Even Unassociated Features Can Improve Lexical Distributional Similarity
Kazuhide Yamamoto and Takeshi Asakura. Even Unassociated Features Can Improve Lexical Distributional Similarity. Proceedings of The Second International Workshop on NLP Challenges in the Information Explosion Era (NLPIX 2010), pp.32-39 (2010.8)
Improve Can Improve Lexical Distributional Similarity Lexical Distributional Similarity Kazuhide Yamamoto Kazuhide Yamamoto Takeshi Asakura Takeshi Asakura Nagaoka University of Technology, Japan Nagaoka University of Technology, Japan
in natural language processing Essential task in natural language processing Look for similar words for Look for similar words for (corpus-driven) summarization, machine translation, (corpus-driven) summarization, machine translation, textual entailment recognition, ... textual entailment recognition, ... Generalize or cluster words for Generalize or cluster words for Language modeling, word sense disambiguation, ... Language modeling, word sense disambiguation, ...
thesaurus / ontology Based on thesaurus / ontology Such as WordNet Such as WordNet Based on corpus = Based on corpus = distributional similarity distributional similarity Harris (1968) : “semantically similar words tend to Harris (1968) : “semantically similar words tend to appear in similar contexts.” appear in similar contexts.” Target of our work Target of our work
Japanese two words: たばこ たばこ (tobacco) (tobacco) タバコ タバコ (tobacco) (tobacco) Same pronunciation Same pronunciation Same meaning Same meaning Computed similarity is Computed similarity is far from 1.0 (0.428) far from 1.0 (0.428)
Context There must be There must be many noises included many noises included in a context that in a context that causes inaccurate similarity measure. causes inaccurate similarity measure. If that is the case, we should If that is the case, we should clean context clean context before before computing similarity. computing similarity. State-of-the-art appoaches are used for other modules. State-of-the-art appoaches are used for other modules.
similarity is computed in basically the same Distributional similarity is computed in basically the same framework: framework: 1. 1. A context is extracted A context is extracted for each of two words, for each of two words, 2. 2. A vector is made A vector is made in which an element is a value or a weight, in which an element is a value or a weight, 3. 3. Two vectors are compared Two vectors are compared to measure similarity. to measure similarity.
SUBJ A boy's friend … The boy cried … … … corpus: feature vector for boy: ... ... Features are collection of syntactically-dependent words Features are collection of syntactically-dependent words with their syntactic roles. with their syntactic roles. Compound words are identified. Compound words are identified. Pointwise mutual information used for feature value. Pointwise mutual information used for feature value. Features are filtered out if threshold < α Features are filtered out if threshold < α
Kurohashi (2009) reported that Jaccard- Shibata and Kurohashi (2009) reported that Jaccard- Simpson attains better (in Japanese) than Simpson, Simpson attains better (in Japanese) than Simpson, Cosine, Lin98, and Lin02. Cosine, Lin98, and Lin02. We follow their findings and use Jaccard-Simpson. We follow their findings and use Jaccard-Simpson. sim Jaccard = ∣V1∩V2∣ ∣V1∪V2∣ sim Simpson = ∣V1∩V2∣ min∣V1∣,∣V2∣ sim JaccardSimpson = sim Jaccard sim Simpson 2 Shibata and Kurohashi. Distributional similarity calculation using very large scale Web corpus. ANLP Annual Meeting, pp.705-708, 2009.
(friend A feature (friend MOD MOD ) is reinforced according to how ) is reinforced according to how much synonyms of “ much synonyms of “boy boy” has the feature. ” has the feature. All features in all words are weighted, and values are All features in all words are weighted, and values are normalized to 0-1 for each word. normalized to 0-1 for each word. Use thesaurus to get synonyms. Use thesaurus to get synonyms. friend MOD feature for “boy”:
Problem Zhitomirsky-Geffet and Zhitomirsky-Geffet and Dagan (2009) picks up Dagan (2009) picks up only “associated” only “associated” features and reduced features and reduced other features. other features. high low Color: degree of value; After reduction: Original: word 1 word 2 word 1 word 2 Zhitomirsky-Geffet and Dagan, Bootstrapping Feature Vector Quality. Computational Linguistics, Vol.35, No.3, pp.435-461 2009.
: Problem (continued) However, it measures However, it measures well only in very similar well only in very similar words with many words with many associated features. associated features. In case two words are In case two words are middle- or low-similar middle- or low-similar (right figure), little (right figure), little information is provided. information is provided. high low Color: degree of value; After reduction: Original: word 1 word 2 word 1 word 2
: Our Idea We propose to use We propose to use features where features where the the difference of the values difference of the values is less than β. is less than β. Final similarity is Final similarity is computed by Jaccard- computed by Jaccard- Simposon with the Simposon with the reduced features. reduced features. high low Color: degree of value; After reduction: Original: word 1 word 2 word 1 word 2
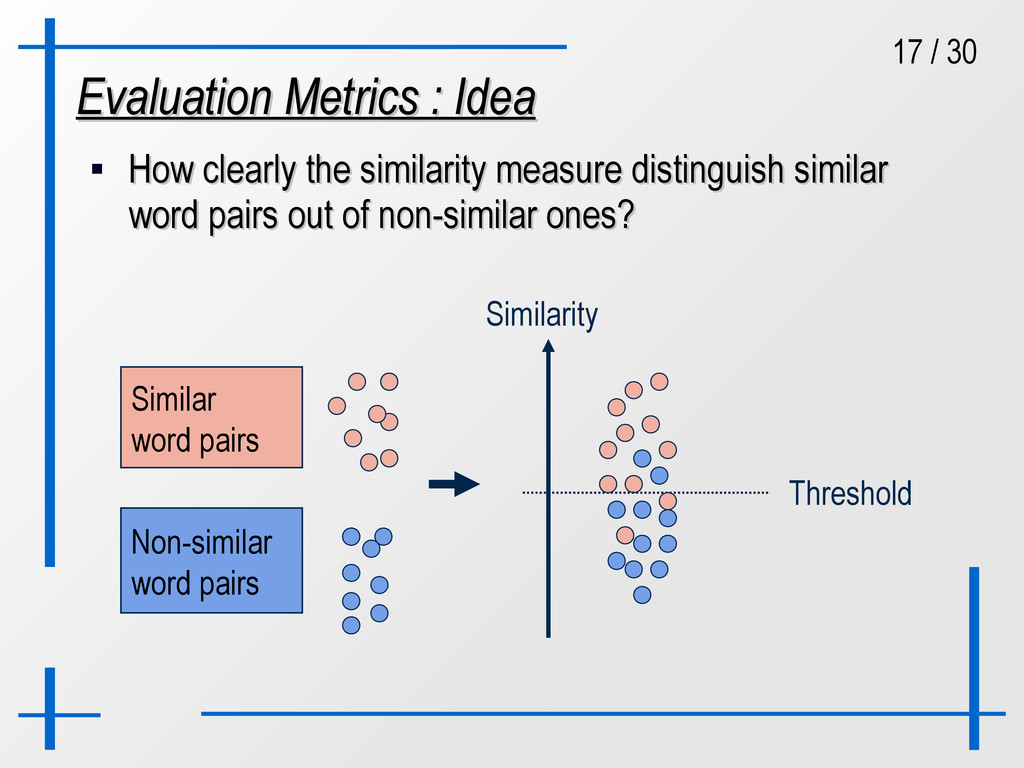
Idea How clearly the similarity measure distinguish similar How clearly the similarity measure distinguish similar word pairs out of non-similar ones? word pairs out of non-similar ones? Similar word pairs Non-similar word pairs Threshold Similarity
continued However, it is easy task to distinguish similar and non- However, it is easy task to distinguish similar and non- similar, that makes it difficult who wins. similar, that makes it difficult who wins. Therefore, we define a more difficult task that Therefore, we define a more difficult task that distinguishes different similarity level. distinguishes different similarity level. Similarity level is defined by thesaurus. Similarity level is defined by thesaurus. (root) (example) Target : Asia Level 3 : Europe Level 2 : Brazil Level 1 : my country Level 0 : system
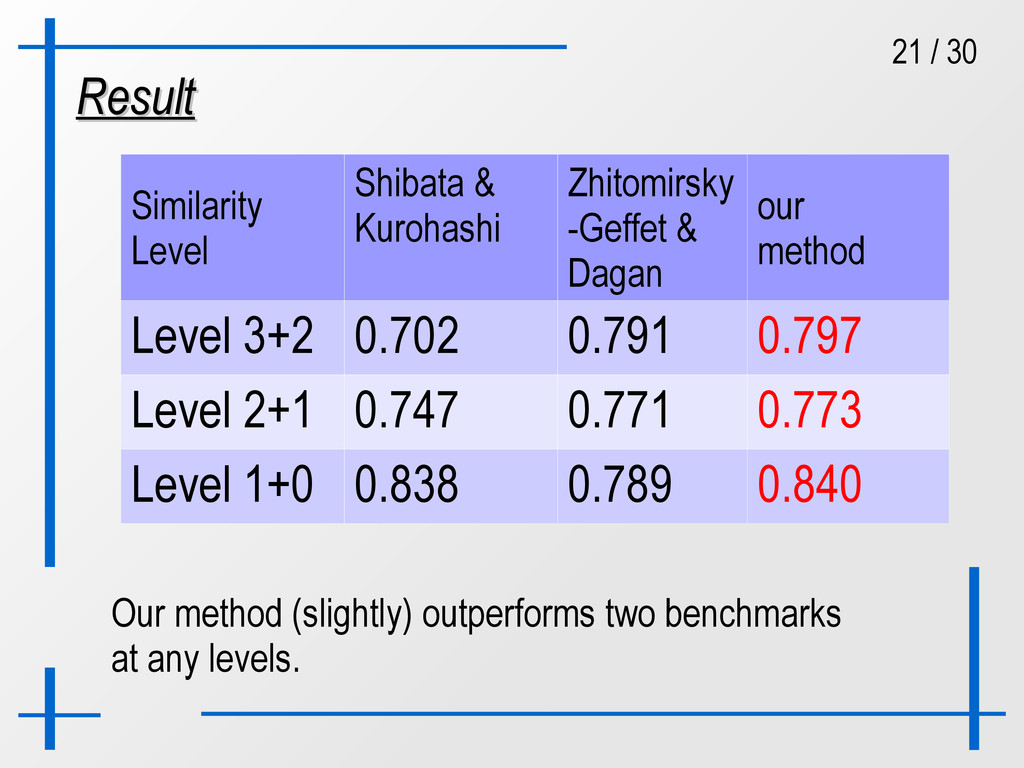
benchmarks: Compare with two benchmarks: Shibata and Kurohashi (2009) Shibata and Kurohashi (2009) Simpson-Jaccard without feature reduction. Simpson-Jaccard without feature reduction. Zhitomirsky-Geffet and Dagan (2009) Zhitomirsky-Geffet and Dagan (2009) reinforce associated features. reinforce associated features. Corpus : the Nikkei newspaper corpus, 14 years. Corpus : the Nikkei newspaper corpus, 14 years. Thesaurus : Bunrui Goi Hyo. Thesaurus : Bunrui Goi Hyo. Number of target words : 75,530. Number of target words : 75,530. Evaluation set : 800 pairs in each Level. Evaluation set : 800 pairs in each Level.
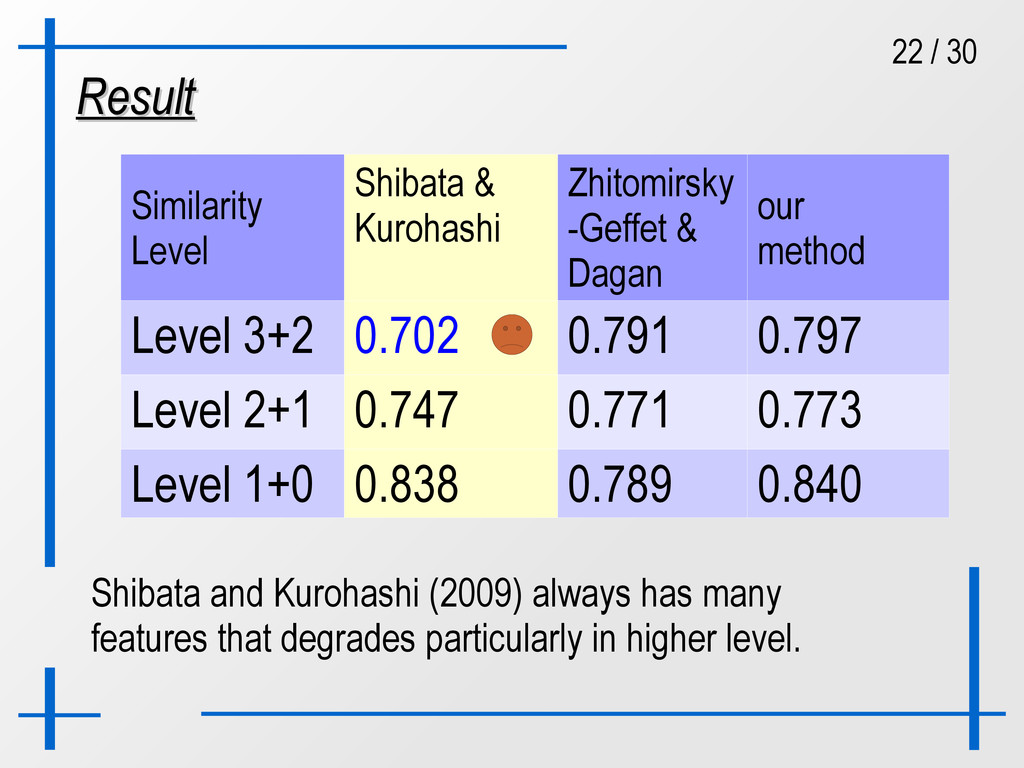
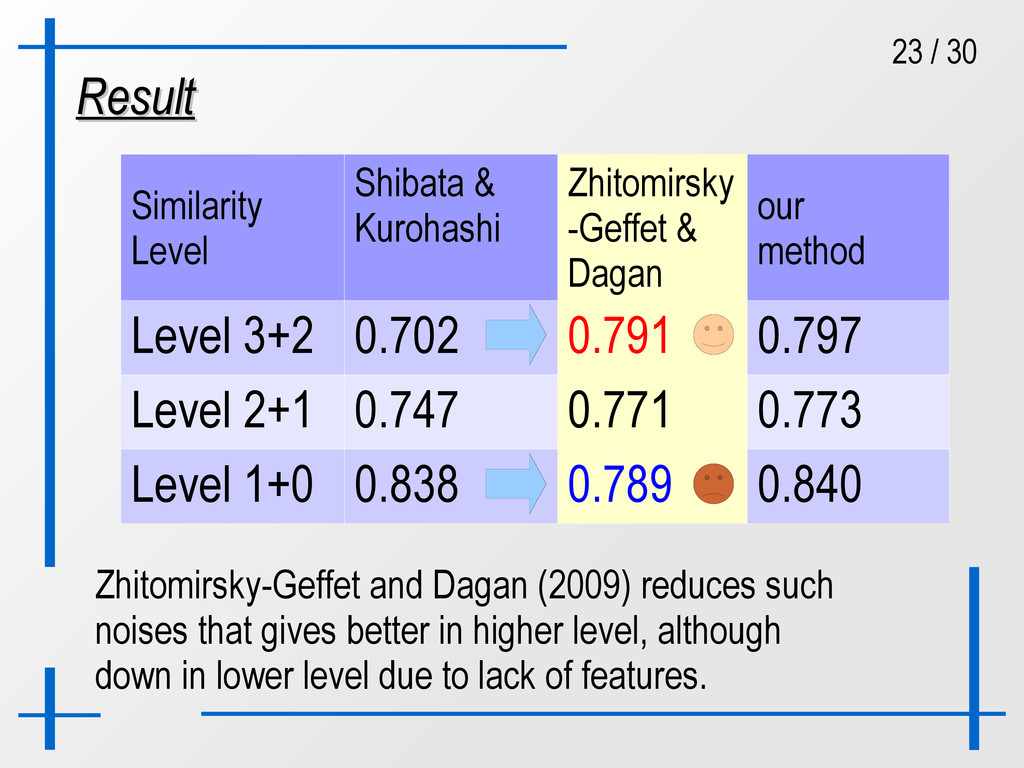
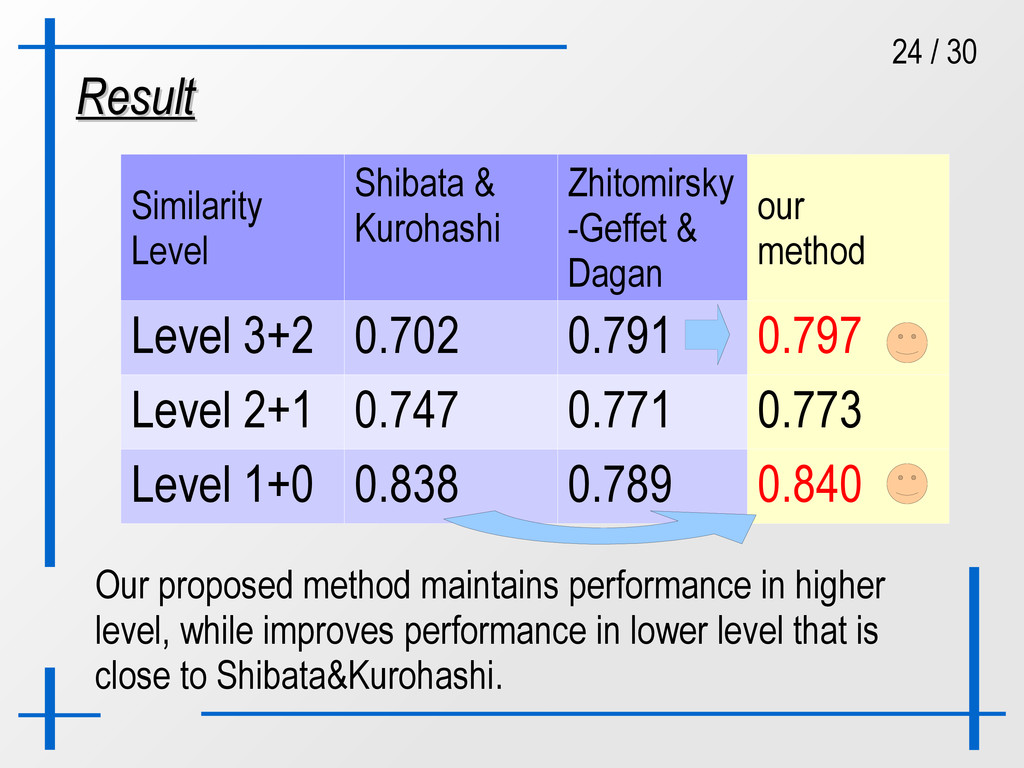
Zhitomirsky -Geffet & Dagan our method Level 3+2 0.702 0.791 0.797 Level 2+1 0.747 0.771 0.773 Level 1+0 0.838 0.789 0.840 Zhitomirsky-Geffet and Dagan (2009) reduces such noises that gives better in higher level, although down in lower level due to lack of features.
Analysis Major errors are NOT due to lack of features (below). Major errors are NOT due to lack of features (below). Hence, key features are reduced and/or noisy features Hence, key features are reduced and/or noisy features are remained in the reduction. are remained in the reduction. #errors < 20 fea. Level 3+2 (high) 125 32 (26%) (low) 220 60 (27%) Level 2+1 (high) 137 32 (23%) (low) 253 52 (21%) Level 1+0 (high) 149 4 (3%) (low) 100 3 (3%)
Reduction We may reduce 81% of features in level 3+2, 87% in We may reduce 81% of features in level 3+2, 87% in level 2+1, and 52% in level 1+0. level 2+1, and 52% in level 1+0. The precisions are given by observing performance The precisions are given by observing performance changes. changes. Not surprising since Hagiwara et al. (2006) reports Not surprising since Hagiwara et al. (2006) reports similar statistics (90%). similar statistics (90%). There is a lot to be reduced further. There is a lot to be reduced further. Hagiwara et al. Selection of Contextual Information for Automatic Synonym Acquisition. Proc. of Coling-ACL, pp.353-360 (2006)
distributional similarity is New method for lexical distributional similarity is proposed. proposed. Not only Not only associated associated features but features but even even unassociated unassociated features can improve lexical distributional similarity. features can improve lexical distributional similarity. Experimental results shows (slightly) better performance Experimental results shows (slightly) better performance in all levels of similarity. in all levels of similarity.
words: Again, two same words: たばこ たばこ (tobacco) (tobacco) タバコ タバコ (tobacco) (tobacco) The similarity is The similarity is still far from 1.0 still far from 1.0. .
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}