Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
深層学習フレームワーク Chainerの特徴 @第5回 産総研人工知能セミナー「深層学習フレー...
Search
Yuya Unno
March 17, 2016
Technology
18
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
深層学習フレームワーク Chainerの特徴 @第5回 産総研人工知能セミナー「深層学習フレームワーク」
Yuya Unno
March 17, 2016
More Decks by Yuya Unno
See All by Yuya Unno
深層学習で切り拓くパーソナルロボットの未来 @東京大学 先端技術セミナー 工学最前線
unnonouno
0
29
深層学習時代の自然言語処理ビジネス @DLLAB 言語・音声ナイト
unnonouno
0
53
ベンチャー企業で言葉を扱うロボットの研究開発をする @東京大学 電子情報学特論I
unnonouno
0
50
PFNにおけるセミナー活動 @NLP2018 言語処理研究者・技術者の育成と未来への連携WS
unnonouno
0
20
進化するChainer @JSAI2017
unnonouno
0
30
予測型戦略を知るための機械学習チュートリアル @BigData Conference 2017 Spring
unnonouno
0
29
深層学習フレームワーク Chainerとその進化
unnonouno
0
31
深層学習による機械とのコミュニケーション @DeNA TechCon 2017
unnonouno
0
43
最先端NLP勉強会 “Learning Language Games through Interaction” @第8回最先端NLP勉強会
unnonouno
0
24
Other Decks in Technology
See All in Technology
キャリアの中で本を作る / Making a Book During Your Career
ak1210
0
130
SRE Next 2026 何でも屋からの脱却
bto
0
480
人を動かすのは時間ではなく、納得感 〜新任EMが入社3ヶ月、組織を2回変えた話〜
kakehashi
PRO
3
200
LLMやAIエージェントをソフトウェアに組み込むプラクティス
shibuiwilliam
1
310
Control Planeで育てるBtoB SaaSの認証基盤 - SRE NEXT 2026
pokohide
1
2.1k
ruby.wasmとPicoRuby.wasmに対応した仮想DOMライブラリを作ってる話 #kaigieffect_kaigi
sue445
PRO
0
130
デジタル・デザイン構想 by Sayaka Ishizuka
y150saya
0
200
型は壁、Rustでもバグを直すな、表現できなくせよ
nwiizo
13
2k
AIを駆使した OSS脆弱性調査のすゝめ
saku0512
0
100
CSに"SLO"は要らない、経営層に"99.9%"は伝わらない - SREを全社に"翻訳"する3原則
cscengineer
PRO
1
4.3k
Gen3R: 3D Scene Generation Meets Feed-Forward Reconstruction
spatial_ai_network
0
110
Baseline対応のDOMの型定義を作った
uhyo
3
730
Featured
See All Featured
Designing Dashboards & Data Visualisations in Web Apps
destraynor
231
55k
First, design no harm
axbom
PRO
2
1.2k
How People are Using Generative and Agentic AI to Supercharge Their Products, Projects, Services and Value Streams Today
helenjbeal
1
230
The Invisible Side of Design
smashingmag
301
52k
Principles of Awesome APIs and How to Build Them.
keavy
128
18k
HDC tutorial
michielstock
2
740
Practical Tips for Bootstrapping Information Extraction Pipelines
honnibal
25
2k
A Guide to Academic Writing Using Generative AI - A Workshop
ks91
PRO
1
350
Color Theory Basics | Prateek | Gurzu
gurzu
0
390
Rebuilding a faster, lazier Slack
samanthasiow
85
9.6k
Code Reviewing Like a Champion
maltzj
528
40k
Six Lessons from altMBA
skipperchong
29
4.3k
Transcript
深層学習フレームワーク Chainerの特徴 (株)Preferred Infrastructure 海野 裕也 2016/03/17 第5回 産総研人工知能セミナー「深層学習フレームワーク」
⾃自⼰己紹介 海野 裕也 l -2008 東⼤大情報理理⼯工修⼠士 l ⾃自然⾔言語処理理 l 2008-2011
⽇日本アイ・ビー・エム(株)東京基礎研 l テキストマイニング、⾃自然⾔言語処理理の研究開発 l 2011- (株)プリファードインフラストラクチャー l ⾃自然⾔言語処理理、情報検索索、機械学習、テキストマイニングなど の研究開発 l 研究開発系案件、コンサルティング l JubatusやChainerの開発 l 最近は対話処理理 NLP若若⼿手の会共同委員⻑⾧長(2014-) 「オンライン機械学習」(2015, 講談社) 2
Chainer http://chainer.org/ 3
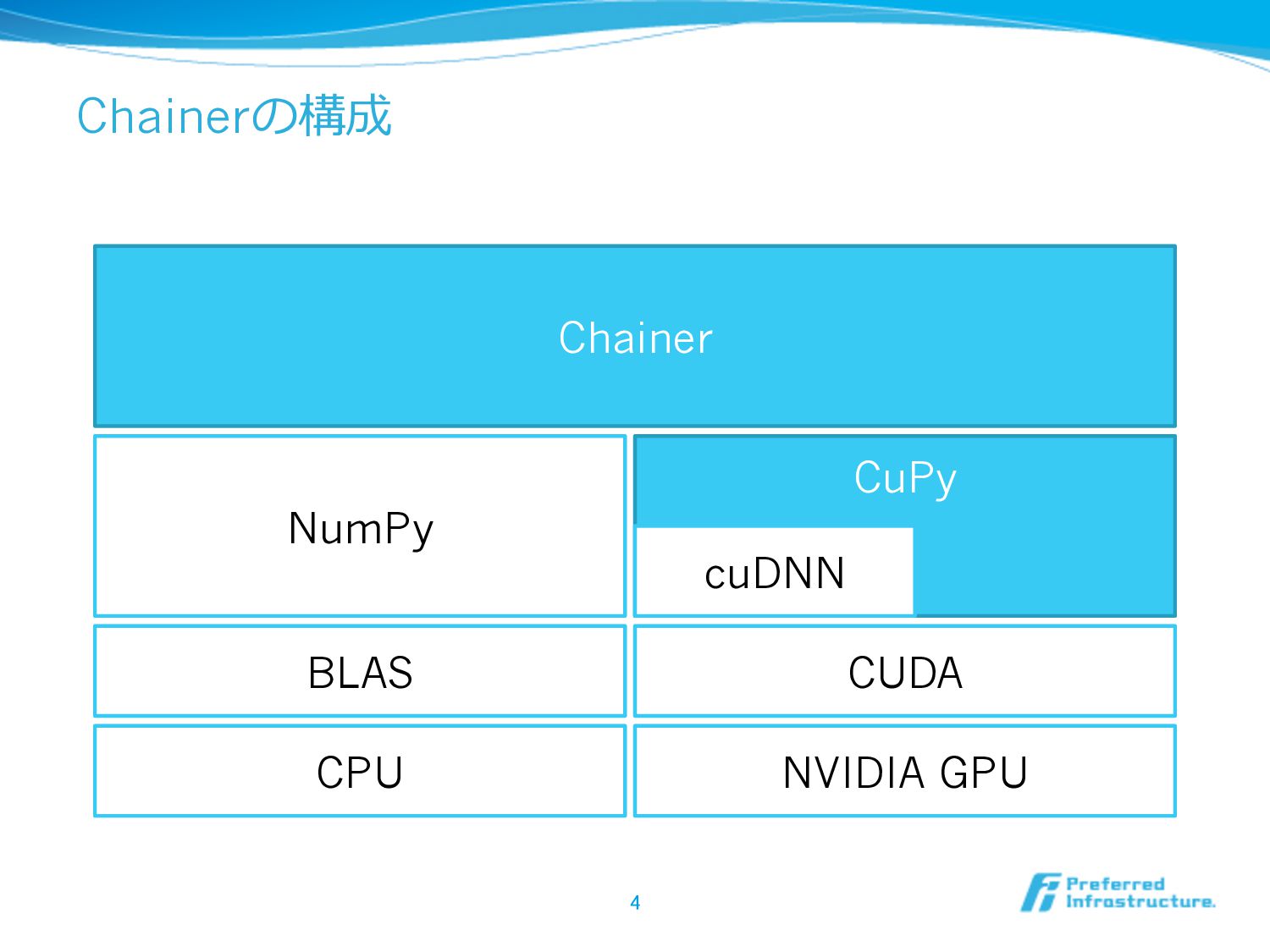
CuPy Chainerの構成 4 CPU NVIDIA GPU CUDA cuDNN BLAS NumPy
Chainer
直感的な深層学習フレームワーク Chainer 5
ニューラルネット l 値が伝播していく有向グラフ l エッジで重みをかけて、ノードに⼊入るところで⾜足し 込み、ノードの中で⾮非線形変換する l 全体としては巨⼤大で複雑な関数を表す 6
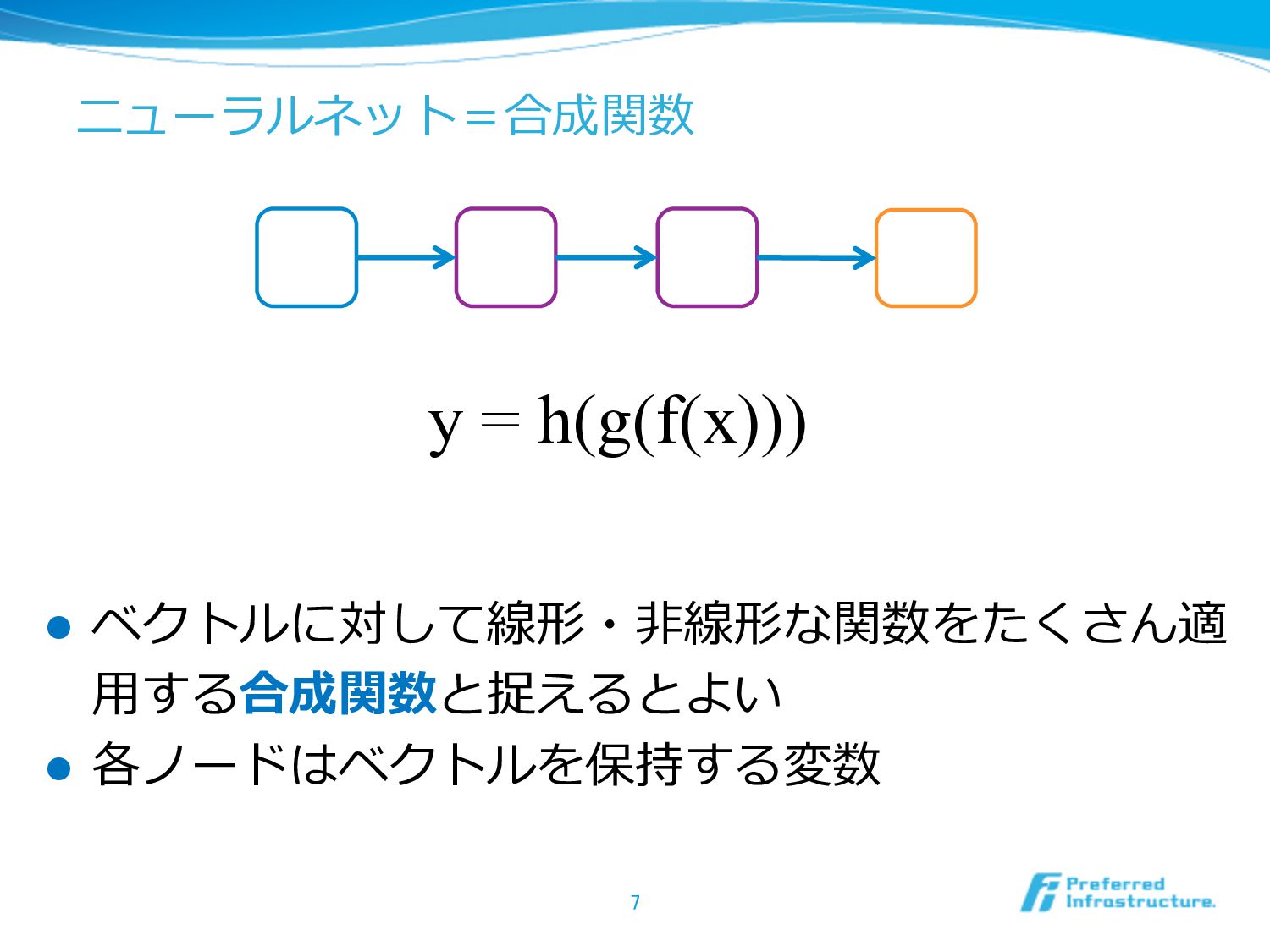
ニューラルネット=合成関数 l ベクトルに対して線形・⾮非線形な関数をたくさん適 ⽤用する合成関数と捉えるとよい l 各ノードはベクトルを保持する変数 7 y = h(g(f(x)))
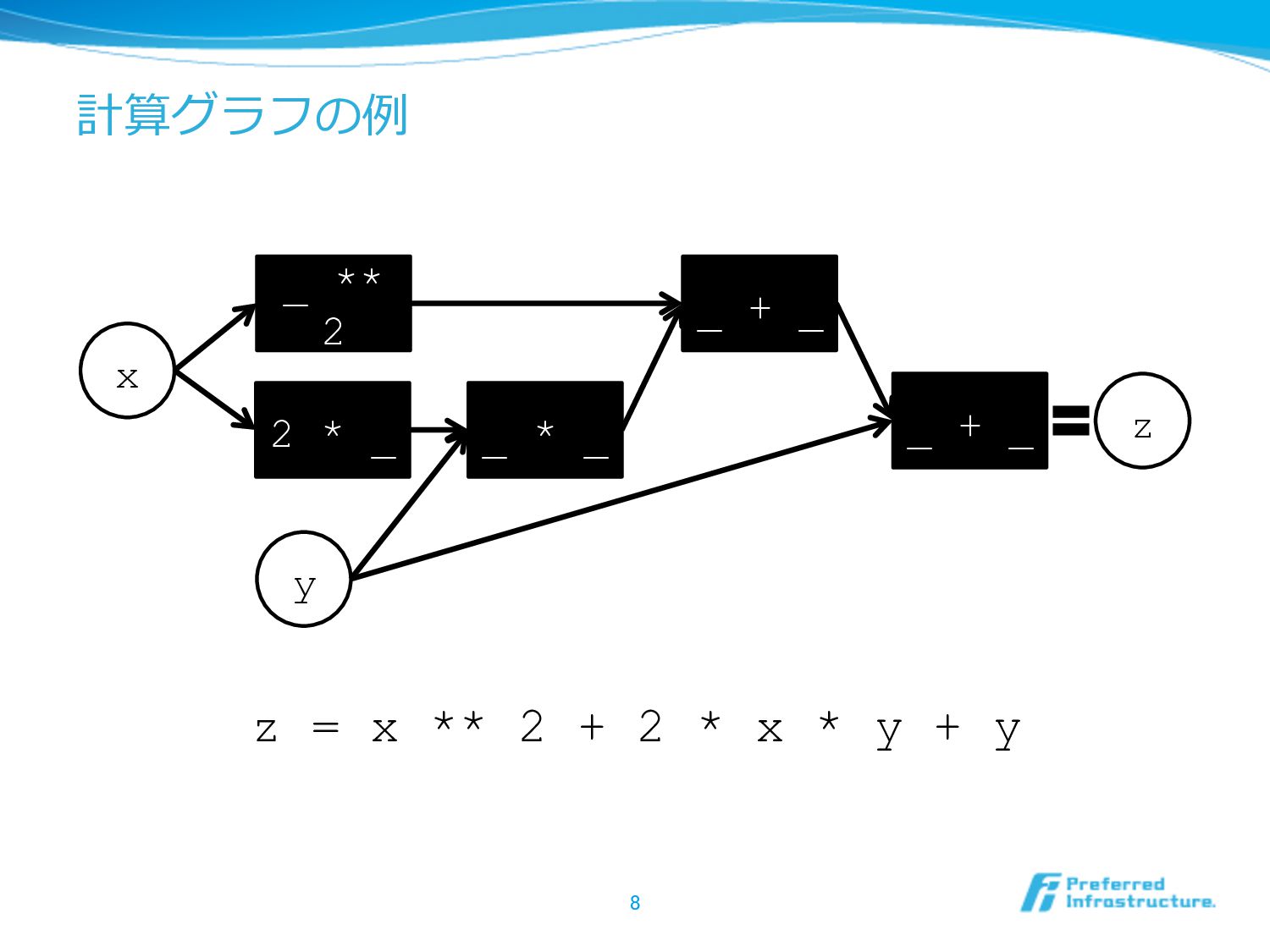
計算グラフの例例 z = x ** 2 + 2 * x
* y + y 8 x y _ ** 2 2 * _ _ * _ _ + _ z _ + _
誤差逆伝播によって勾配を計算できるのが重要 l 誤差逆伝播は連鎖律律をつかって勾配を計算する l 計算グラフと順伝播時の変数の値があれば計算可能 l ニューラルネットのフレームワークはこれを⾃自動で ⾏行行ってくれる 9 y’
= h’(g(f(x))) g’(f(x)) f’(x)
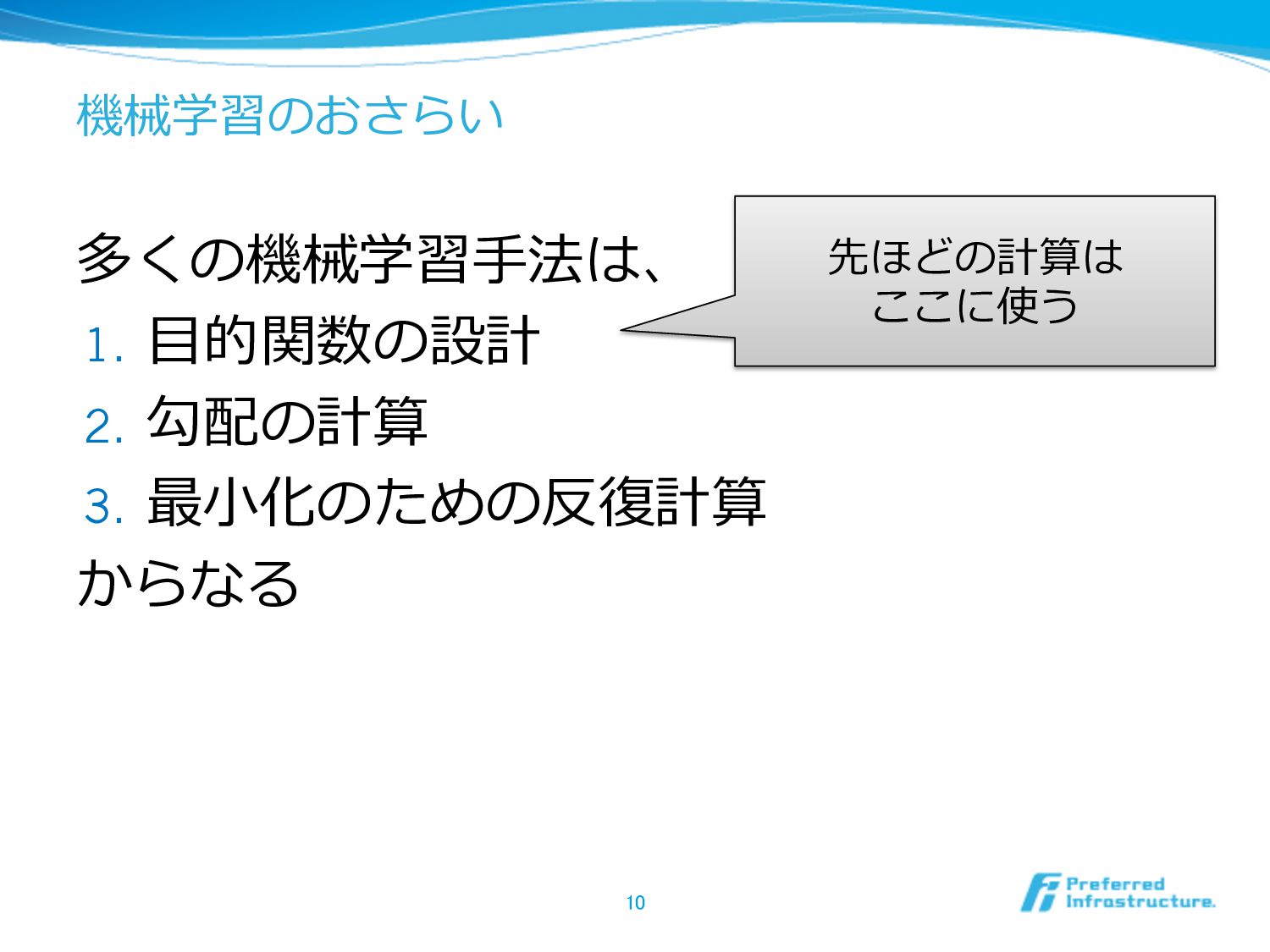
機械学習のおさらい 多くの機械学習⼿手法は、 1. ⽬目的関数の設計 2. 勾配の計算 3. 最⼩小化のための反復復計算 からなる 10
先ほどの計算は ここに使う
機械学習の例例:分類学習のアルゴリズム l ⽬目的関数をパラメータwで微分した値(勾配) を計算する⽅方法を⽤用意する l wを勾配の⽅方向に少しだけ動かす、を繰り返す l 実際は更更新⽅方向の取り⽅方に⼯工夫が他数ある 11 initialize
w until converge: w := w - η d/dw L(x, y; w) 最急降降下法
ニューラルネットの学習⽅方法 1. ⽬目的関数の設計 l 計算グラフを⾃自分で設計する 2. 勾配の計算 l 誤差逆伝播で機械的に計算できる 3.
最⼩小化のための反復復計算 l 勾配を使って反復復更更新する 12 1さえ設計すれば残りは ほぼ⾃自動化されている
深層学習フレームワークの構成要素 l いずれも似たような構成要素からなる l テンソルデータ構造 l レイヤー(関数) l ネットワーク(計算グラフ) l
最適化ルーチン l フレームワークによってこれらの設計指針や抽 象化の粒粒度度、インターフェイスが異異なる 13
深層学習フレームワークの⽐比較ポイント l 計算グラフをどう作るか? l GPUで計算できるか? l 複数GPUで計算できるか? l 複数ノードで計算できるか? l
何の⾔言語で出来ているか? 14 Chainerはここに特徴がある
計算グラフの作成戦略略 define-and-runとdefine-by-run l define-and-run l まず計算グラフを構築し、構築した計算グラフに データを流流すという、2ステップから成る l ほとんどのフレームワークがこちら l
Caffeやtheanoなど l define-by-run l 通常の⾏行行列列演算をする感覚で順伝播処理理をすると同 時に、逆伝播ようの計算グラフが構築される l Chainer 15
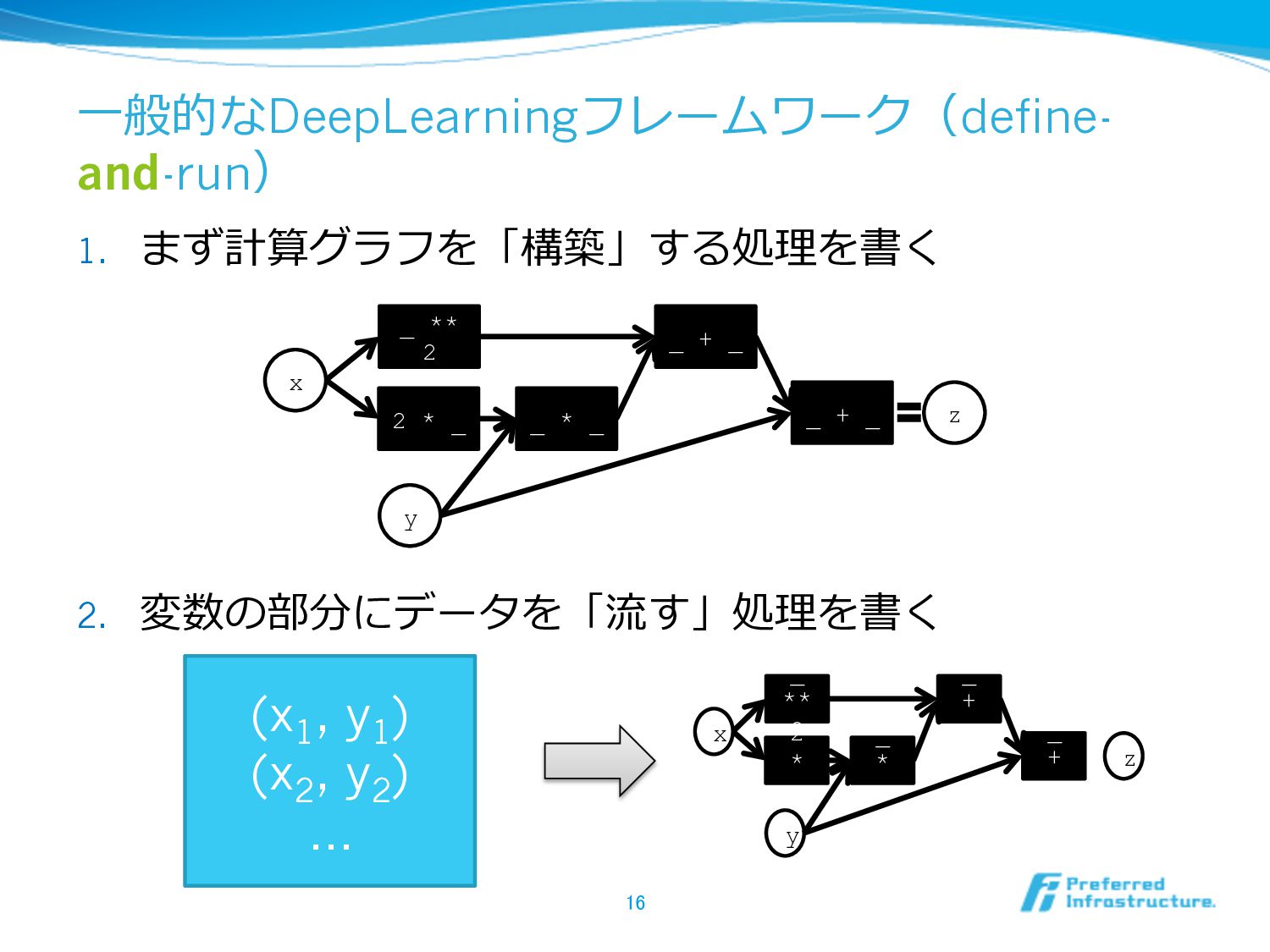
⼀一般的なDeepLearningフレームワーク(define- and-run) 1. まず計算グラフを「構築」する処理理を書く 2. 変数の部分にデータを「流流す」処理理を書く 16 x y _
** 2 2 * _ _ * _ _ + _ z _ + _ (x 1 , y 1 ) (x 2 , y 2 ) … x y _ ** 2 2 * _ _ * _ _ + _ z _ + _
計算グラフがデータに依存する例例が扱いにくい l データごとにネットワークの構造が変わってし まう⼿手法も多数存在 l 特に、ここ数年年でRecurrent Network系の研究 が増えてきている 17 Recurrent
Net Recursive Net
define-and-runで構造を扱う⽅方法 l データにごとに挙動の変わるノードをつくる l 例例えばループを表現するTheanoのscan関数 l 計算グラフ中に新たなプログラミング⾔言語を作って いるイメージ l 複数の計算グラフを予め作り、近いものを使う
l ⻑⾧長さ10, 20, 30…のRNNを作っておいて、データご とにいずれかを選択する 18 仕様が複雑になる 指数的な組み合わせに対処できない
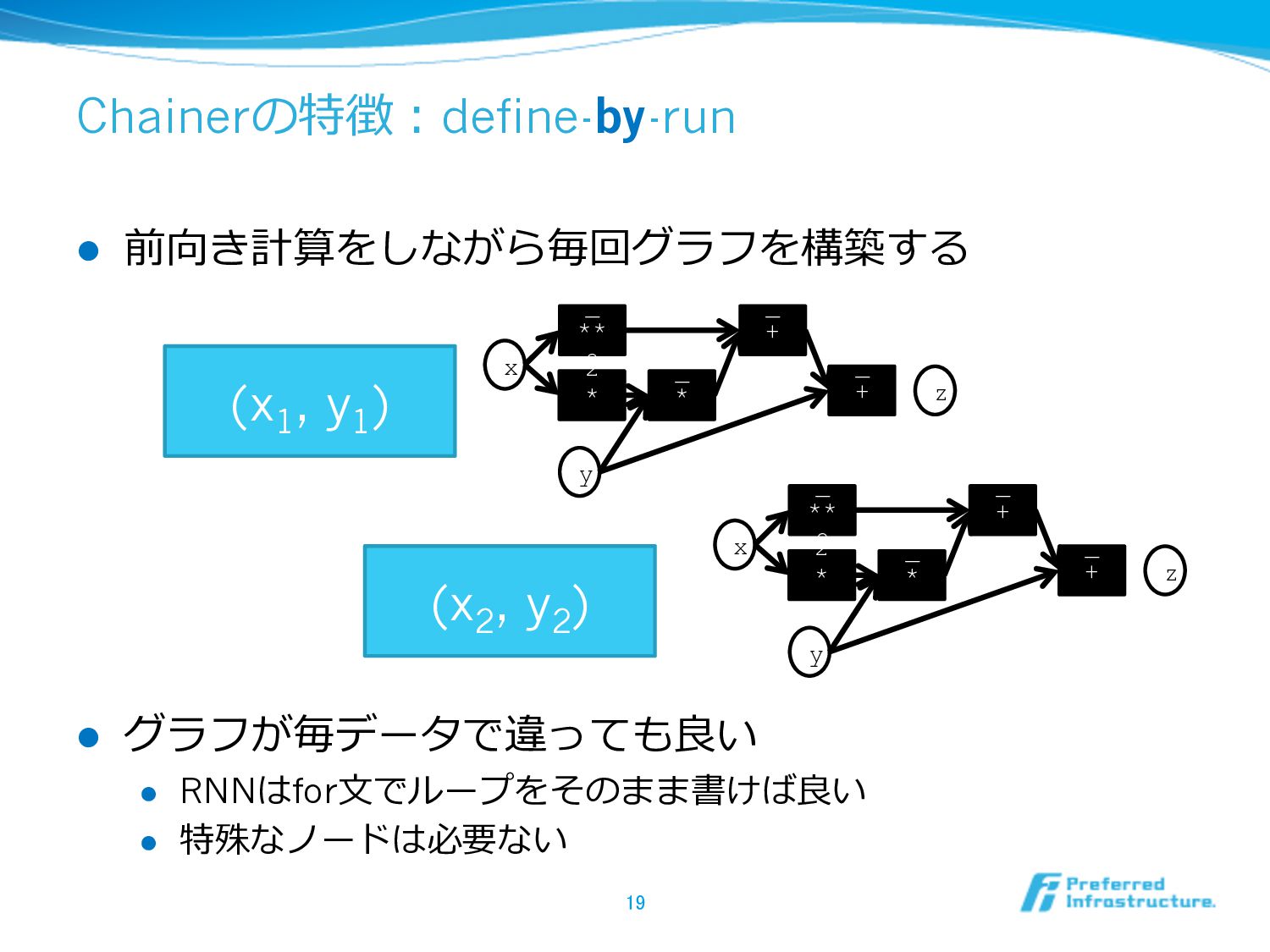
Chainerの特徴:define-by-run l 前向き計算をしながら毎回グラフを構築する l グラフが毎データで違っても良良い l RNNはfor⽂文でループをそのまま書けば良良い l 特殊なノードは必要ない 19
x y _ ** 2 2 * _ _ * _ _ + _ z _ + _ x y _ ** 2 2 * _ _ * _ _ + _ z _ + _ (x 1 , y 1 ) (x 2 , y 2 )
擬似コードで⽐比較する define-and-run # 構築 x = Variable(‘x’) y = Variable(‘y’)
z = x + 2 * y # 評価 for xi, yi in data: eval(z, x=xi, y=yi)) define-by-run # 構築と評価が同時 for xi, yi in data: x = Variable(xi) y = Variable(yi) z = x + 2 * y 20 データを⾒見見ながら 違う処理理をしてもよい
計算グラフで⽐比較する 21 s = 0 for x in [1, 2,
3]: s += x s x + x + x + s s x + s define-and-runで ループを作る define-by-runでは すべて展開される
インタプリタとコンパイラのアナロジー l define-and-runはコンパイラ l 計算⼿手順をグラフの形にそのまま変換する l ループなどの制御構⽂文相当のノードがそのまま残る l define-by-runはインタプリタ l
⽣生成されるのは計算の履履歴 l そのためループは全て展開される l 再帰も含めて、任意の計算⼿手順を実⾏行行できる 22
なぜ、⾃自由度度の⾼高いフレームワークが必要か? 深層学習とは階層の深いニューラルネットのことだけでは なくなってきている l 深いボルツマンマシン l 深い畳込みニューラルネットワーク l 再帰ニューラルネットワーク l
双⽅方向再帰ネットワーク l 注意メカニズム(Attention) 特に⾃自然⾔言語処理理など、対象のデータの構造を活かした ネットワークを作るときに役⽴立立つ 23
計算グラフ構造がデータごとに異異なる例例 [⼩小林林+16] l ⽂文中の同⼀一の固有表現の出現ごとに、Bi-RNNでエン コードして、max-pooling l 固有表現の出現パターンはデータごとに全く異異なる 24
define-by-runは何が良良いか? l 任意の構造を構築できる l Recurrentはforループを、Recursiveは再帰呼び出し でそのまま書ける l バグの箇所がわかりやすい l 前向き計算のバグはPython中の特定の⾏行行に対応する
l 演算中に簡単に処理理を差し込める l 例例えばデバッグプリントやassertを⼊入れられる 25
define-by-runのデメリット l 計算グラフの構築コストが⼤大きい l 毎計算ごとにグラフを構築する l ループは展開される l 最適化をかけづらい l
2つの演算をまとめたような演算に変換できない 26 演算単位が⼤大きいベクトルなので、オーバー ヘッドは⽐比較的軽微 計算の実⾏行行を遅延させて、JITで最適化を⾏行行う ことはできそう
Chainerを使う場合 l Pythonのインストール l pipのインストール l CUDAのインストール l pip install
chainer 27
NNフレームワークの現在・今後の課題 l メモリ使⽤用量量の削減 l ニューラルネットの学習はメモリを⼤大量量に消費する l ⼀一⽅方でGPUのメモリは⼩小さい l マルチGPU・マルチノード l
⾃自動で最適化しないと使ってもらえない l 最後のTensorflowの発表に期待! l ミニバッチ化をやめたい l 計算効率率率を上げるために、同じデータを纏めて計算している l そのため、構造の違うデータを⼀一度度に処理理しづらい 28
Chainerのまとめ l NNフレームワークは誤差逆伝播を⾃自動でやって くれる l 計算グラフ構築の2つの⽅方法論論 l define-and-runが主流流で、最適化をしやすい l Chainerはdefine-by-runで、⼿手法の⾃自由度度が⾼高い
l まだ課題はある l メモリ使⽤用量量、マルチノード、ミニバッチの排除 29
CUDAによる⾏行行列列ライブラリCuPy 30
CuPyとは何か? NumPy互換インターフェースの CUDA実装の⾏行行列列ライブラリ 31 Pythonの⾏行行列列ライブラリ NVIDIA GPUの開発環境とライブラリ
既存のライブラリと 同じインターフェースで GPUの⾼高速性を⼿手に⼊入れられる 32
CuPyとNumPyの⽐比較 import numpy x = numpy.array([1,2,3], numpy.float32) y = x
* x s = numpy.sum(y) print(s) import cupy x = cupy.array([1,2,3], cupy.float32) y = x * x s = cupy.sum(y) print(s) 33
CuPyはどのくらい早いの? l 状況しだいですが、最⼤大数⼗十倍程度度速くなります def test(xp): a = xp.arange(1000000).reshape(1000, -1) return
a.T * 2 test(numpy) t1 = datetime.datetime.now() for i in range(1000): test(numpy) t2 = datetime.datetime.now() print(t2 -t1) test(cupy) t1 = datetime.datetime.now() for i in range(1000): test(cupy) t2 = datetime.datetime.now() print(t2 -t1) 34 時間 [ms] 倍率率率 NumPy 2929 1.0 CuPy 585 5.0 CuPy + Memory Pool 123 23.8 Intel Core i7-4790 @3.60GHz, 32GB, GeForce GTX 970
なぜCuPyが求められるのか? l GPUを使った応⽤用研究では、必 要な知識識が以前より増えた l GPU⾃自体が複雑 l GPUを効率率率的に扱うアルゴリズム も複雑 l
使わないと効率率率で勝てない l GPUを効率率率的に⼿手軽に使える仕 組みが必要になっている 35 GPU CUDA ⾏行行列列ライブラリ 深層学習エンジン 応⽤用研究
裏裏の仕組み l CUDA⽤用ソースを⾃自動⽣生成してコンパイラが⾛走る l ⽣生成されたバイナリをGPUに⾃自動的に転送・実⾏行行する l ビルド結果はキャッシュされるので2回⽬目移⾏行行⾼高速 36 スタブ スタブ
実処理理 nvcc コンパイラ .cubin GPU 実行 キャッシュ する
CUDA関連ライブラリの利利⽤用 l NVIDIAはCUDA⽤用のライブラリを提供している l CUPYはこれらのライブラリを内部で利利⽤用する l cuBLAS、cuDNN l 例例えば内積計算すれば、勝⼿手に効率率率のよいcuBLASが 使われる
l バージョン間の差も吸収 l cuDNN v2, v3, v4すべてサポート l 全部APIが微妙に変わっている(!) 37
⾃自分でコードを書きたい時 例例:z[i] = x[i] + 2 * y[i] を書きたい 38
引数の型: “float32 x, float32 y” 戻り値の型: “float32 z” 処理理: “z = x + 2 * y;” ループやインデックスの処理理は ⾃自動で埋めてくれる これだけ書け ば良良い
Elementwiseカーネルの実体 l Pythonの⽂文字列列テンプレートを使って⽣生成 39 ${preamble} extern "C" __global__ void ${name}(${params})
{ ${loop_prep}; CUPY_FOR(i, _ind.size()){ //全要素のループ _ind.set(i); //インデックスを計算 ${operation}; //計算部分 } ${after_loop}; }
できる処理理 l Elementwise l 各次元に対して同じ処理理をおこなう l z i = f(x
i , y i , …) for all i l Reduction l 全次元をマージする l z = f(f(… f(x1, x2), x3, …) それぞれMapReduceのMapとReduceに対応して いると思えば良良い 40
型を汎⽤用にしたい 例例:z[i] = x[i] + 2 * y[i] をint/float対応にしたい 41
引数の型: “T x, T y” 戻り値の型: “T z” 処理理: “z = x + 2 * y;” 渡された配列列の型に応じて 異異なるソースを⽣生成する
型解決の仕組み l 基本的にNumPyの型規則に準拠 l 例例えばint32 + float32はfloat64になるなど、 NumPyの仕様が決まっている l NumPyのバグ(?)も再現
l 渡された型ごとにコードを⾃自動⽣生成する仕組み があるので、int32とfloat32に対して同じコー ドを書けばよい l 例例外を書く⽅方法も⽤用意されている 42
チューニングの⽅方法 l CUDAのツールがそのまま使える l NVIDIA Visual Profiler (nvvp)やnvprofコマンド l CPU⽤用のプロファイラではGPUのボトルネックがわ
からないので注意 l 詳細はCUDAのサイトへ 43
深層学習以外にも利利⽤用できる l 既存のNumPyコードがほぼそのまま動く l 既存の解析⼿手法がそのままCUDA上で動く l NumPyのベクトルデータとの変換は1⾏行行 44
CuPyの問題点 l 細かい単位の関数呼び出しが多くなる l GPUの帯域律律速になってしまう l 関数合成の仕組みが必要 l ⾮非同期呼び出しとメモリプールの相性が悪い l
現在は⼀一つのストリームのみ使っている l その他 l NumPyの関数のカバー率率率が低い l Chainerに必要なものから実装中 45
全体のまとめ l Chainerは⾃自由度度が⾼高い l NNフレームワークは誤差逆伝播をやってくれる l Chainerのdefine-by-runは⾃自由にネットワークを構築 できる l メモリ、マルチノード、ミニバッチが今後の課題
l CuPyはNumPy互換の⾏行行列列ライブラリ l NumPyとほぼAPI互換 l ビルド作業などは裏裏で勝⼿手にやってくれる l CUDAのコードを⾃自分で書くこともできる 46
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![計算グラフ構造がデータごとに異異なる例例 [⼩小林林+16] l ⽂文中の同⼀一の固有表現の出現ごとに、Bi-RNNでエン コードして、max-pooling l 固有表現の出現パターンはデータごとに全く異異なる 24](https://files.speakerdeck.com/presentations/e28ee2b2058d41a28548180642c38242/slide_23.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![CuPyとNumPyの⽐比較 import numpy x = numpy.array([1,2,3], numpy.float32) y = x](https://files.speakerdeck.com/presentations/e28ee2b2058d41a28548180642c38242/slide_32.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![⾃自分でコードを書きたい時 例例:z[i] = x[i] + 2 * y[i] を書きたい 38](https://files.speakerdeck.com/presentations/e28ee2b2058d41a28548180642c38242/slide_37.jpg){kind=link}
{kind=link}
{kind=link}
![型を汎⽤用にしたい 例例:z[i] = x[i] + 2 * y[i] をint/float対応にしたい 41](https://files.speakerdeck.com/presentations/e28ee2b2058d41a28548180642c38242/slide_40.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}