semantics) • rewritten rules (cf. parsing) • corpus • thesaurus Current natural language processing somewhat requires language resources. Moreover, performance of process heavily depends on quality and quantity of language resources we use. In order to improve better performance, it is required to build (by ourselves) "better" resources.
dictionary for human and that for computer? • Human dictionary is used mainly for getting definition. • Computer dictionary is for getting the difference of senses as well as getting usage. Hence we don't directly utilize human dictionary for computer processing.
language • syntax; inflection, part-of-speech, etc. • semantics; definition etc. knowledge of situation • so far what was spoken at where in when knowledge of world = common sense • what we all know; e.g., umbrella is used at rainy day, teacher is at school to teach something, the red signal of the light shows stop. etc. technical knowledge • shared knowledge within a special community, such as electronics, law, and cooking.
林檎・りんご・リンゴ、%・パーセント • difference within the same orthography – 付属・附属、バイオリン・ヴァイオリン • mixture of Kanji and Kana – 洗たく、けい光灯、消火せん、き裂、は握 • inflection – 行う・行なう、受付・受付け・受け付け
are written. • Conjugation is written as a rule. However, all conjugation are not always possible. • ゆく – change in -た form; we say いった instead of ゆった • ある – no negation form; we never say あらない. • かもしれない – only negation form; we never say かもしれる.
in the dictionary since there are unlimited. • However, some words are recorded in the dictionary that include number(s) in their expressions. – 一人、五分: different pronunciation – 八戸、四郎丸、六本木: place name – 一郎、百合子: person name – 一杯、十分: adverb
text collection • Originally used for linguistics to see usage of words; corpus linguistics. • Recently it's widely provided and used for language processing.
raw corpus) – No information is tagged. • tagged corpus – Morphological information is tagged. • bracketed corpus, treebank – Syntactic information is tagged as well.
with speech data and language data • mainly used for speech recognition parallel corpora • sentences in more than two languages that are corresponded • mainly used for machine translation and cross-language information retrieval
collection of text that supposed to represent the language. A wide range of domains, topics, and materials is considered and sentences are randomly selected to avoid biases. • Example: BCCWJ (Balanced Corpus of Contemporary Written Japanese) – released in 2011. 100M words. – Publication subcorpus: 35M words • books,magazines, and newspapers published during 2001-2005 – Library subcorpus: 30M words • books cataloged at more than 13 public libraries in Tokyo area, and published after 1985 – Special purpose subcorpus: 35M words • governmental whitepaper, textbook, laws, Internet (Yahoo! Q&A), Diet minutes, best selling books, etc.
– new words for machine translation dictionary • statistics – n-gram statistics and collocation statistics • instance collection – case frames and example-based machine translation • knowledge construction – thesaurus construction and grammar rule construction
get newspaper corpus etc. even when we use it only for statistical processing. Quality • hard to maintain the quality of tags. Quantity • hard to get huge amount
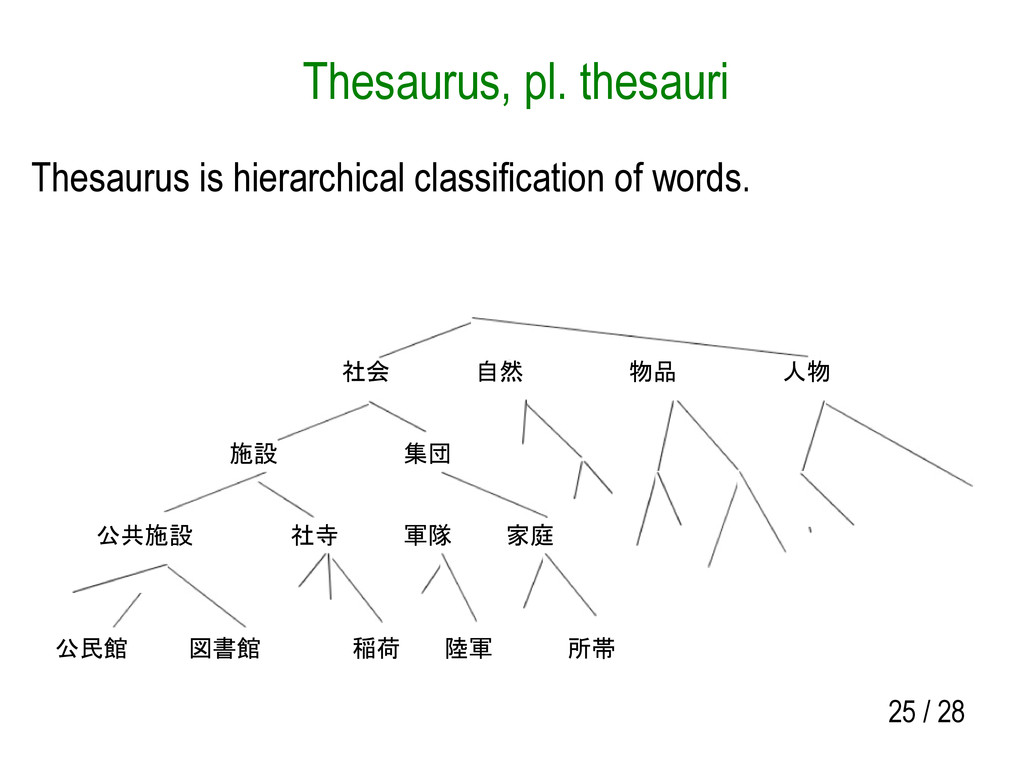
• in order to get how similar given two words, A and B, are. Generalization / normalization • in order to say two words, A and B, in one word. e.g., apple and orange are rephrased fruits. Thesaurus is the only language resources we can use for lexical semantic analysis.
and expenses • not easy of work sharing Definition • A thesaurus represents only one classification of entities; there are a lot more. Association • Thesaurus is unable to represent associative relation; e.g., summer and watermelon, hair and shampoo.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}