The goal of this talk is to deliver an introduction to Graphical Processing Units (GPUs) and their application to general purpose analytics. There is a great deal of excitement and hype around GPU computing, with good reason. The implications of GPU technology for machine and deep learning have already been enormous. But GPUs can do more than train neural networks - and there is a blossoming open source community to prove it. Aaron will discuss an application of GPU computing: the use of GPUs for performing super fast database operations on big data.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
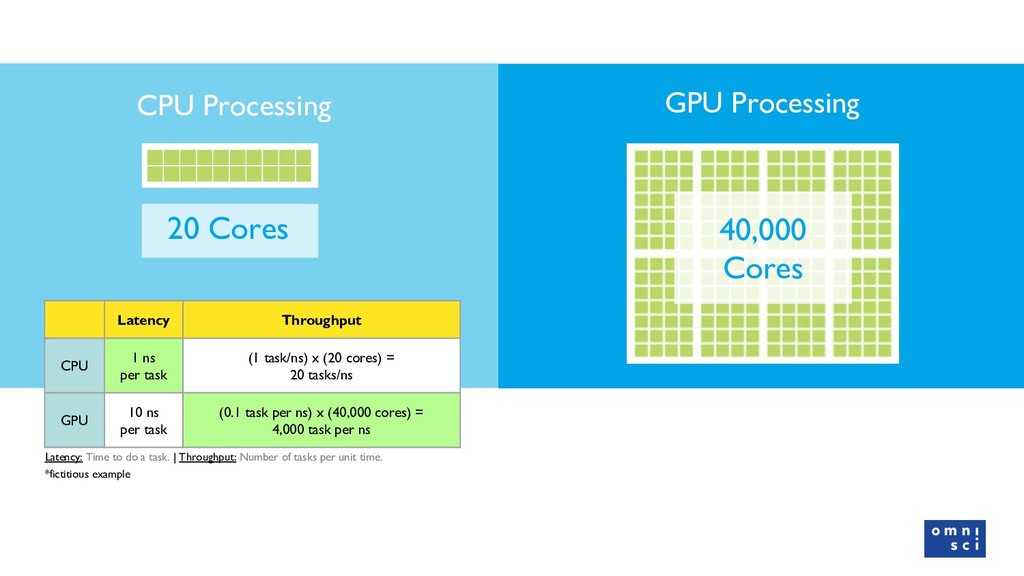{kind=link}
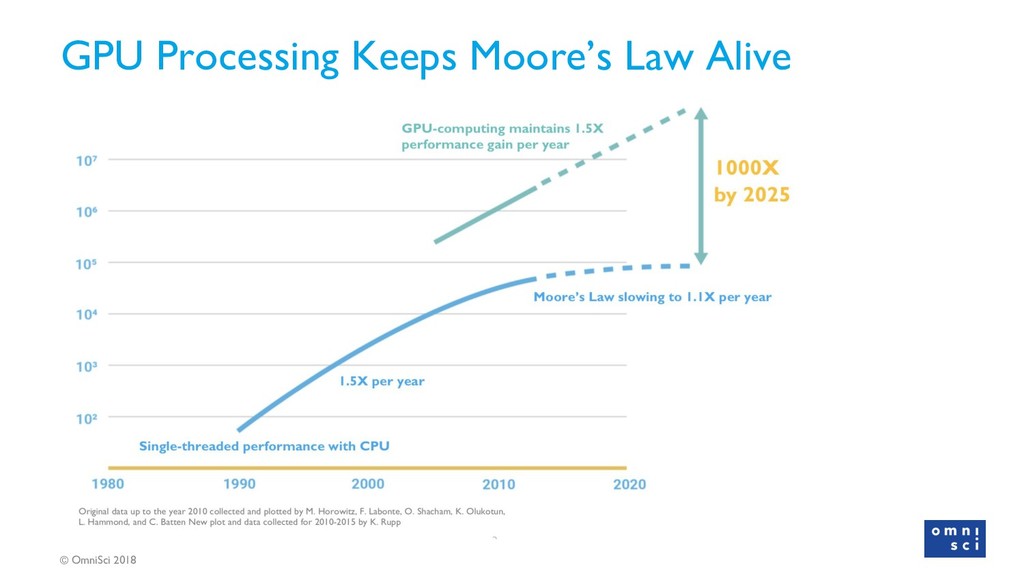{kind=link}
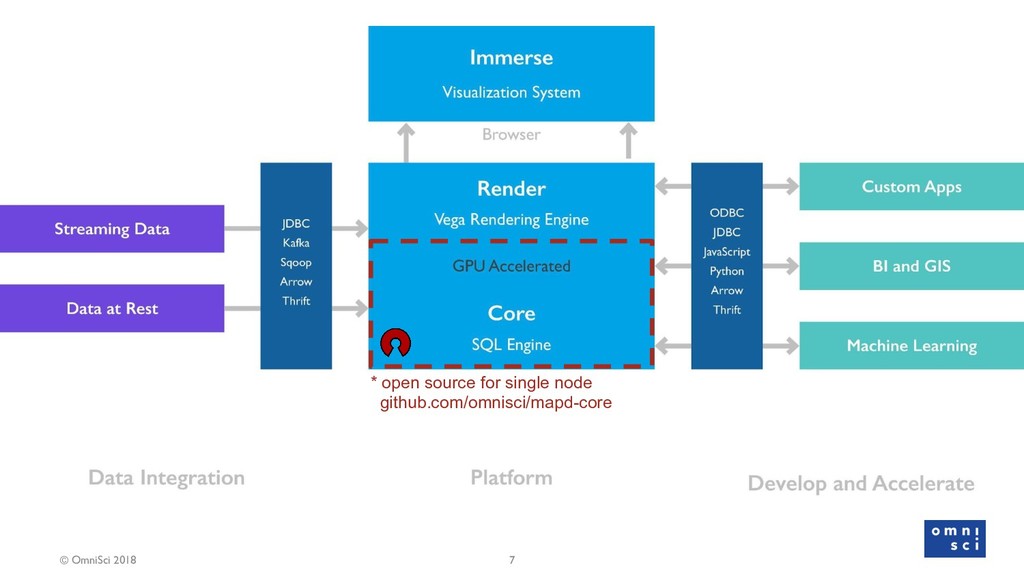{kind=link}
{kind=link}
{kind=link}
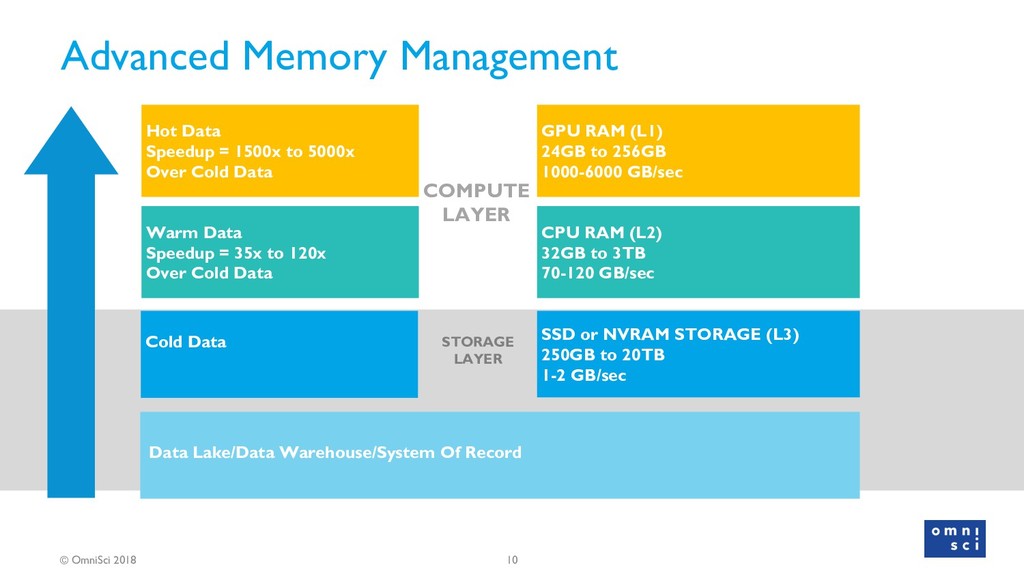{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}