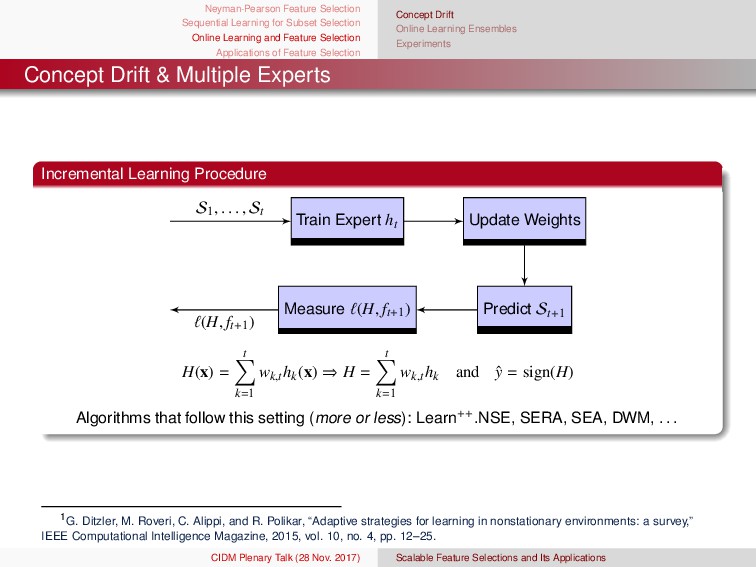
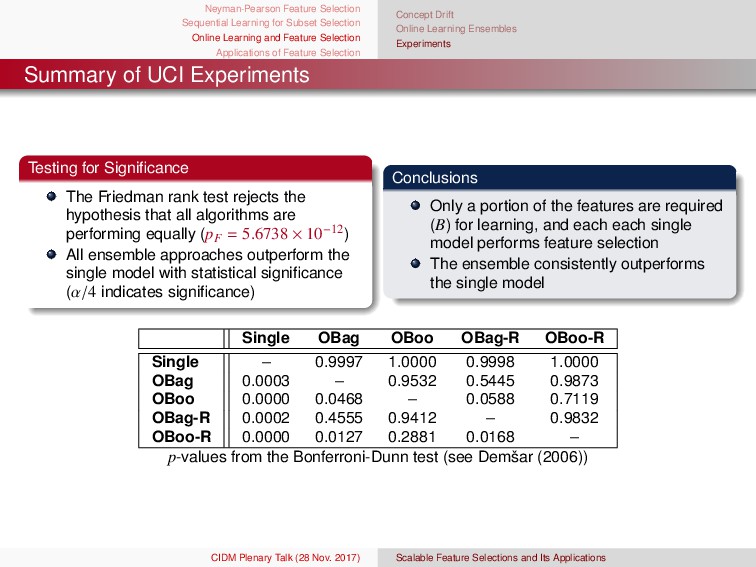
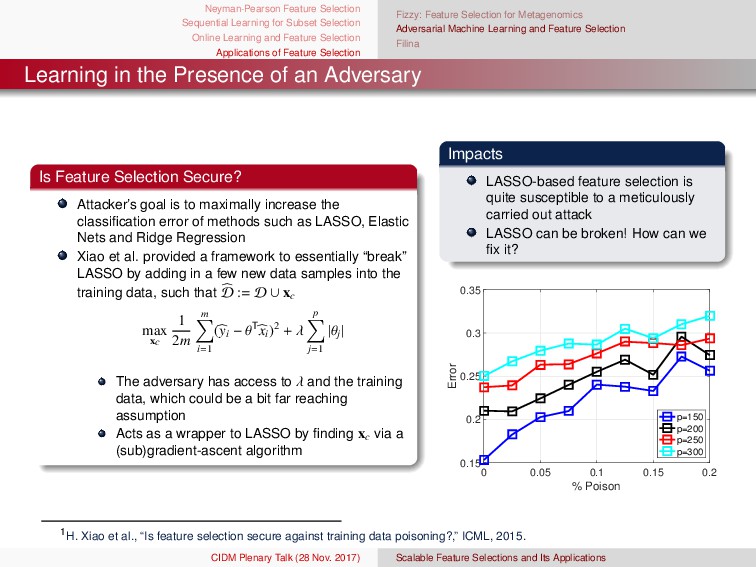
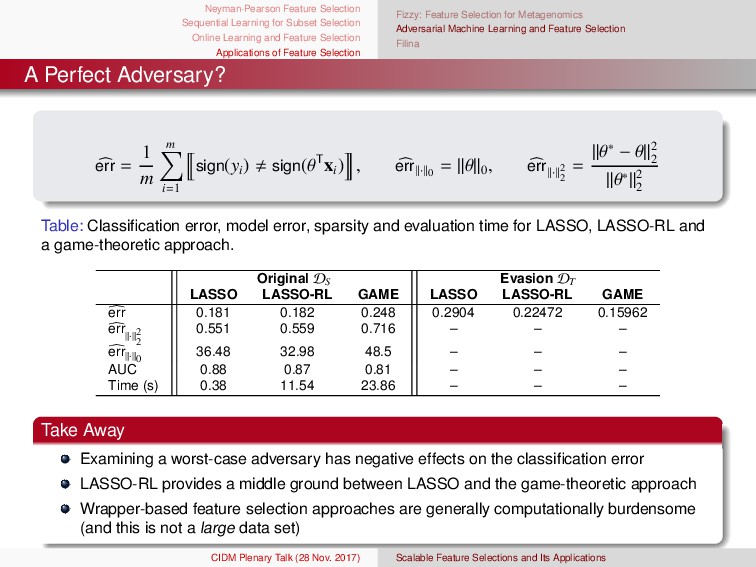
and Feature Selection Applications of Feature Selection Concept Drift Online Learning Ensembles Experiments Online Feature Selection Ensemble Pseudo Code 1: Input B: OFS truncation parameter R: maximum l2 magnitude J: ensemble size 2: Initialization w(j) 0 ∼ N(0, 1) ∀j ∈ [J] p0 ∼ N(0, 1) 3: for t = 1, . . . , T do 4: (xt , yt) ∼ D 5: for j = 1, . . . , J do 6: Z ∼ Poisson(1) 7: for z = 1, . . . , Z do 8: w(j) t ← OFS Update(w(j) t , xt , yt) 9: end for 10: end for 11: pt ← 1 J J j=1 w(j) t 12: pt ← Truncate(pt , B) 13: end for 1: Input: OFS truncation parameter (B), maximum l2 magnitude (R), and ensemble size (J) 2: Initialization: w (j) 0 ∼ N(0, 1), λsc j ← 0, λsw j ← 0, p0 ∼ N(0, 1) ∀j ∈ [J] 3: for t = 1, . . . , T do 4: (xt, yt) ∼ D 5: λt = 1 6: for j = 1, . . . , J do 7: Z ∼ Poisson(λt) 8: for z = 1, . . . , Z do 9: w (j) t ← OFS Update(w (j) t , xt, yt) 10: end for 11: if ytxT t w (j) t < 0 then 12: λsw j ← λsw j + λt 13: λt ← λt t 2λsw j 14: else 15: λsc j ← λsc j + λt 16: λt ← λt t 2λsc j 17: end if 18: end for 19: Set j = λsw j λsw j +λsc j ∀j ∈ [J] 20: pt = J j=1 log 1− j j w (j) t 21: pt ← Truncate(pt, B) 22: end for CIDM Plenary Talk (28 Nov. 2017) Scalable Feature Selections and Its Applications
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
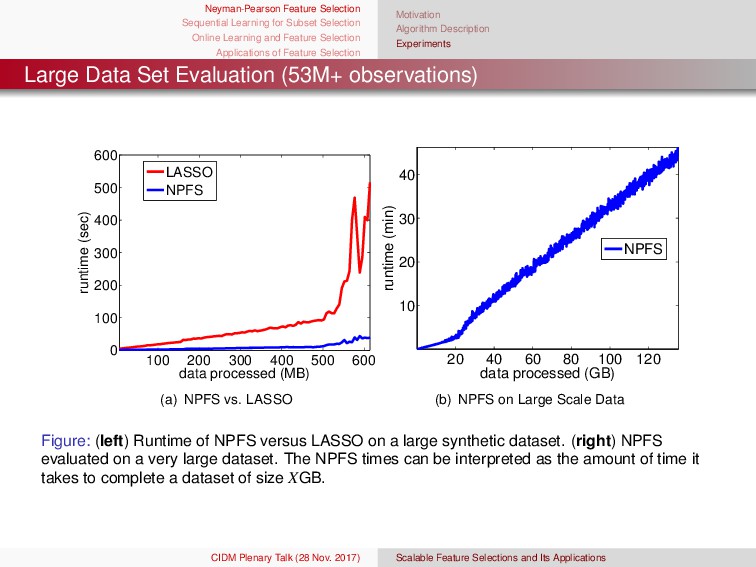{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
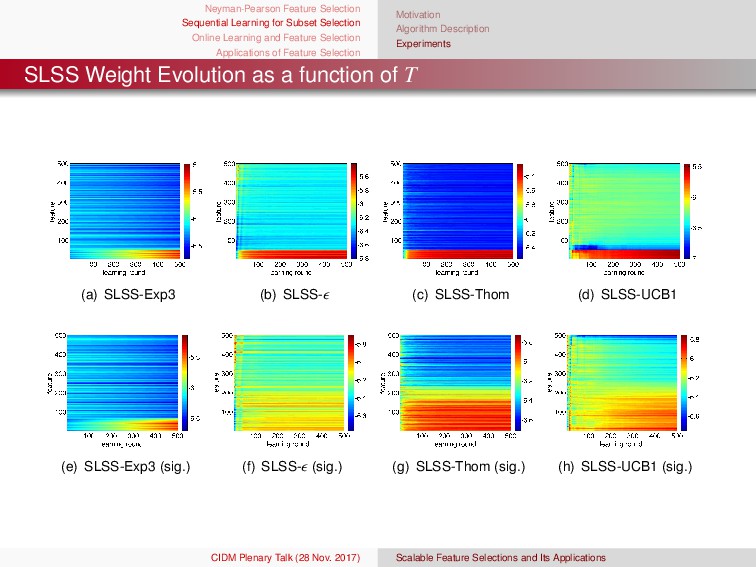{kind=link}
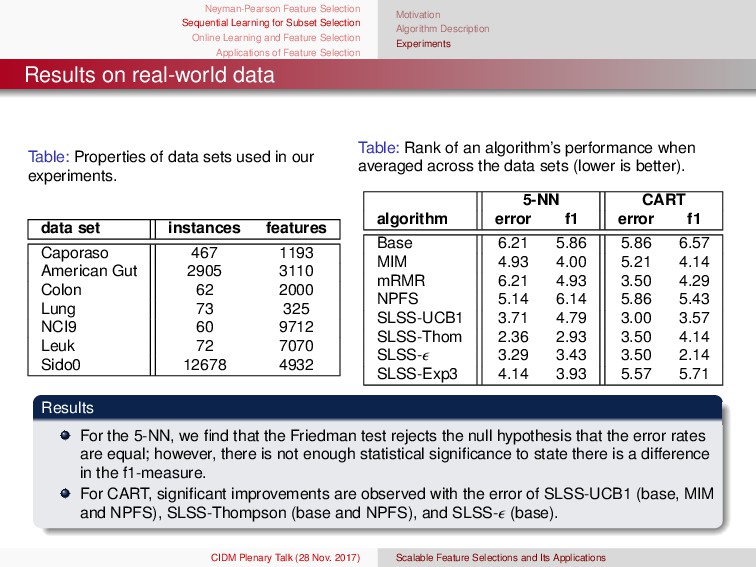{kind=link}
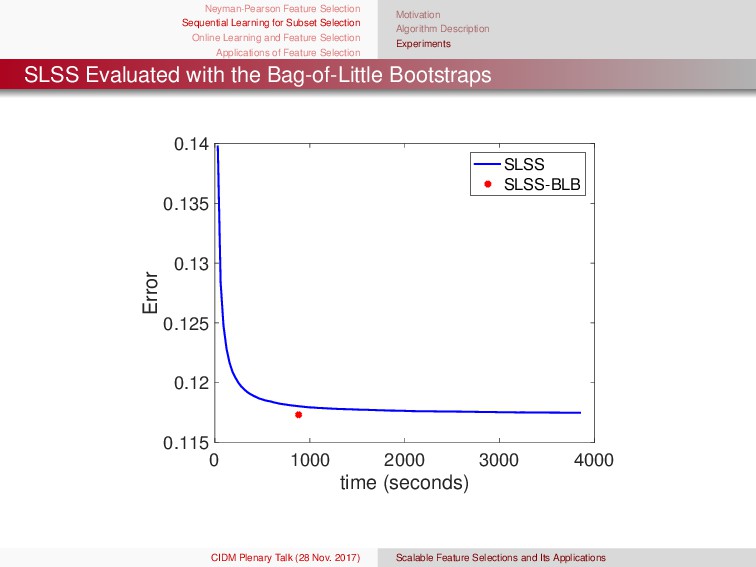{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
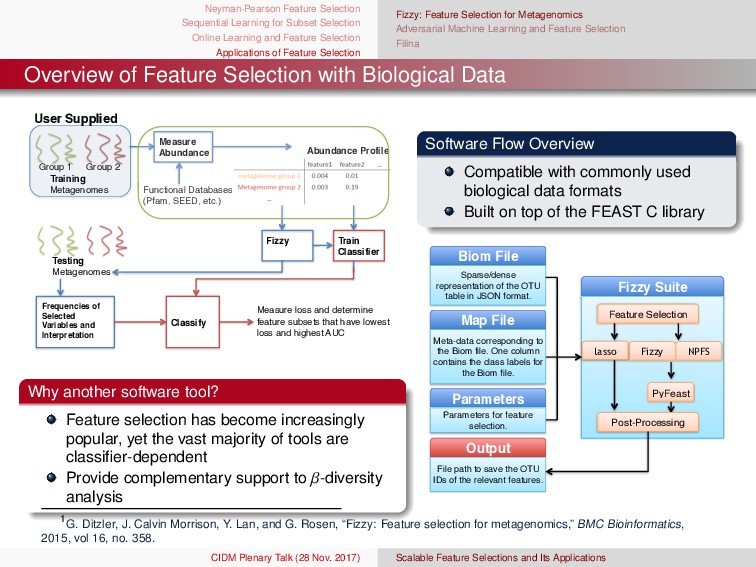{kind=link}
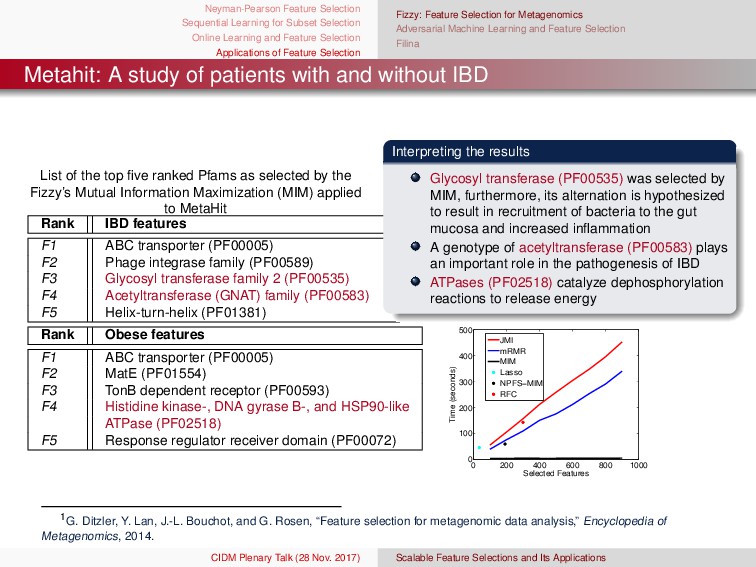{kind=link}
{kind=link}
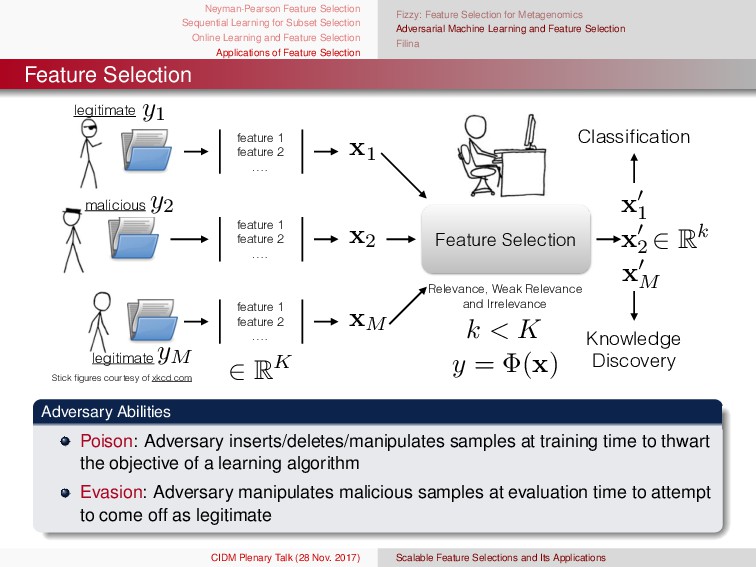{kind=link}
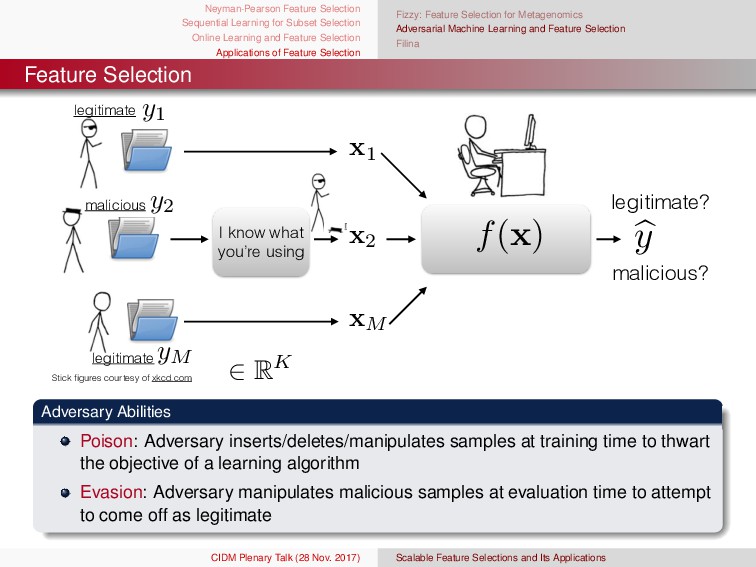{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}