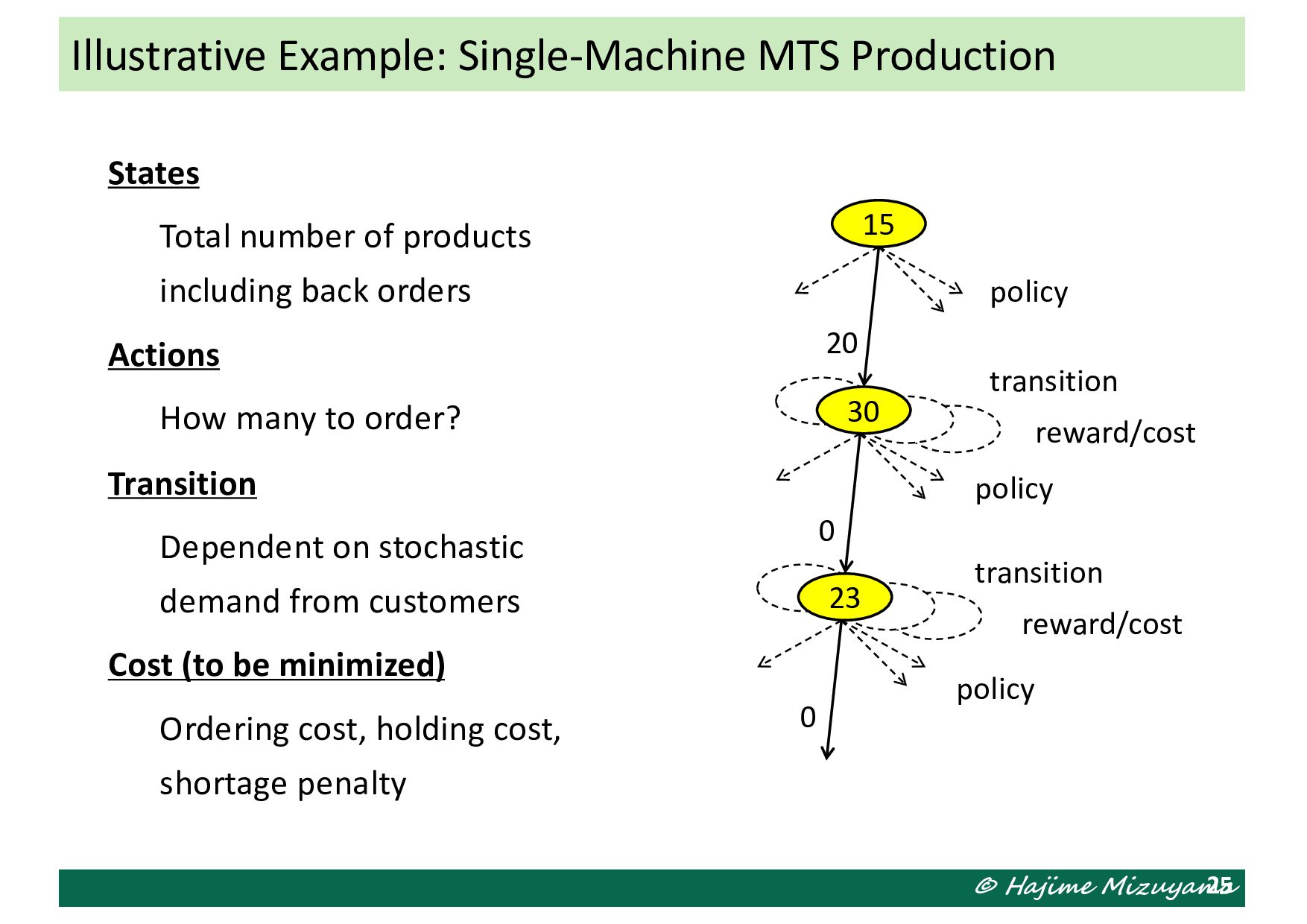
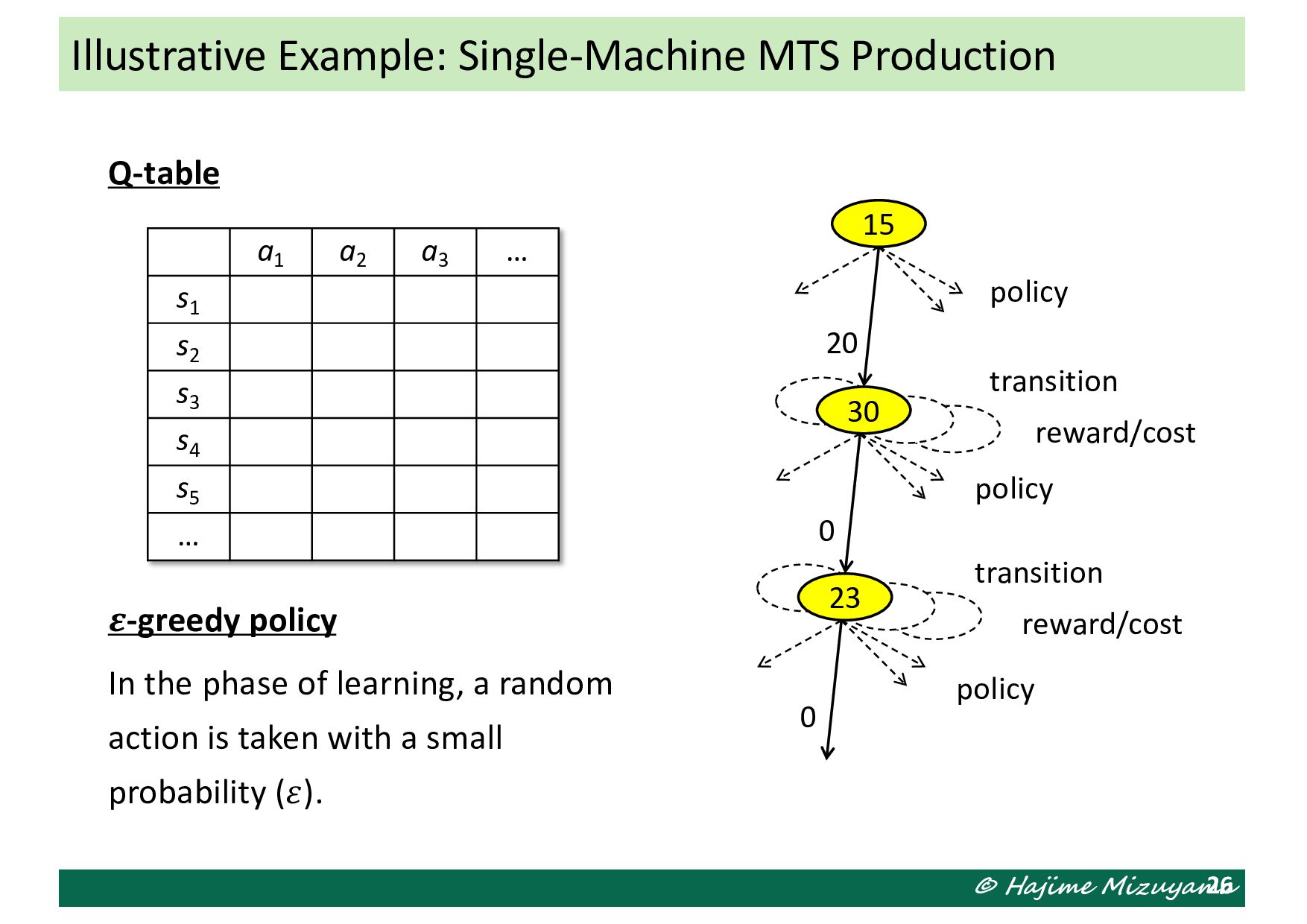
number of products including back orders Actions How many to order? Transition Dependent on stochastic demand from customers Cost (to be minimized) Ordering cost, holding cost, shortage penalty 25 15 20 policy 30 transition reward/cost 0 policy 23 transition reward/cost 0 policy
policy In the phase of learning, a random action is taken with a small probability (𝜀). 26 a1 a2 a3 … s1 s2 s3 s4 s5 … 15 20 policy 30 transition reward/cost 0 policy 23 transition reward/cost 0 policy
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}