and N. Kruschwitz, “Big data, analytics and the path from insights to value.,” MIT Sloan Management Review, vol. 21, 2014. [18] S. Lucas, Interviewee, [Interview]. December 2013. [19] A. Asquer, “The Governance of big data: Perspectives and Issues,” in First International Conference on Public Policy, Grenoble, 2013. [20] Centre for Economics and Business Research, “Data equity: unlocking the value of big data.,” SAS, 2012. [21] United Nations, “A New Global Partnership: Eradicate Poverty and Transform Economies Through Sustainable Development.,” United Nations Publications, New York, 2013. [22] J. Blumenstock, Interviewee, [Interview]. January 2014. [23] V. Frias-Martinez, Interviewee, [Interview]. December 2013. [24] M. Khouja, Interviewee, [Interview]. December 2013. [25] A. Siegel, Interviewee, [Interview]. December 2013. [26] N. Eagle, Interviewee, [Interview]. December 2013. [27] A. Leshinsky, Interviewee, [Interview]. January 2014. [28] R. Kirkpatrick, Interviewee, [Interview]. February 2014. [29] A. Cavallo, Interviewee, [Interview]. February 2014. [30] N. Scott and S. Batchelor, “Real Time Monitoring in Disasters,” IDS Bulletin, vol. 44, no. 2, pp. 122-134, 2013. [31] S. Thornton, Interviewee, [Interview]. February 2014. [32] United Nations Global Pulse, “Big Data for Development: A Primer,” United Nations Publications, 2013. [33] W. Hall, N. Shadbolt, T. Tiropanis, K. O’Hara and T. Davies, “2012,” Nominet Trust, Open data and charities. [34] A. R. Syed, K. Gillela and C. Venugopal, “The Future Revolution on Big Data,” Future, vol. 2, no. 6, 2013. [35] E. Bertino, P. Bernstein, D. Agrawal, S. Davidson, U. Dayal, M. Franklin, ... and J. Widom, “Challenges and Opportunities with Big Data,” White Paper, 2011. [36] World Economic Forum, “Big Data, Big Impact: New Possibilities for International Development,” World Economic Forum, Geneva, 2012. [37] D. Bollier, “The Promise and Peril of Big Data,” The Aspen Institute, Washington, D.C., 2010. [38] M. Ghasemali, Interviewee, [Interview]. January 2014. [39] R. Cross, Interviewee, [Interview]. December 2013. [40] E. Wetter and L. Bengtsson, Interviewees, [Interview]. January 2014. [41] K. Warner, T. Afifi, T. Rawe, C. Smith and A. De Sherbinin, “Where the rain falls: Climate change, food and livelihood security, and migration,” 2012. [42] M. Hilbert, “Big Data for Development: From Information-to Knowledge Societies,” Working Paper, 2013. [43] L. F. Mejía, D. Monsalve, Y. Parra, S. Pulido and Á. M. Reyes, “Indicadores ISAAC: Siguiendo la actividad sectorial a partir de Google Trend,” Ministerio de Hacienda y Crédito Público, Bogotá, 2013. Available: http://www.minhacienda.gov.co/ portal/page/portal/HomeMinhacienda/politicafiscal/ 58
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![commercial and non-commercial utilization [14]. Cities such as New York](https://files.speakerdeck.com/presentations/d9fd731a4532472ba1caec546e486e00/slide_9.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
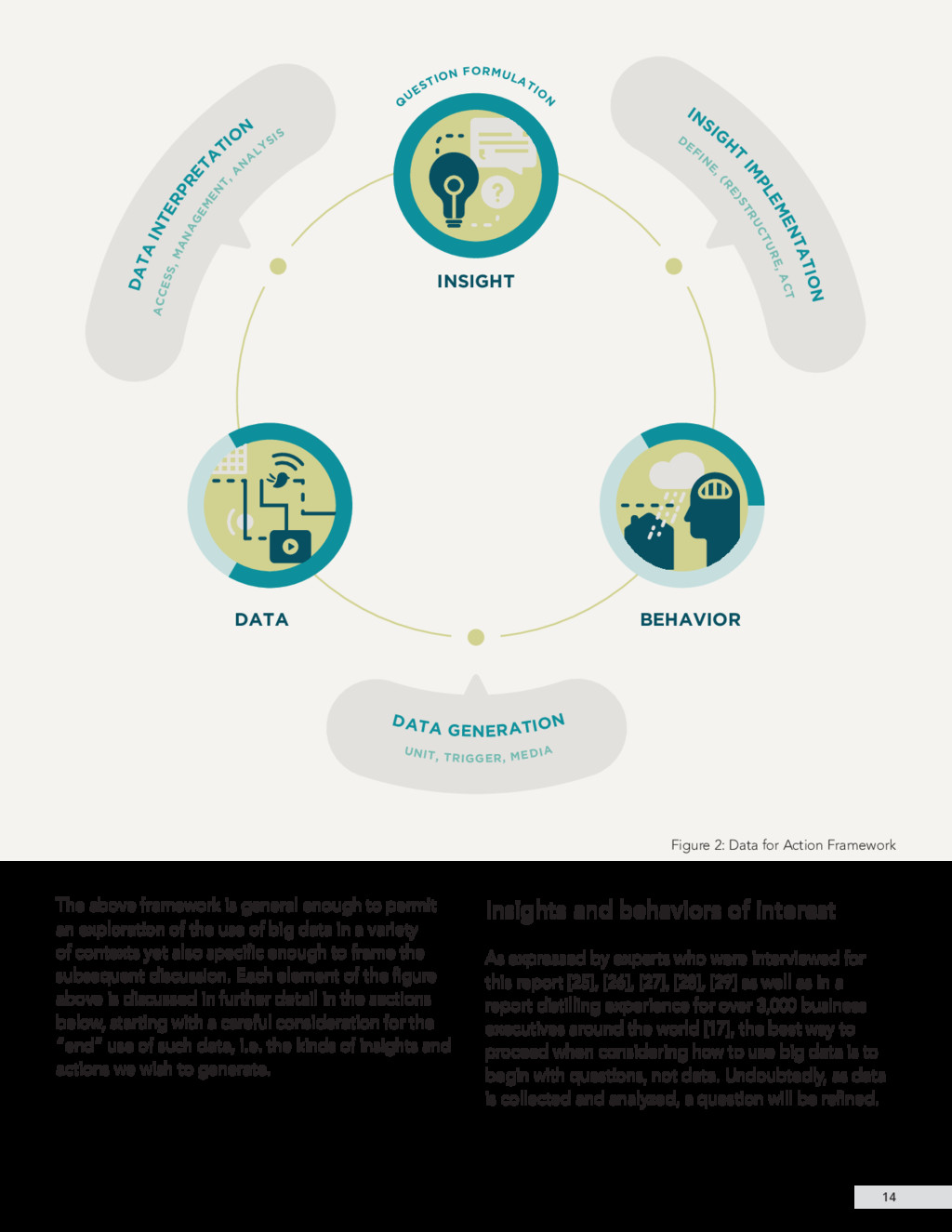{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
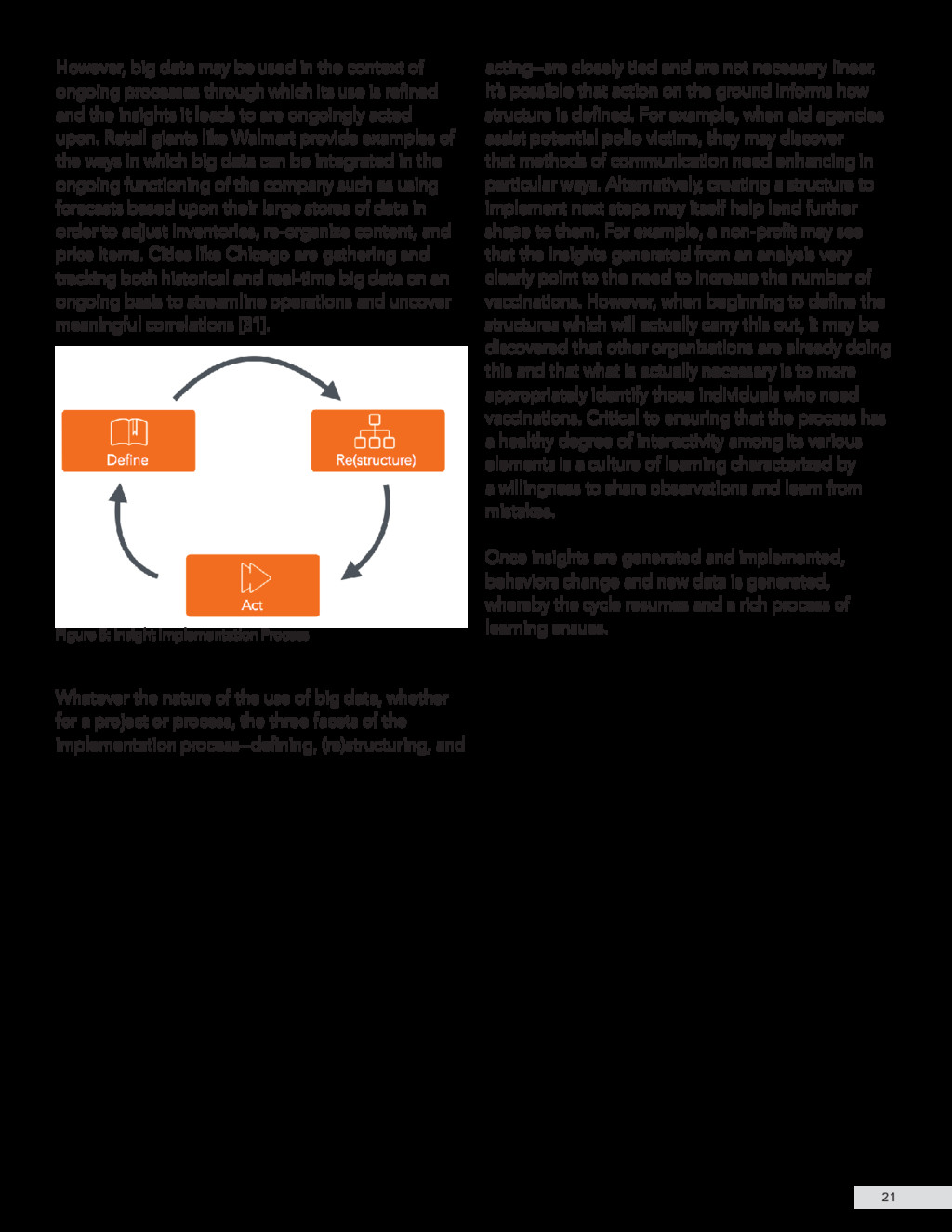{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![also can increase time and cost savings for drivers [42].](https://files.speakerdeck.com/presentations/d9fd731a4532472ba1caec546e486e00/slide_26.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![movement and prepare for interaction with other data [22]. Text](https://files.speakerdeck.com/presentations/d9fd731a4532472ba1caec546e486e00/slide_43.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![on generating insights for policy or management decisions [26]. Use](https://files.speakerdeck.com/presentations/d9fd731a4532472ba1caec546e486e00/slide_50.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[1] H. Varian, “Big Data: New Tricks for Econometrics,” Journal](https://files.speakerdeck.com/presentations/d9fd731a4532472ba1caec546e486e00/slide_56.jpg){kind=link}
![[17] S. LaValle, E. Lesser, R. Shockley, M. S. Hopkins](https://files.speakerdeck.com/presentations/d9fd731a4532472ba1caec546e486e00/slide_57.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}