prezentacjach • Przestawia 2 przykłady transformacji, których efektem są stany słabo zależne statystycznie od czynników je wywołujących. Przy czym skupimy się na rozkładzie jednorodnym oraz gaussa.
s posiada jednorodny rozkład prawdopodobieństwa jeśli: P(s=s l )=const. gdzie l=1,2,…,L bądź w przypadku zmiennej ciągłej p(s)=const. Vs W dalszej części będziemy rozważać przypadek ciągły.
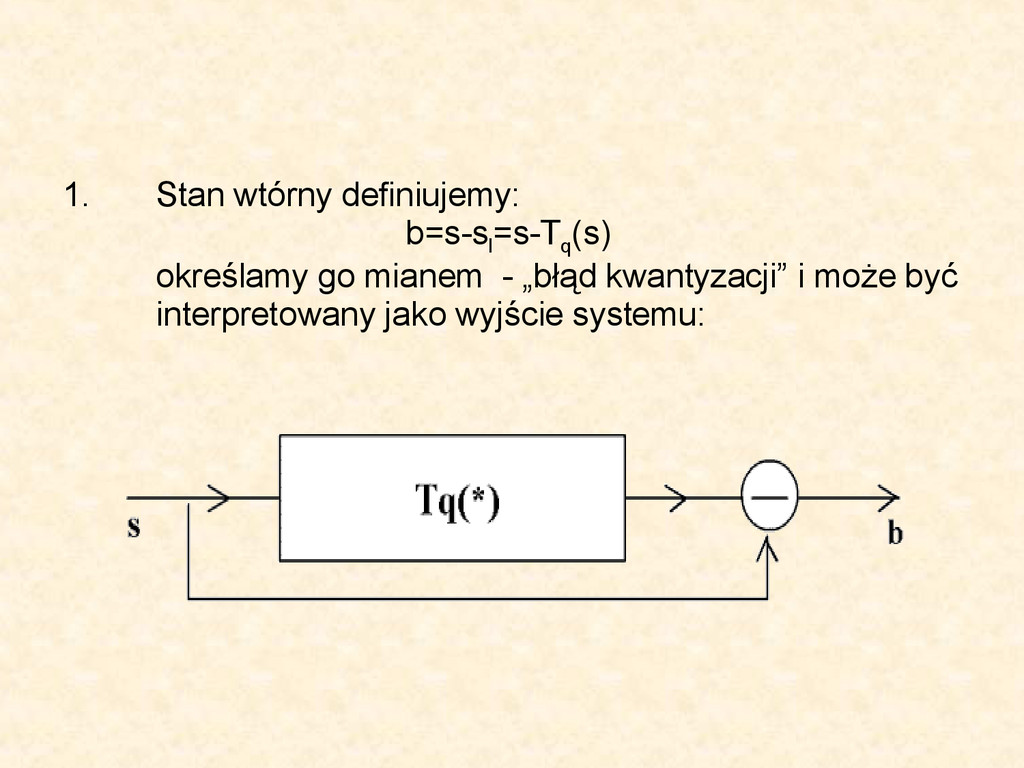
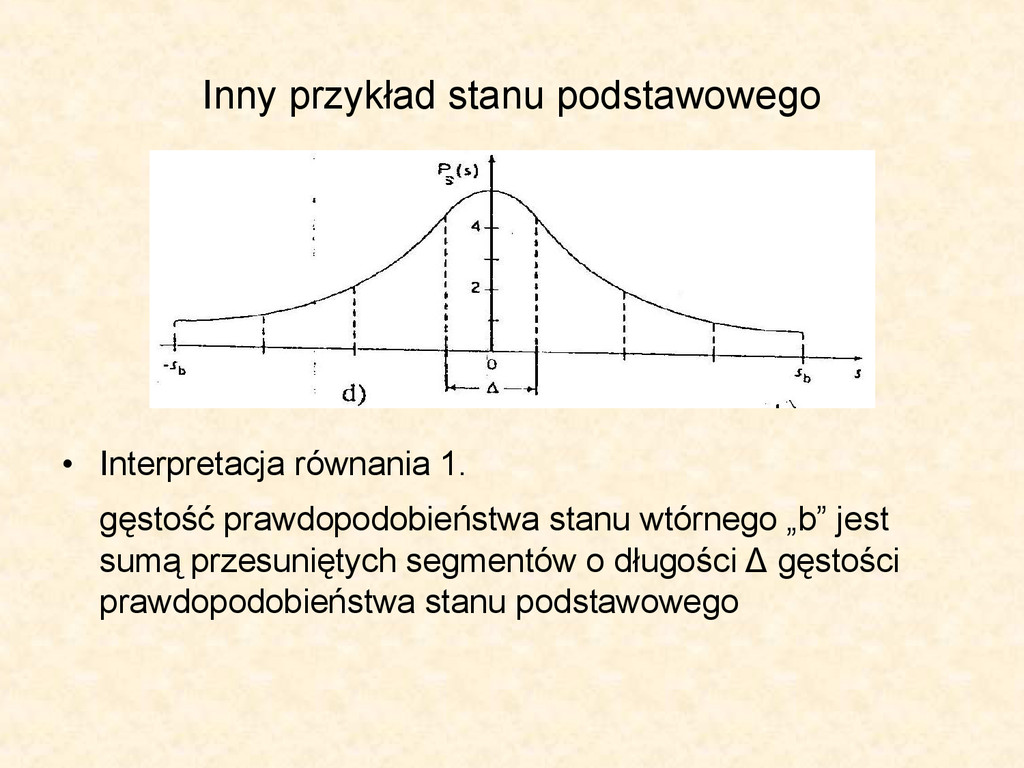
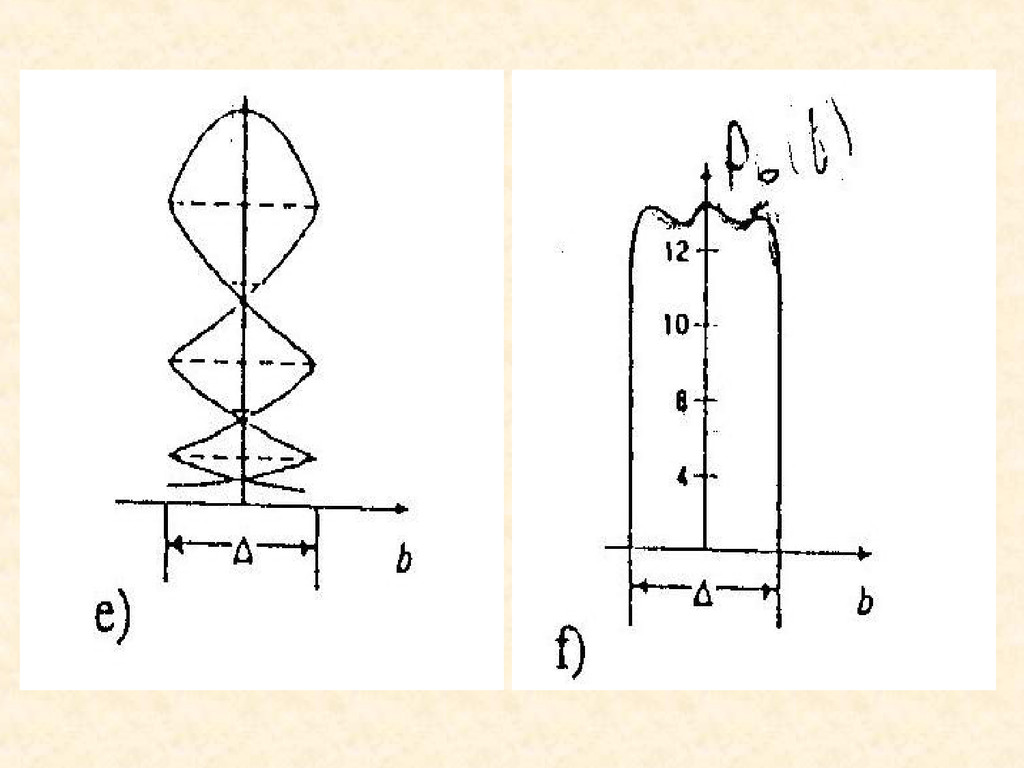
, s b ) • Stan postawowy może być rozważany jako realizacja ciągłej zmiennej losowej s, a przez p(s) oznaczamy jej gęstość prawdopodobieństwa • Używając jednorodnej kwantyzacji - T q (۰) przekształcamy ciągłą zmienną „s” w ziarnistą zmienna „w” przyjmującą potencjalne wartości: s l , l=1,2,…,L czyli w=T q (s) • Reguła kwantyzacji: w = s l jeżeli | s-s l | ≤ | s-s k | V k≠l gdzie s l = [l - (L + 1)/2]Δ Δ=2s b /L
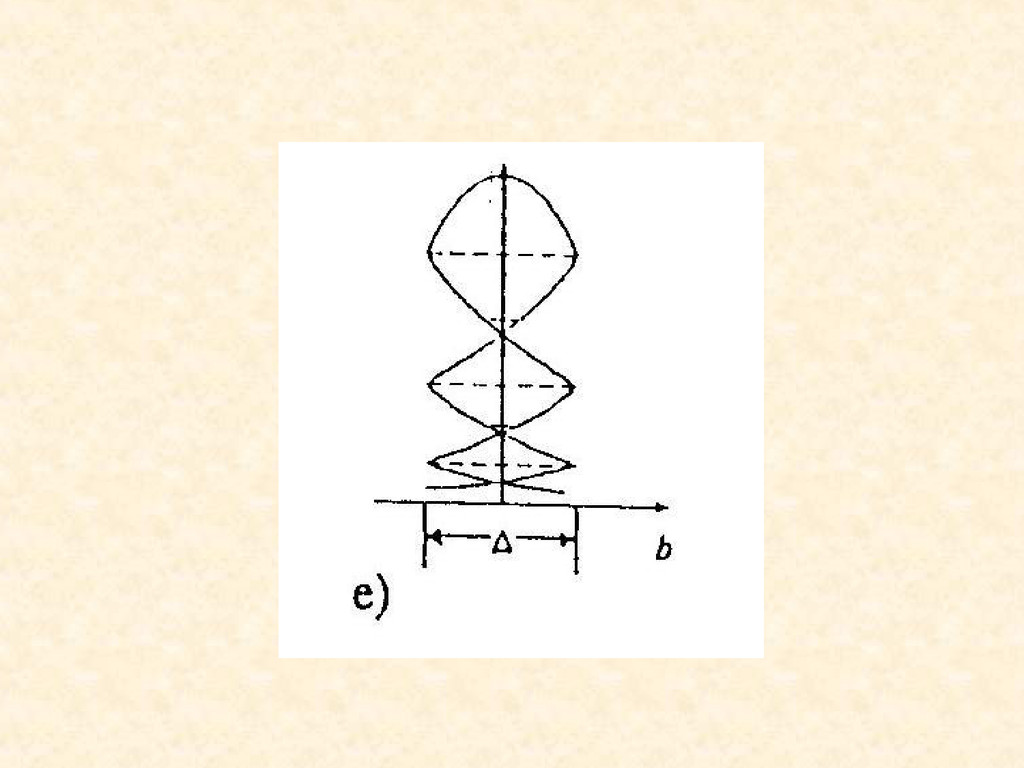
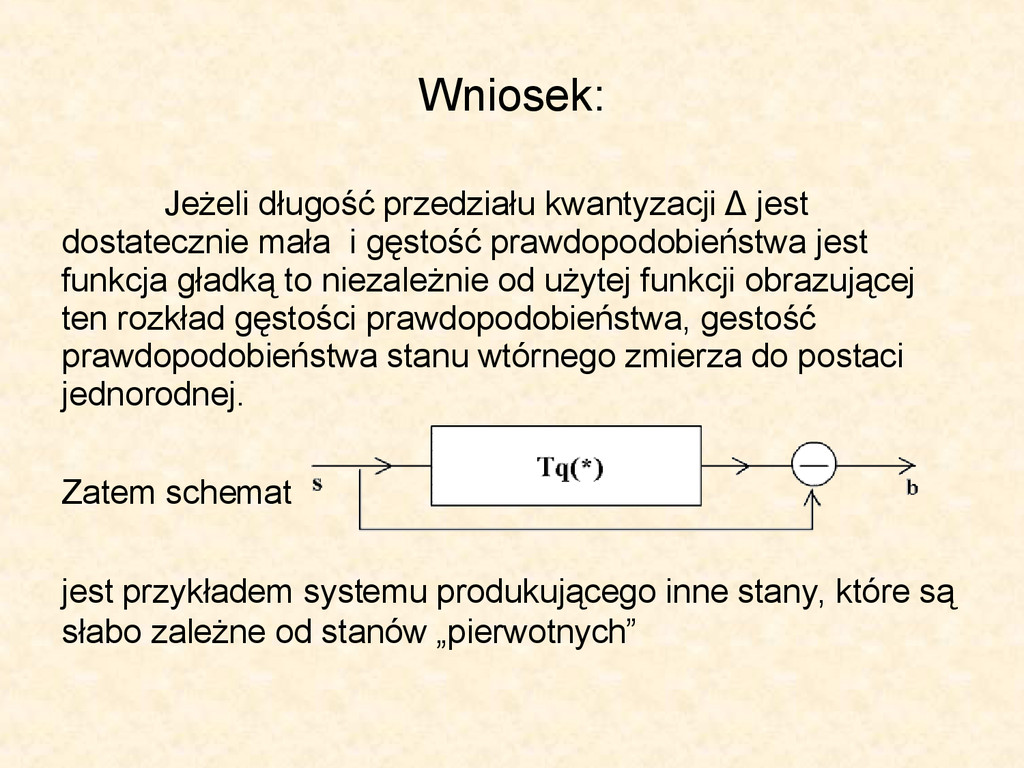
gęstość prawdopodobieństwa jest funkcja gładką to niezależnie od użytej funkcji obrazującej ten rozkład gęstości prawdopodobieństwa, gestość prawdopodobieństwa stanu wtórnego zmierza do postaci jednorodnej. Zatem schemat jest przykładem systemu produkującego inne stany, które są słabo zależne od stanów „pierwotnych”
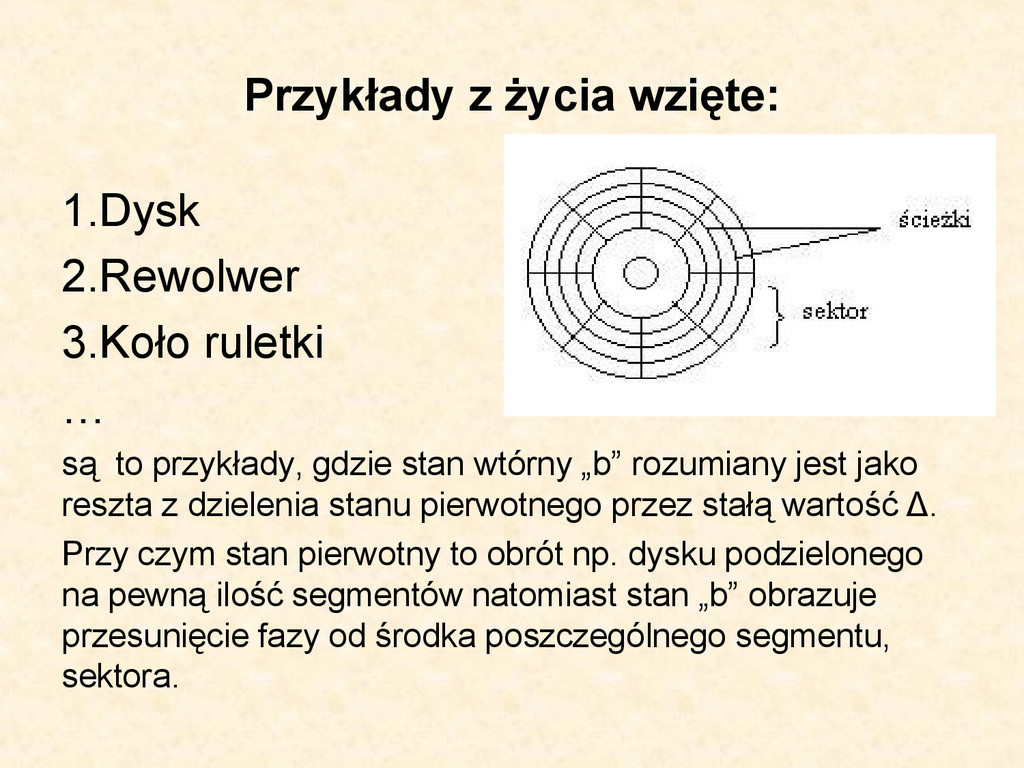
to przykłady, gdzie stan wtórny „b” rozumiany jest jako reszta z dzielenia stanu pierwotnego przez stałą wartość Δ. Przy czym stan pierwotny to obrót np. dysku podzielonego na pewną ilość segmentów natomiast stan „b” obrazuje przesunięcie fazy od środka poszczególnego segmentu, sektora.
zmienne losowe S(i) mają Es(i) = 0, ich wariancje σ2[s(i)] są podobnego rzędu wielkości* i ponadto zmienne S(i) spełniają dodatkowe szerokie założenia, to wtedy dla dużych I gęstość prawdopodobieństwa znormalizowanej zmiennej losowej S/√i zmierza do gaussowskiego rozkładu prawdopodobieństwa. S=∑ i=1 I si
dwie stałe A 1 >0 i A 2 >A 1 takie, że A 1 < σ2[s(i)]< A 2 dla wszystkich i. Rozkład prawdopodobieństwa: (gdzie G=[G(m, k)]) nazywamy K-wymiarowym gaussowskim rozkładem prawdopodobieństwa; - determinowany przez czynniki a(k) and G(m, k), związane z momentami odpowiadającej K-wymiarowej zmiennej losowej: S = {s(k), k =1, 2, ..., K}
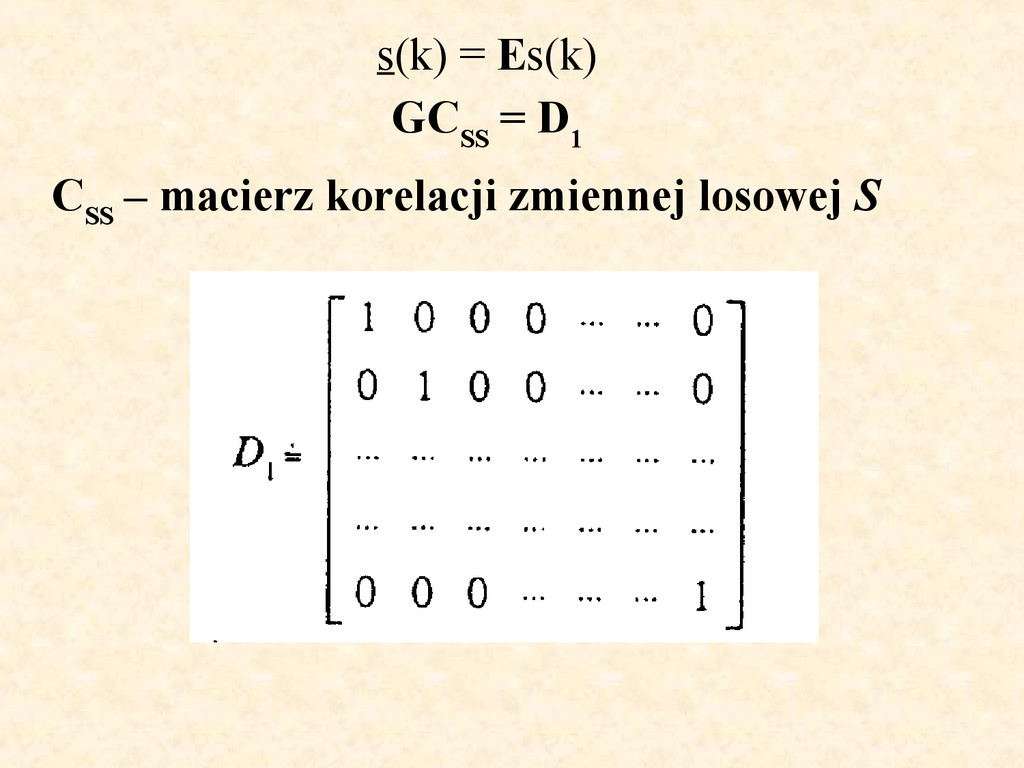
korelacji C, więc wzór (4.5.51b) można zapisać w postaci A=C SS -1 Z (4.5.25a) i (4.5.15b) wnioskujemy następująco: K-wymiarowy rozkład prawdopodobieństwa jest dokładnie określony przez średnie składników odpowiadającej K-wymiarowej zmiennej losowej i ich macierz korelacji.
są nieskorelowane (c(m, k) = 0 ; dla wszystkich m różnych od k) A2. Wartości średnie Es(k) = 0 A3. Wariancje σ2[S(k)] = σ2 = const Z A1 wynika, że wszystkie elementy macierzy korelacji C SS leżące poza główną przekątną są zerowe.
przekształcić wcześniejszy wzór: 4.5.19a A = (2πσ)2 Widzimy, że gęstość prawdopodobieństwa nieskorelowanych zmiennych gaussowskich równa jest produktowi gęstości prawdopodobieństwa zmiennych składowych. Innymi słowy Jeśli zmienne gaussowskie są nieskorelowane, to są one statystycznie niezależne.
jako suma dużej liczby niezależnych zbiorów składników o podobnej rzędzie wielkości wariancji, to znormalizowana suma ma w przybliżeniu wielowymiarową gęstość prawdopodobieństwa
z wielu jednostkowych impulsów generowanych przez zderzenia elektronów. Tak więc, bez wnikania w szczegóły dotyczące właściwości pojedynczych impulsów, dochodzimy do wniosku, że ciąg próbek szumu termicznego ma wielowymiarowy rozkład gaussowski. Z dużą dokładnością dowodzą tego eksperymenty.
zmiennych gaussowskich, wystarczy tylko znać ich średnie wartości i macierz korelacji (4.5.21) • zmienne gaussowskie poddane przekształceniom liniowym dają w wyniku zmienna gaussowską • -->
pod warunkiem, że zestaw innych składników jest znany, jest gaussowskim rozkładem prawdopodobieństwa. Te właściwości w powiązaniu z równaniem (4.4.3) pozwalają zredukować obliczenia rozkładu prawdopodobieństwa liniowej kombinacji zmiennej gaussowskiej i łącznych i warunkowych rozkładów takiej liniowej kombinacji do prostych przekształceń macierzowych.
s(2), … , s(I) } jest obserwacją zmiennych losowych S tr = { s(1), s(2), … , s(I) } gdzie łańcuch stanów przedstawia statystyczną regularność [tr – train ] 2. zbiór potencjalnych wartości każdego elementarnego stanu jest taki sam i potencjalnymi stanami są s l , l = 1, 2, … , L 3. zmienne losowe s(i) dla każdego i są statystycznie niezależne 4. M(s l , I) oznacza liczbę wystąpień stanu s l w łańcuchu S tr
δ) że dla I > I(ε, δ) zbiór S (I) nieograniczonego łańcucha S tr może być podzielony na dwa podzbiory S ty i S nty tak, że dla każdego łańcucha mamy : (1) oraz S S ty tr M s l , I I P s l s l , l ) ( nty tr S S P
w łańcuchu S tr . • Tak więc w każdym ciągu należącym do zbioru S ty częstość występowania każdego elementarnego stanu s l jest z dokładnością lepszą niż ε bliska prawdopodobieństwu stanu s l . Taki cąg nazywamy typowym - zgodnie z notacja S ty • Zbiór S nty składa się z łańcuchów dla których częstość występowania stanów różni się przynajmniej o ε. Taki ciąg nazywamy nietypowym. • Prawdopodobieństwo jest sumą prawdopodobieństw wszystkich nietypowych ciągów I I s M l l I s P ) , ( * ) , ( ) S ( nty tr S P
prawdopodobieństwo każdego nietypowego ciągu jest małe • Oznaczmy przez S tr ’ ciąg należący do zbioru S ty . Szacujemy prawdopodobieństwo (3) że ciąg S tr ’ jest wynikiem obserwacji ciągu zmiennych losowych Str ) ( nty tr S S P )] ( ' ) ( ),..., 2 ( ' ) 2 ( ), 1 ( ' ) 1 ( [ ) ' ( I s I s s s s s P S S P tr tr
• Po zlogarytmowaniu otrzymujemy i podzieleniu obu stron równania przez I: (5) • Wzór (*) zapiszemy w postaci: (6) gdzie | ε l | < ε. • Podstawiając powyższe równanie otrzymujemy: (7) ) ( 1 1 ] ) ( [ ) ( ' ) ( [ ) ' ( N s M l L l I i tr tr l s l s P i s i s P S S P ] ) ( [ log )] ( ' ) ( [ log 2 1 ) ( 1 2 1 ) ' ( log2 l L l I I s M I i I I S S P s l s P i s i s P l tr tr ] ) 1 ( [ ) , ( l I I s M s s P l l I S S P C s H tr )] 1 ( [ ) ' ( log 2
współczynnik C l definiujemy jako: (9) • Ze wzoru (7) dochodzimy do postaci: (10) L l l l s s P s l s P l s H 1 2 ] ) 1 ( [ ]} ) ( [ log { )] ( [ L l l l s s P C 1 2 ] ) 1 ( [ log 2 )] ( [ ) ' ( l s IH tr tr S S P
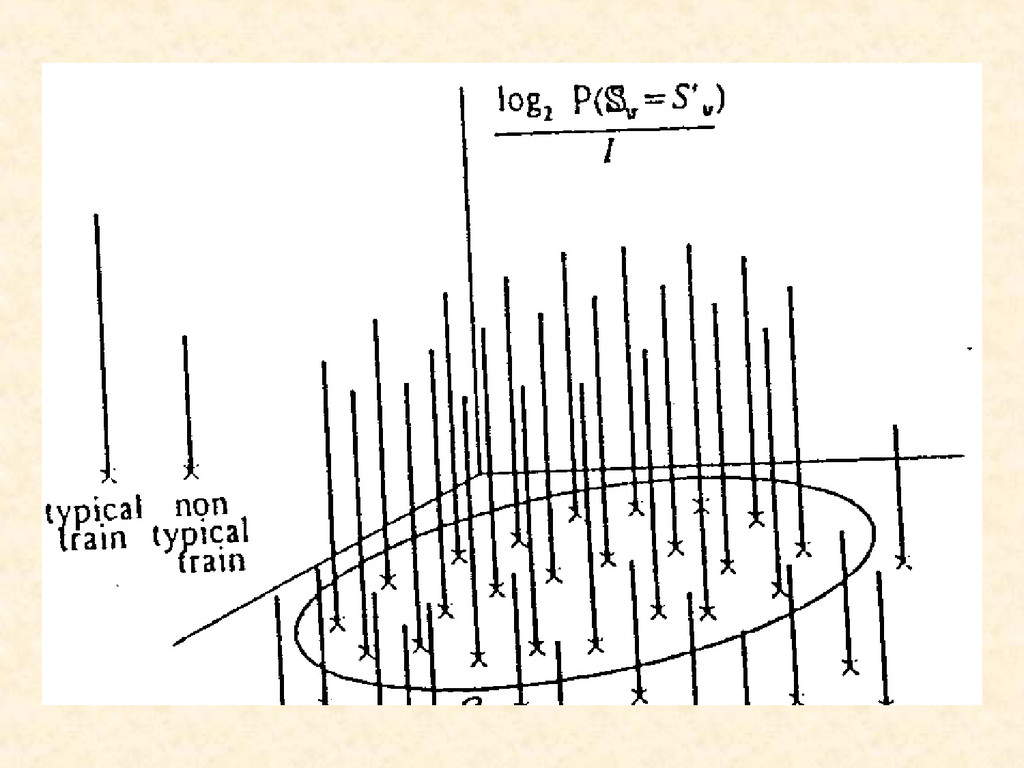
wszystkich możliwych ciągów S tr ={s(1),s(2), … , s(I)} wówczas wierzchołki tych linii utworzą dwa obszary: jeden „wysoki” obszar obrazujący zbiór S ty (z wysokością wyrażoną zależnością 10 i drugi obszar niski (o poziomie bliskim zeru) określający zbiór S nty - nietypowych ciągów.
możemy zmodyfikować do postaci ciągłej jeżeli zamiast P(S=s) weźmiemy gęstość prawdopodobieństwa p(S) typowego ciągu. Wówczas entropię zmiennej ciągłej przedstawi się jako równanie: • Dla zmiennych ciągłych chcąc zobrazować podział na ciagi typowe oraz nietypowe zauważymy znaczne skomplikowanie. Dla przykładu gdy gęstość prawdopodobieństwa p(s) wyrażona będzie funkcją gaussa wówczas zbiór S ty jest cienką, I – wymiarową kulistą powłoką. b a s s ds s p s p l s H ) ( )] ( log [ )] ( [ 2 L l l l s s P s l s P l s H 1 2 ] ) 1 ( [ ]} ) ( [ log { )] ( [
je stanem statystycznym i oznaczamy przez S STAT • W opisie tym zawiera się stan różnorodności SVAR stanu zewnętrznego i opis wag statystycznych: S STAT = { S VAR , W } = { SRT, MR, W }
•stan wewnętrzny • ogólne związki pomiędzy elementami stanów zewnętrznych •stan konkretny • stany wewnętrzne i zewnętrzne •stan różnorodności • zbiór potencjalnych form stanu konkretnego •stan statystyczny • jw. ale wraz ze związanymi wagami statystycznymi
stan wyższego rzędu • zbiór potencjalnych form meta stanu niższego rzędu, ewentualnie wraz z wagami statystycznymi •stan uogólniony • stany konkretne i metastany
zgrubny •Każdy ze stanów ma fundamentalną strukturę, często również makrostrukturę. Podstawowe struktury: wektor, tablica (funkcja ziarnistych argumentów), i funkcja argumentu(ów) ciągłych.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
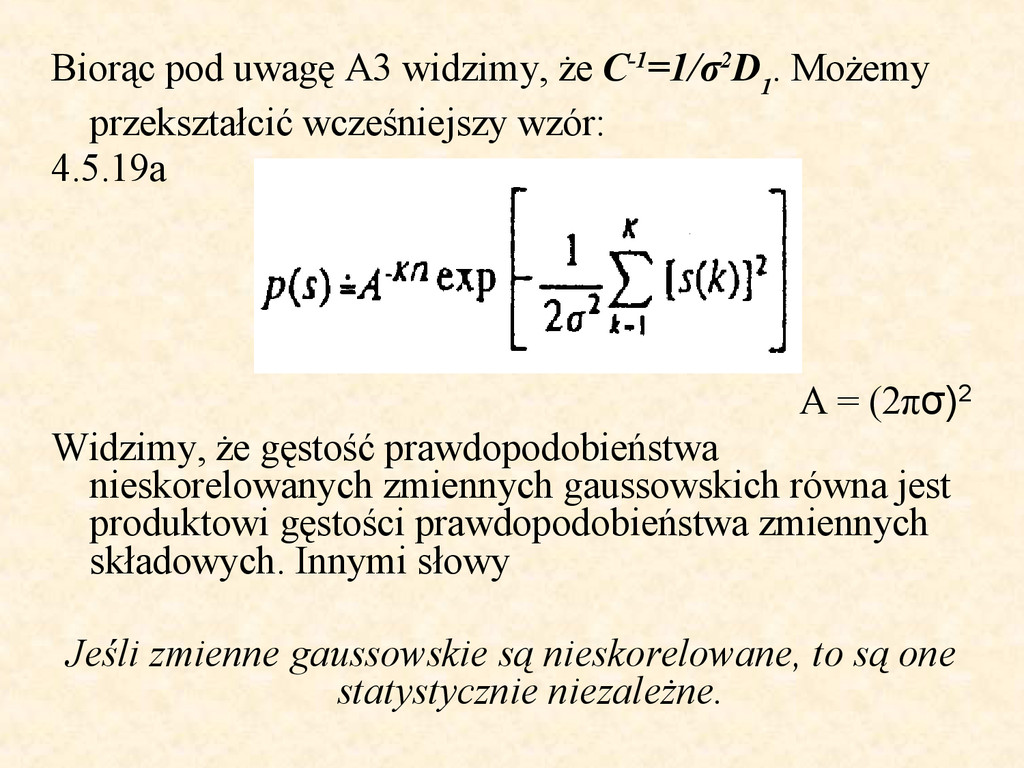{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
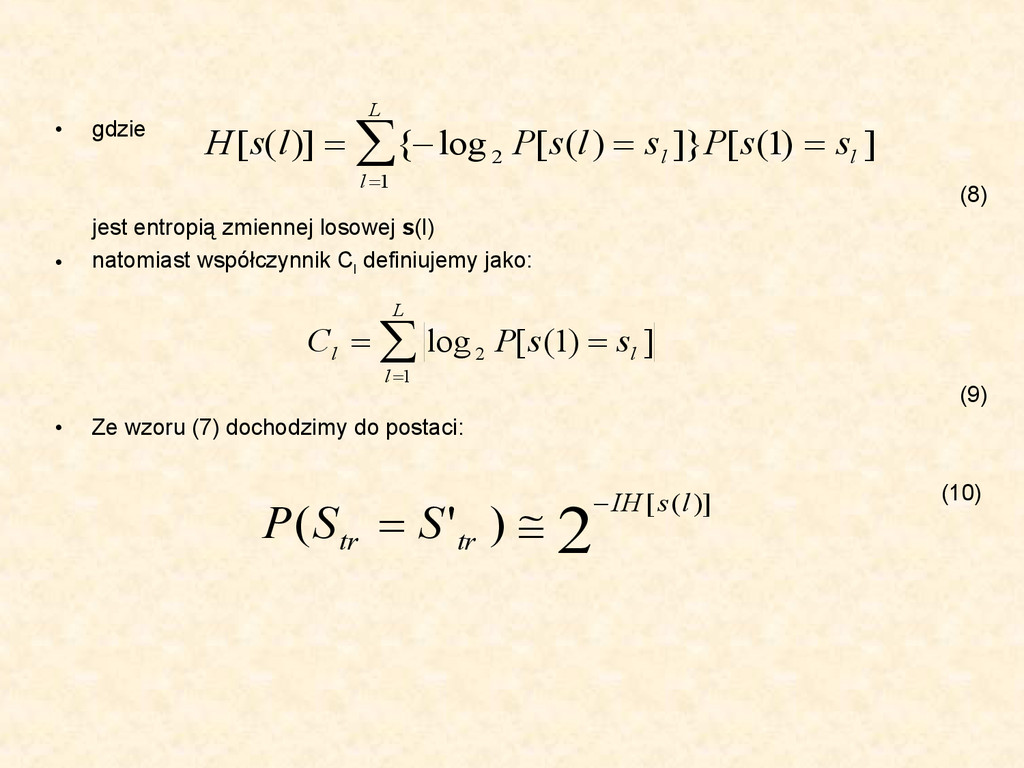{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}