Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
複数の客観的手法を用いたテキスト含意認識評価セットの構築
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
自然言語処理研究室
March 31, 2011
Research
82
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
複数の客観的手法を用いたテキスト含意認識評価セットの構築
宇髙 邦弘, 山本 和英. 複数の客観的手法を用いたテキスト含意認識評価セットの構築. 言語処理学会第17回年次大会, pp.627-630 (2011.3)
自然言語処理研究室
March 31, 2011
More Decks by 自然言語処理研究室
See All by 自然言語処理研究室
データサイエンス14_システム.pdf
jnlp
0
420
データサイエンス13_解析.pdf
jnlp
0
530
データサイエンス12_分類.pdf
jnlp
0
370
データサイエンス11_前処理.pdf
jnlp
0
500
Recurrent neural network based language model
jnlp
0
170
自然言語処理研究室 研究概要(2012年)
jnlp
0
160
自然言語処理研究室 研究概要(2013年)
jnlp
0
130
自然言語処理研究室 研究概要(2014年)
jnlp
0
150
自然言語処理研究室 研究概要(2015年)
jnlp
0
230
Other Decks in Research
See All in Research
論文紹介:HalluCitation Matters
wasyro
0
120
JICA QUEST 共創×革新プログラム Impact Report(海ノ向こうコーヒー)
ontheslope
0
180
東京大学工学部計数工学科、計数工学特別講義の説明資料
kikuzo
0
550
Harness Engineering and Al Agent
kzinmr
3
1.8k
Cross-Media Information Spaces and Architectures
signer
PRO
0
310
【ローカルAIに向き合う展示会vol.2】液体時間定数型モジュールを用いた オリジナルの双方向エンコーダーモデルNexteraBERT 推論速度向上検討並びにダウンストリーム評価
rikkabotan7
0
120
計算情報学研究室 (数理情報学第7研究室)2026
tomohirokoana
0
630
Language and AI
ayaniwa
0
170
さくらインターネット研究所テックトーク2026春、研究開発Gr.25年度成果26年度方針
kikuzo
0
160
進学校の生徒にはア行の苗字が多いのか
ozekinote
0
470
言語モデルから言語について語る際に押さえておきたいこと
eumesy
PRO
6
2.5k
Unified Audio Source Separation (Defense Slides)
kohei_1979
1
630
Featured
See All Featured
SERP Conf. Vienna - Web Accessibility: Optimizing for Inclusivity and SEO
sarafernandez
2
1.5k
RailsConf 2023
tenderlove
30
1.5k
How to Ace a Technical Interview
jacobian
281
24k
Improving Core Web Vitals using Speculation Rules API
sergeychernyshev
21
1.5k
Odyssey Design
rkendrick25
PRO
2
730
Faster Mobile Websites
deanohume
310
32k
JAMstack: Web Apps at Ludicrous Speed - All Things Open 2022
reverentgeek
1
490
Groundhog Day: Seeking Process in Gaming for Health
codingconduct
0
240
How STYLIGHT went responsive
nonsquared
100
6.2k
Templates, Plugins, & Blocks: Oh My! Creating the theme that thinks of everything
marktimemedia
31
2.8k
So, you think you're a good person
axbom
PRO
2
2.1k
Building a A Zero-Code AI SEO Workflow
portentint
PRO
0
630
Transcript
複数の客観的手法を用いた テキスト含意認識評価セット の構築 長岡技術科学大学 電気系 山本研究室 宇高 邦弘,山本 和英
テキスト含意認識とは ① ・言語表現A(テキスト)が言語表現B(仮説) の意味を含むかを判断するタスク テキスト :日本の大豆生産量は世界16位だ 仮説 :日本は大豆を生産している 含意判定 :含意
テキスト含意認識の例
研究背景 ・テキスト含意認識(RTE)の研究が活発化 ⇒換言や質問応答など多様な問題を含む ・日本語の評価セットが少ない ⇒構築コストの高さ ⇒テキスト含意認識のための知識の少なさ ⇒既存の評価セットは再現性に乏しい ⇒どのような含意関係を解決可能か不明瞭 ②
研究目的 換言や要約などの手法による 評価セットの構築 手法ごとに評価セットを作成 ⇒評価セットの難易性を統一 ⇒構築が低コスト ⇒再現性が高い ③
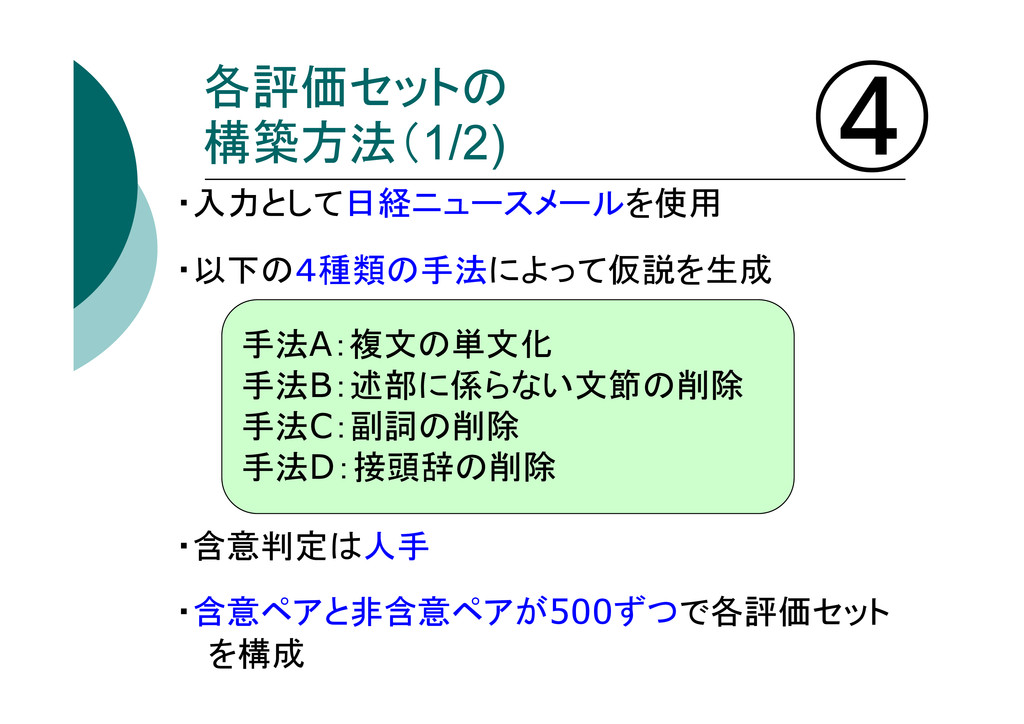
各評価セットの 構築方法(1/2) ・入力として日経ニュースメールを使用 ・以下の4種類の手法によって仮説を生成 ・含意判定は人手 ・含意ペアと非含意ペアが500ずつで各評価セット を構成 ④ 手法A:複文の単文化 手法B:述部に係らない文節の削除
手法C:副詞の削除 手法D:接頭辞の削除
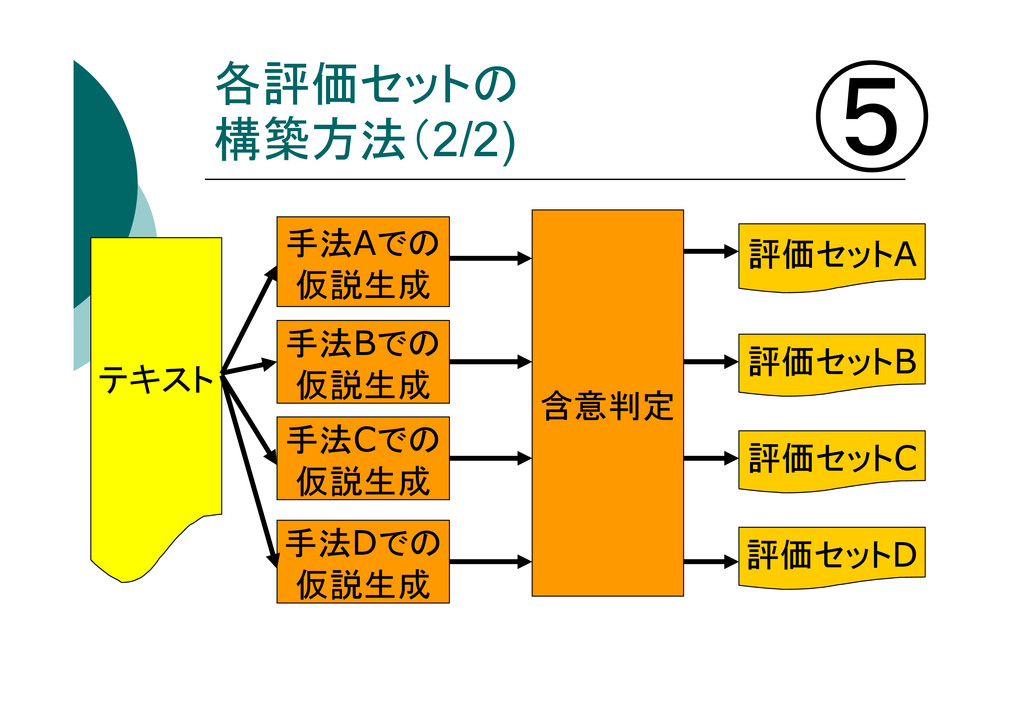
各評価セットの 構築方法(2/2) 手法Aでの 仮説生成 テキスト 手法Bでの 仮説生成 手法Cでの 仮説生成 手法Dでの
仮説生成 評価セットA 評価セットB 評価セットC 評価セットD 含意判定 ⑤
手法A:複文の単文化 ⑥ ・連体修飾節について格助詞を補う ⇒文構造を変化させた仮説を作成 テキスト :AT&Tは高速ネット接続を可能にする CATV網を他の通信会社に開放する 仮説 :高速ネット接続をCATV網が可能にする 生成されるペアの例
手法B:述部に係る 文節以外の削除 ・述部に係る文節以外を全て削除 ⇒文構造を変化させた仮説を生成 ⑦ テキスト :NTTは電話線を使う高速ネット「ADSL」 を月800円で開放する 仮説 :NTTは「ADSL」を800円で開放する
生成されるペアの例
手法C:副詞の削除 ⑧ ・文中に存在する副詞を全て削除 (副詞可能名詞も含む) ⇒表層情報を変化させた仮説を生成 テキスト :東証のベンチャー向け新市場「マザーズ」 に22日、ネット関連2社が始めて上場 仮説 :東証のベンチャー向け新市場「マザーズ」
に22日、ネット関連2社が上場 生成されるペアの例
手法D:接頭辞の削除 ⑨ ・文中に存在する接頭辞を全て削除することで 仮説を生成 (「反,未,非,無,不」は未削除) ⇒表層情報を変化させた仮説を生成 テキスト :ジー・オー巨額詐欺事件で大神源太被告ら 5人の初公判が20日、東京地裁で開かれた 仮説
:ジー・オー巨額詐欺事件で大神源太被告ら 5人の公判が20日、東京地裁で開かれた 生成されるペアの例
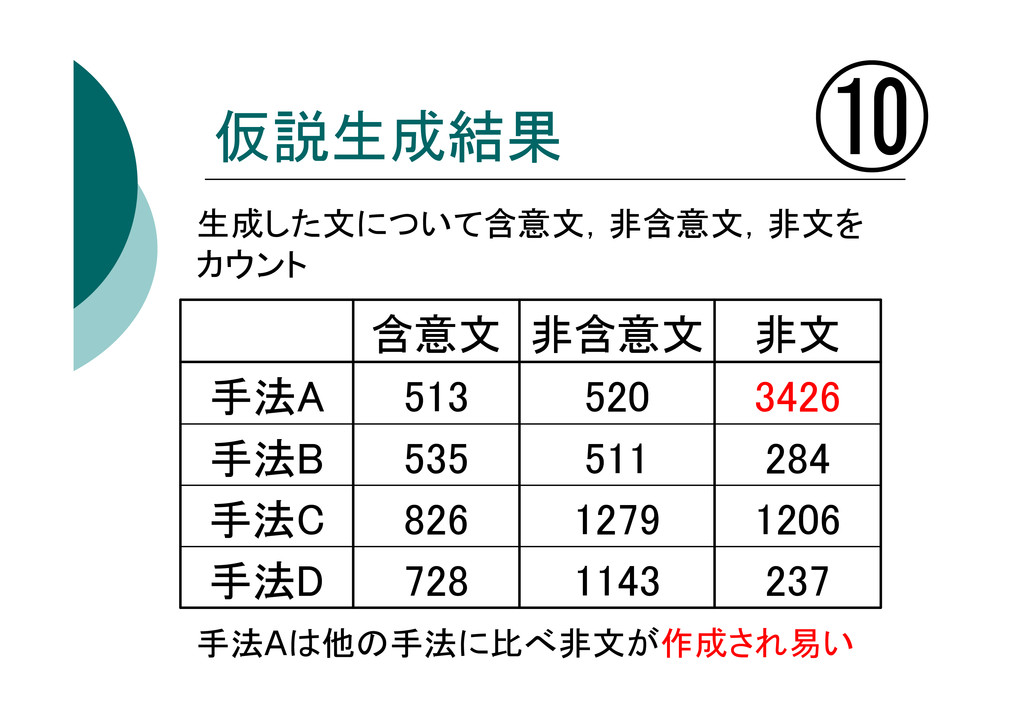
仮説生成結果 手法Aは他の手法に比べ非文が作成され易い ⑩ 237 1143 728 手法D 1206 1279 826
手法C 284 511 535 手法B 3426 520 513 手法A 非文 非含意文 含意文 生成した文について含意文,非含意文,非文を カウント
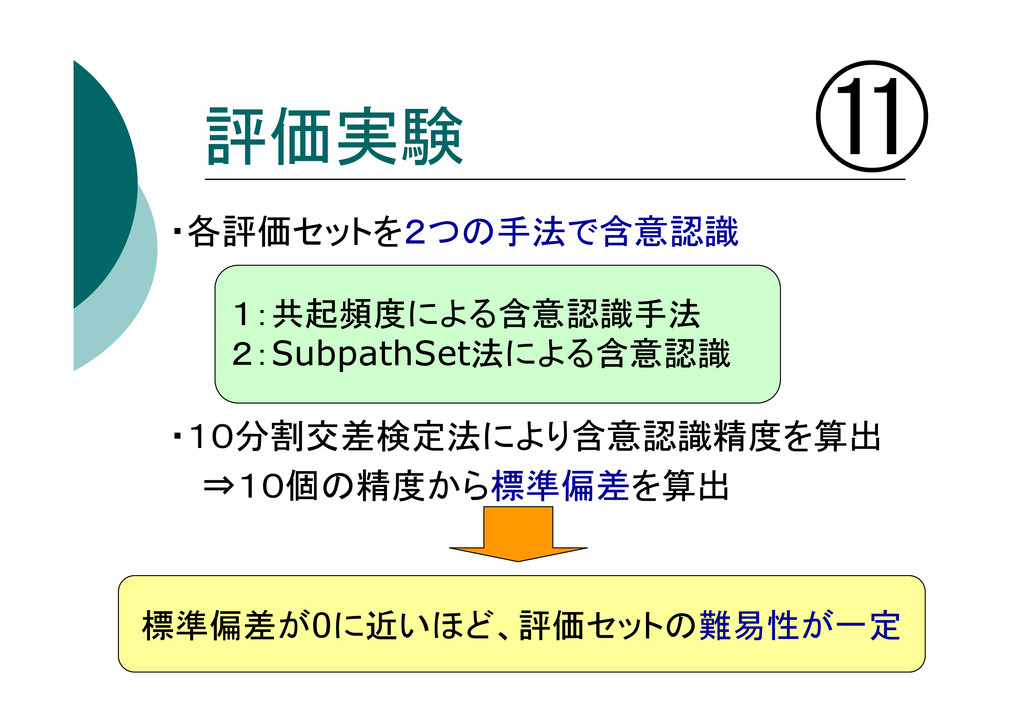
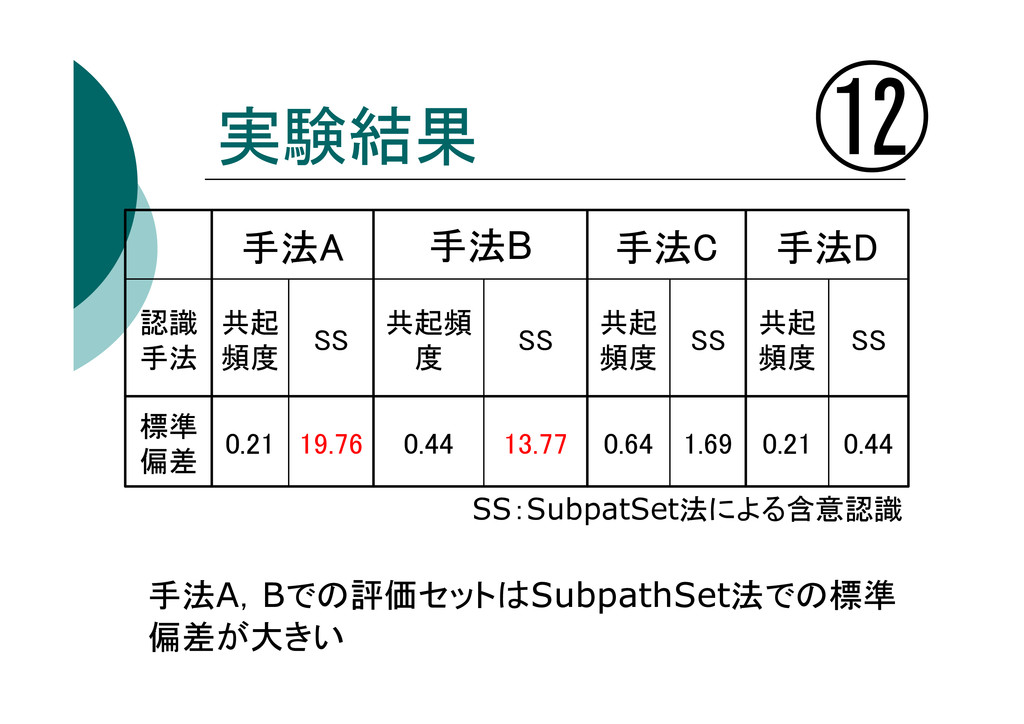
評価実験 ⑪ ・各評価セットを2つの手法で含意認識 ・10分割交差検定法により含意認識精度を算出 ⇒10個の精度から標準偏差を算出 標準偏差が0に近いほど、評価セットの難易性が一定 1:共起頻度による含意認識手法 2:SubpathSet法による含意認識
実験結果 ⑫ SS:SubpatSet法による含意認識 0.44 0.21 1.69 0.64 13.77 0.44 19.76
0.21 標準 偏差 SS 共起 頻度 SS 共起 頻度 SS 共起頻 度 SS 共起 頻度 認識 手法 手法D 手法C 手法B 手法A 手法A,Bでの評価セットはSubpathSet法での標準 偏差が大きい
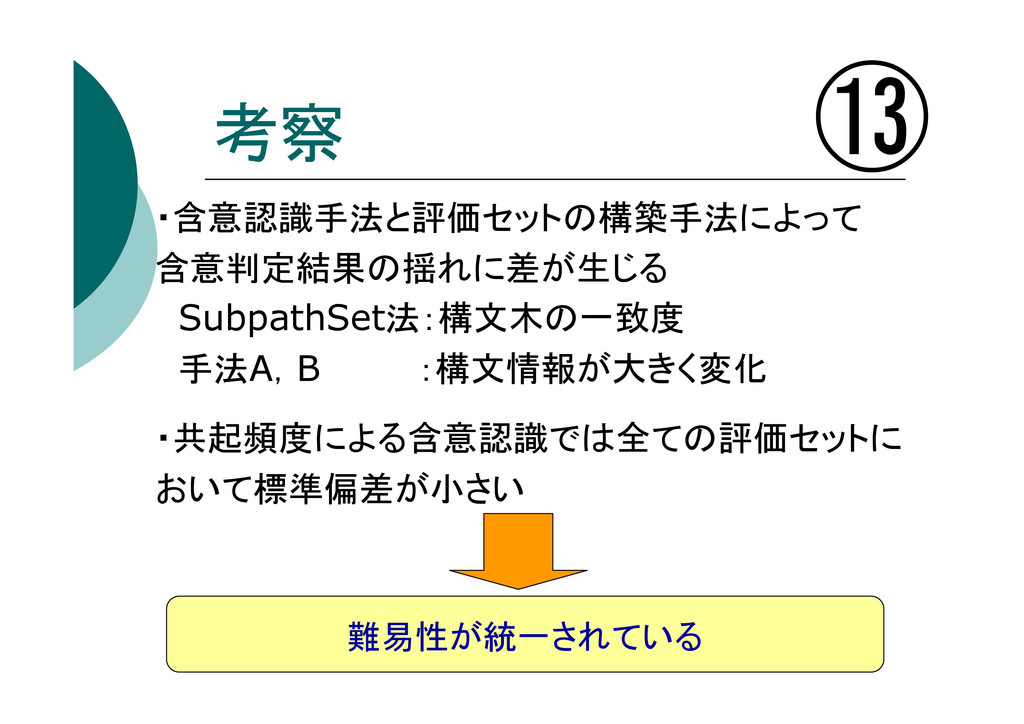
考察 ・含意認識手法と評価セットの構築手法によって 含意判定結果の揺れに差が生じる SubpathSet法:構文木の一致度 手法A,B :構文情報が大きく変化 ・共起頻度による含意認識では全ての評価セットに おいて標準偏差が小さい ⑬ 難易性が統一されている
結論 ・4種類の手法を個々に用いて,日本語テキス ト含意認識評価セットを構築 ⇒構築コストの低下,再現性の向上 ・以下の2点についてさらに研究を進める. ⑭ 1:他の含意認識手法を用いて,評価セットの 難易性が統一されていることを確認 2:他の手法を用いて評価セットを作成し, 含意認識の問題を網羅する
既存研究 ⑤ ・The PASCAL Recognizing Textual Entailment Challenge [Dagan et
al. 2005] ⇒機械翻訳や情報検索の手法を使用 ・日本語Textual Entailmentのデータ構築と自動 獲得した類語表現に基づく推論関係の認識 [小谷ら 2008] ⇒推論要因を5つに分類し,評価セットを構築 ⇒分類方法が不明瞭なため再現性がない ⇒含意認識時の問題点が議論しにくい
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}