Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
[Journal Club]Label-efficient semantic segmenta...
Search
Sponsored
·
Ship Features Fearlessly
Turn features on and off without deploys. Used by thousands of Ruby developers.
→
Semantic Machine Intelligence Lab., Keio Univ.
PRO
December 15, 2022
Technology
440
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
[Journal Club]Label-efficient semantic segmentation with diffusion models
Semantic Machine Intelligence Lab., Keio Univ.
PRO
December 15, 2022
More Decks by Semantic Machine Intelligence Lab., Keio Univ.
See All by Semantic Machine Intelligence Lab., Keio Univ.
[Journal club] Predict Before You Explore: Predictive Planning with Specialized Memory for Embodied Question Answering
keio_smilab
PRO
0
81
[Journal club] PHyCLIP: 𝒍𝟏-Product of Hyperbolic Factors Unifies Hierarchy and Compositionality in Vision-Language Representation Learning
keio_smilab
PRO
0
86
[Journal club] ReMEmbR: Building and Reasoning Over Long-Horizon Spatio-Temporal Memory for Robot Navigation
keio_smilab
PRO
0
110
[Journal club] ReLaGS: Relational Language Gaussian Splatting
keio_smilab
PRO
0
120
[Journal club] Flow as the Cross-Domain Manipulation Interface
keio_smilab
PRO
0
98
Mobi-𝜋: Mobilizing Your Robot Learning Policy
keio_smilab
PRO
0
160
A Gentle Introduction to Transformers
keio_smilab
PRO
16
7k
FlowAR: Scale-wise Autoregressive Image Generation Meets Flow Matching
keio_smilab
PRO
0
60
[Journal club] VLA-Adapter: An Effective Paradigm for Tiny-Scale Vision-Language-Action Model
keio_smilab
PRO
1
150
Other Decks in Technology
See All in Technology
Playwright × AI Agent でE2Eテストはどう変わるか AI駆動テストの可能性と実用検証の結果
taiga7543
2
790
データエンジニアリングとドメイン駆動設計
masuda220
PRO
14
2.5k
Amplify Gen2でbackend.tsにCDKを定義する/しない事によるCDKの挙動の違いとユースケース
smt7174
1
490
Devsumi 2026 Summer 人もAIも使える共通基盤を事業の加速装置にする~デザインシステム運用に学ぶ組織レバレッジ~ 渡辺 凌央
legalontechnologies
PRO
1
280
Jitera Company Deck
jitera
0
270
AmplifyHostingConstructからSSRフレームワークのためのホスティング設計を考察する/amplify-hosting-construct
fossamagna
1
300
AIとハーネスで育てるトランスコンパイラ / 20260722 Yasushi Katayama
shift_evolve
PRO
3
780
”AIを使う” から ”AIに任せる” へ ─ 開発プロセスを再設計してAIを組織標準にするまで
cyberagentdevelopers
PRO
1
140
“それは自分の仕事じゃない"を 越えて行け
yuukiyo
1
520
Vポイント分析基盤におけるデータモデリング20年史
taromatsui_cccmkhd
4
720
StepFunctionsとGraphRAGを活用した暗黙知活用のためのRAG基盤
yakumo
0
120
第67回コンピュータビジョン勉強会CVPR2026読会前編
tsukamotokenji
0
160
Featured
See All Featured
Bioeconomy Workshop: Dr. Julius Ecuru, Opportunities for a Bioeconomy in West Africa
akademiya2063
PRO
1
180
How to Align SEO within the Product Triangle To Get Buy-In & Support - #RIMC
aleyda
2
1.7k
The browser strikes back
jonoalderson
0
1.4k
Into the Great Unknown - MozCon
thekraken
41
2.6k
The Hidden Cost of Media on the Web [PixelPalooza 2025]
tammyeverts
2
380
Game over? The fight for quality and originality in the time of robots
wayneb77
1
230
brightonSEO & MeasureFest 2025 - Christian Goodrich - Winning strategies for Black Friday CRO & PPC
cargoodrich
3
750
What's in a price? How to price your products and services
michaelherold
247
13k
How to make the Groovebox
asonas
2
2.3k
Lightning talk: Run Django tests with GitHub Actions
sabderemane
0
220
Leo the Paperboy
mayatellez
8
1.9k
DevOps and Value Stream Thinking: Enabling flow, efficiency and business value
helenjbeal
1
260
Transcript
LABEL-EFFICIENT SEMANTIC SEGMENTATION WITH DIFFUSION MODELS Dmitry Baranchuk, Ivan Rubachev,
Andrey Voynov, Valentin Khrulkov, Artem Babenko Yandex Research, ICLR2022 慶應義塾大学 杉浦孔明研究室 飯岡雄偉 Baranchuk, D., Rubachev, I., Voynov, A., Khrulkov, V., & Babenko, A. “ Label-efficient semantic segmentation with diffusion models.” ICLR2022
概要:拡散モデルをsemantic segmentationに応用 • 拡散モデルの顕著な発展 – Semantic segmentationタスクにも応用できるのでは? • 拡散モデルが有効な表現学習器となりうるのか検証 •
多様な条件での実験により効率の良い特徴量抽出を試みる – 特定のドメインにおいてSoTAを達成 • 複雑なドメインについては将来研究 2
背景:拡散モデルの概要 • Forward Step(拡散過程) – 入力画像にガウシアンノイズを徐々に加えていく – マルコフ性を持つ • ひとつ前の時刻のみによって出力が決定する
– ここでは学習は行われない • Reverse Step(逆拡散過程) – ノイズを取り除いて,元画像を復元していく • マルコフ連鎖に基づく – この過程で学習していく 3
背景:拡散モデルの概要 4 • Forward Step(拡散過程) • 計算過程・学習方法は,同研究室の過去の輪講資料を参考 – https://speakerdeck.com/keio_smilab/journal-club-denoising-diffusion-probabilistic-models 正規分布によって
𝑥𝑡 が決定 𝛽𝑡 :ノイズの強さ(0~1) 任意の𝑥𝑡 を閉形式で表現 ⇒計算の簡略化
背景:拡散モデルの概要 5 • Reverse Step(逆拡散過程) – 共分散行列は固定のスカラー値でもよいが,学習させるとより良い性能 となることが報告されている[Nichol+, ICML21] •
計算過程・学習方法は,同研究室の過去の輪講資料を参考 – https://speakerdeck.com/keio_smilab/journal-club-denoising-diffusion-probabilistic-models
背景:拡散モデルのvision taskへの応用例 • Super resolution[Saharia+, 2021] 6 • Inpainting[Yang+, ICLR21]
• Semantic editing[Meng+, ICLR22]
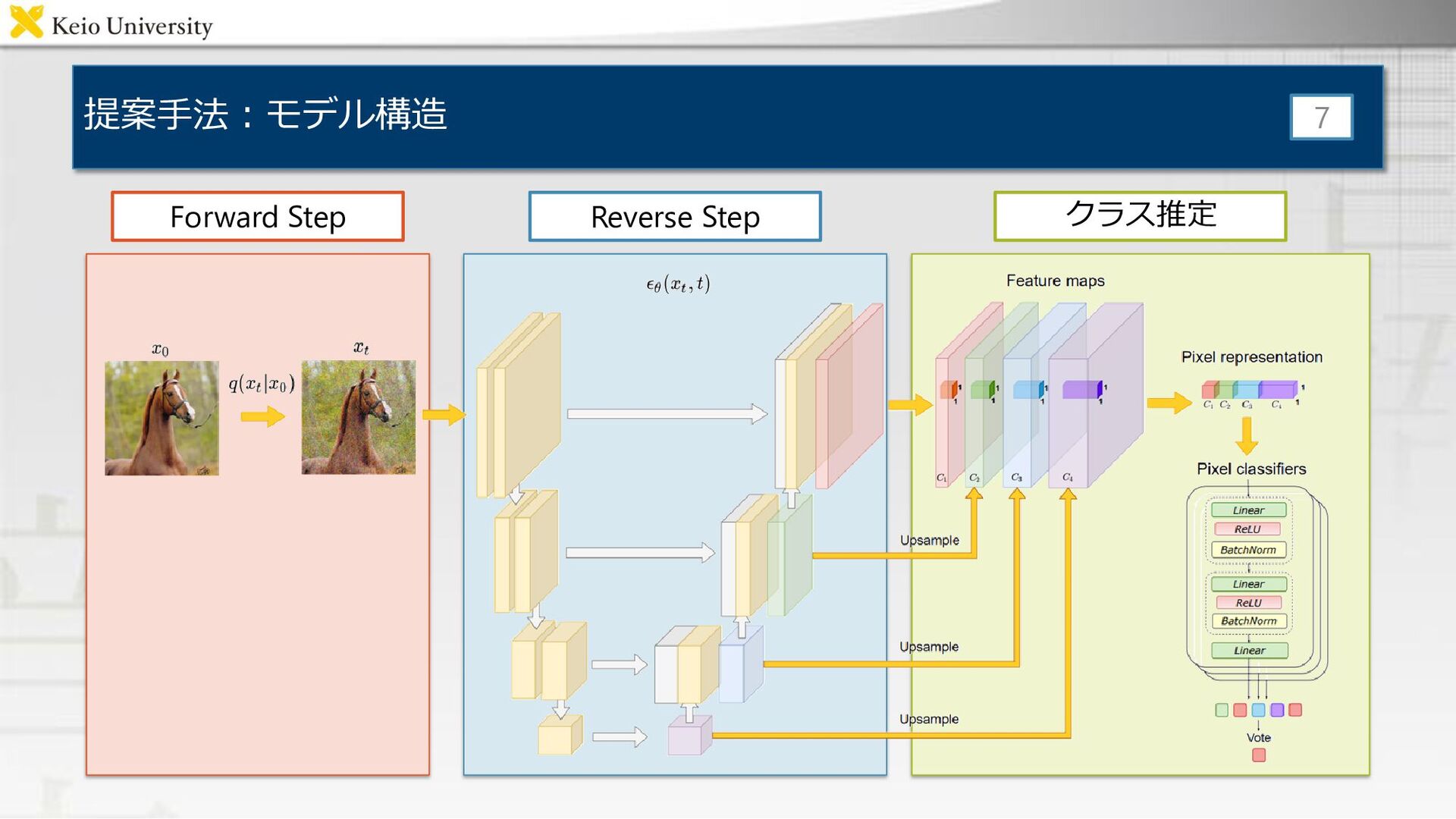
提案手法:モデル構造 7 Forward Step Reverse Step クラス推定
提案手法:U-Net[Ronnebeger+, MICCAI15]の構造 • Reverse Step – Denoiseされた画像ではなく,画像に加えられてい るノイズを推測 • DDPM[Ho+,
NeurIPS20]で性能向上を報告 – 中間層の出力にsegmentに関する情報が含まれて いると仮定 – 各層の深さ・time stepごとに特徴量の抽出を行う • どの特徴量を用いると効率が良いかを比較 8
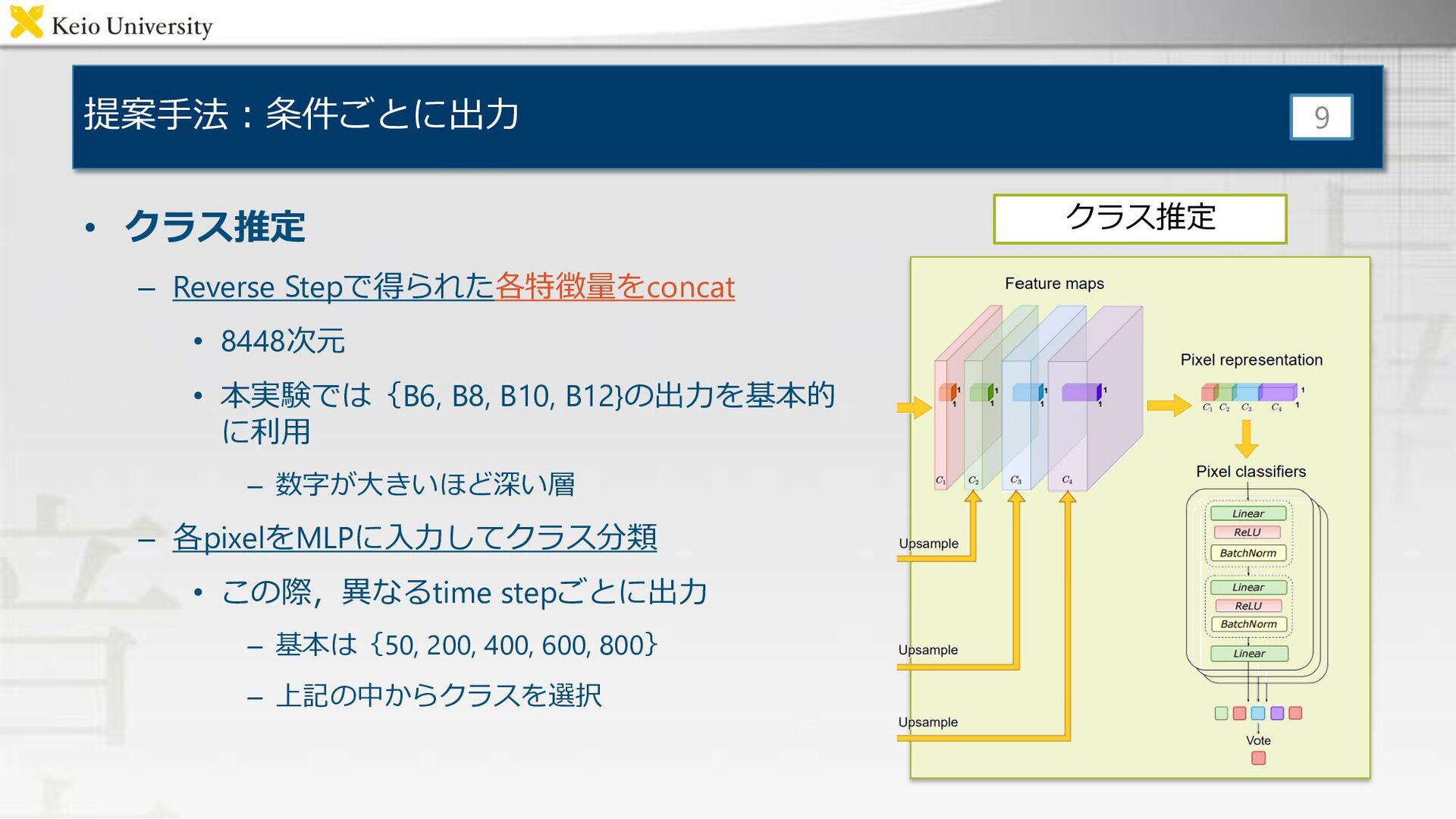
提案手法:条件ごとに出力 • クラス推定 – Reverse Stepで得られた各特徴量をconcat • 8448次元 • 本実験では{B6,
B8, B10, B12}の出力を基本的 に利用 – 数字が大きいほど深い層 – 各pixelをMLPに入力してクラス分類 • この際,異なるtime stepごとに出力 – 基本は{50, 200, 400, 600, 800} – 上記の中からクラスを選択 9
実験設定:各ドメインごとに学習 • 学習方法 – ラベルなし画像でpretrain -> 再構成 – ラベルあり画像で転移学習 •
データセット – LSUN[Yu+, 2015], FFHQ[Karras+, CVPR19] • 学習時間 – 記述なし • 256×256の50枚画像の学習に210GBのRAM使用 10 https://github.com/NVlabs/ffhq-dataset
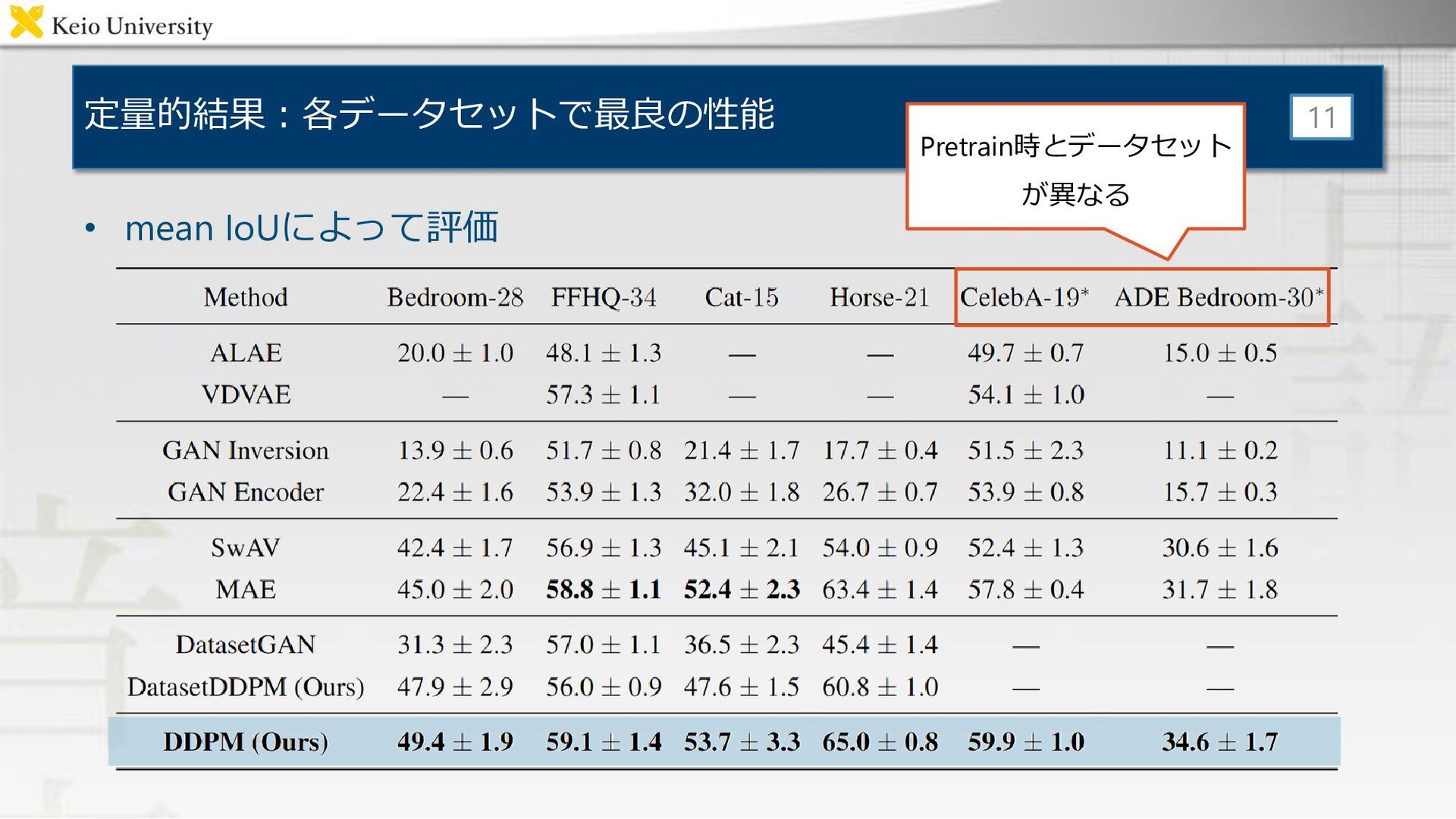
定量的結果:各データセットで最良の性能 • mean IoUによって評価 11 Pretrain時とデータセット が異なる
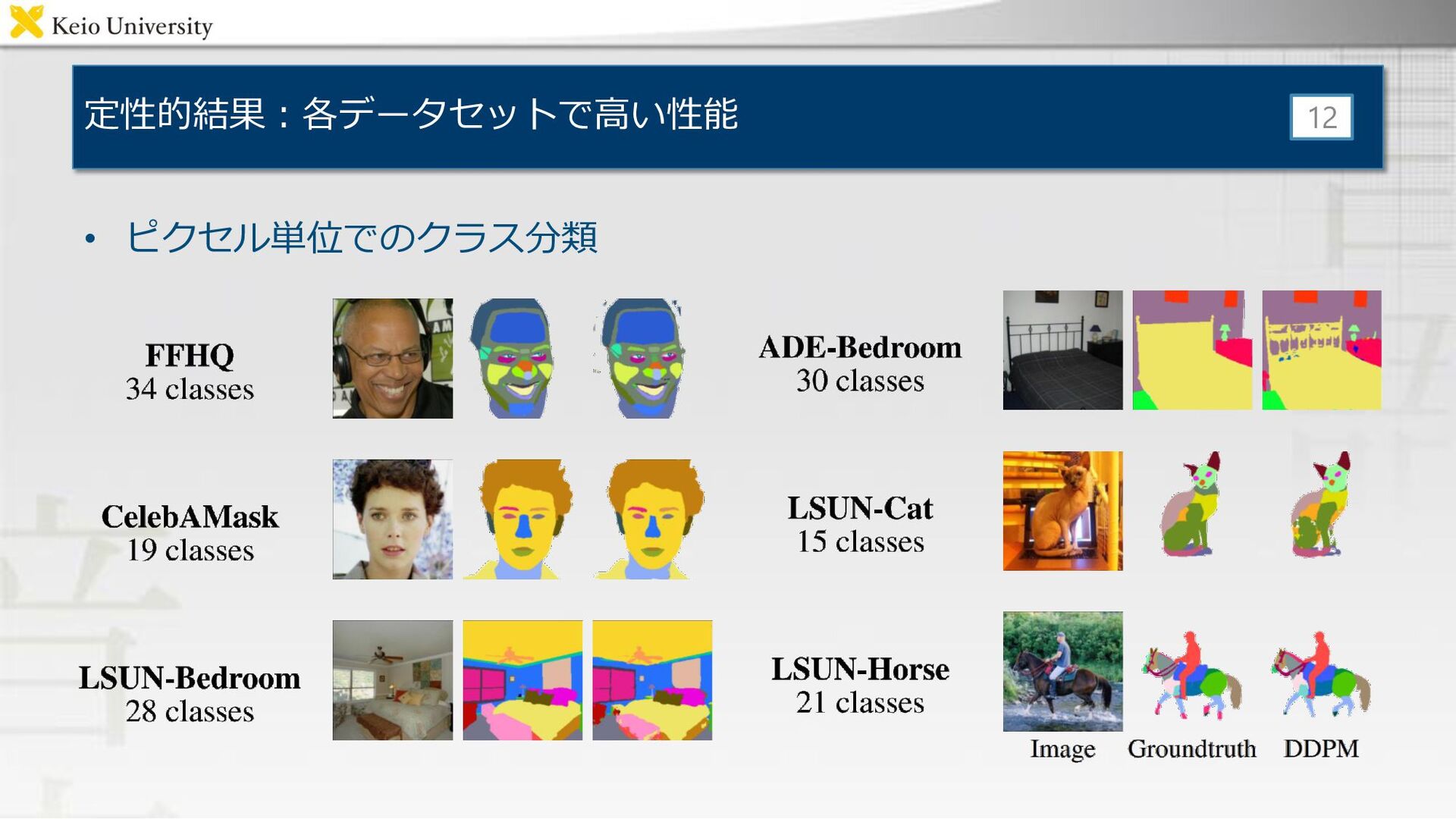
定性的結果:各データセットで高い性能 12 • ピクセル単位でのクラス分類
まとめ:拡散モデルをsemantic segmentationに応用 • 拡散モデルの顕著な発展 – Semantic segmentationタスクにも応用できるのでは? • 拡散モデルが有効な表現学習器となりうるのか検証 •
多様な条件での実験により効率の良い特徴量抽出を試みる – 特定のドメインにおいてSoTAを達成 • 複雑なドメインについては将来研究 13
Appendix:各層の深さ・time stepごとの性能[定量] • 小さいtime step = Reverse Stepの後半での評価が高い • 真ん中に位置するBlockほど高性能
14
Appendix:各層の深さ・time stepごとの性能[定性] • 小さいtime step = Reverse Stepの後半での評価が高い • 真ん中に位置するBlockほど高性能
15
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![背景:拡散モデルの概要 5 • Reverse Step(逆拡散過程) – 共分散行列は固定のスカラー値でもよいが,学習させるとより良い性能 となることが報告されている[Nichol+, ICML21] •](https://files.speakerdeck.com/presentations/91d9aa8a1d7c466daabbd4cd9e0f9b68/slide_4.jpg){kind=link}
![背景:拡散モデルのvision taskへの応用例 • Super resolution[Saharia+, 2021] 6 • Inpainting[Yang+, ICLR21]](https://files.speakerdeck.com/presentations/91d9aa8a1d7c466daabbd4cd9e0f9b68/slide_5.jpg){kind=link}
{kind=link}
![提案手法:U-Net[Ronnebeger+, MICCAI15]の構造 • Reverse Step – Denoiseされた画像ではなく,画像に加えられてい るノイズを推測 • DDPM[Ho+,](https://files.speakerdeck.com/presentations/91d9aa8a1d7c466daabbd4cd9e0f9b68/slide_7.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Appendix:各層の深さ・time stepごとの性能[定量] • 小さいtime step = Reverse Stepの後半での評価が高い • 真ん中に位置するBlockほど高性能](https://files.speakerdeck.com/presentations/91d9aa8a1d7c466daabbd4cd9e0f9b68/slide_13.jpg){kind=link}
![Appendix:各層の深さ・time stepごとの性能[定性] • 小さいtime step = Reverse Stepの後半での評価が高い • 真ん中に位置するBlockほど高性能](https://files.speakerdeck.com/presentations/91d9aa8a1d7c466daabbd4cd9e0f9b68/slide_14.jpg){kind=link}