Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Big Data Service, Cloud SQL 概要 / Big Data Servi...
Search
oracle4engineer
PRO
May 31, 2022
Technology
780
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Big Data Service, Cloud SQL 概要 / Big Data Service, Cloud SQL overview
oracle4engineer
PRO
May 31, 2022
More Decks by oracle4engineer
See All by oracle4engineer
Oracle Exadata Database Service on Cloud@Customer X11M (ExaDB-C@C) サービス概要
oracle4engineer
PRO
2
8.4k
Oracle Base Database Service 技術詳細
oracle4engineer
PRO
15
110k
Deep Data Security 機能解説
oracle4engineer
PRO
2
300
Oracle Cloud Infrastructure:2026年6月度サービス・アップデート
oracle4engineer
PRO
1
590
Oracle AI Databaseデータベース・サービスのメンテナンス(BaseDB/ExaDB-D/ExaDB-XS)
oracle4engineer
PRO
4
1.9k
Oracle AI Database@Google Cloud:サービス概要のご紹介
oracle4engineer
PRO
6
1.6k
Oracle AI Database@Azure:サービス概要のご紹介
oracle4engineer
PRO
6
2.1k
Oracle AI Database@AWS:サービス概要のご紹介
oracle4engineer
PRO
4
3.2k
CrossplaneによるCloud Native Control Plane
oracle4engineer
PRO
0
130
Other Decks in Technology
See All in Technology
AIDLC_ヤフーショッピングの取り組み
lycorptech_jp
PRO
0
600
CSに"SLO"は要らない、経営層に"99.9%"は伝わらない - SREを全社に"翻訳"する3原則
cscengineer
PRO
1
4.3k
キャリアの中で本を作る / Making a Book During Your Career
ak1210
0
130
ローカルLLMとLINE Botの組み合わせ その3 / LINE DC Generative AI Meetup #8
you
PRO
0
130
cccccc
moznion
0
1.9k
Zoom2Youtube.Claude
kawaguti
PRO
3
490
ゼロをイチにする仕事が終わったあと
smasato
0
330
実装だけじゃない! CCA-F取得エンジニアが教えるClaude Code開発プロセス活用術
diggymo
2
510
「最後に責任を取るのはチーム」— 人間のPRレビューを最小化してアップデートしたメンタルモデル
jnishime_dresscode
0
200
最近評価が難しくなった
maroon8021
0
300
知らん間に、回ってる
ming_ayami
0
390
美しいコードを書くためにF#を学んでみた話
yud0uhu
1
400
Featured
See All Featured
SEO for Brand Visibility & Recognition
aleyda
0
4.6k
Joys of Absence: A Defence of Solitary Play
codingconduct
1
410
Leading Effective Engineering Teams in the AI Era
addyosmani
9
2.1k
The #1 spot is gone: here's how to win anyway
tamaranovitovic
3
1.1k
It's Worth the Effort
3n
188
29k
Understanding Cognitive Biases in Performance Measurement
bluesmoon
32
3k
HTML-Aware ERB: The Path to Reactive Rendering @ RubyCon 2026, Rimini, Italy
marcoroth
2
320
Faster Mobile Websites
deanohume
310
32k
How to Talk to Developers About Accessibility
jct
2
300
Six Lessons from altMBA
skipperchong
29
4.3k
Documentation Writing (for coders)
carmenintech
77
5.4k
Dominate Local Search Results - an insider guide to GBP, reviews, and Local SEO
greggifford
PRO
0
210
Transcript
Oracle Cloud Infrastructure Big Data Service / Cloud SQL 製品技術概要
日本オラクル株式会社
Copyright © 2022, Oracle and/or its affiliates 1. Big Data
Serviceの概要 2. Oracle Distribution for Hadoop 3. Cloud SQL 4. BDSノード構成 アジェンダ 2022/5/31
Copyright © 2022, Oracle and/or its affiliates Big Data Service
概要
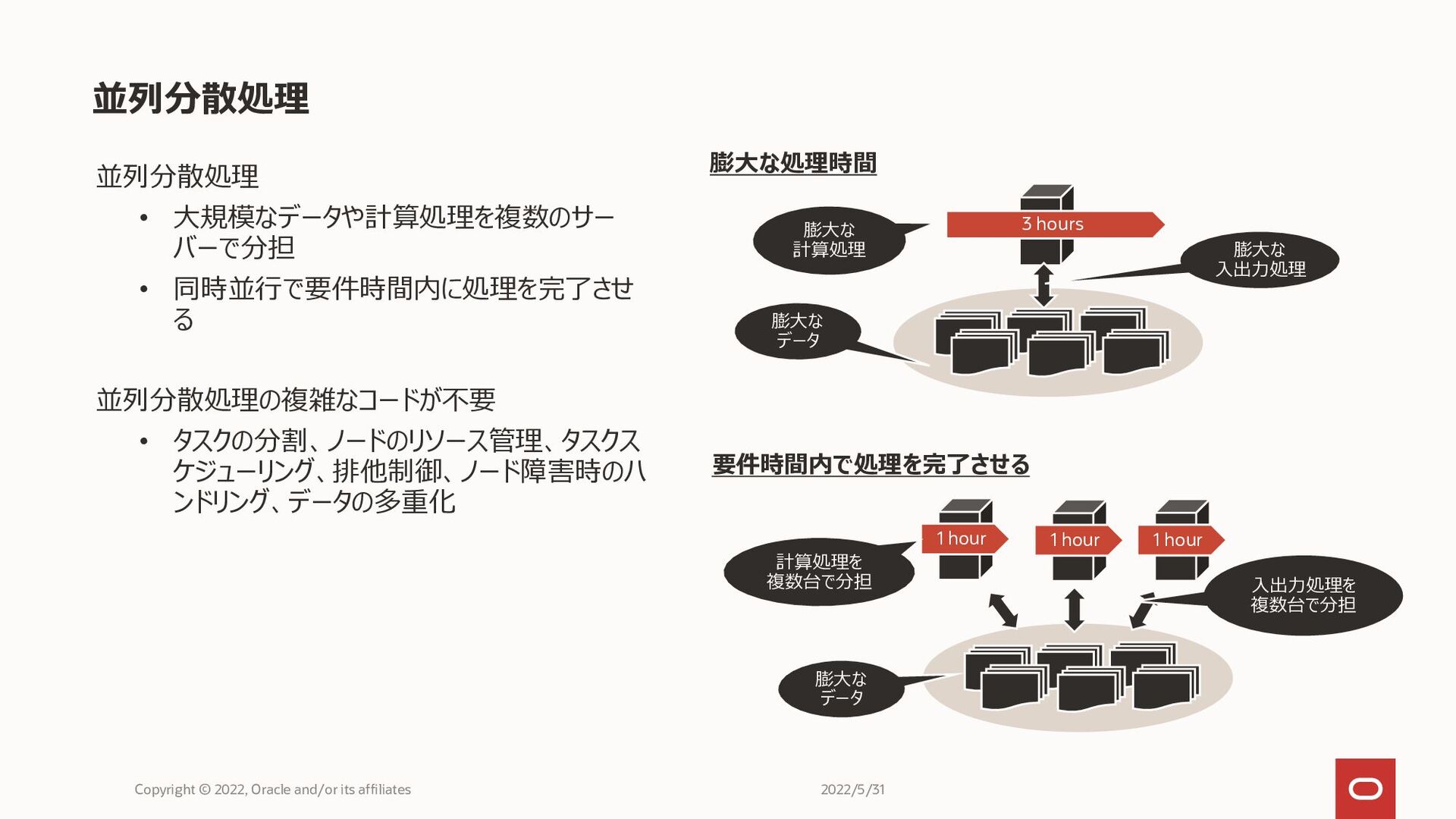
並列分散処理 Copyright © 2022, Oracle and/or its affiliates 膨大な データ
膨大な 入出力処理 膨大な 計算処理 1 hour 3 hours 1 hour 1 hour 膨大な データ 入出力処理を 複数台で分担 計算処理を 複数台で分担 膨大な処理時間 要件時間内で処理を完了させる 並列分散処理 • 大規模なデータや計算処理を複数のサー バーで分担 • 同時並行で要件時間内に処理を完了させ る 並列分散処理の複雑なコードが不要 • タスクの分割、ノードのリソース管理、タスクス ケジューリング、排他制御、ノード障害時のハ ンドリング、データの多重化 2022/5/31
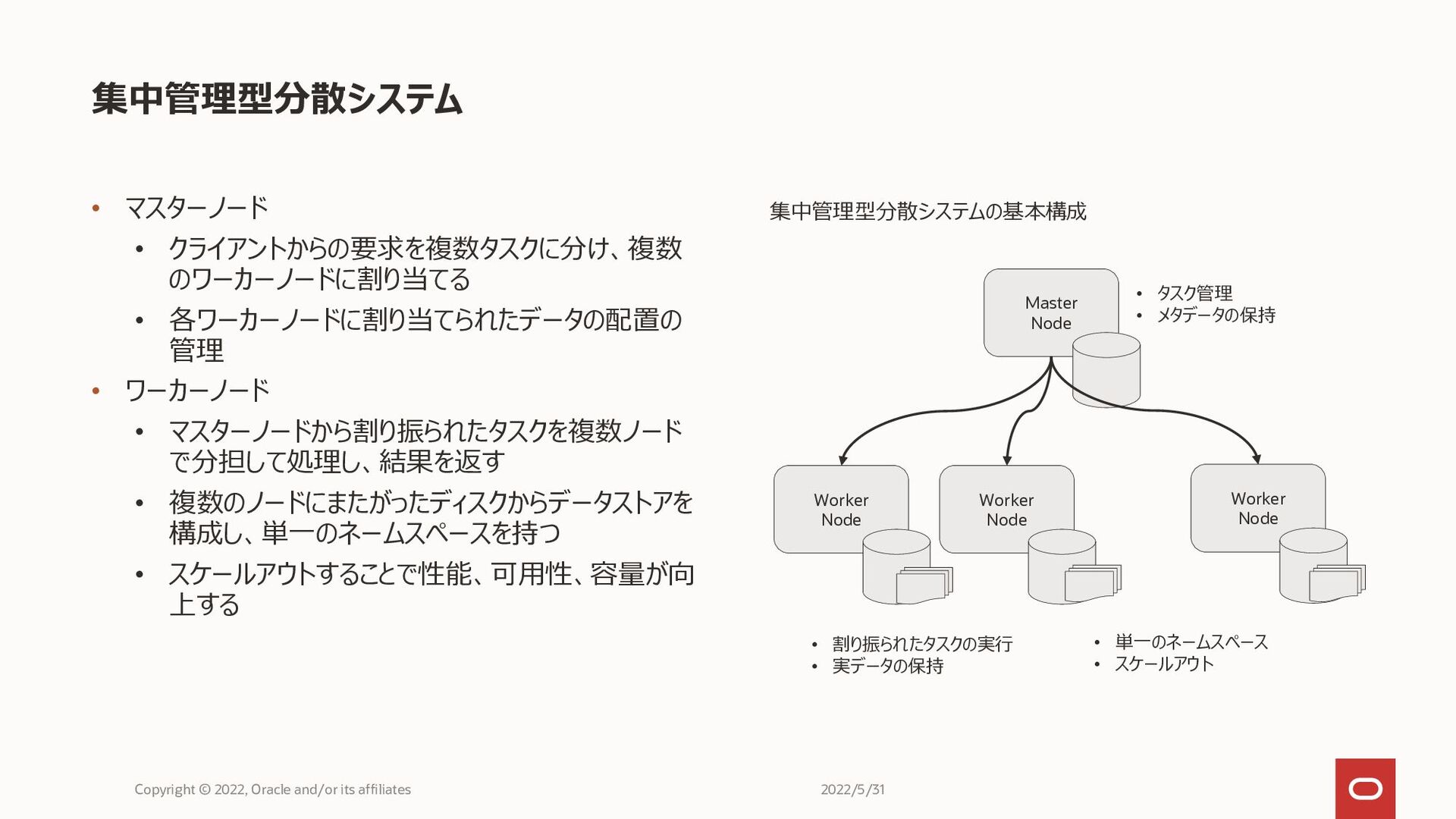
集中管理型分散システム Copyright © 2022, Oracle and/or its affiliates • マスターノード
• クライアントからの要求を複数タスクに分け、複数 のワーカーノードに割り当てる • 各ワーカーノードに割り当てられたデータの配置の 管理 • ワーカーノード • マスターノードから割り振られたタスクを複数ノード で分担して処理し、結果を返す • 複数のノードにまたがったディスクからデータストアを 構成し、単一のネームスペースを持つ • スケールアウトすることで性能、可用性、容量が向 上する Master Node Worker Node Worker Node Worker Node • タスク管理 • メタデータの保持 • 割り振られたタスクの実行 • 実データの保持 • 単一のネームスペース • スケールアウト 集中管理型分散システムの基本構成 2022/5/31
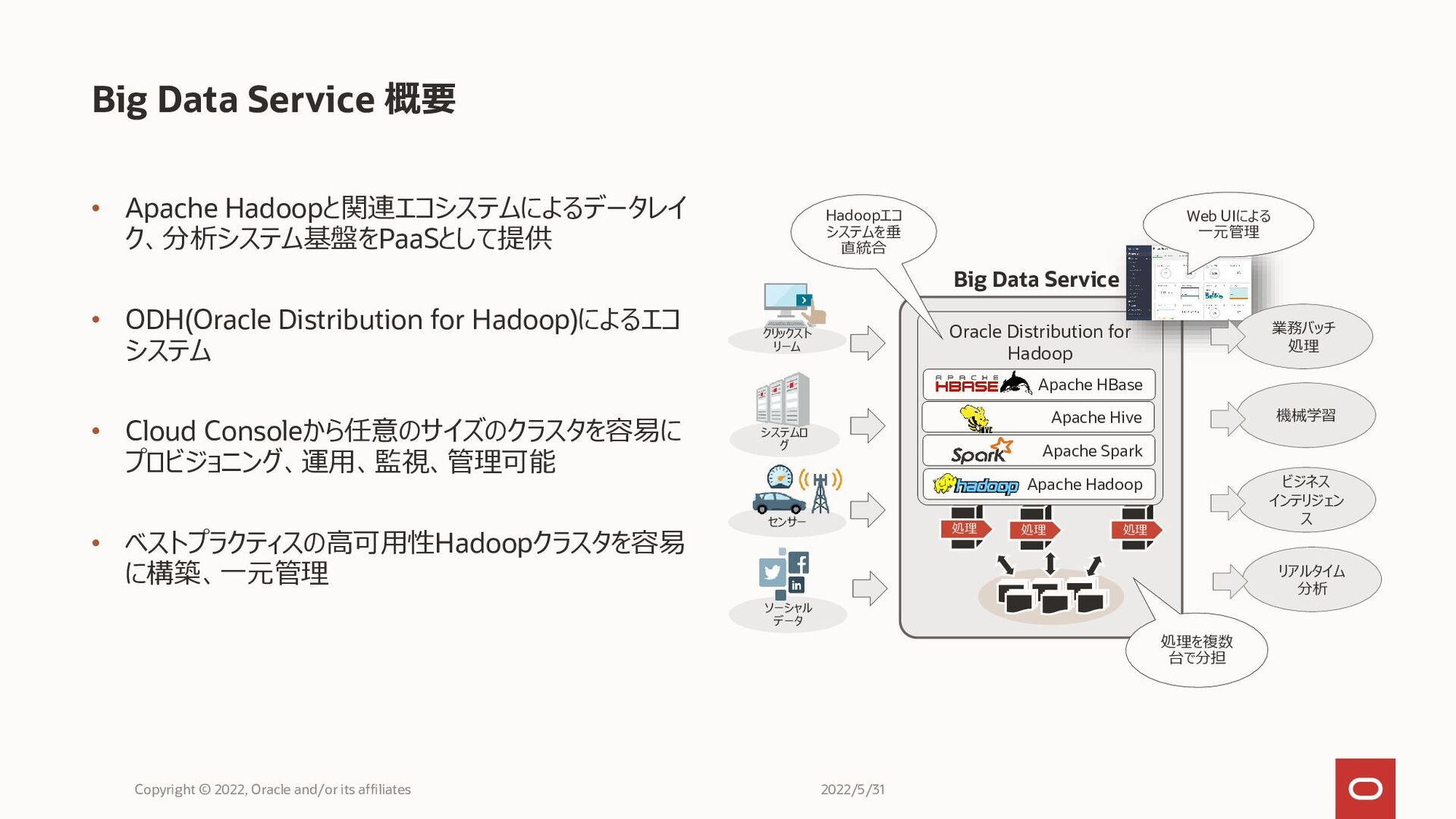
• Apache Hadoopと関連エコシステムによるデータレイ ク、分析システム基盤をPaaSとして提供 • ODH(Oracle Distribution for Hadoop)によるエコ システム
• Cloud Consoleから任意のサイズのクラスタを容易に プロビジョニング、運用、監視、管理可能 • ベストプラクティスの高可用性Hadoopクラスタを容易 に構築、一元管理 Big Data Service 概要 Copyright © 2022, Oracle and/or its affiliates ソーシャル データ クリックスト リーム システムロ グ センサー 処理を複数 台で分担 処理 処理 処理 Oracle Distribution for Hadoop Apache Hadoop Apache Spark Apache Hive Apache HBase Web UIによる 一元管理 Hadoopエコ システムを垂 直統合 Big Data Service 業務バッチ 処理 機械学習 ビジネス インテリジェン ス リアルタイム 分析 2022/5/31
Copyright © 2022, Oracle and/or its affiliates Oracle Distribution for
Hadoop(OHD)
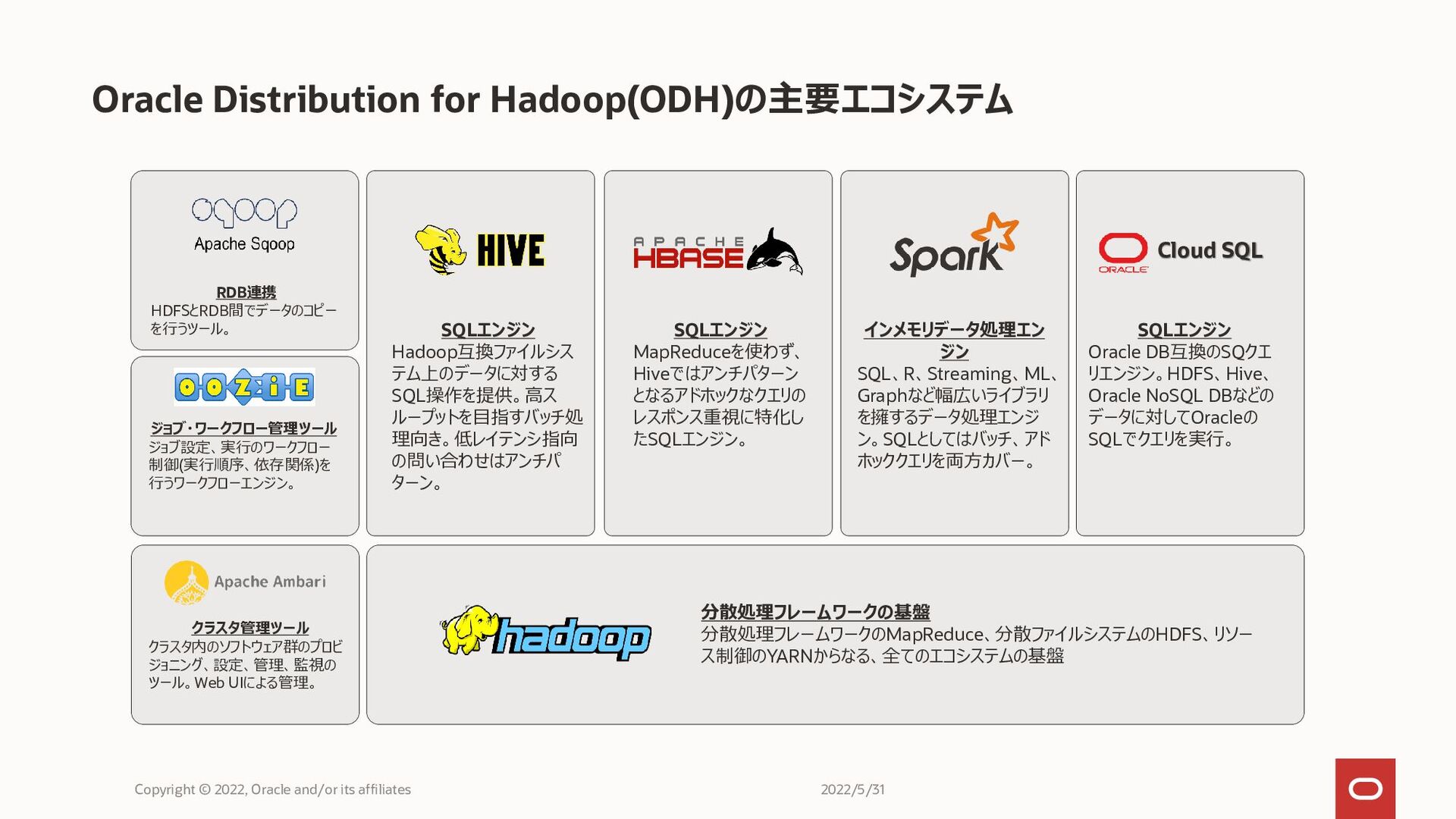
Oracle Distribution for Hadoop(ODH)の主要エコシステム Copyright © 2022, Oracle and/or its
affiliates 分散処理フレームワークの基盤 分散処理フレームワークのMapReduce、分散ファイルシステムのHDFS、リソー ス制御のYARNからなる、全てのエコシステムの基盤 インメモリデータ処理エン ジン SQL、R、Streaming、ML、 Graphなど幅広いライブラリ を擁するデータ処理エンジ ン。SQLとしてはバッチ、アド ホッククエリを両方カバー。 SQLエンジン Hadoop互換ファイルシス テム上のデータに対する SQL操作を提供。高ス ループットを目指すバッチ処 理向き。低レイテンシ指向 の問い合わせはアンチパ ターン。 SQLエンジン MapReduceを使わず、 Hiveではアンチパターン となるアドホックなクエリの レスポンス重視に特化し たSQLエンジン。 RDB連携 HDFSとRDB間でデータのコピー を行うツール。 ジョブ・ワークフロー管理ツール ジョブ設定、実行のワークフロー 制御(実行順序、依存関係)を 行うワークフローエンジン。 クラスタ管理ツール クラスタ内のソフトウェア群のプロビ ジョニング、設定、管理、監視の ツール。Web UIによる管理。 SQLエンジン Oracle DB互換のSQクエ リエンジン。HDFS、Hive、 Oracle NoSQL DBなどの データに対してOracleの SQLでクエリを実行。 Cloud SQL 2022/5/31
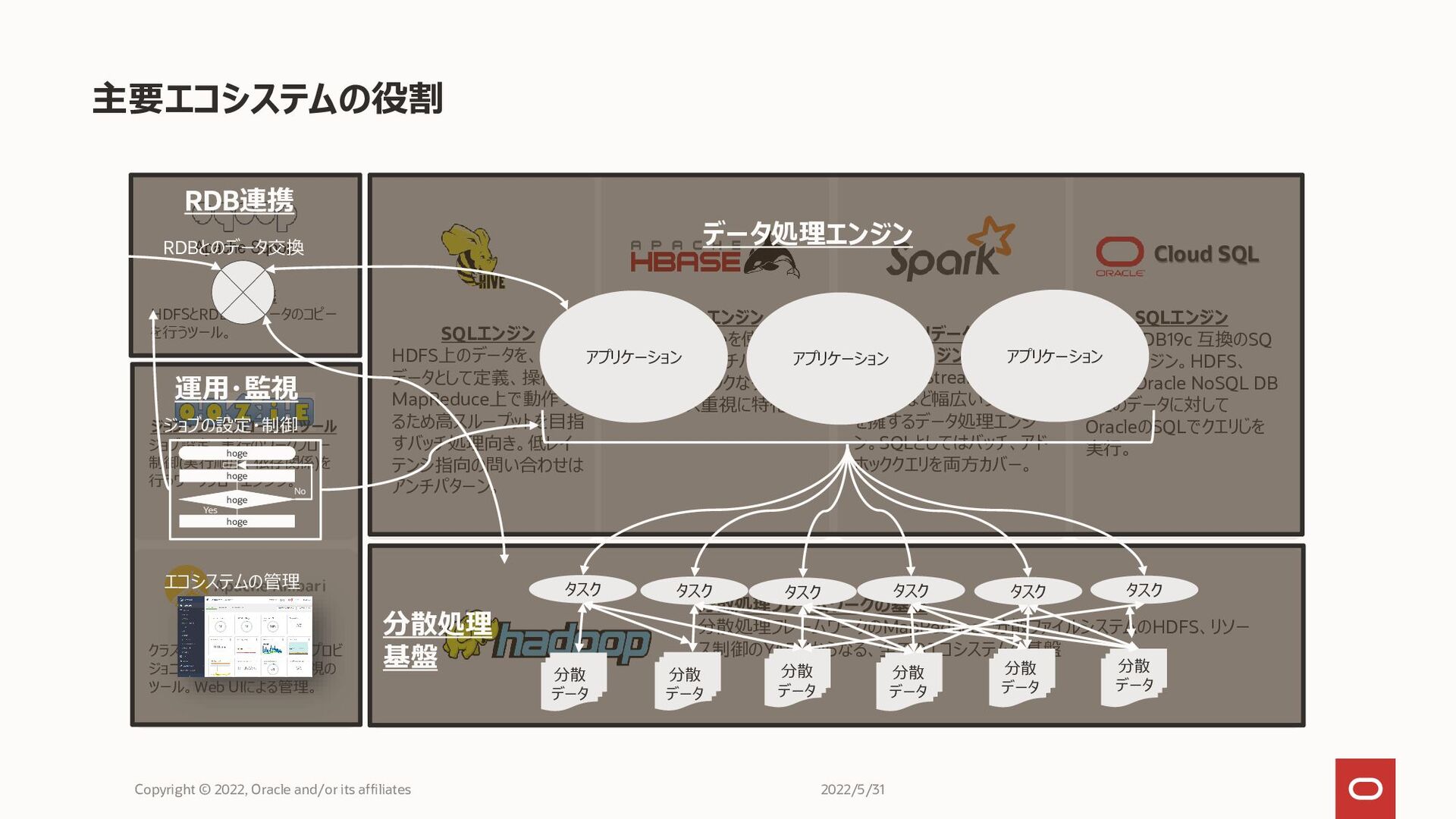
主要エコシステムの役割 Copyright © 2022, Oracle and/or its affiliates 分散処理フレームワークの基盤 分散処理フレームワークのMapReduce、分散ファイルシステムのHDFS、リソー
ス制御のYARNからなる、全てのエコシステムの基盤 インメモリデータ処理エン ジン SQL、R、Streaming、ML、 Graphなど幅広いライブラリ を擁するデータ処理エンジ ン。SQLとしてはバッチ、アド ホッククエリを両方カバー。 SQLエンジン HDFS上のデータを、定型 データとして定義、操作。 MapReduce上で動作す るため高スループットを目指 すバッチ処理向き。低レイ テンシ指向の問い合わせは アンチパターン。 SQLエンジン MapReduceを使わず、 Hiveではアンチパターン となるアドホックなクエリの レスポンス重視に特化。 RDB連携 HDFSとRDB間でデータのコピー を行うツール。 ジョブ・ワークフロー管理ツール ジョブ設定、実行のワークフロー 制御(実行順序、依存関係)を 行うワークフローエンジン。 クラスタ管理ツール クラスタ内のソフトウェア群のプロビ ジョニング、設定、管理、監視の ツール。Web UIによる管理。 SQLエンジン Oracle DB19c 互換のSQ クエリエンジン。HDFS、 Hive、Oracle NoSQL DB などのデータに対して OracleのSQLでクエリじを 実行。 Cloud SQL hoge hoge hoge hoge Yes No アプリケーション 分散処理 基盤 タスク タスク タスク タスク タスク タスク アプリケーション アプリケーション 分散 データ 分散 データ 分散 データ 分散 データ 分散 データ 分散 データ ジョブの設定・制御 エコシステムの管理 RDBとのデータ交換 データ処理エンジン 運用・監視 RDB連携 2022/5/31
MapReduce Apache Hadoop Copyright © 2022, Oracle and/or its affiliates
巨大なデータセットの蓄積およびデータ処理を複数の計算機に分散する 並列分散処理基盤 Hadoop Distributed File System(HDFS) • Hadoopエコシステム内のあらゆるデータ処理エンジンのデータストア • 単一のストレージサブシステムでは保持しきれない巨大なデータセット を安価に効率よく保持するファイルシステム MapReduce • 単一の計算機では時間のかかる処理を複数のノードで分担して処理 可能なデータ処理API(Java、C#、Pythonなど) • 複数ノードへのタスク分割、ノード間の排他制御などが抽象化された 分散処理プログラミングモデル • 高スループットを必要とするバッチ処理向き、OLTPには向かない Yet Another Resource Negotiator (YARN) • クラスタ内の計算リソース管理ツール • 計算リソースの死活監視、利用状況を管理し、アプリケーション (MapReduce)からのリソース要求を処理する HDFS YARN 大規模データ セットを複数ノー ドに分散して蓄 積 クラスタ内の計 算リソースを監 視、管理 複数ノードを意 識しないプログラ ミングモデル import java.io.IOException; import java.util.StringTokenizer; public class WordCount { public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable>{ private final static IntWritable one = new IntWritable(1); private Text word = new Text(); ・・・・・ ・・・・・ Example.java 2022/5/31
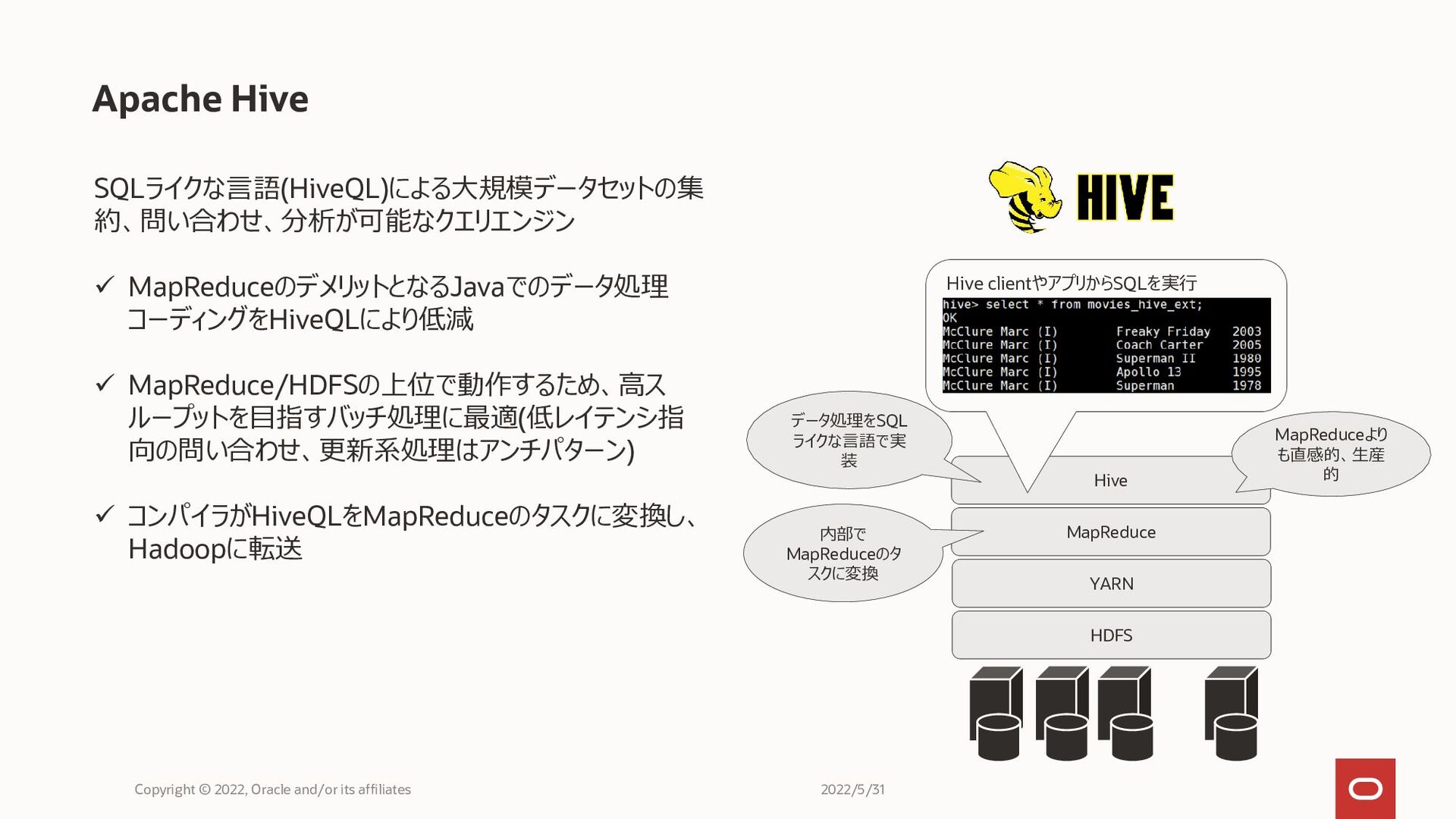
Hive Apache Hive Copyright © 2022, Oracle and/or its affiliates
SQLライクな言語(HiveQL)による大規模データセットの集 約、問い合わせ、分析が可能なクエリエンジン ✓ MapReduceのデメリットとなるJavaでのデータ処理 コーディングをHiveQLにより低減 ✓ MapReduce/HDFSの上位で動作するため、高ス ループットを目指すバッチ処理に最適(低レイテンシ指 向の問い合わせ、更新系処理はアンチパターン) ✓ コンパイラがHiveQLをMapReduceのタスクに変換し、 Hadoopに転送 HDFS YARN MapReduce 内部で MapReduceのタ スクに変換 データ処理をSQL ライクな言語で実 装 MapReduceより も直感的、生産 的 Hive clientやアプリからSQLを実行 2022/5/31
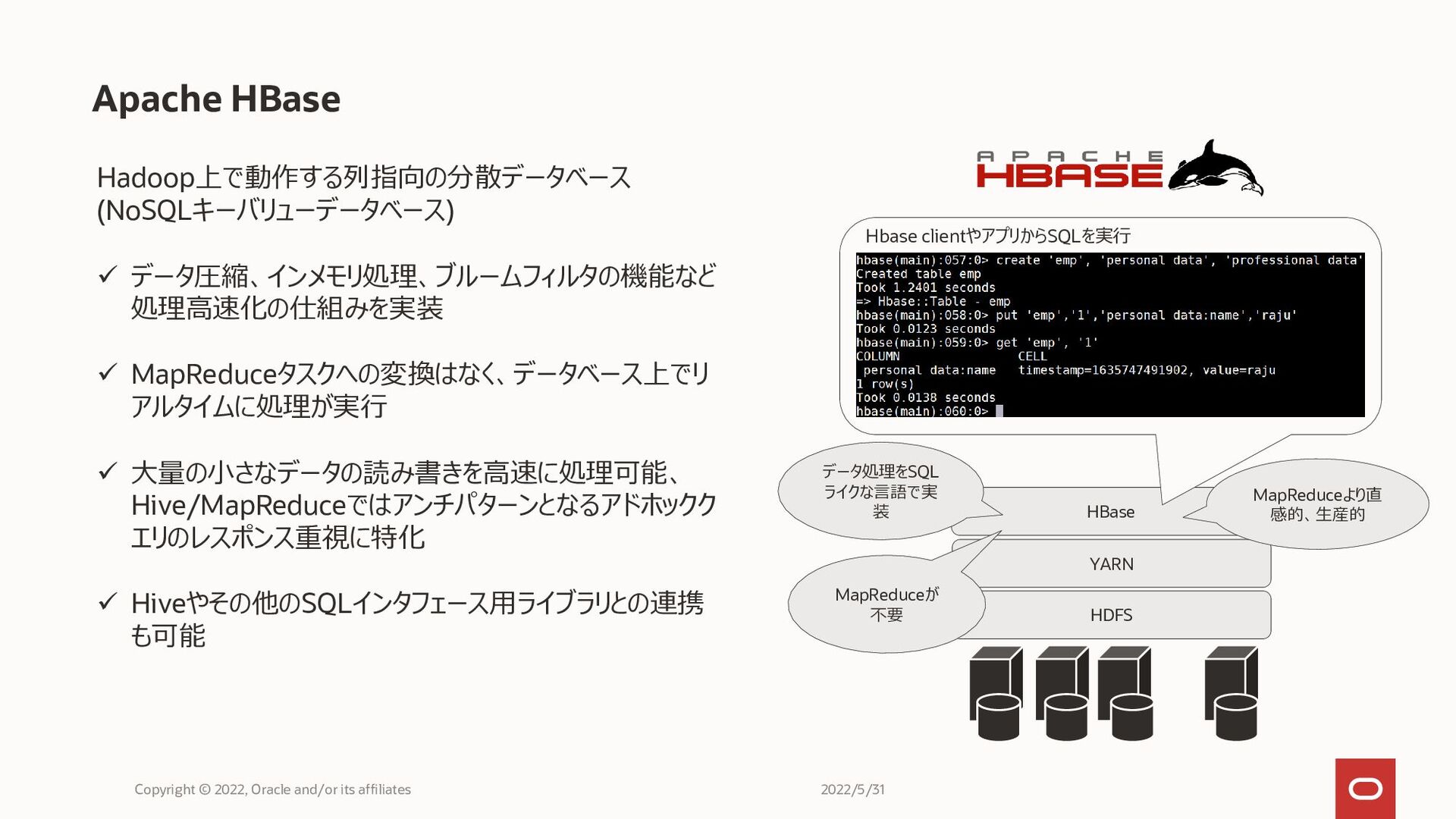
HBase Apache HBase Copyright © 2022, Oracle and/or its affiliates
Hadoop上で動作する列指向の分散データベース (NoSQLキーバリューデータベース) ✓ データ圧縮、インメモリ処理、ブルームフィルタの機能など 処理高速化の仕組みを実装 ✓ MapReduceタスクへの変換はなく、データベース上でリ アルタイムに処理が実行 ✓ 大量の小さなデータの読み書きを高速に処理可能、 Hive/MapReduceではアンチパターンとなるアドホックク エリのレスポンス重視に特化 ✓ Hiveやその他のSQLインタフェース用ライブラリとの連携 も可能 HDFS YARN MapReduceが 不要 データ処理をSQL ライクな言語で実 装 MapReduceより直 感的、生産的 Hbase clientやアプリからSQLを実行 2022/5/31
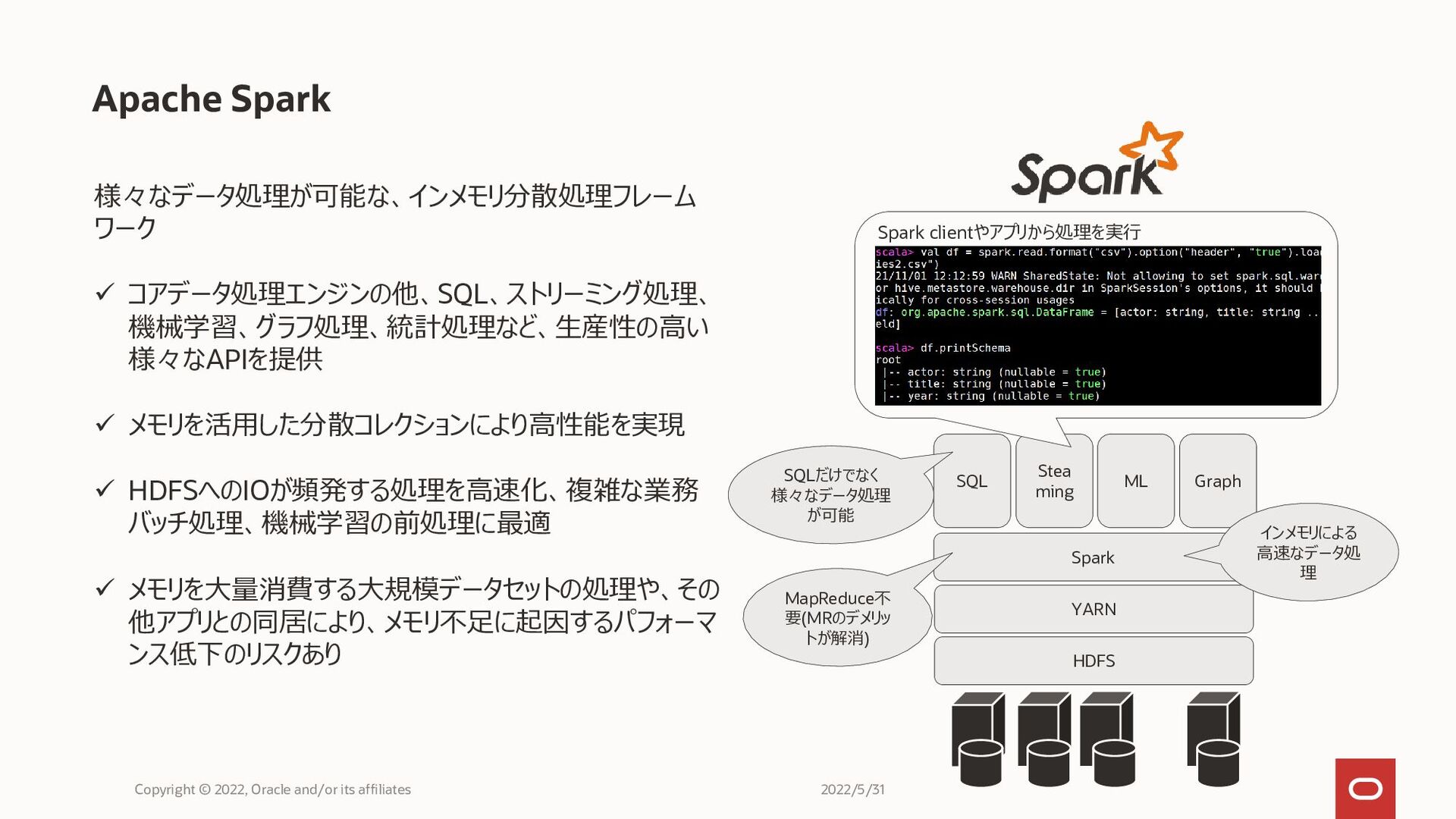
Apache Spark Copyright © 2022, Oracle and/or its affiliates 様々なデータ処理が可能な、インメモリ分散処理フレーム
ワーク ✓ コアデータ処理エンジンの他、SQL、ストリーミング処理、 機械学習、グラフ処理、統計処理など、生産性の高い 様々なAPIを提供 ✓ メモリを活用した分散コレクションにより高性能を実現 ✓ HDFSへのIOが頻発する処理を高速化、複雑な業務 バッチ処理、機械学習の前処理に最適 ✓ メモリを大量消費する大規模データセットの処理や、その 他アプリとの同居により、メモリ不足に起因するパフォーマ ンス低下のリスクあり HDFS YARN Spark MapReduce不 要(MRのデメリッ トが解消) SQL Stea ming ML Graph SQLだけでなく 様々なデータ処理 が可能 インメモリによる 高速なデータ処 理 Spark clientやアプリから処理を実行 2022/5/31
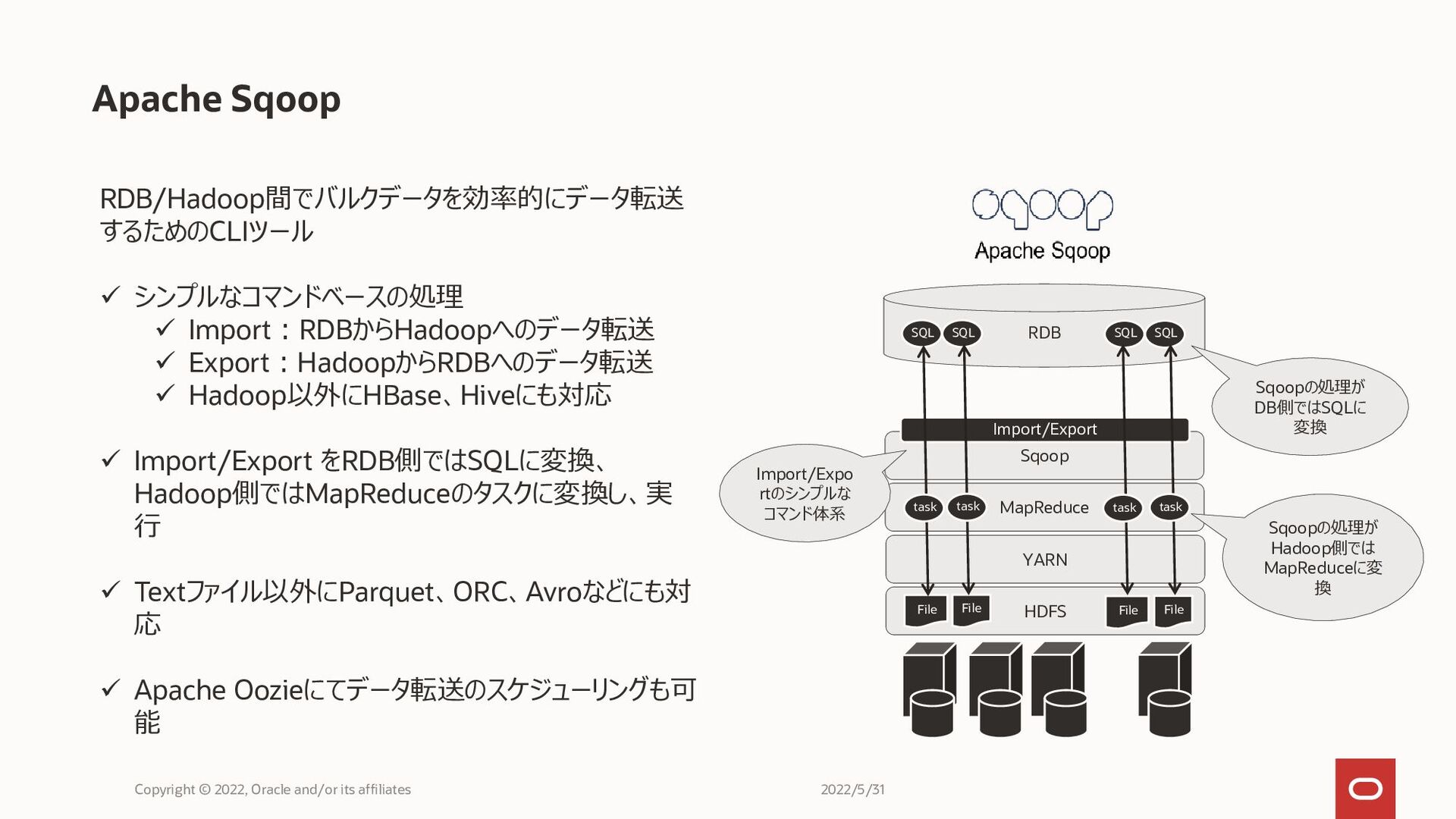
Apache Sqoop Copyright © 2022, Oracle and/or its affiliates RDB/Hadoop間でバルクデータを効率的にデータ転送
するためのCLIツール ✓ シンプルなコマンドベースの処理 ✓ Import:RDBからHadoopへのデータ転送 ✓ Export:HadoopからRDBへのデータ転送 ✓ Hadoop以外にHBase、Hiveにも対応 ✓ Import/Export をRDB側ではSQLに変換、 Hadoop側ではMapReduceのタスクに変換し、実 行 ✓ Textファイル以外にParquet、ORC、Avroなどにも対 応 ✓ Apache Oozieにてデータ転送のスケジューリングも可 能 HDFS YARN MapReduce Sqoop File File File File RDB SQL SQL SQL SQL Import/Export task task task task Import/Expo rtのシンプルな コマンド体系 Sqoopの処理が DB側ではSQLに 変換 Sqoopの処理が Hadoop側では MapReduceに変 換 2022/5/31
Apache Oozie Copyright © 2022, Oracle and/or its affiliates Hadoop上のデータ処理エンジンのジョブスケジュー
ラー ✓ 複数の複雑なジョブを組み合わせて順番に実行 し、より大きなタスクを実行 ✓ MapReduce/Pig/Hive/Sqoop向けのジョブや Java、Shellをサポート Oozie Workflow ✓ 個別でアクションを定義し、実行順序を決定 Oozie Coordinator ✓ 時間や条件指定によりジョブをトリガー Oozie Bundle ✓ 複数のコーディネータやワークフロージョブをパッ ケージ、ジョブのライフサイクルを管理 ワークフローの定義(XML) Action 2 (Hive表の作成) Action 1 (Hive表の作成) Action 3 (データロード) ワークフローの定義の例 2022/5/31
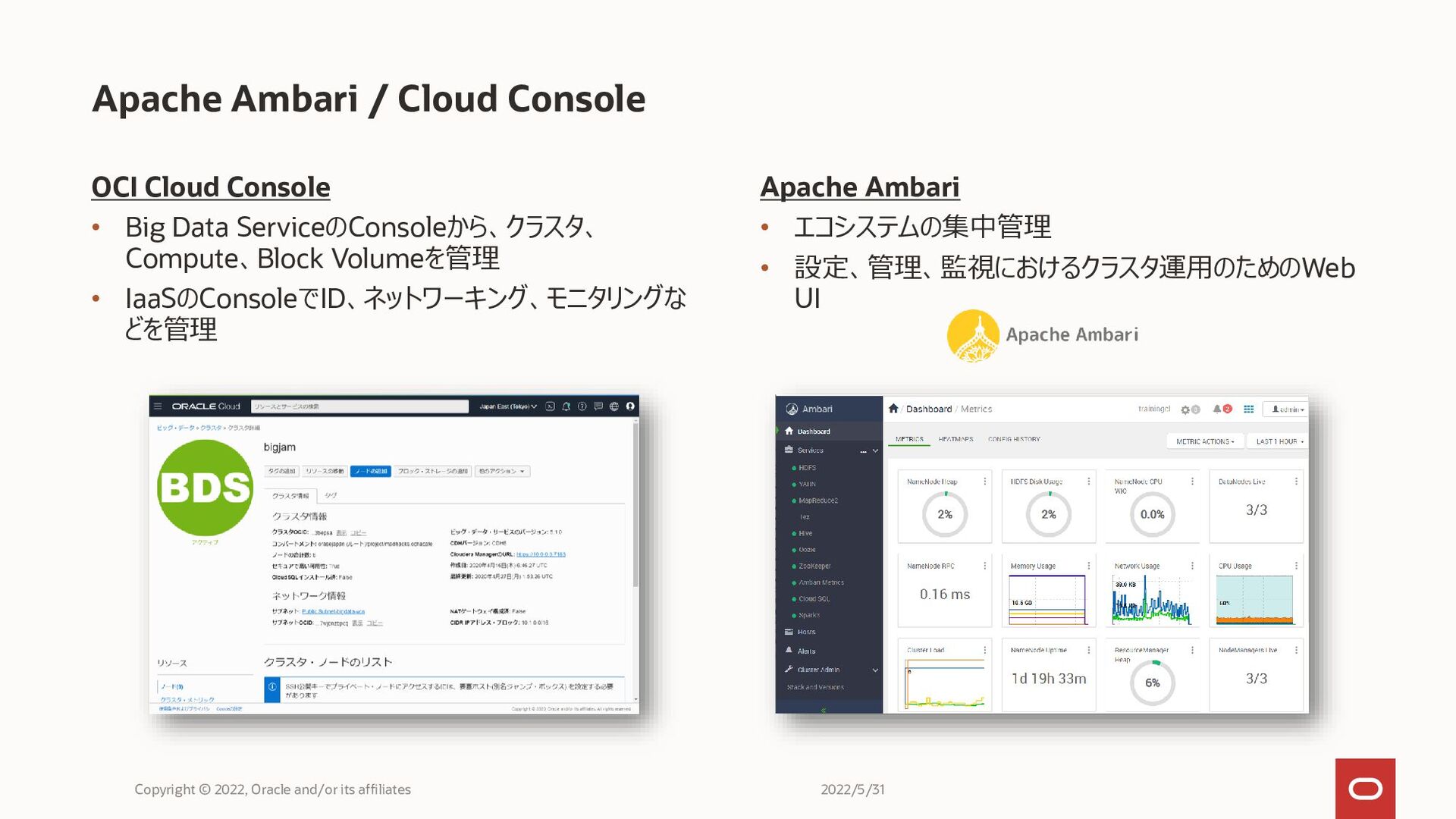
OCI Cloud Console • Big Data ServiceのConsoleから、クラスタ、 Compute、Block Volumeを管理 •
IaaSのConsoleでID、ネットワーキング、モニタリングな どを管理 Apache Ambari / Cloud Console Copyright © 2022, Oracle and/or its affiliates Apache Ambari • エコシステムの集中管理 • 設定、管理、監視におけるクラスタ運用のためのWeb UI 2022/5/31
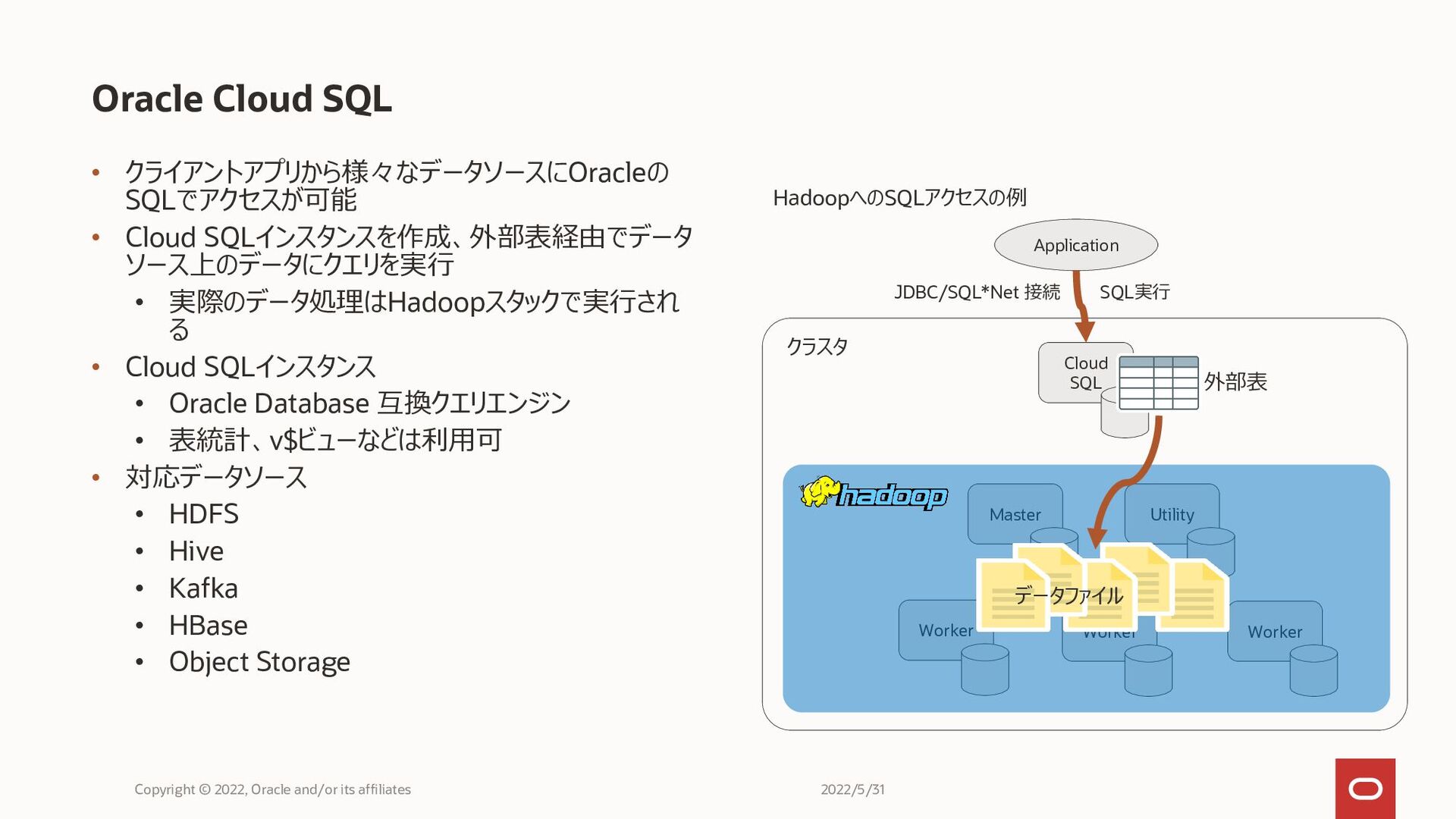
Copyright © 2022, Oracle and/or its affiliates Cloud SQL
• クライアントアプリから様々なデータソースにOracleの SQLでアクセスが可能 • Cloud SQLインスタンスを作成、外部表経由でデータ ソース上のデータにクエリを実行 • 実際のデータ処理はHadoopスタックで実行され る
• Cloud SQLインスタンス • Oracle Database 互換クエリエンジン • 表統計、v$ビューなどは利用可 • 対応データソース • HDFS • Hive • Kafka • HBase • Object Storage Oracle Cloud SQL Copyright © 2022, Oracle and/or its affiliates Cloud SQL Worker Worker Worker Utility Master Application JDBC/SQL*Net 接続 データファイル 外部表 クラスタ SQL実行 HadoopへのSQLアクセスの例 2022/5/31
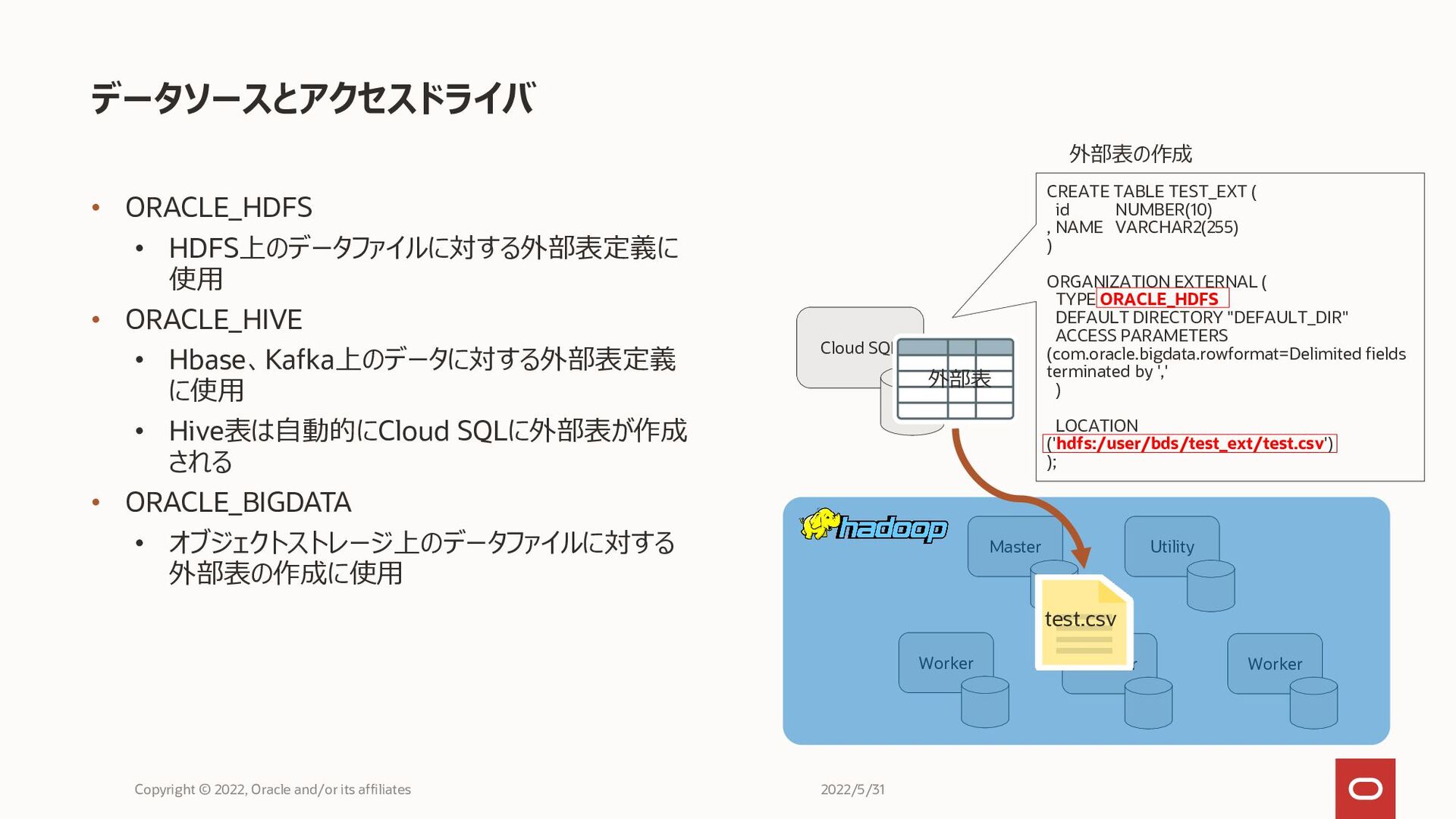
• ORACLE_HDFS • HDFS上のデータファイルに対する外部表定義に 使用 • ORACLE_HIVE • Hbase、Kafka上のデータに対する外部表定義 に使用
• Hive表は自動的にCloud SQLに外部表が作成 される • ORACLE_BIGDATA • オブジェクトストレージ上のデータファイルに対する 外部表の作成に使用 データソースとアクセスドライバ Copyright © 2022, Oracle and/or its affiliates Worker Worker Worker Utility Master test.csv Cloud SQL 外部表 外部表の作成 CREATE TABLE TEST_EXT ( id NUMBER(10) , NAME VARCHAR2(255) ) ORGANIZATION EXTERNAL ( TYPE ORACLE_HDFS DEFAULT DIRECTORY "DEFAULT_DIR" ACCESS PARAMETERS (com.oracle.bigdata.rowformat=Delimited fields terminated by ',' ) LOCATION ('hdfs:/user/bds/test_ext/test.csv') ); 2022/5/31
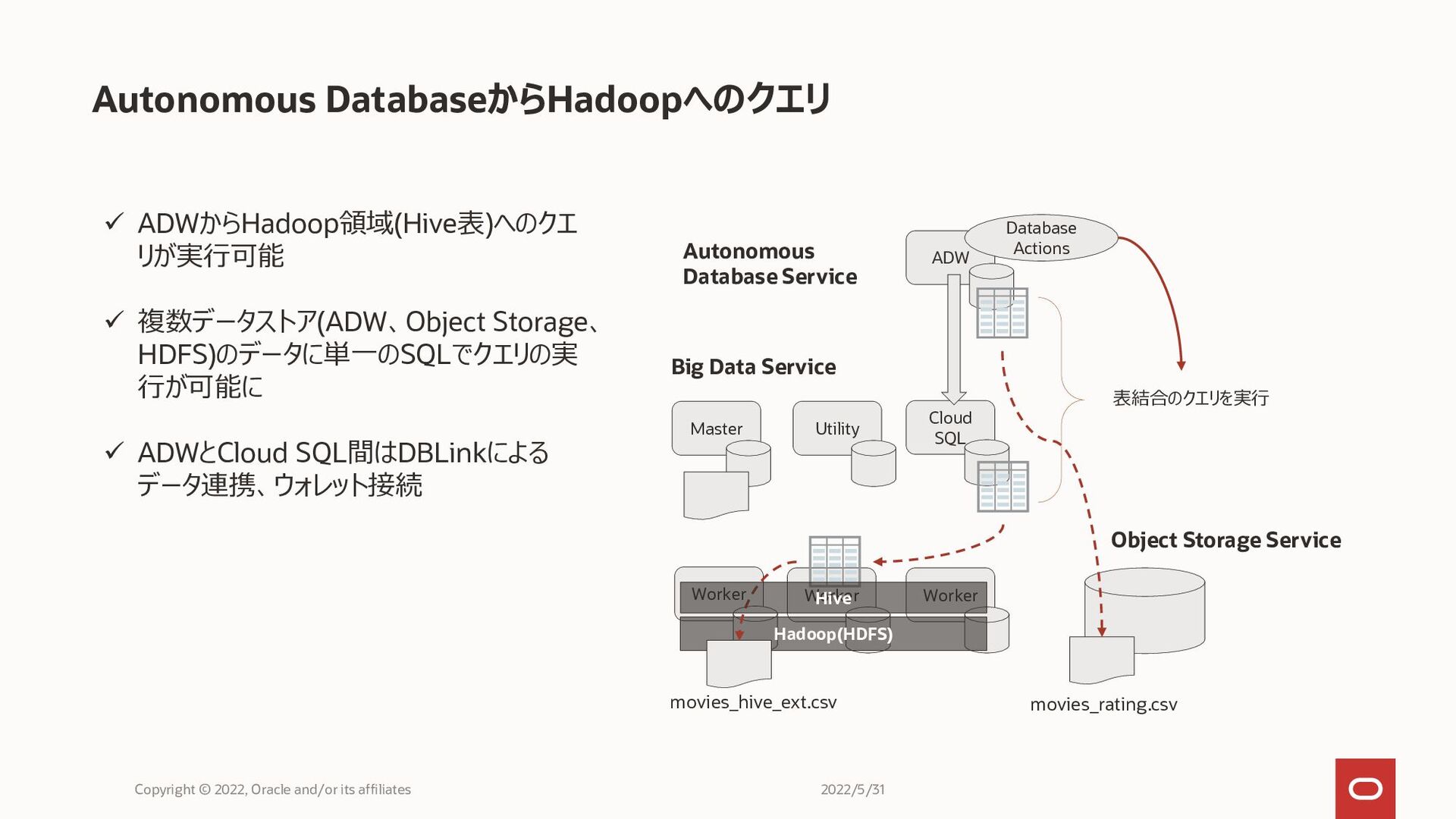
Autonomous DatabaseからHadoopへのクエリ Copyright © 2022, Oracle and/or its affiliates movies_rating.csv
Object Storage Service Master Utility Worker Worker Worker Hadoop(HDFS) movies_hive_ext.csv Cloud SQL Hive ADW Database Actions Big Data Service Autonomous Database Service 表結合のクエリを実行 ✓ ADWからHadoop領域(Hive表)へのクエ リが実行可能 ✓ 複数データストア(ADW、Object Storage、 HDFS)のデータに単一のSQLでクエリの実 行が可能に ✓ ADWとCloud SQL間はDBLinkによる データ連携、ウォレット接続 2022/5/31
Copyright © 2022, Oracle and/or its affiliates Big Data Service
ノード構成
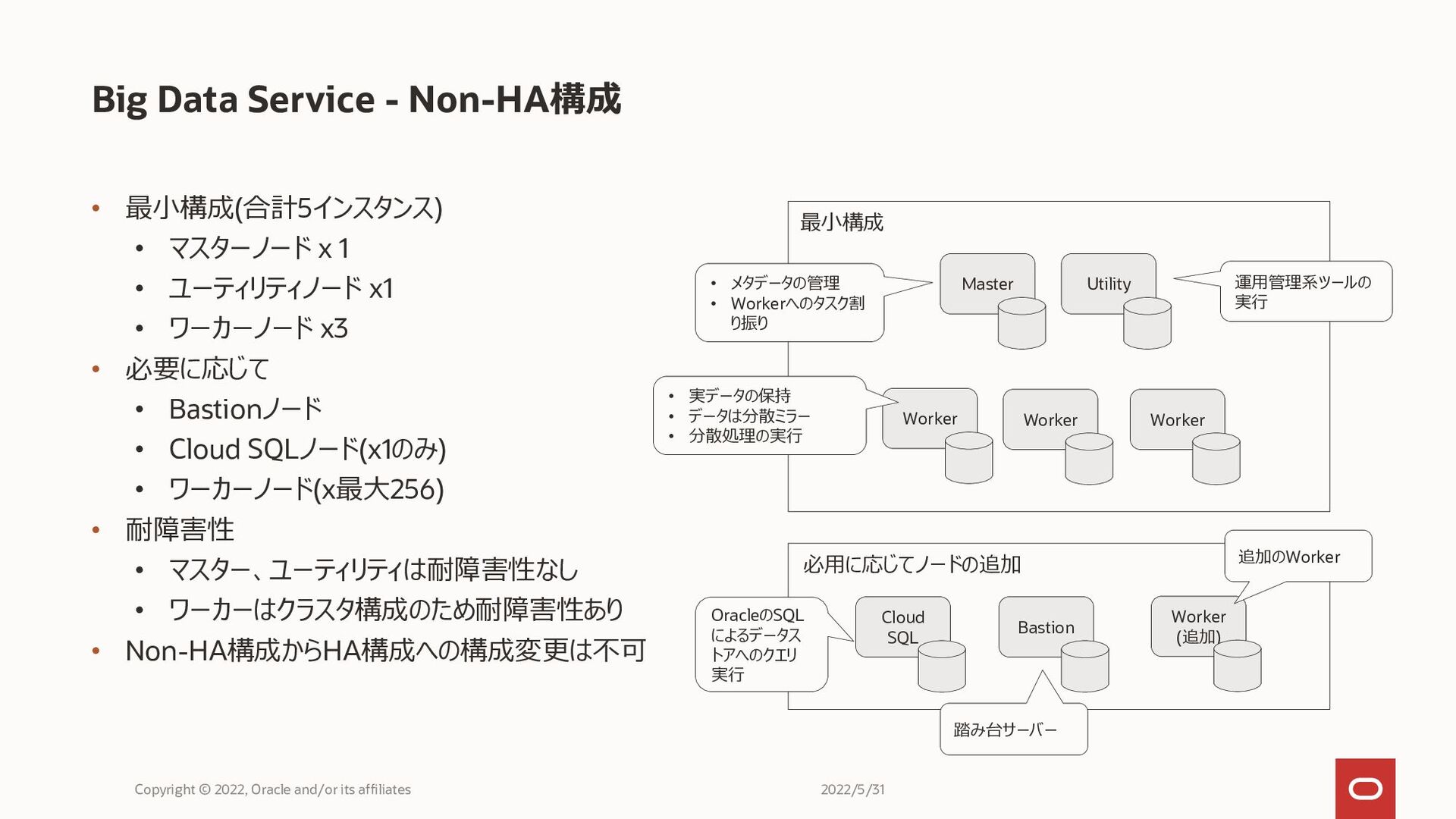
• 最小構成(合計5インスタンス) • マスターノード x 1 • ユーティリティノード x1 •
ワーカーノード x3 • 必要に応じて • Bastionノード • Cloud SQLノード(x1のみ) • ワーカーノード(x最大256) • 耐障害性 • マスター、ユーティリティは耐障害性なし • ワーカーはクラスタ構成のため耐障害性あり • Non-HA構成からHA構成への構成変更は不可 Big Data Service - Non-HA構成 Copyright © 2022, Oracle and/or its affiliates Master Utility Worker Worker Worker 最小構成 • メタデータの管理 • Workerへのタスク割 り振り 運用管理系ツールの 実行 • 実データの保持 • データは分散ミラー • 分散処理の実行 Cloud SQL Bastion Worker (追加) OracleのSQL によるデータス トアへのクエリ 実行 踏み台サーバー 追加のWorker 必用に応じてノードの追加 2022/5/31
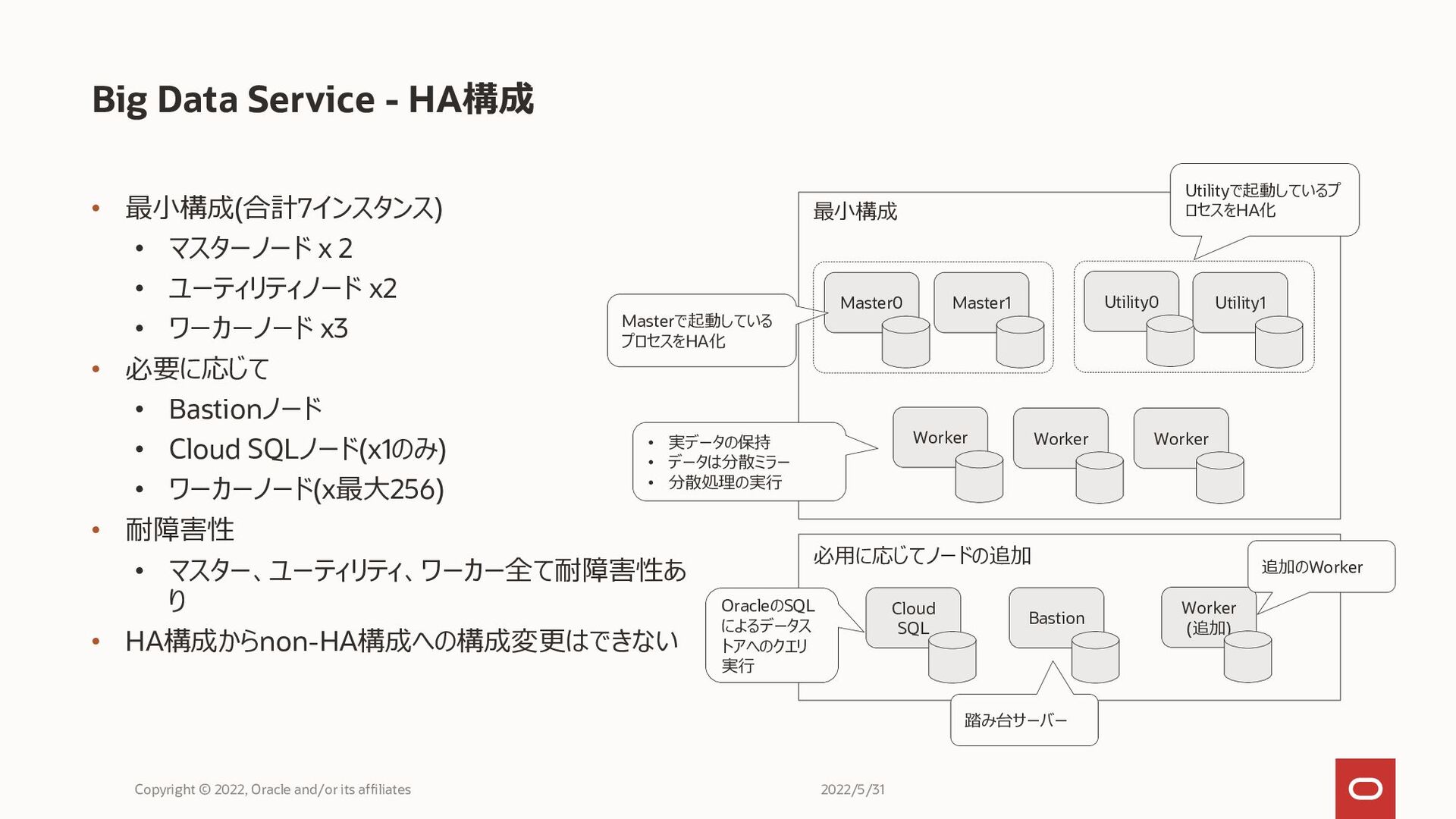
• 最小構成(合計7インスタンス) • マスターノード x 2 • ユーティリティノード x2 •
ワーカーノード x3 • 必要に応じて • Bastionノード • Cloud SQLノード(x1のみ) • ワーカーノード(x最大256) • 耐障害性 • マスター、ユーティリティ、ワーカー全て耐障害性あ り • HA構成からnon-HA構成への構成変更はできない Big Data Service - HA構成 Copyright © 2022, Oracle and/or its affiliates Master0 Utility0 Worker Worker Worker Cloud SQL Bastion Worker (追加) 最小構成 Master1 Utility1 必用に応じてノードの追加 Masterで起動している プロセスをHA化 Utilityで起動しているプ ロセスをHA化 • 実データの保持 • データは分散ミラー • 分散処理の実行 OracleのSQL によるデータス トアへのクエリ 実行 踏み台サーバー 追加のWorker 2022/5/31
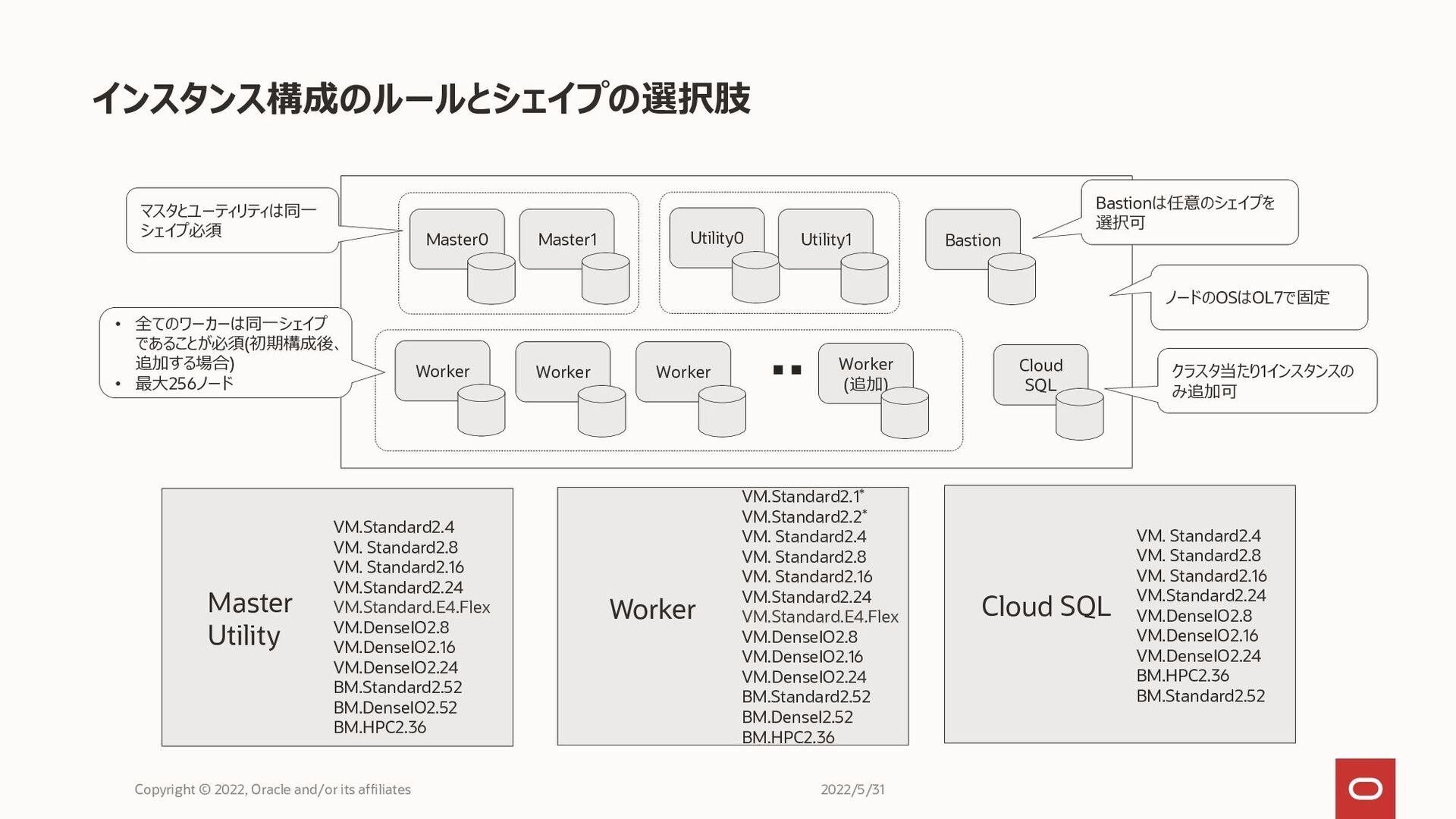
インスタンス構成のルールとシェイプの選択肢 Copyright © 2022, Oracle and/or its affiliates Master0 Utility0
Worker Worker Worker Cloud SQL Bastion Worker (追加) Master1 Utility1 マスタとユーティリティは同一 シェイプ必須 • 全てのワーカーは同一シェイプ であることが必須(初期構成後、 追加する場合) • 最大256ノード クラスタ当たり1インスタンスの み追加可 ノードのOSはOL7で固定 VM. Standard2.4 VM. Standard2.8 VM. Standard2.16 VM.Standard2.24 VM.DenseIO2.8 VM.DenseIO2.16 VM.DenseIO2.24 BM.HPC2.36 BM.Standard2.52 Cloud SQL VM.Standard2.4 VM. Standard2.8 VM. Standard2.16 VM.Standard2.24 VM.Standard.E4.Flex VM.DenseIO2.8 VM.DenseIO2.16 VM.DenseIO2.24 BM.Standard2.52 BM.DenseIO2.52 BM.HPC2.36 Master Utility VM.Standard2.1* VM.Standard2.2* VM. Standard2.4 VM. Standard2.8 VM. Standard2.16 VM.Standard2.24 VM.Standard.E4.Flex VM.DenseIO2.8 VM.DenseIO2.16 VM.DenseIO2.24 BM.Standard2.52 BM.DenseI2.52 BM.HPC2.36 Worker Bastionは任意のシェイプを 選択可 2022/5/31
• マスター/ユーティリティ • ブートボリューム 150GB固定 • ブロックボリュームx1 • ノードあたり最小150GBから50GB単位で最大 32TB
• 初期構成後のブロックストレージの追加は不可 • Cloud SQL • ノードあたり最小1TBから50GB単位で最大32TB • 2TB以上を推奨 ブロックストレージの構成ルール Copyright © 2022, Oracle and/or its affiliates • ワーカー • ブートボリューム 150GB固定 • ブロックボリューム xN • ノードあたり最小150GBから50GB単位で最大 48TB • 初期構成後の追加は上記と同じだが、初期+追 加で48TB以内となる • 6TB未満/ノードの場合 • 500GBのVolに均等分割、最後のVolは500GB未 満 • 6TB – 48TB/ノードの場合 - 500GB以上のvol x12に均等分割、最後のVolは 500GB未満 • 初期構成後にブロックストレージを追加する場合、 全てのノードに追加される 2022/5/31
CPU負荷に基づき、ワーカーノードの計算のシェイプとノード数を 自動的に増減し、最適なコストパフォーマンスを維持 • オートスケールのパターン ✓ スケール・アップ:次に大きいシェイプへの切り替え ✓ スケール・ダウン:次に小さいシェイプへの切り替え ✓ スケール・アウト:クラスターへのノードの追加
(追加ノード数、クラスタの最大ノード数を指定) ✓ スケール・イン:クラスターからのノードの削除 (削除ノード数、クラスタの最小ノード数を指定) • オートスケールのトリガー ✓ 事前設定した平均CPU負荷の閾値(%)とその期間(5〜60 分または1〜24時間で60分単位に指定) ✓ 指定した期間の経過後に構成変更がトリガーされる • 設定例 ✓ 平均CPU使用率80%以上の期間が30分続いた場合、ス ケール・アップ or スケール・アウトをトリガー ✓ 平均CPU使用率20%以下の期間が30分続いた場合、ス ケール・ダウン or スケール・インをトリガー クラスタ構成のオートスケール Copyright © 2022, Oracle and/or its affiliates 2022/5/31
• HA構成からNon-HA構成の変更不可(逆も不可) • クラスタノードの停止不可(再起動および終了のみ可) • オートスケールはWorkerノードのみ可 • 手動のノード追加、削除、シェイプの変更はWorkerノードのみ可 • Cloud
SQL • 一台のみ追加可能、ノードの削除可能 • HA構成は不可 構成変更についての注意点 Copyright © 2022, Oracle and/or its affiliates 2022/5/31
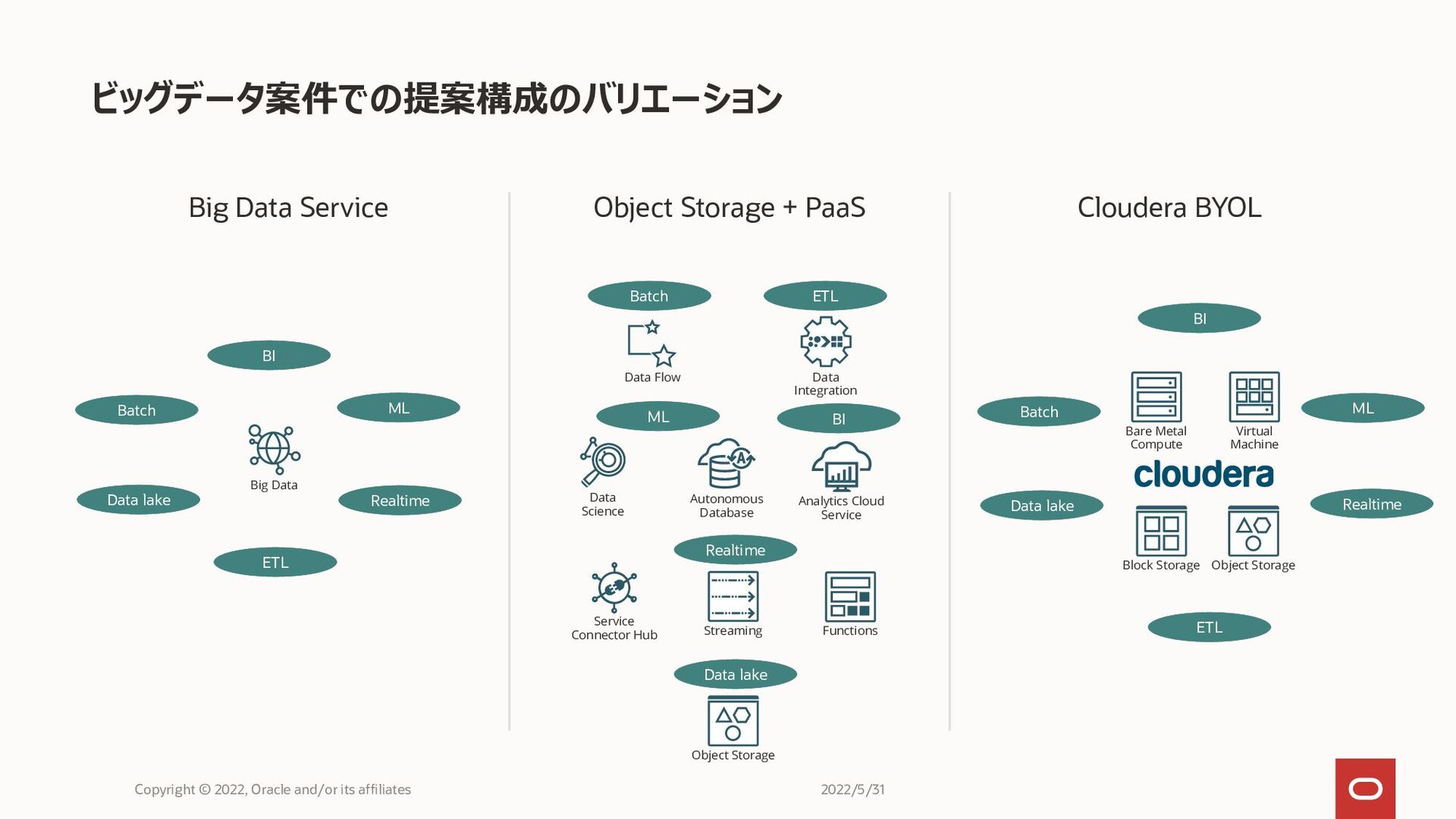
Big Data Service Object Storage + PaaS Cloudera BYOL ビッグデータ案件での提案構成のバリエーション
Copyright © 2022, Oracle and/or its affiliates Big Data Object Storage Data Flow Autonomous Database Data Science Data Integration Analytics Cloud Service Streaming Service Connector Hub Functions Data lake Realtime BI ML ETL Batch Data lake BI Batch ETL Realtime ML Bare Metal Compute Virtual Machine Block Storage Object Storage Data lake Realtime BI ML ETL Batch 2022/5/31
None
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}