Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
ざっくり理解する Nutanix の Day 2 オペレーション
Search
Satoshi Shimazaki
July 01, 2021
Technology
1.1k
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
ざっくり理解する Nutanix の Day 2 オペレーション
Nutanix Meetup Online 21.06の講演資料です。
イベントページはコチラ。
https://nutanix.connpass.com/event/214554/
Satoshi Shimazaki
July 01, 2021
More Decks by Satoshi Shimazaki
See All by Satoshi Shimazaki
次期LTSに備えよ!AOS 6.1 HCI Core 編
smzksts
0
770
Nutanix AHVのメモリオーバーコミット
smzksts
0
1.7k
AOS 5.20 LTS & 6.0 STS アップデート情報
smzksts
0
1.4k
つまづかない!Nutanix CE 5.18の始めかた
smzksts
1
1.2k
そんなことまで!?Nutanix CEを使い倒そう!
smzksts
1
1.9k
Nutanix Community Edition 5.18 - Installation issues and workarounds
smzksts
0
1.4k
Nutanix Community Edition 5.18 徹底解説 / Nutanix CE 5.18 Deep Dive
smzksts
0
14k
Other Decks in Technology
See All in Technology
Webアプリ認証の全体像 / The Big Picture of Web App Authentication
kitano_yuichi
1
430
AIが当たり前の組織で エンジニアはどう育つか
nishihira
1
990
AI Native なプロダクト組織の立ち上げ方 : 生産性 100 倍への挑戦
mikesorae
0
1.3k
Devsumi 2026 Summer 人もAIも使える共通基盤を事業の加速装置にする~デザインシステム運用に学ぶ組織レバレッジ~ 渡辺 凌央
legalontechnologies
PRO
1
290
AI時代の開発生産性を捉え直す — 経営と現場をつなぐ「開発組織のオブザーバビリティ」— / AI Dev Ex Conference 2026
tkyowa
1
1.3k
文字起こし基盤の信頼性
abnoumaru
0
120
アップデートで何が変わった?デモで学んで使いこなすIBM Bob2.0
muehara
0
230
OPENLOGI Company Profile for engineer
hr01
1
74k
穢れた技術選定について
watany
19
6.2k
”AIを使う” から ”AIに任せる” へ ─ 開発プロセスを再設計してAIを組織標準にするまで
cyberagentdevelopers
PRO
2
140
AI工学特論: MLOps・継続的評価
asei
6
1.3k
kaonavi Tech Night#1
kaonavi
0
160
Featured
See All Featured
The Success of Rails: Ensuring Growth for the Next 100 Years
eileencodes
47
8.2k
How to Ace a Technical Interview
jacobian
281
24k
Balancing Empowerment & Direction
lara
6
1.2k
Sharpening the Axe: The Primacy of Toolmaking
bcantrill
46
2.9k
Ecommerce SEO: The Keys for Success Now & Beyond - #SERPConf2024
aleyda
1
2.1k
Documentation Writing (for coders)
carmenintech
77
5.4k
Chrome DevTools: State of the Union 2024 - Debugging React & Beyond
addyosmani
10
1.3k
The #1 spot is gone: here's how to win anyway
tamaranovitovic
3
1.1k
Refactoring Trust on Your Teams (GOTO; Chicago 2020)
rmw
35
3.7k
Public Speaking Without Barfing On Your Shoes - THAT 2023
reverentgeek
1
460
We Analyzed 250 Million AI Search Results: Here's What I Found
joshbly
1
1.6k
Discover your Explorer Soul
emna__ayadi
2
1.2k
Transcript
ざっくり理解する の オペレーション
はじめに – 本資料は、 年 月時点における弊社の一般的な製品情報を説明を主目的とするものです。 – 本資料は情報提供を唯一の目的とするものであり、法律的またはその他の指導や助言を意図したものではなく、 いかなる契約にも用いることはできません。 – 本資料に含まれている情報については、完全性と正確性を期するよう努力しましたが、「現状」で提供され、
明示的または暗示的に関わらず、いかなる保証も伴わないものとします。 – 本資料またはその他の資料の使用によって、あるいはその他の関連によって、いかなる損害か生した場合も、 及びニュータニックス・ジャパン合同会社は責任を負わないものとします。 – 本資料で提供する情報やマテリアル、機能を確実に提供することを確約するものではありません。 弊社製品に関して記載されている機能の開発、リリースおよび時期については、弊社の裁量により決定されます。
オペレーションって? •いわゆる「運用」フェーズで行う諸々の作業 – :計画、設計、調達 – :構築、初期設定 – :運用 ▪監視、メンテナンス、トラブルシューティング等々、 システムが正常稼働し続けるために必要なこと
今回の アジェンダ における オペレーションの概要 システムの健全性を保つ ソフトウェアを サポート対象のバージョンに保つ リソース枯渇を防ぐ
このセッションにはあまり含まない内容 • バックアップ –重要な オペレーションではあるが、 テーマ単体でのボリュームが大きいため • セキュリティ –重要な オペ
• 自動化 –重要な オペ
における オペレーションの概要
の主な運用管理ツール • 外部連携を伴う自動化の際には利用する可能性あり • プロダクト毎に が存在する • 一部のオペレーションでは最小限のコマンド操作が必要 • 基本コマンドと
独自コマンドの組合せ • 定常運用タスクの殆どは で完結
ブラウザベースの統合管理ツール
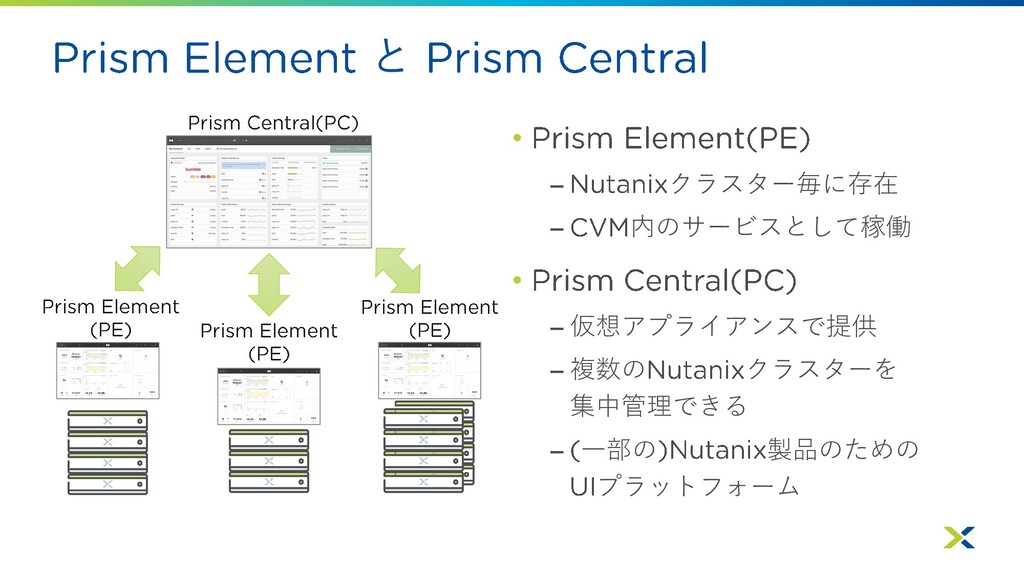
と • – クラスター毎に存在 – 内のサービスとして稼働 • – 仮想アプライアンスで提供 –
複数の クラスターを 集中管理できる – 一部の 製品のための プラットフォーム
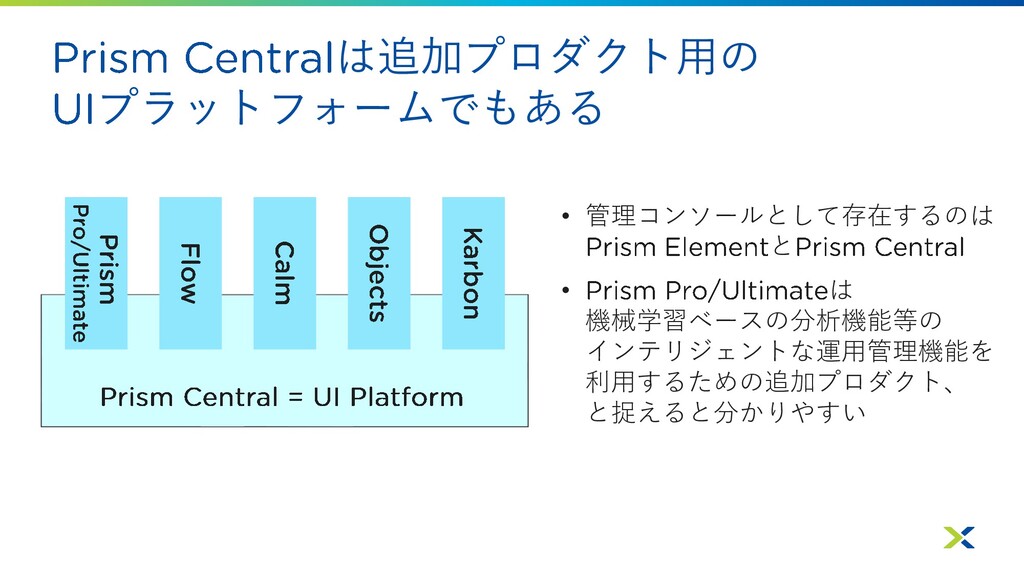
は追加プロダクト用の プラットフォームでもある • 管理コンソールとして存在するのは と • は 機械学習ベースの分析機能等の インテリジェントな運用管理機能を 利用するための追加プロダクト、
と捉えると分かりやすい
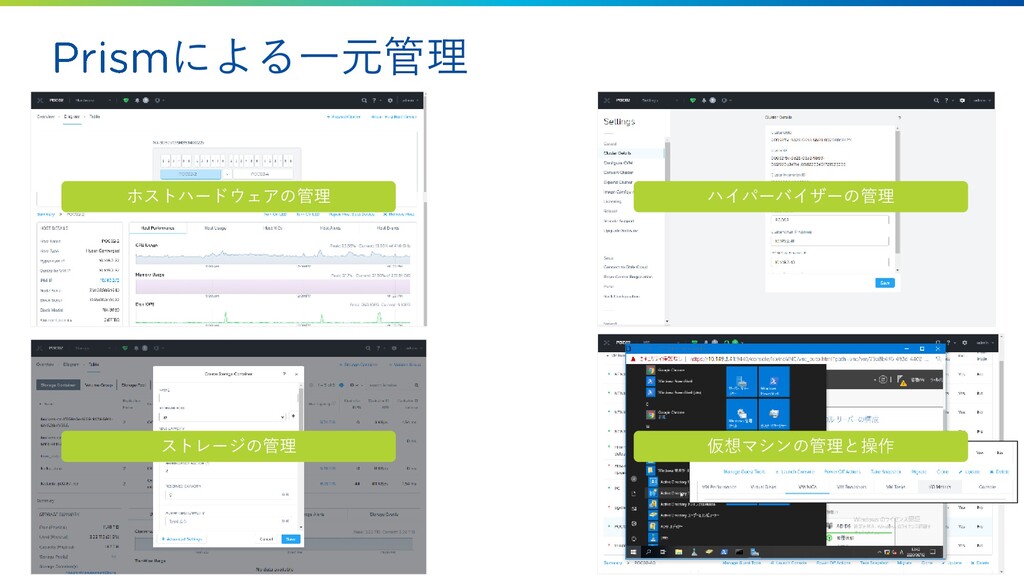
による一元管理 ホストハードウェアの管理 ハイパーバイザーの管理 ストレージの管理 仮想マシンの管理と操作
による一元管理 バックアップ・ の管理 ネットワーク可視化 ファイルサーバー の展開と管理 メトリックとアラートの相関分析
による一元管理 インフラストラクチャーの健全性管理 ソフトウェアアップデート アラートの管理 ファームウェアアップデート
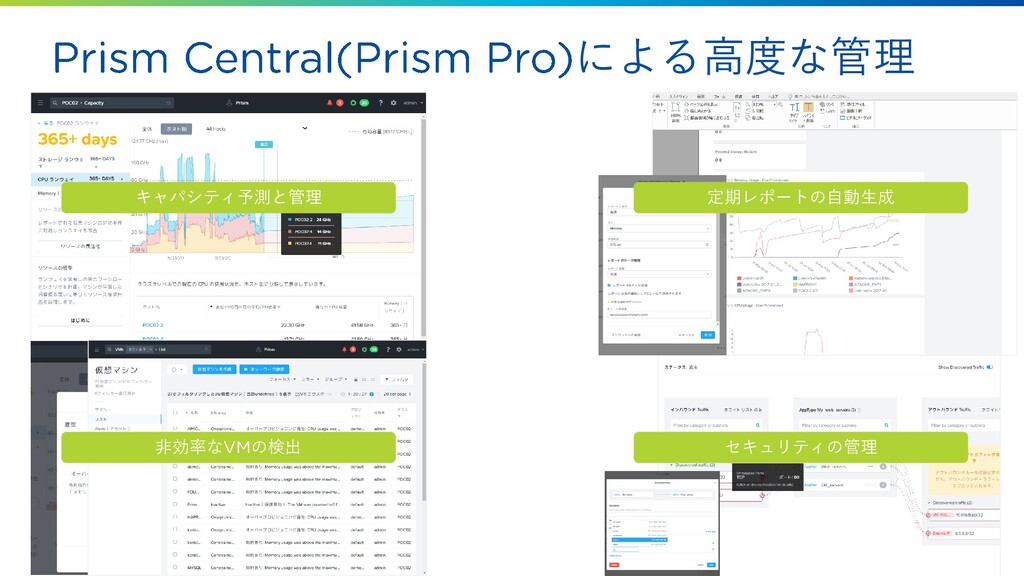
による高度な管理 キャパシティ予測と管理 非効率な の検出 セキュリティの管理 定期レポートの自動生成
との比較① 作業項目 ソフトウェア、 ファームウェア 更新 機器及びそれぞれの内部コンポーネントのアップデー ト情報を確認。ソフトウェア ファームウェア間での 互換性を調査し、更新作業の順序を設計。 で数クリック
• • 監視 機器ごとに異なる 、異なるフォーマットの情報を比 較。横断的に監視を行うためには の監視シ ステムが必要。 • の健全性メニューを確認 • を確認 • メール通知の確認 レポート作成 機器ごとに異なるフォーマットのデータをそれぞれの から収集し、取りまとめる。 • リソース情報や操作履歴の 出力 • による自動レポート生成 バックアップ ストレージ レベルでのバックアップや、 バックアップツールによる レベルでの バックアップなど、環境及び要件に合わせたバック アップシステムを設計・構築。運用方法は選択した方 式やツールにより異なる。 • の保護ドメインメニュー • メイン 環境の運用性を共通化 • 運用は で数クリック • バックアップ • により設計・構築を簡素化
との比較② 作業項目 スケールアウト (ノード増設) 結線、 スイッチ、 スイッチの疎通、スト レージ装置の設定、ハイパーバイザーの設定などを更 新した上で、ハイパーバイザーのクラスターに追加 結線と
スイッチの設定を行い、ノード間での 疎通が可能な状態にする で数クリック スケールイン (ノード取外し) ホストをメンテナンスモードにし、ハイパーバイザー のクラスターから削除した上で、ハイパーバイザー、 ストレージ装置、 スイッチの設定を更新 削除 し、 取外し で数クリック スイッチの設定を更新 削除 し、取外し 起動 スイッチ、 スイッチ、ストレージ装置、 サーバーの順で起動し、ハイパーバイザーがストレー ジを認識していることを確認 スイッチを起動 各ノードを起動 ノード間の疎通が可能な状態で コマンドを実行 停止 ゲスト を停止 ハイパーバイザーを停止 ストレージ装置を停止 スイッチの順で停止 ゲスト を停止 コマンドを実行 をシャットダウン ハイパーバイザーをシャットダウン
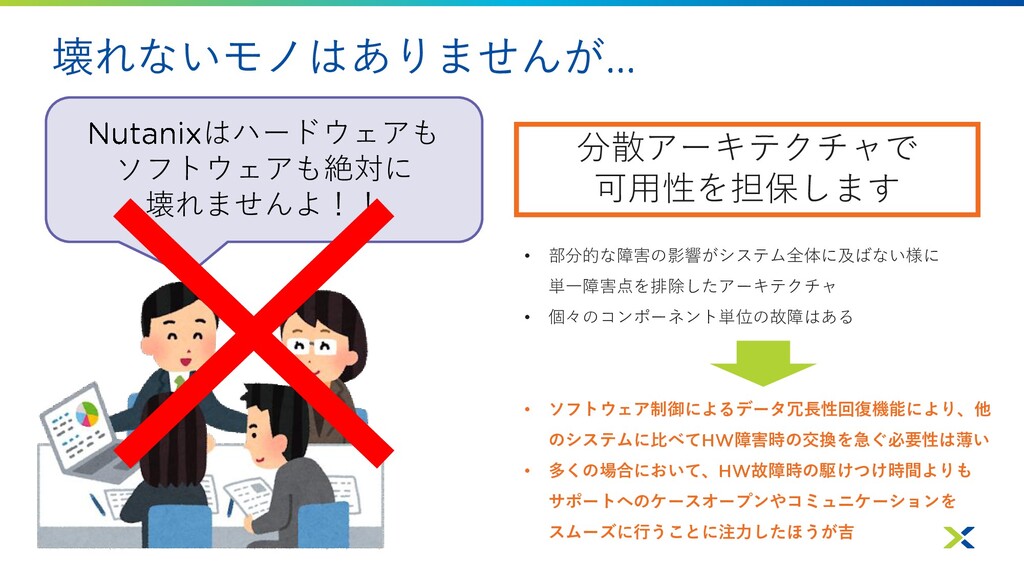
壊れないモノはありませんが はハードウェアも ソフトウェアも絶対に 壊れませんよ!! 分散アーキテクチャで 可用性を担保します • 部分的な障害の影響がシステム全体に及ばない様に 単一障害点を排除したアーキテクチャ •
個々のコンポーネント単位の故障はある • ソフトウェア制御によるデータ冗長性回復機能により、他 のシステムに比べて 障害時の交換を急ぐ必要性は薄い • 多くの場合において、 故障時の駆けつけ時間よりも サポートへのケースオープンやコミュニケーションを スムーズに行うことに注力したほうが吉
ここまでを踏まえてのポイント 時間× 日、 ずっと を見続けよう! しかもダブルチェックだ!! のコンセプトは 『 』 •
「存在を意識する必要がない」くらいシンプル • とはいえ「存在しない」わけではない以上 意識しておくべきポイントはもちろんある 勘所を押さえることで、過剰な運用負荷や 過剰な人的コストを防ぐ、という方向が吉
システムの健全性を保つ あるいは発生した問題を迅速に解決する
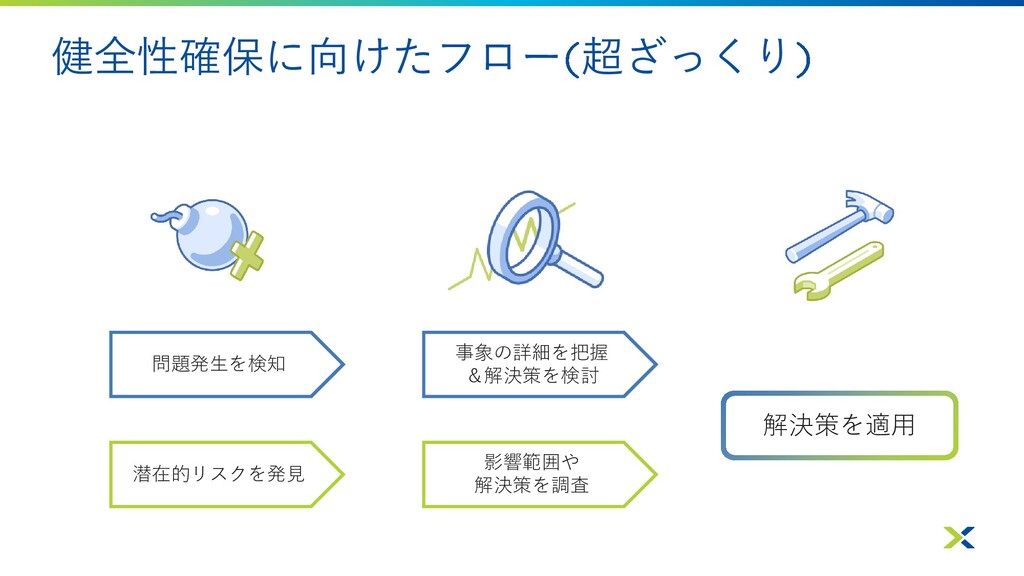
健全性確保に向けたフロー 超ざっくり 問題発生を検知 事象の詳細を把握 &解決策を検討 解決策を適用 潜在的リスクを発見 影響範囲や 解決策を調査
• 全体の健全性を数百項目に渡ってチェックする仕組み – 実体はスクリプト群 – チェックの結果は、アラートの生成、 健全性情報のテキストファイルでの レポート出力、 健全性 メニューの
表示などに利用される – を週次で実行し、レポートをメールで受信することを推奨 – 健全性を正しく管理するために、チェックの仕組みを健全に保つのが重要 ▪ 自身もソフトウェアなので、ワンクリックアップグレード でアップデートが可能
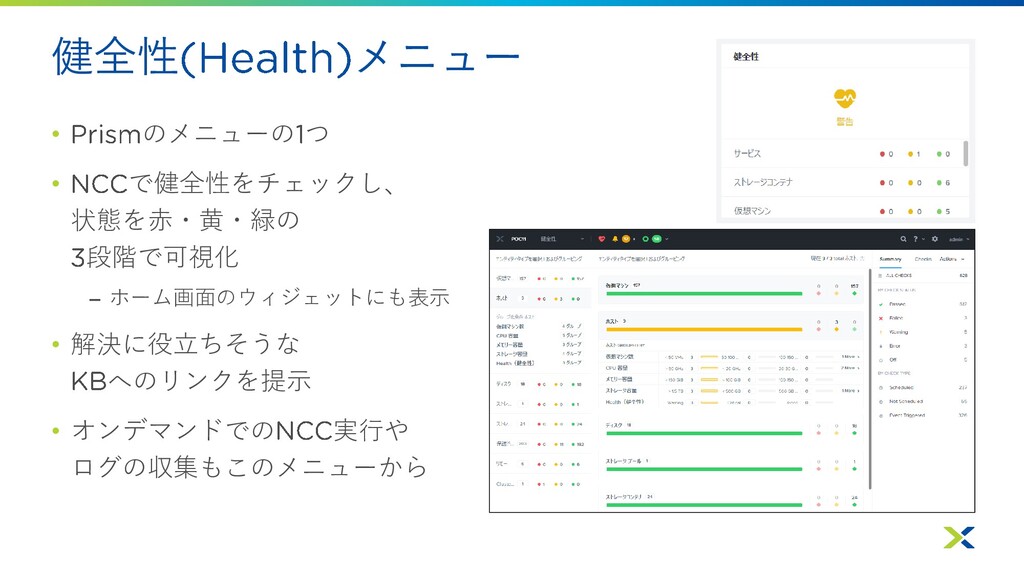
健全性 メニュー • のメニューの つ • で健全性をチェックし、 状態を赤・黄・緑の 段階で可視化 –
ホーム画面のウィジェットにも表示 • 解決に役立ちそうな へのリンクを提示 • オンデマンドでの 実行や ログの収集もこのメニューから
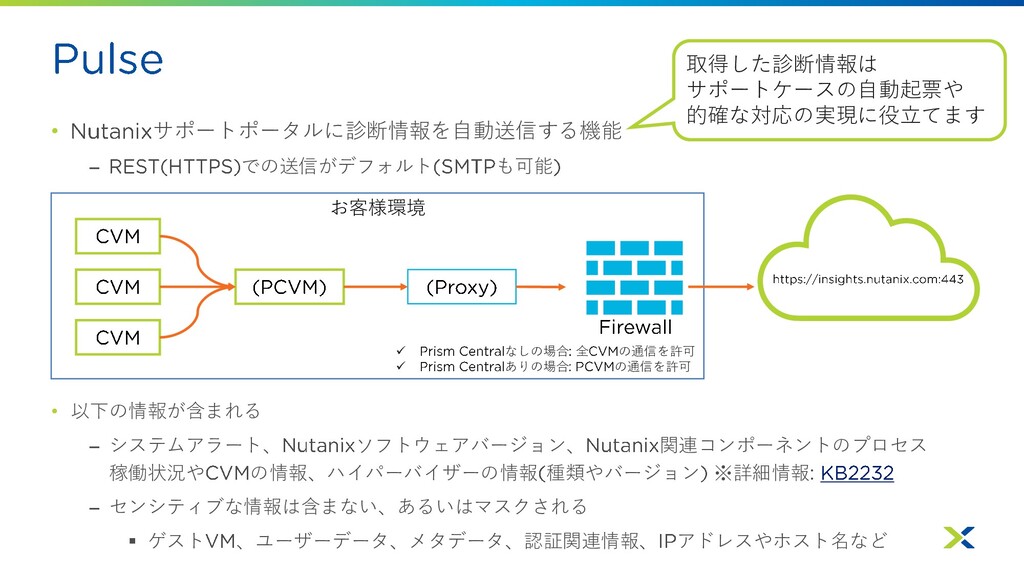
• サポートポータルに診断情報を自動送信する機能 – での送信がデフォルト も可能 • 以下の情報が含まれる – システムアラート、 ソフトウェアバージョン、
関連コンポーネントのプロセス 稼働状況や の情報、ハイパーバイザーの情報 種類やバージョン ※詳細情報 – センシティブな情報は含まない、あるいはマスクされる ▪ ゲスト 、ユーザーデータ、メタデータ、認証関連情報、 アドレスやホスト名など お客様環境 ✓ なしの場合 全 の通信を許可 ✓ ありの場合 の通信を許可 取得した診断情報は サポートケースの自動起票や 的確な対応の実現に役立てます
• 分析機能を備えたサポートポータル – 複数のサイトやクラスターに関する 健全性やサポートケース一元的に表示 – 健全性に関する予兆検知 – 推奨される対応方法の提示 –
サポートケースの自動作成 – サポートケース関連ログの自動採取 • 要件 – が有効化されていること
障害検知 サポート担当者による障害認知 • システム側が検知するだけでなく、 それをサポート担当に知らせる仕組みが必要 – のダッシュボードや健全性メニューの目視 – メール通知 –
– のノーコード自動化機能 によるアラートの外部通知 ▪ ▪ ▪
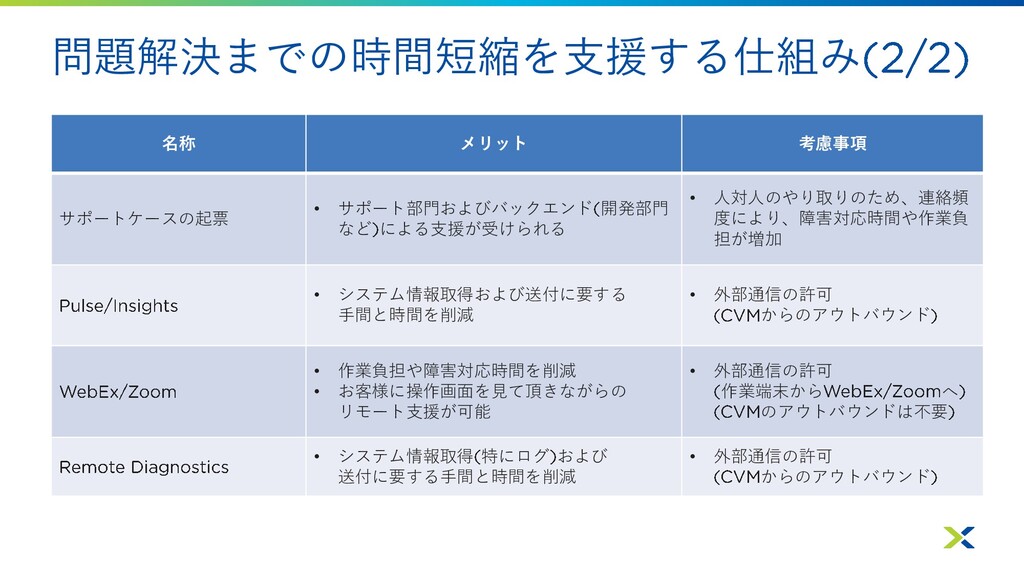
問題解決までの時間短縮を支援する仕組み 名称 概要 主なタイミング サポートケースの起票 にて手動で 起票 、アラートメール、 トラップなど により異常を確認し、復旧にはサポートエンジ
ニアの支援が必要と判断したとき システム情報を自動的に サポートに送信 • 構成変更や障害:即時 • メトリック: ~ 分毎 • 構成情報: 時間毎 お客様端末を介してサポートエンジ ニアが代理で操作 問題解決に向けて対象システムの 操作が必要な際 サービスによる ログや構成情報の自動収集 の回線を利用 ケース対応時にオンデマンドで ユーザーの許可を得て サポートが取得
問題解決までの時間短縮を支援する仕組み 名称 メリット 考慮事項 サポートケースの起票 • サポート部門およびバックエンド 開発部門 など による支援が受けられる
• 人対人のやり取りのため、連絡頻 度により、障害対応時間や作業負 担が増加 • システム情報取得および送付に要する 手間と時間を削減 • 外部通信の許可 からのアウトバウンド • 作業負担や障害対応時間を削減 • お客様に操作画面を見て頂きながらの リモート支援が可能 • 外部通信の許可 作業端末から へ のアウトバウンドは不要 • システム情報取得 特にログ および 送付に要する手間と時間を削減 • 外部通信の許可 からのアウトバウンド
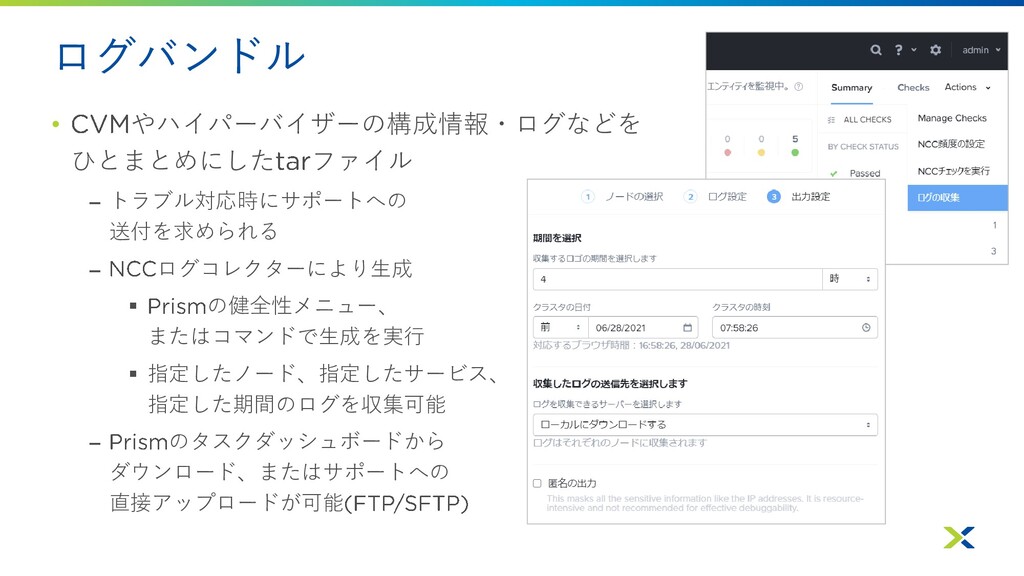
ログバンドル • やハイパーバイザーの構成情報・ログなどを ひとまとめにした ファイル – トラブル対応時にサポートへの 送付を求められる – ログコレクターにより生成
▪ の健全性メニュー、 またはコマンドで生成を実行 ▪ 指定したノード、指定したサービス、 指定した期間のログを収集可能 – のタスクダッシュボードから ダウンロード、またはサポートへの 直接アップロードが可能
ダークサイト運用ってどうなの? • ダークサイト=すべての機器が一切インターネットに接続できない環境 – 日本ではありがち カジュアルにこの構成を選びすぎでは – 海外でも無くはないが 政府機関、国防系などがメインであまり多くはない –
サポート支援機能の利用が制限されるため、相対的に問題解決の難易度が上がったり、 解決までの時間が長くなったりするなどのデメリットがある 目を逸らしてはいけない • 管理系ネットワーク構成の選択肢 特定の通信元から 特定の通信先への 特定ポートでの 通信を許可する インターネットへの アクセスを 完全に遮断する どの機器も自由に インターネットに 接続可能!
【必読!】サポートドキュメント日本語版 • 実際に問題が起きたときに慌てないために、この資料で紹介していない項目も含め、 ひととおり一度は目を通し、可能な範囲で予行練習をしてみることをお勧めします! – • ドキュメントの例 – サポートポータルのユーザー登録 –
サポートケースのプライオリティの定義と対応時間 – を使用したリモートサポート – アップグレードに関する – クラスターの健全性確認 – ログの取得方法 – アラートメールの設定 – サポートへファイルを送付する – ホストとクラスターの停止・起動手順 – 特に重要度の高い 項目以上を掲載中
ソフトウェアを サポート対象のバージョンに保つ
稼働中の システムへの 影響が怖い? ソフトウェアの塩漬けってどうなの? 数年後に発動する 時限爆弾的バグ 新たな脆弱性 新たな攻撃手法 更新による 互換性の問題が
事前調査で判明? アップデートの 作業コストを 抑えたい? • レガシーシステムのために 全体をリスクに晒すことを 許容できるか • あまりに多ければレガシー 隔離用の基盤も検討 • 重要度が低い場合は廃止も 検討 • 攻撃を受けたときの 損害額や信頼失墜リスク のほうがはるかに大きい • なら数クリッ クでアップグレード可能 • ならローリン グ 輪番 で更新 ✓ ゲスト は無停止 ✓ 最大 ノード分のリソー ス減をあらかじめ想定 • 仮に更新処理が中断した場 合もゲスト は動作継続 ✓ 更新処理の完了支援を サポートに依頼できる よう事前に準備 更新すべき理由 外的要因・制御不能 塩漬けしたい理由 社内事情・調整面倒
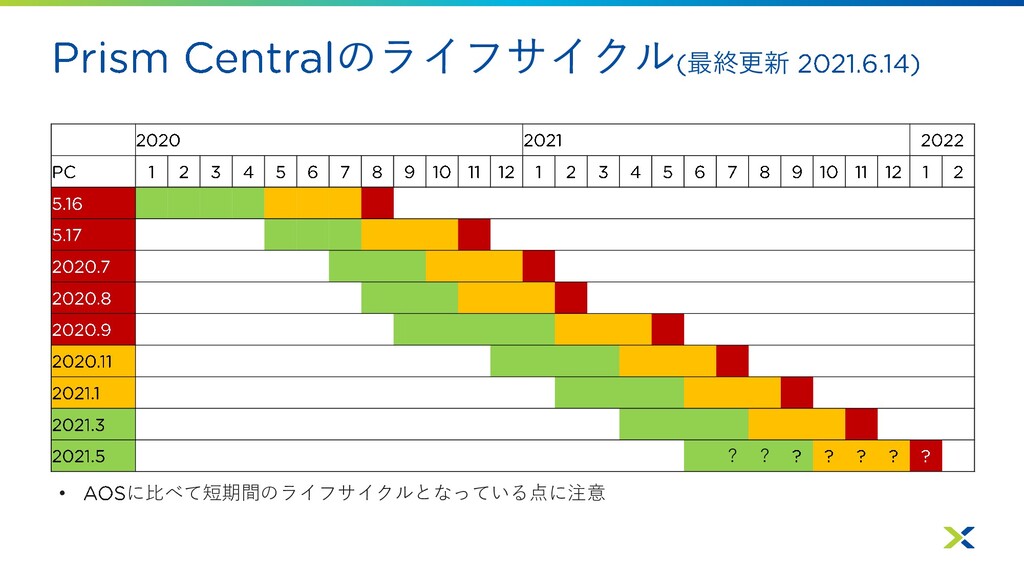
のサポートライフサイクル 最終更新 • 緑 :現行 メンテナンス対象 • 黄 : メンテナンス終了、サポート対象
• 赤 : サポート終了 • :現時点でまだ明記されていない部分 製品ライフサイクル情報一覧 およびアップデート関連の 2020 2021 2022 1 2 3 4 5 6 7 8 9 10 11 12 1 2 3 4 5 6 7 8 9 10 11 12 1 2 3 4 5 5.10 LTS 5.15 LTS 5.16 STS 5.17 STS 5.18 STS 5.19 STS 5.20 LTS ? ? ? ? ? ? ? ? ? ? ? ? 6.0 STS ? ? ? ? ? ?
• や 、 等のライフサイクルは、 のライフサイクルとは異なりますのでご注意ください – 製品ごとのライフサイクル ▪ ▪ と
のバージョン互換性には注意すること ▪ 実績として、 の互換は幅が広い傾向 ▪ は に紐づくが、 と直接的には紐づかない – との対応関係については も関わる ▪ – 基本的には → → →その他 利用 の順で更新するのがセオリー
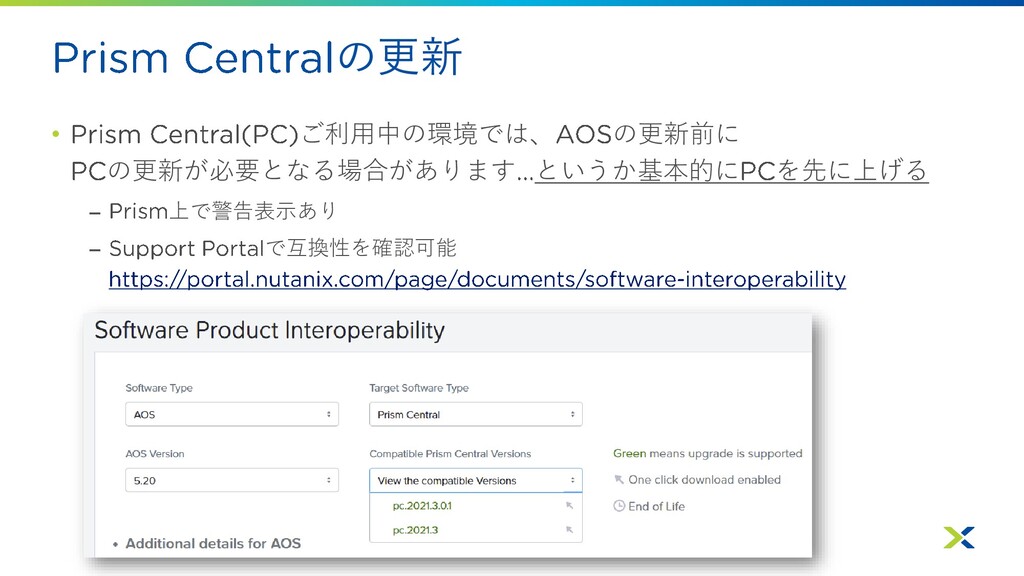
の更新 • ご利用中の環境では、 の更新前に の更新が必要となる場合があります というか基本的に を先に上げる – 上で警告表示あり –
で互換性を確認可能
のライフサイクル 最終更新 ? ? • に比べて短期間のライフサイクルとなっている点に注意
のライフサイクル 最終更新 • とのバージョン互換性は厳しくないが、 自身のライフサイクルには注意
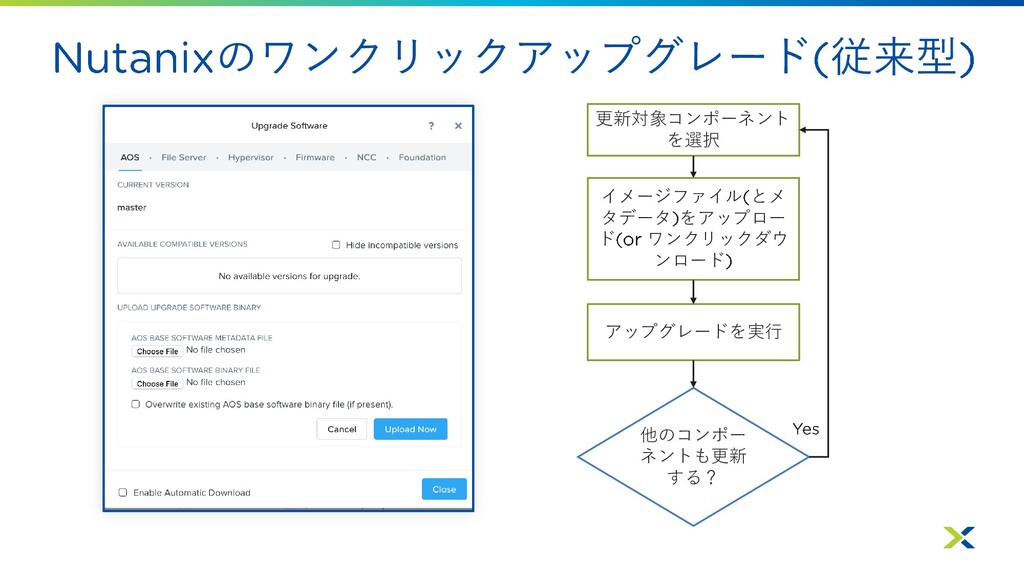
のワンクリックアップグレード 従来型 更新対象コンポーネント を選択 イメージファイル とメ タデータ をアップロー ド ワンクリックダウ
ンロード 他のコンポー ネントも更新 する? アップグレードを実行
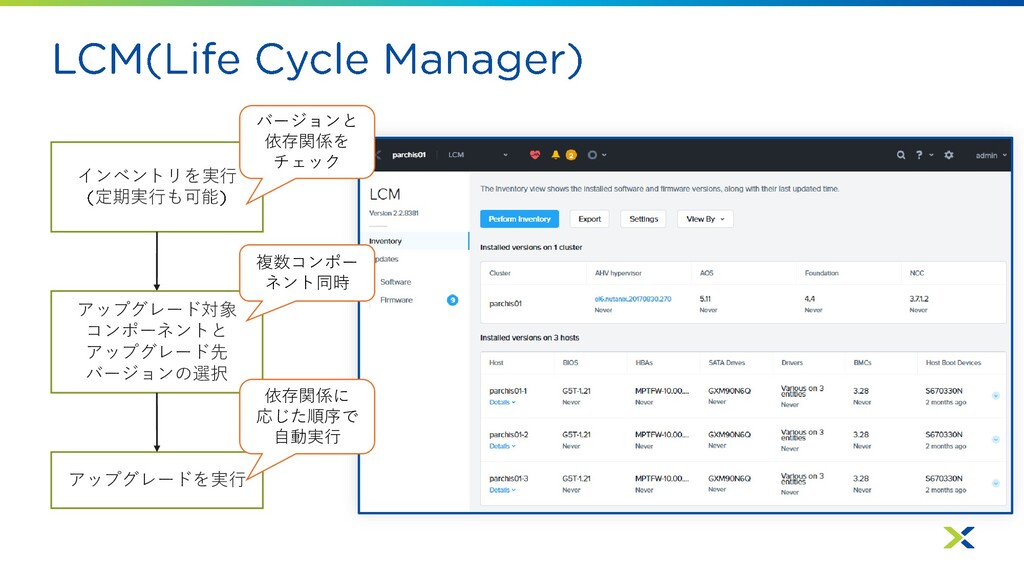
インベントリを実行 定期実行も可能 アップグレード対象 コンポーネントと アップグレード先 バージョンの選択 アップグレードを実行 バージョンと 依存関係を チェック
複数コンポー ネント同時 依存関係に 応じた順序で 自動実行
に関する備考 • インターネットへのアウトバウンド通信が可能な場合 – および の以下の通信を許可 ▪ 、ポート ▪ 、ポート
• ダークサイト インターネットへのアウトバウンド通信不可 の場合 – 内部 サーバーを建てて以下のファイルをホストする必要あり ▪ ファイル 依存関係を定義した 大量の ファイルを固めた ファイル ▪ ファイルが正しいものであることをチェック ▪ 各プロダクトの 更新用データを固めた ファイル – で一部コンポーネントの直接アップロード対応を開始
ソフトウェア更新のポイント • 各バージョンのサポート期間の都合上、 最低でも年に 回程度の アップグレードを想定 – 約 年半 と
約半年 が存在する点に注意 – 最新機能を追いかける場合を除いては は で – は年に 回程度の更新を見込む • アップグレード前に、システムの健全性をチェックし、 問題がある場合はまずそれを解消してから • システム稼働中で問題ないが、高負荷なバッチの真っ最中や、 明らかに業務負荷がピークを迎えている時間帯は避ける
特に重要度や影響度の高い情報の確認 • – ▪ 既知の重大な問題の詳細 および回避方法 – ▪ 既知の脆弱性の詳細 および対策方法
– で更新情報の 通知受け取り設定が可能 ▪ 画面右上 ▪ メールおよび の通知アイコン
リソース枯渇を防ぐ
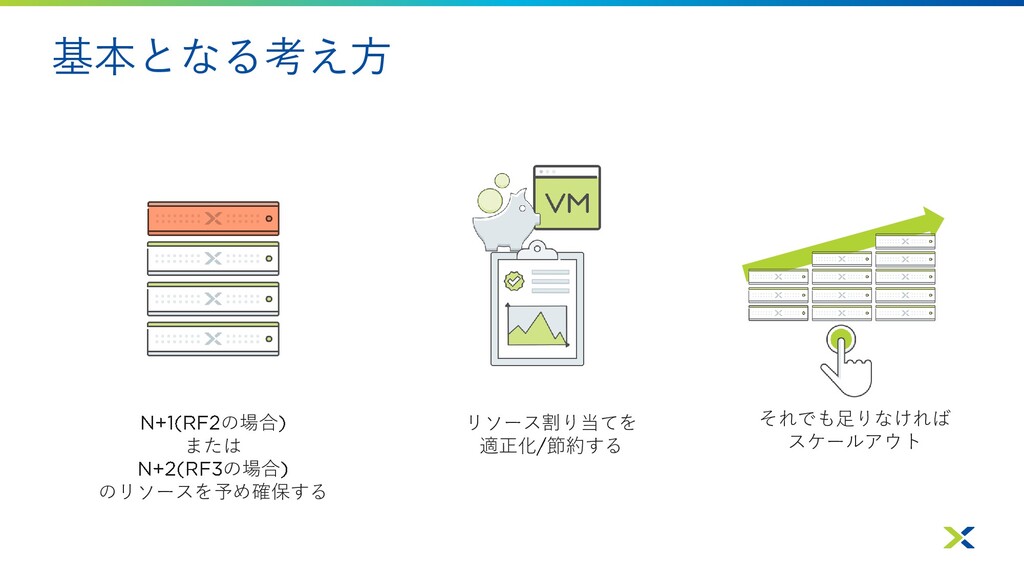
基本となる考え方 の場合 または の場合 のリソースを予め確保する リソース割り当てを 適正化 節約する それでも足りなければ スケールアウト
を確保する理由 • ノードの停止や再起動を伴うメンテナンス時に 仮想マシンを止めずに済むようにするため • ノードダウンが発生した場合に、 機能で 仮想マシンを再稼働させるリソースを確保するため • ノードダウン発生中にもデータの冗長性
多重度 を 確保するため • に関しては、オーバーコミットが可能なので 余剰分の確保はメモリやディスクほど厳密に行わないケースもある パフォーマンス低下を避けたい場合はしっかり確保
リソース割り当ての適正化 • は の稼働状況を学習し、リソース割り当てが 適正でないと考えられる をリストアップしてくれる • 休眠状態 日間の状態で判定 –
ずっと電源がオフ – 電源オンだが 合計 未満、かつ通信が 未満 • 過剰な割り当て 下記項目を 日間、 条件で判定 – 中程度 – シビア 重度 • リソース不足 下記項目を 日間、 条件で判定 – 中程度 – シビア 重度 • 周囲に悪影響を及ぼす 下記の状態が 時間以上継続する場合 –
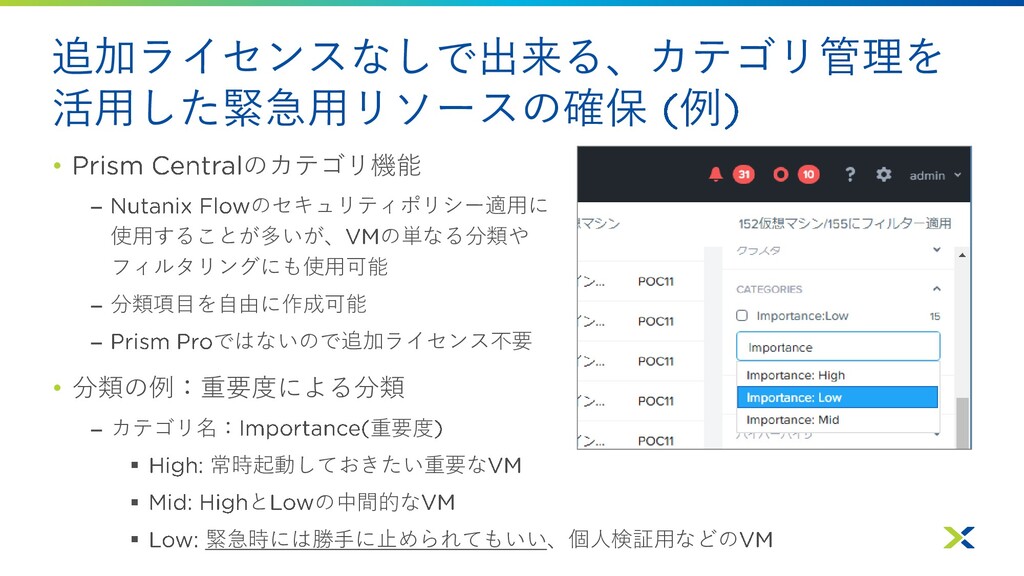
追加ライセンスなしで出来る、カテゴリ管理を 活用した緊急用リソースの確保 例 • のカテゴリ機能 – のセキュリティポリシー適用に 使用することが多いが、 の単なる分類や フィルタリングにも使用可能
– 分類項目を自由に作成可能 – ではないので追加ライセンス不要 • 分類の例:重要度による分類 – カテゴリ名: 重要度 ▪ 常時起動しておきたい重要な ▪ と の中間的な ▪ 緊急時には勝手に止められてもいい、個人検証用などの
それでも足りなければスケールアウト 導入時 年後 年後 年後 年後 年後 年後 数 層型仮想化基盤は拡張しづらい
• 将来のリソース需要を予測し一括投資 ➢ 初期導入コストの大きさがプロジェクトを阻害 ➢ 設計・構築に長い時間を要する ➢ 「過剰投資」 「過少予測によるリソース枯渇」の発生 将来を 予測して 一括投資 なら拡張しやすい • 最小 ノードでスタート • 投資のタイミングを分散 • 過剰な安全マージンを抑制 • 拡張時点の最新 を導入 需要増に 合わせて 少しずつ投資 例 投資と実際の利用 数
スモールスタート&スケールアウトのポイント • クラウド的なインフラ投資・計画の考え方にシフトする – 必要な時に、必要な分だけ – ただし は 単位ではなく、ノード単位での投資となる –
ノード調達のリードタイムを考慮すると、突然の枯渇には注意。 のキャパシティ需要予測機能が役立つ。 • 層型仮想化基盤とは、システム拡張時の ストレージ性能に対する影響が「逆」であることを理解する – 層型 台の共有ストレージを利用するサーバーが増えるため性能リスクあり – 分散ストレージを提供するサーバーが増えるため性能が向上する • クラスター拡張前に、システムの健全性をチェックし、 問題がある場合はまずそれを解消してから
まとめ
まとめ 色々お伝えしましたが要するにコレ ✓ 問題をすぐに検知&認知する準備を ✓ トラブルが発生したときは サポートとのスムーズな コミュニケーションが最重要 ✓ ちゃんとアプデしよう
✓ リソースは常に をキープ
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}