Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
[Journal club] Mobile-Former: Bridging MobileNe...
Search
Semantic Machine Intelligence Lab., Keio Univ.
PRO
July 27, 2022
Technology
1.3k
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
[Journal club] Mobile-Former: Bridging MobileNet and Transformer
Semantic Machine Intelligence Lab., Keio Univ.
PRO
July 27, 2022
More Decks by Semantic Machine Intelligence Lab., Keio Univ.
See All by Semantic Machine Intelligence Lab., Keio Univ.
[Journal club] Predict Before You Explore: Predictive Planning with Specialized Memory for Embodied Question Answering
keio_smilab
PRO
0
88
[Journal club] PHyCLIP: 𝒍𝟏-Product of Hyperbolic Factors Unifies Hierarchy and Compositionality in Vision-Language Representation Learning
keio_smilab
PRO
0
88
[Journal club] ReMEmbR: Building and Reasoning Over Long-Horizon Spatio-Temporal Memory for Robot Navigation
keio_smilab
PRO
0
110
[Journal club] ReLaGS: Relational Language Gaussian Splatting
keio_smilab
PRO
0
120
[Journal club] Flow as the Cross-Domain Manipulation Interface
keio_smilab
PRO
0
99
Mobi-𝜋: Mobilizing Your Robot Learning Policy
keio_smilab
PRO
0
170
A Gentle Introduction to Transformers
keio_smilab
PRO
16
7k
FlowAR: Scale-wise Autoregressive Image Generation Meets Flow Matching
keio_smilab
PRO
0
61
[Journal club] VLA-Adapter: An Effective Paradigm for Tiny-Scale Vision-Language-Action Model
keio_smilab
PRO
1
150
Other Decks in Technology
See All in Technology
AIコード生成×サプライチェーン攻撃 — PHPが直面する“二重の信頼問題
shinyasaita
0
490
書籍セキュアAPIについて
riiimparm
0
350
Vポイント分析基盤におけるデータモデリング20年史
taromatsui_cccmkhd
4
770
AI時代におけるテストの基礎の再定義 / Rethinking the Fundamentals of Testing in the AI Era
mineo_matsuya
15
5.7k
歴史から理解するクラウドインフラのしくみ
kizawa2020
0
170
プロダクト開発組織の現在地(Ver.2026/07) / product-organization
kaonavi
0
520
AI x 開発生産性を取り巻く予算戦略と投資対効果
i35_267
8
3.4k
AI驚き屋発見器
yama3133
1
330
OpenTelemetryにおけるGoのゼロコード・コンパイル時計装について #fukuokago
quiver
0
340
Webの技術とガジェットで子どもも大人も楽しめるワクワク体験を提供する / Qiita Tech Festa Day 2026
you
PRO
1
290
Git 研修【MIXI 26新卒技術研修】
mixi_engineers
PRO
1
460
AI工学特論: MLOps・継続的評価
asei
11
2.7k
Featured
See All Featured
The Art of Delivering Value - GDevCon NA Keynote
reverentgeek
16
2.1k
sira's awesome portfolio website redesign presentation
elsirapls
0
310
How to Think Like a Performance Engineer
csswizardry
28
2.7k
The Invisible Side of Design
smashingmag
301
52k
Building Applications with DynamoDB
mza
96
7.1k
What the history of the web can teach us about the future of AI
inesmontani
PRO
1
640
Facilitating Awesome Meetings
lara
57
7k
Taking LLMs out of the black box: A practical guide to human-in-the-loop distillation
inesmontani
PRO
3
2.3k
Accessibility Awareness
sabderemane
1
160
What does AI have to do with Human Rights?
axbom
PRO
1
2.3k
10 Git Anti Patterns You Should be Aware of
lemiorhan
PRO
659
62k
Reflections from 52 weeks, 52 projects
jeffersonlam
356
21k
Transcript
慶應義塾大学 杉浦孔明研究室 是方諒介 Mobile-Former: Bridging MobileNet and Transformer Yinpeng Chen1,
Xiyang Dai1, Dongdong Chen1, Mengchen Liu1, Xiaoyi Dong2, Lu Yuan1, Zicheng Liu1 (1Microsoft, 2University of Science and Technology of China) CVPR 2022 Yinpeng Chen, Xiyang Dai, Dongdong Chen, Mengchen Liu, Xiaoyi Dong, Lu Yuan, and Zicheng Liu. "Mobile-Former: Bridging MobileNet and Transformer." CVPR 2022.
目標 ◼ 画像認識モデルを実世界アプリに組込む 課題 ◼ エッジデバイスでは、処理能力/実行時間に限界 ◼ 計算力をサーバに頼ると、個人情報やセキュリティ面で懸念 解決策 ◼
軽量かつ(ある程度)高性能なモデルの確立 背景:低計算コストかつ高精度の画像認識モデルの需要 2
関連研究:計算量/性能面で改善の余地 3 Model Detail MobileNetV1, V2, V3 [Howard+ 17], [Sandler+
18], [Howard+ ICCV19] ・携帯電話での利用を想定した軽量CNNモデル ・convolutionをdepthwiseとpointwiseに分割 ViT [Dosovitskiy+ ICLR21] ・transformer [Vaswani+ NeurIPS17] を画像分類に応用 CvT [Wu+ ICCV21] ・multi-head attentionの前にconvolutionを導入 CvT ① CNN ② transformer ③ CNN & transformer ViT
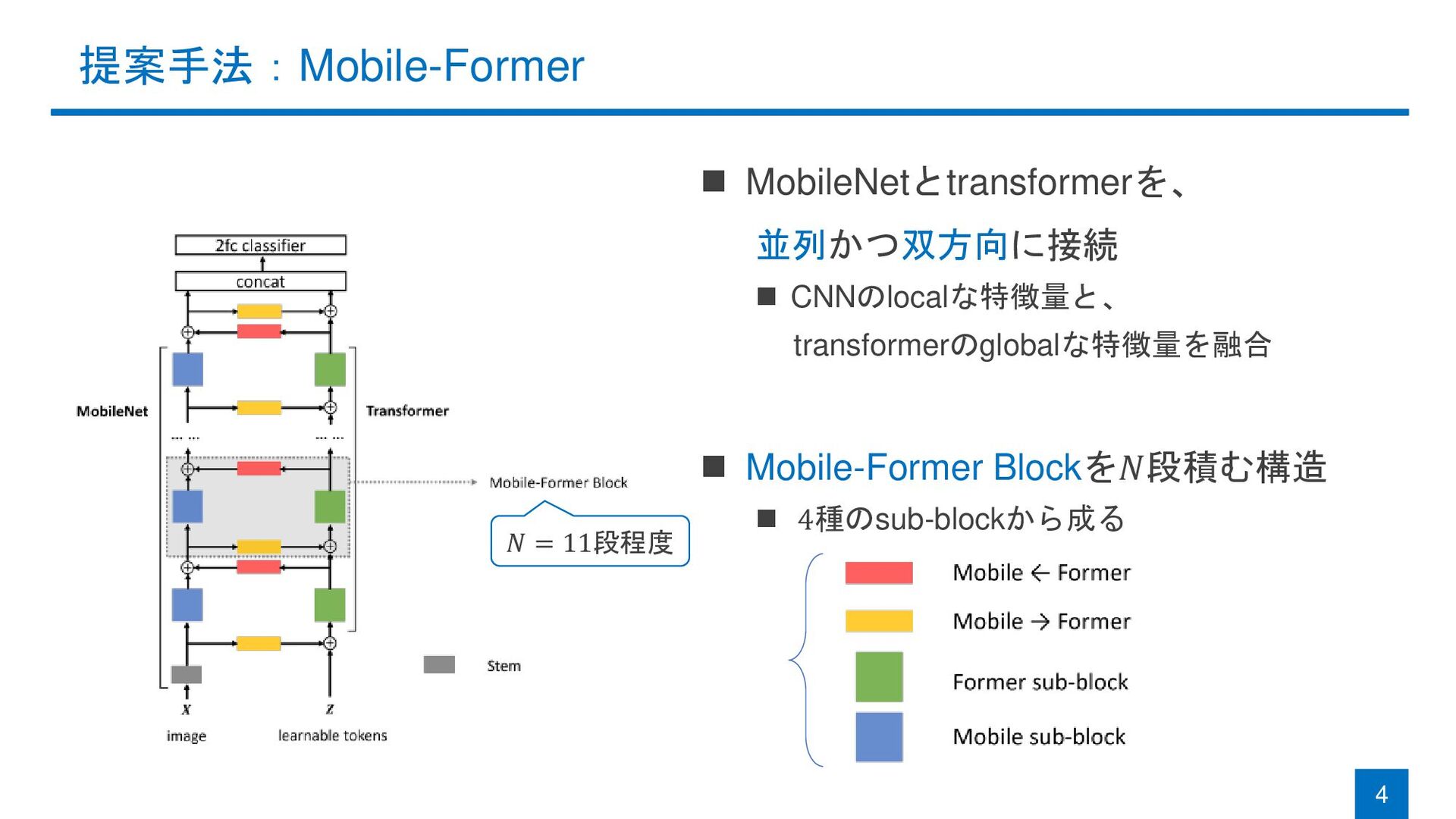
提案手法:Mobile-Former ◼ MobileNetとtransformerを、 並列かつ双方向に接続 ◼ CNNのlocalな特徴量と、 transformerのglobalな特徴量を融合 ◼ Mobile-Former Blockを𝑁段積む構造
◼ 4種のsub-blockから成る 4 𝑁 = 11段程度
モデル全体の入出力:画像と学習可能なトークン → 分類ラベル ◼ 入力 ① 𝑿 ∈ ℝ𝐻𝑊×3:画像 ②
𝒁 ∈ ℝ𝑀×𝑑:学習可能なトークン ◼ ランダムに初期化 ◼ 出力 ◼ 𝑿, 𝒁をconcatしてFC層× 2 ◼ 活性化関数はh-swish [Howard+ ICCV19] 5 𝐻:高さ 𝑊:幅 𝑀 (≤ 6):トークン数 𝑑:トークンの次元 𝑀の小ささが対ViT 計算コスト減の要因 3 × 3 convolution層
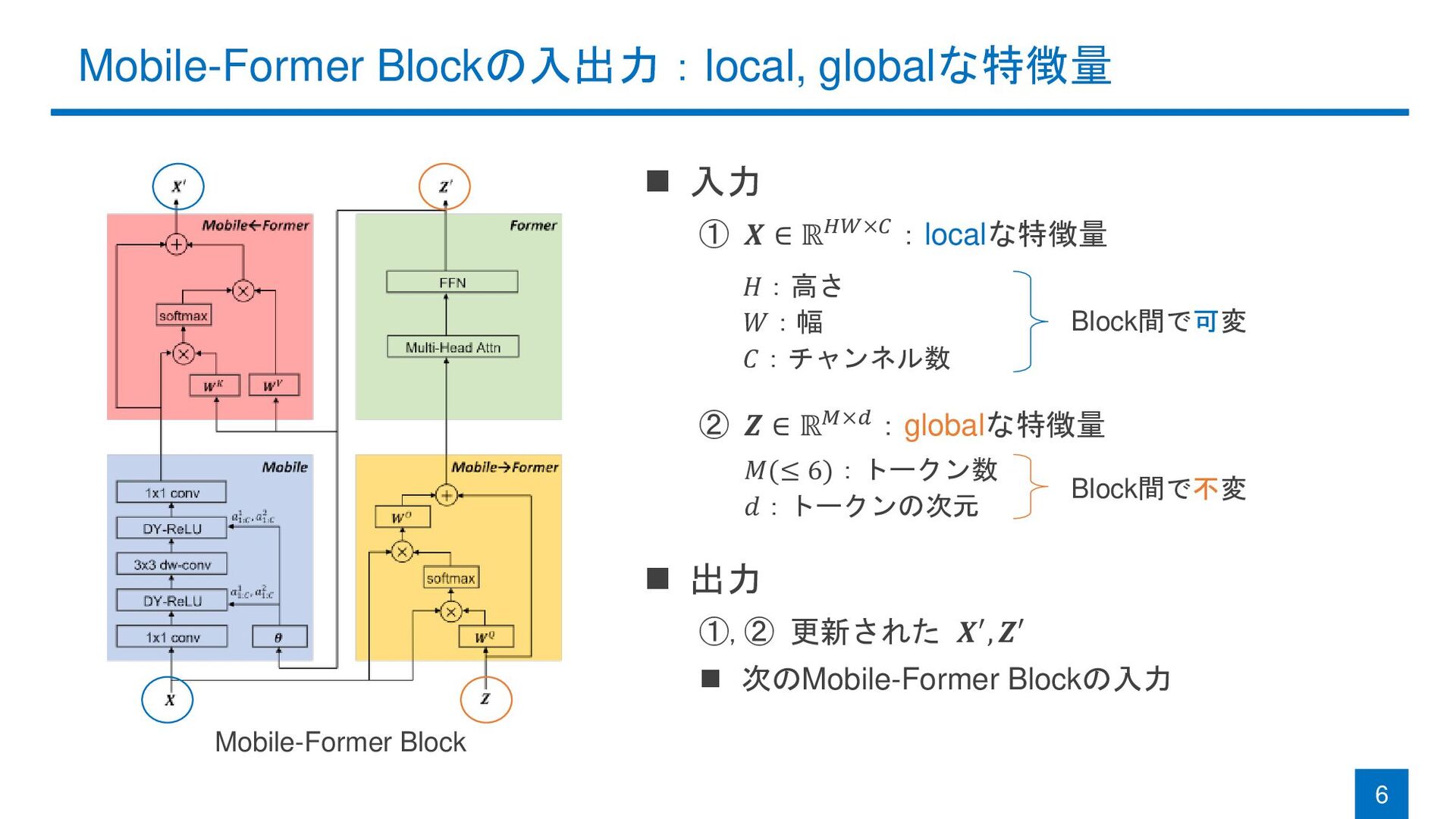
Mobile-Former Blockの入出力:local, globalな特徴量 6 Mobile-Former Block ◼ 入力 ① 𝑿
∈ ℝ𝐻𝑊×𝐶:localな特徴量 ② 𝒁 ∈ ℝ𝑀×𝑑:globalな特徴量 ◼ 出力 ①,② 更新された 𝑿′, 𝒁′ ◼ 次のMobile-Former Blockの入力 𝑀(≤ 6):トークン数 𝑑:トークンの次元 Block間で可変 Block間で不変 𝐻:高さ 𝑊:幅 𝐶:チャンネル数
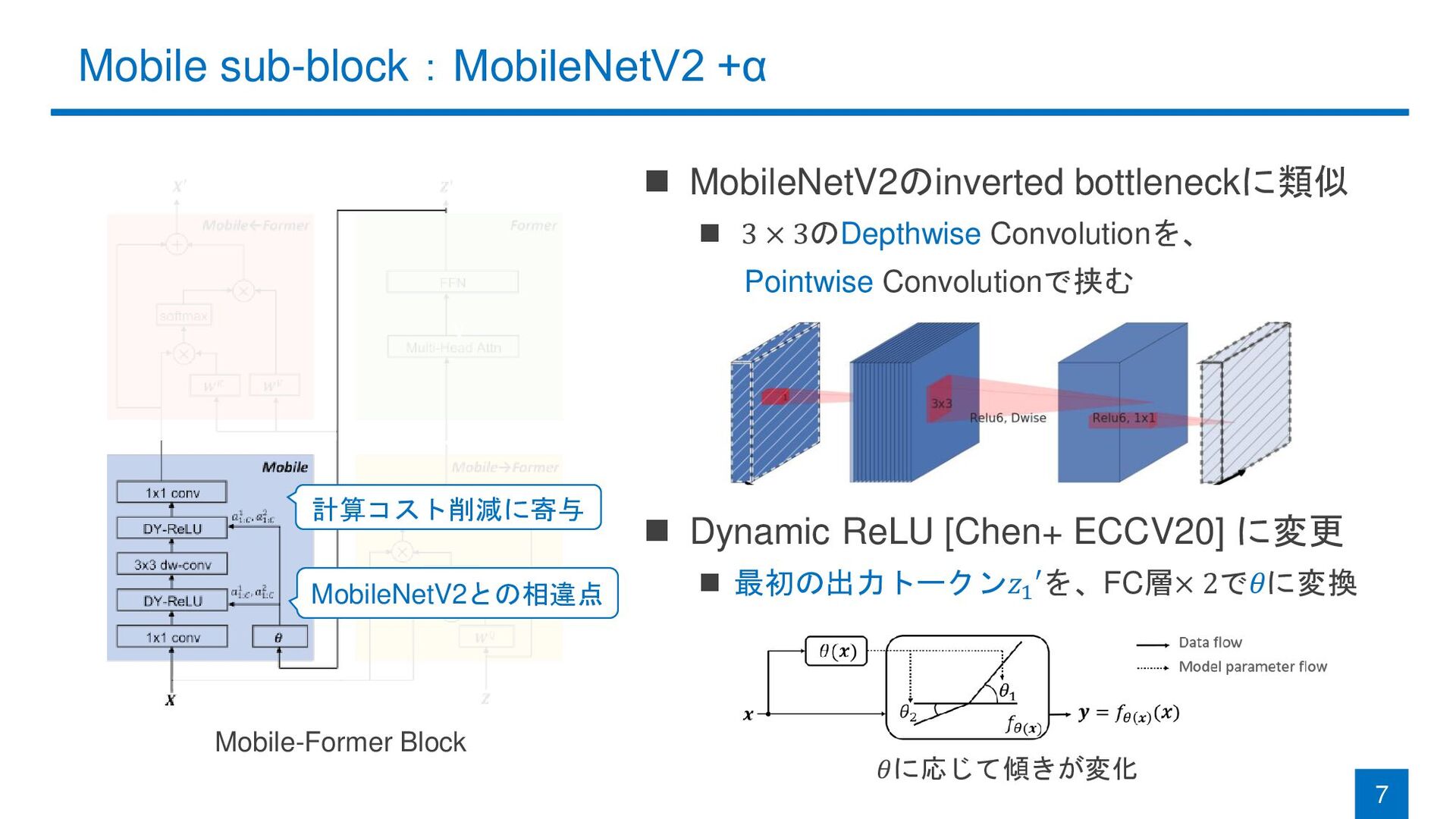
Mobile sub-block:MobileNetV2 +α 7 Mobile-Former Block ◼ MobileNetV2のinverted bottleneckに類似 ◼
3 × 3のDepthwise Convolutionを、 Pointwise Convolutionで挟む ◼ Dynamic ReLU [Chen+ ECCV20] に変更 ◼ 最初の出力トークン𝑧1 ′を、FC層× 2で𝜃に変換 v 計算コスト削減に寄与 MobileNetV2との相違点 𝜃に応じて傾きが変化
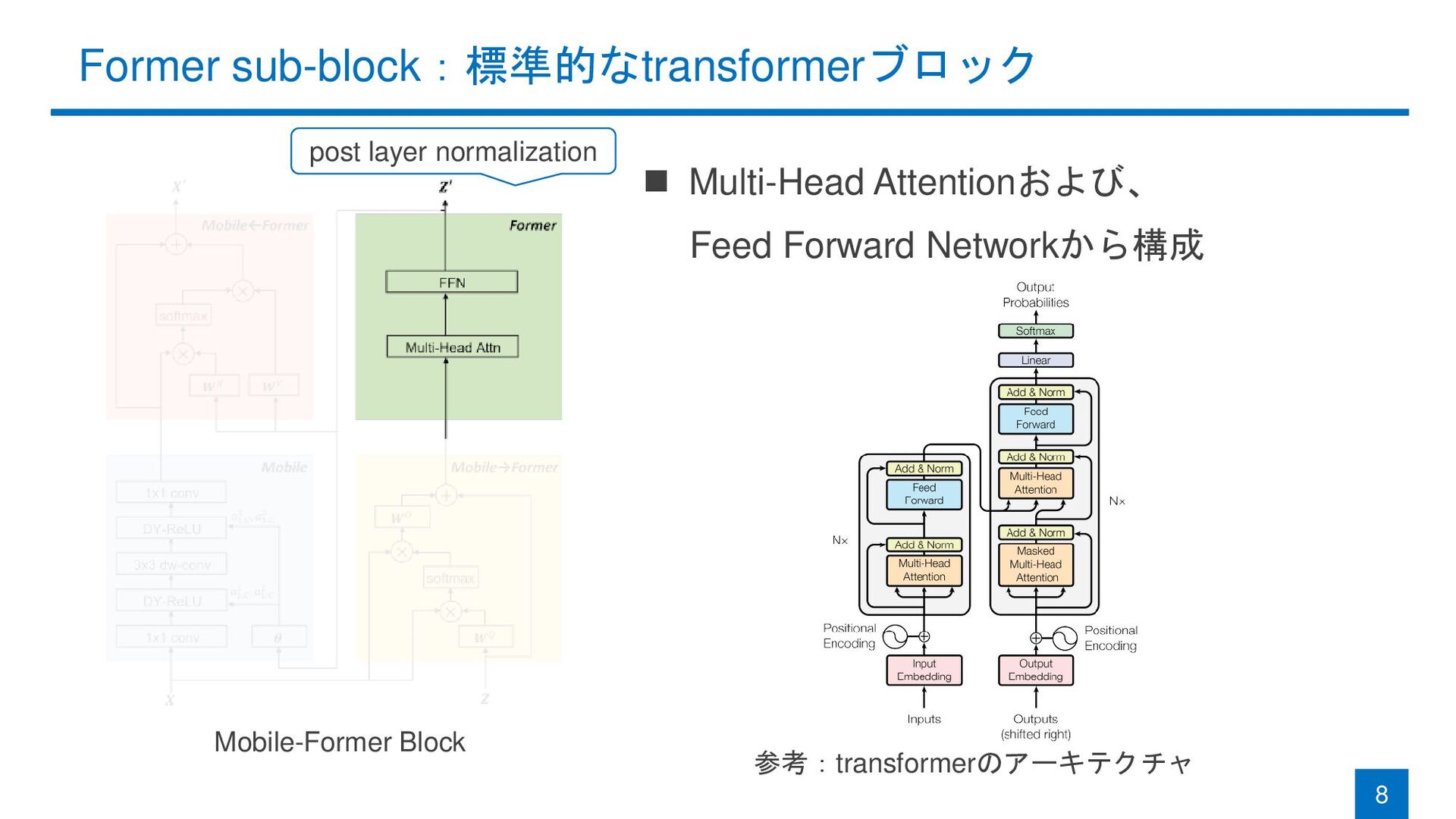
Former sub-block:標準的なtransformerブロック 8 Mobile-Former Block ◼ Multi-Head Attentionおよび、 Feed Forward
Networkから構成 参考:transformerのアーキテクチャ post layer normalization
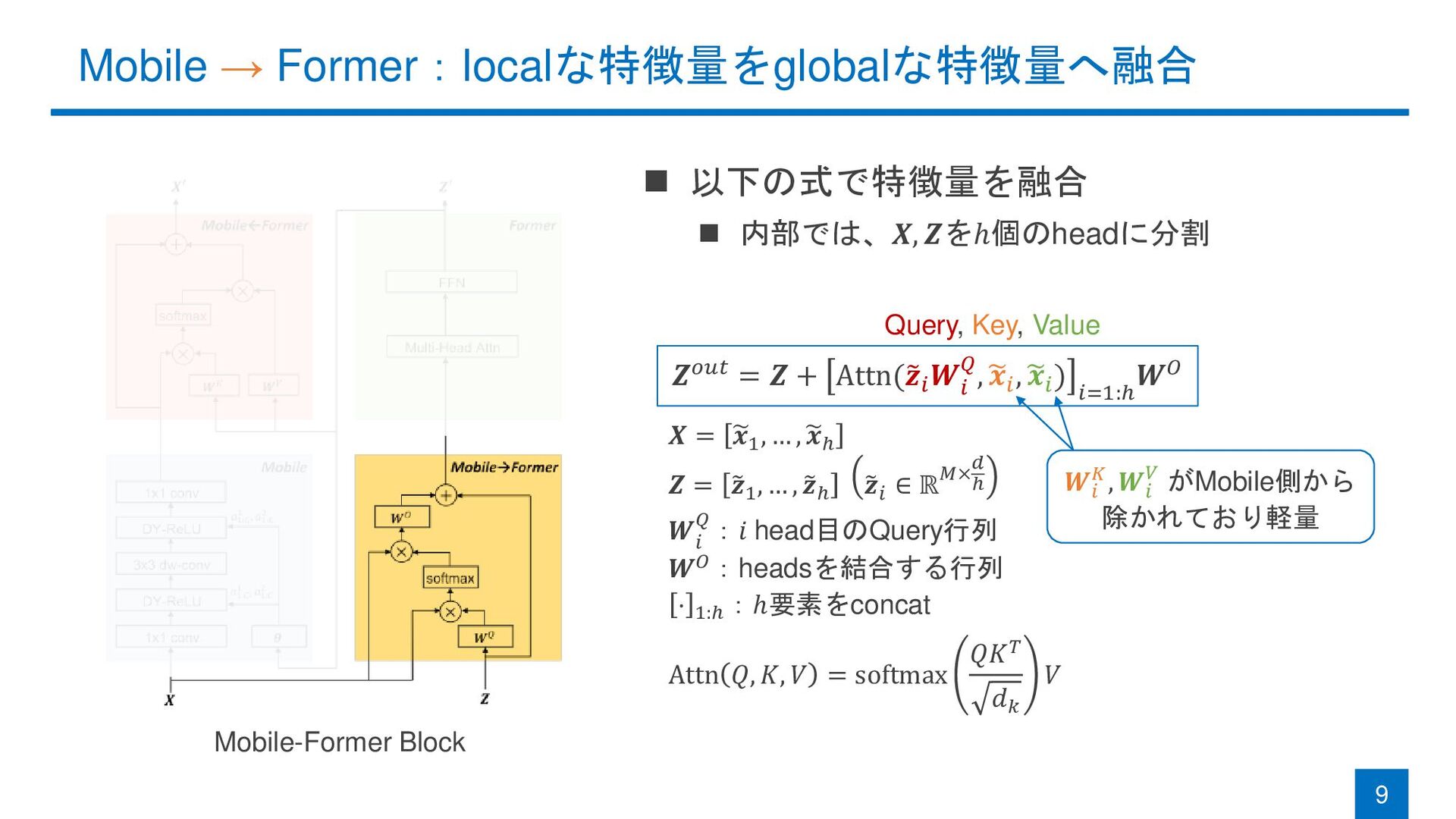
Mobile → Former:localな特徴量をglobalな特徴量へ融合 9 Mobile-Former Block ◼ 以下の式で特徴量を融合 ◼ 内部では、𝑿,
𝒁をℎ個のheadに分割 𝒁𝑜𝑢𝑡 = 𝒁 + Attn( 𝒛𝑖 𝑾 𝑖 𝑄, 𝒙𝑖 , 𝒙𝑖 ) 𝑖=1:ℎ 𝑾𝑂 𝑿 = 𝒙1 , … , 𝒙ℎ 𝒁 = 𝒛1 , … , 𝒛ℎ 𝒛𝑖 ∈ ℝ𝑀× 𝑑 ℎ 𝑾 𝑖 𝑄:𝑖 head目のQuery行列 𝑾𝑂:headsを結合する行列 ⋅ 1:ℎ :ℎ要素をconcat Attn 𝑄, 𝐾, 𝑉 = softmax 𝑄𝐾𝑇 𝑑𝑘 𝑉 Query, Key, Value 𝑾𝑖 𝐾, 𝑾𝑖 𝑉 がMobile側から 除かれており軽量
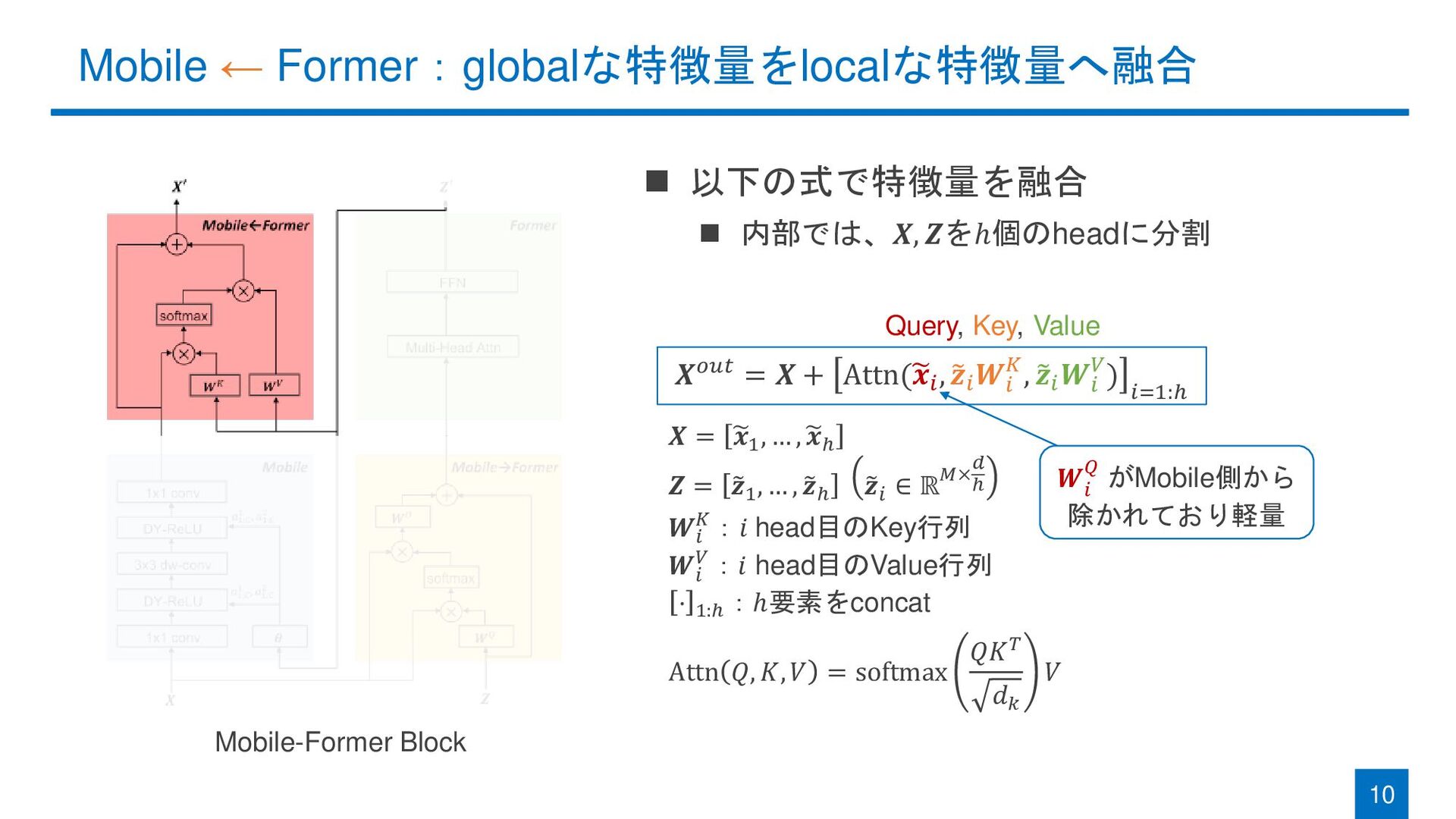
◼ 以下の式で特徴量を融合 ◼ 内部では、𝑿, 𝒁をℎ個のheadに分割 Mobile ← Former:globalな特徴量をlocalな特徴量へ融合 10 Mobile-Former
Block 𝑿𝑜𝑢𝑡 = 𝑿 + Attn( 𝒙𝑖 , 𝒛𝑖 𝑾𝑖 𝐾, 𝒛𝑖 𝑾𝑖 𝑉) 𝑖=1:ℎ 𝑿 = 𝒙1 , … , 𝒙ℎ 𝒁 = 𝒛1 , … , 𝒛ℎ 𝒛𝑖 ∈ ℝ𝑀× 𝑑 ℎ 𝑾𝑖 𝐾:𝑖 head目のKey行列 𝑾𝑖 𝑉:𝑖 head目のValue行列 ⋅ 1:ℎ :ℎ要素をconcat Attn 𝑄, 𝐾, 𝑉 = softmax 𝑄𝐾𝑇 𝑑𝑘 𝑉 Query, Key, Value 𝑾 𝑖 𝑄 がMobile側から 除かれており軽量
◼ 実験:ImageNet [Deng+ CVPR09] における画像分類 ◼ 計算コストが近いモデル同士で比較 定量的結果:対CNN/ViTともに計算コスト/性能で優位 11 Multiply-Adds:計算コストの指標
Model #Params↓ MAdds↓ Top-1↑ ShuffleNetV2 1.5× [Ma+ ECCV18] 3.5M 299M 72.6 MobileNetV3 1.25× [Howard+ ICCV19] 7.5M 356M 76.6 ViTC [Xiao+ NeurIPS21] 4.6M 1.1G 75.3 ConT-S [Yan+ CoRR21] 10.1M 1.5G 76.5 Mobile-Former-294M 11.4M 294M 77.9 CNN ViT
追試およびエラー分析(定性的結果):小さな類似物体の認識が課題 12 ◼ 類似の発展手法:MobileViT [Mehta+ ICLR22] ◼ データセット:花の5クラス画像分類(tf_flowers) ◼ 改善案:localな特徴量をより重視するため、CNNの寄与を向上
https://huggingface.co/spaces/keras-io/Flowers-Classification-MobileViT 予測:“sunflower” 正解:“dandelion” “rose” “tulip”
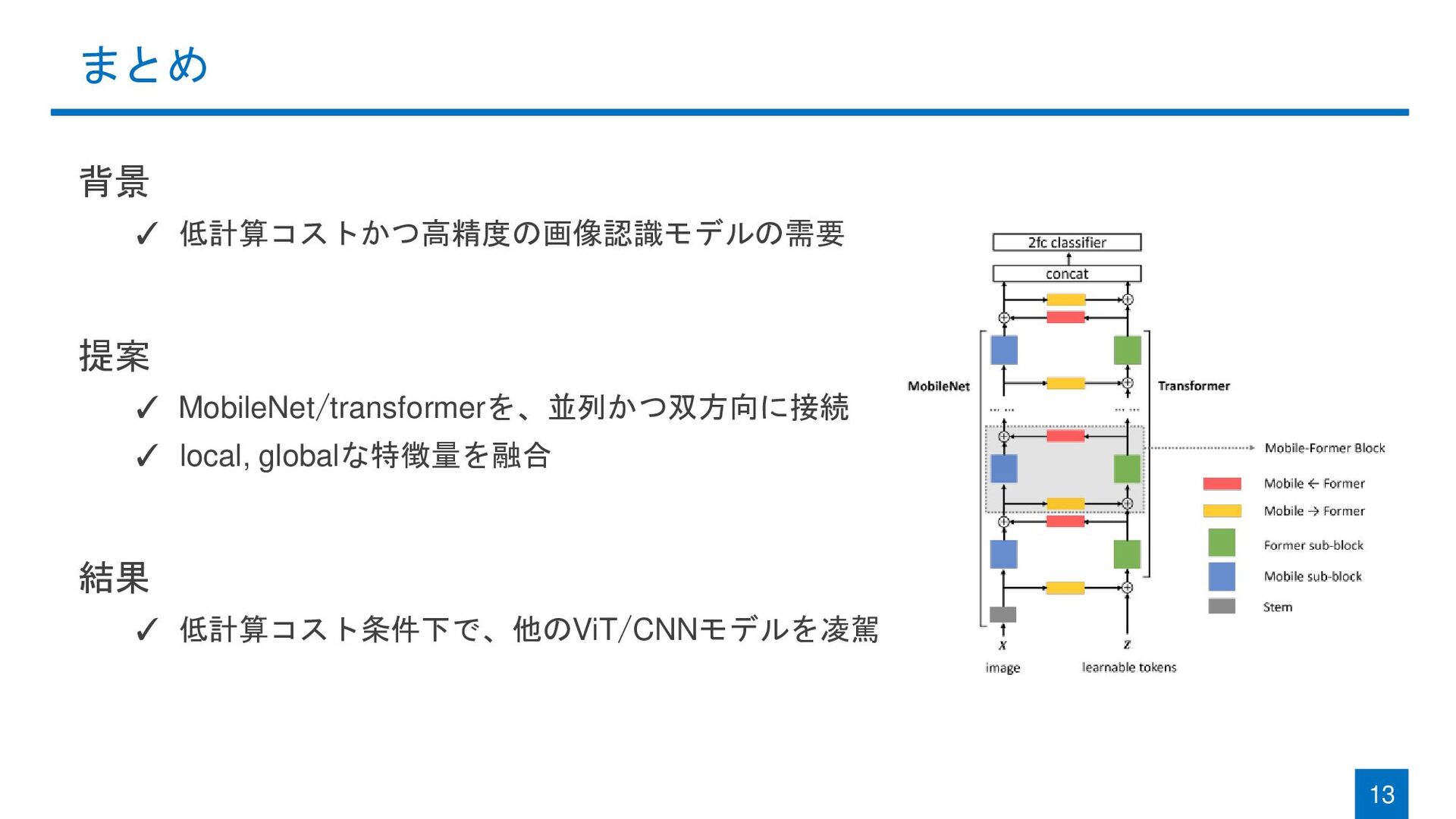
まとめ 背景 ✓ 低計算コストかつ高精度の画像認識モデルの需要 提案 ✓ MobileNet/transformerを、並列かつ双方向に接続 ✓ local, globalな特徴量を融合
結果 ✓ 低計算コスト条件下で、他のViT/CNNモデルを凌駕 13
Appendix:実験設定 ◼ データセット:ImageNet ◼ 1000クラス分類 ◼ 224 × 224画像 実験1:対主要なCNNモデル
◼ MAddsについて26M~508Mのグループに区切り、近いもの同士で比較 実験2:対主要なViT派生モデル ◼ 蒸留なしで比較 14
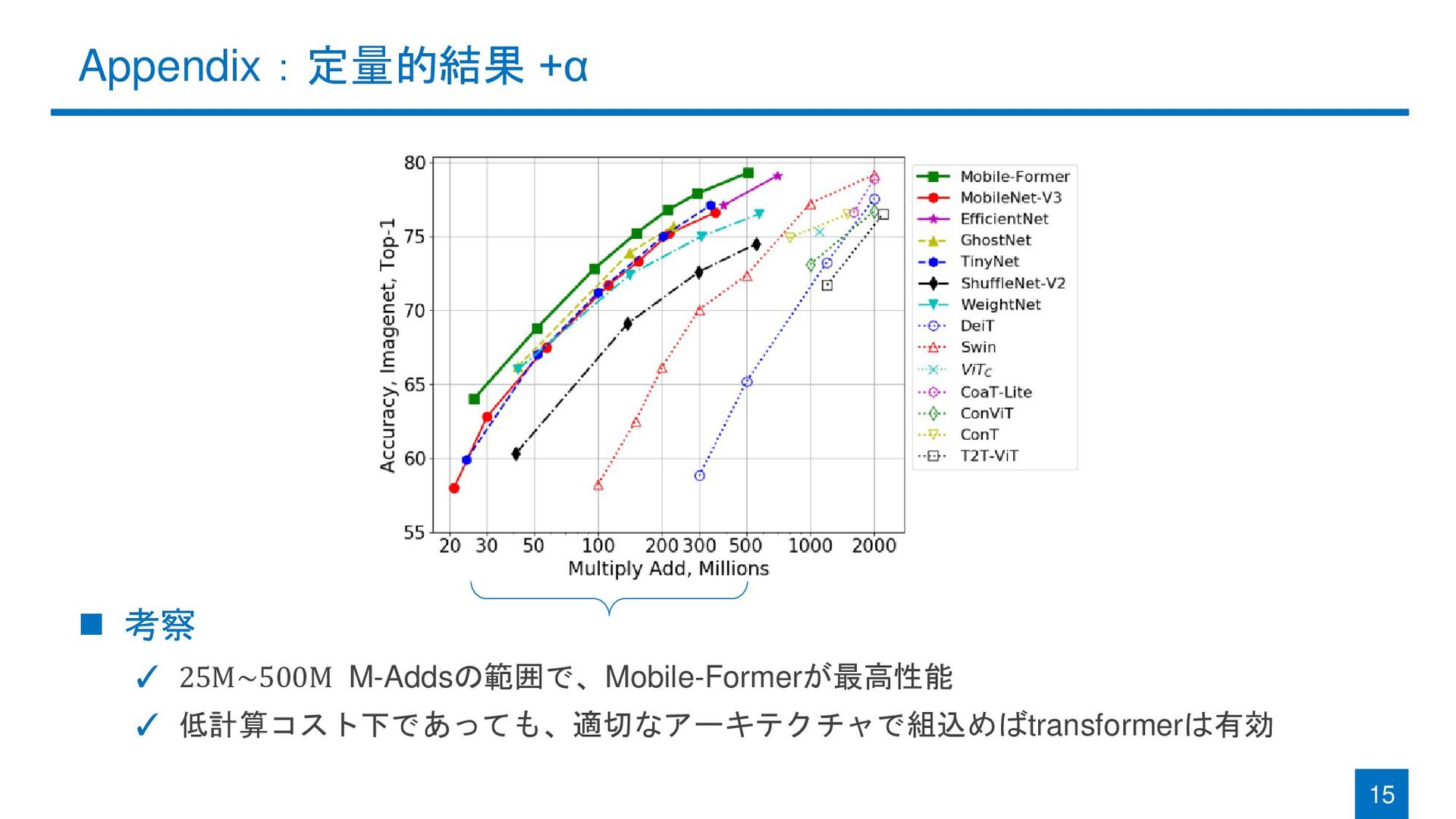
Appendix:定量的結果 +α ◼ 考察 ✓ 25M~500M M-Addsの範囲で、Mobile-Formerが最高性能 ✓ 低計算コスト下であっても、適切なアーキテクチャで組込めばtransformerは有効 15
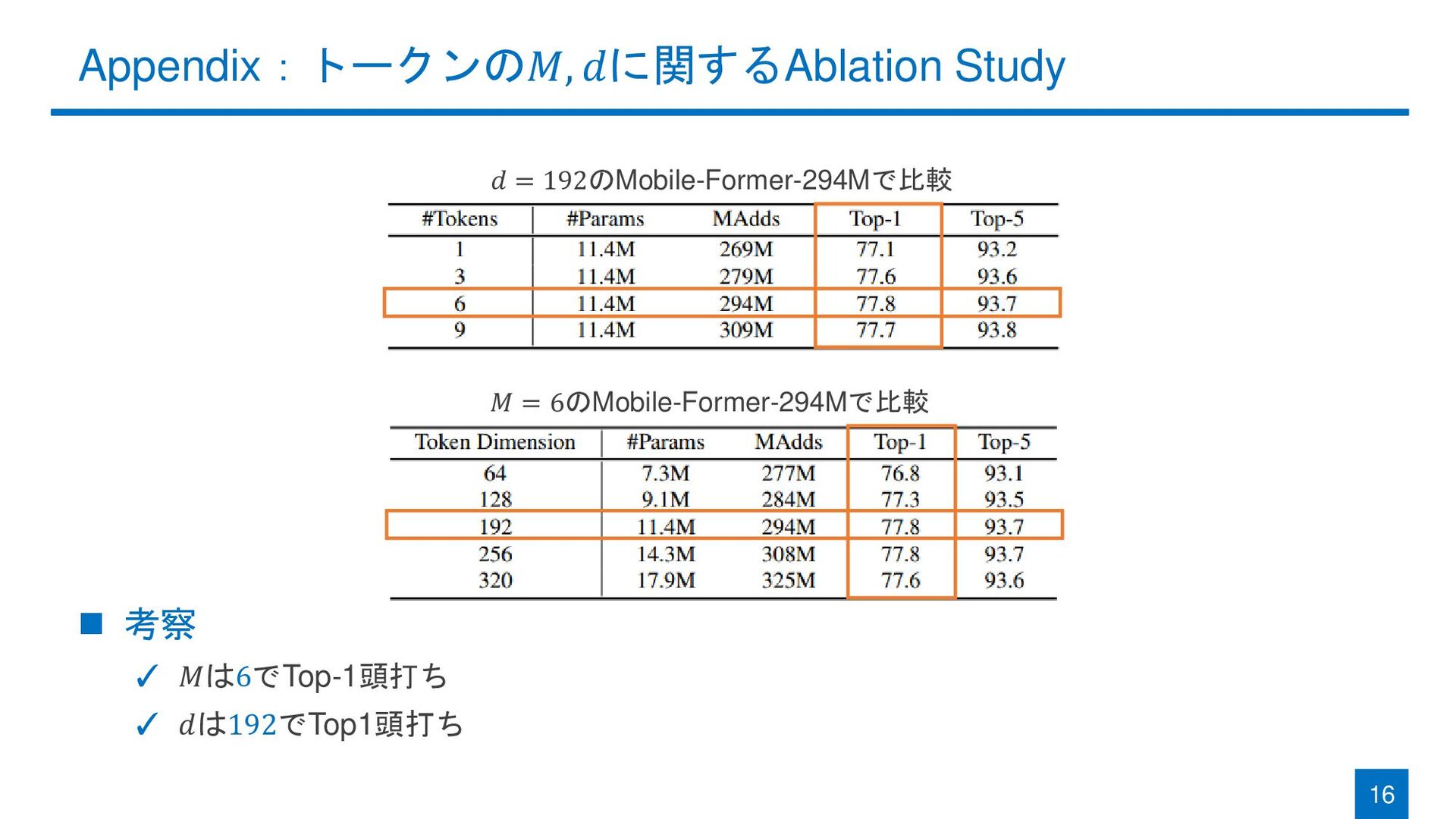
Appendix:トークンの𝑀, 𝑑に関するAblation Study ◼ 考察 ✓ 𝑀は6でTop-1頭打ち ✓ 𝑑は192でTop1頭打ち 16
𝑑 = 192のMobile-Former-294Mで比較 𝑀 = 6のMobile-Former-294Mで比較
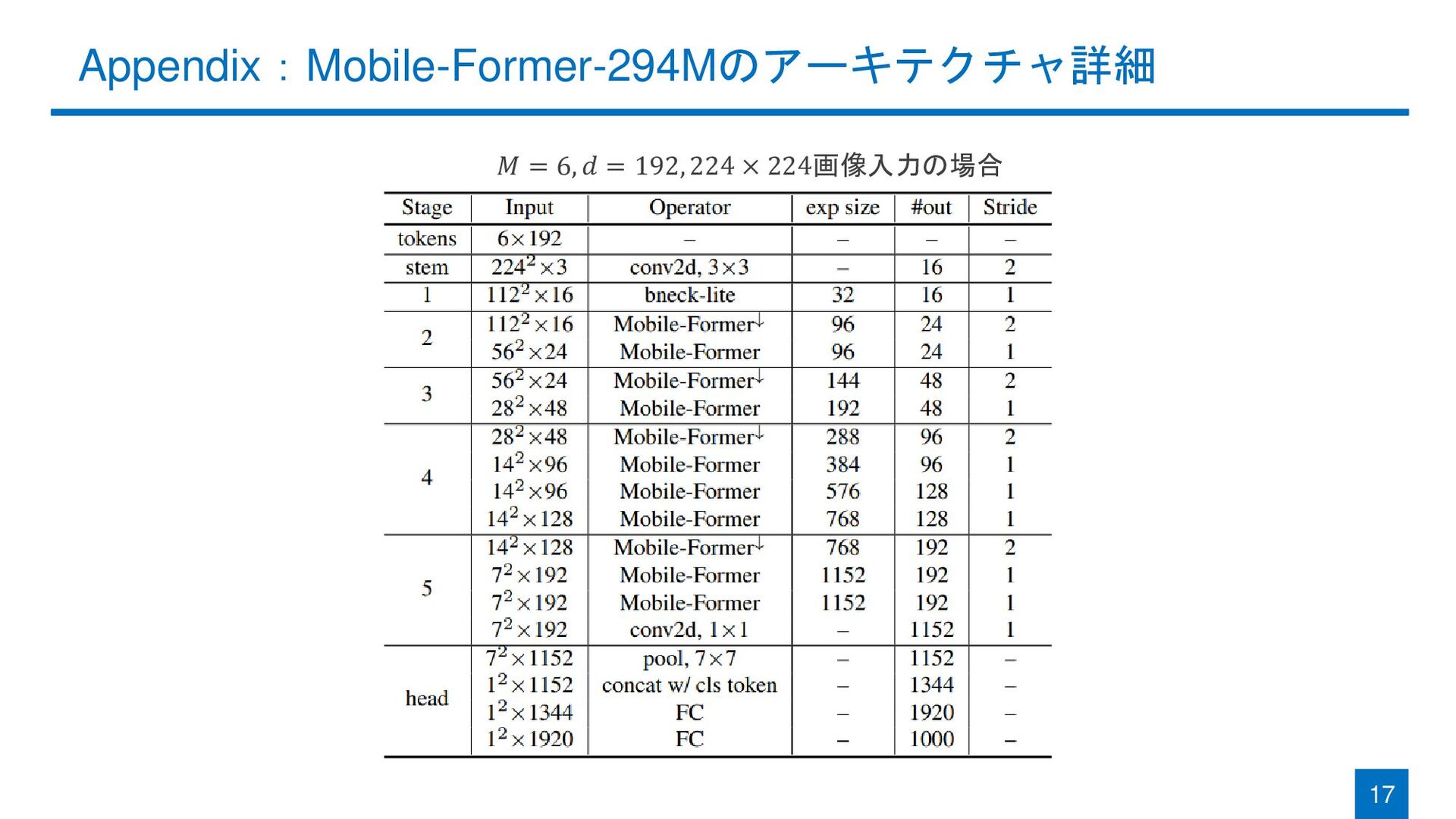
Appendix:Mobile-Former-294Mのアーキテクチャ詳細 17 𝑀 = 6, 𝑑 = 192, 224 ×
224画像入力の場合
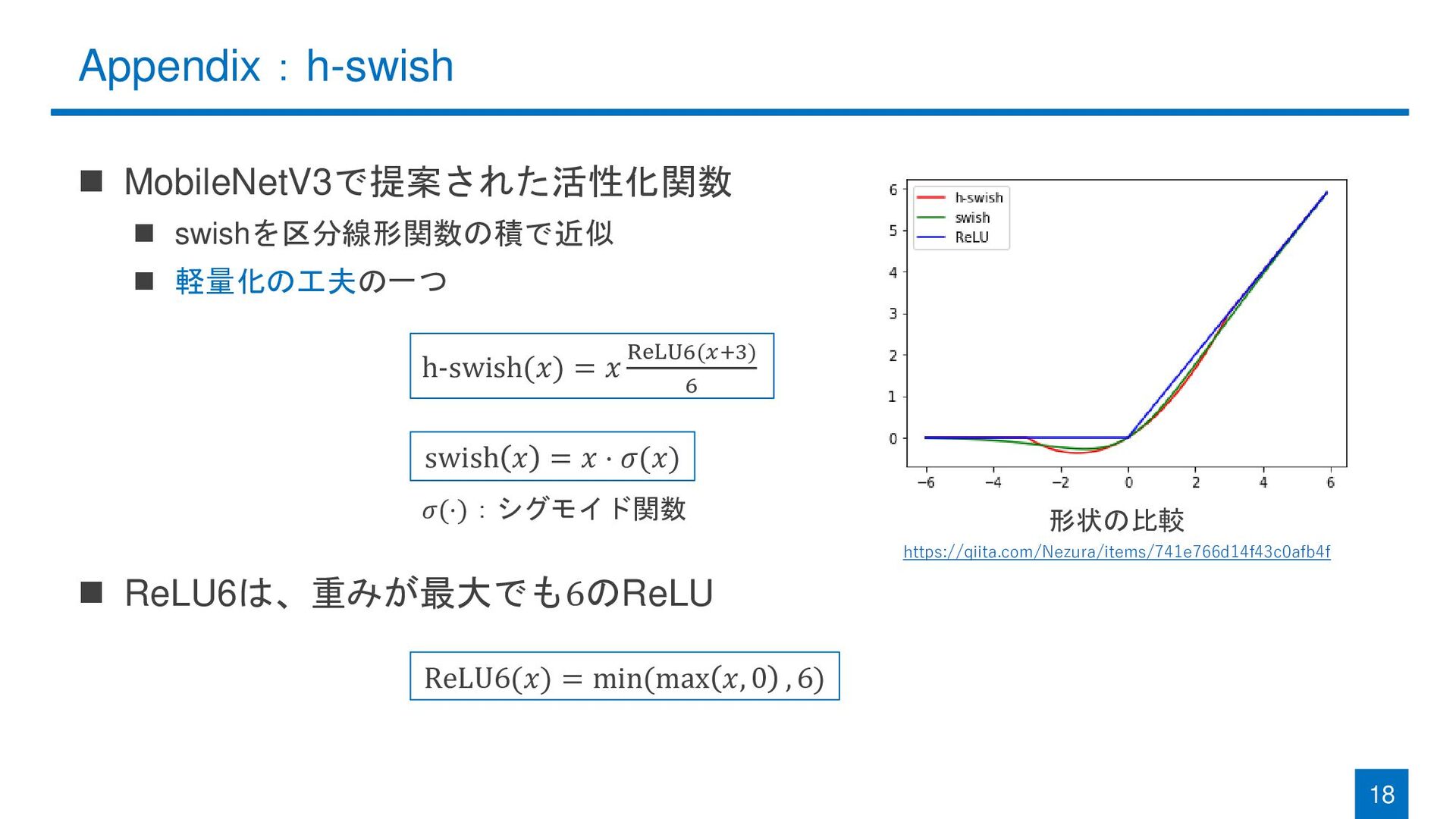
Appendix:h-swish ◼ MobileNetV3で提案された活性化関数 ◼ swishを区分線形関数の積で近似 ◼ 軽量化の工夫の一つ ◼ ReLU6は、重みが最大でも6のReLU 18
h-swish(𝑥) = 𝑥 ReLU6(𝑥+3) 6 ReLU6(𝑥) = min(max 𝑥, 0 , 6) https://qiita.com/Nezura/items/741e766d14f43c0afb4f swish 𝑥 = 𝑥 ⋅ 𝜎(𝑥) 𝜎(⋅):シグモイド関数 形状の比較
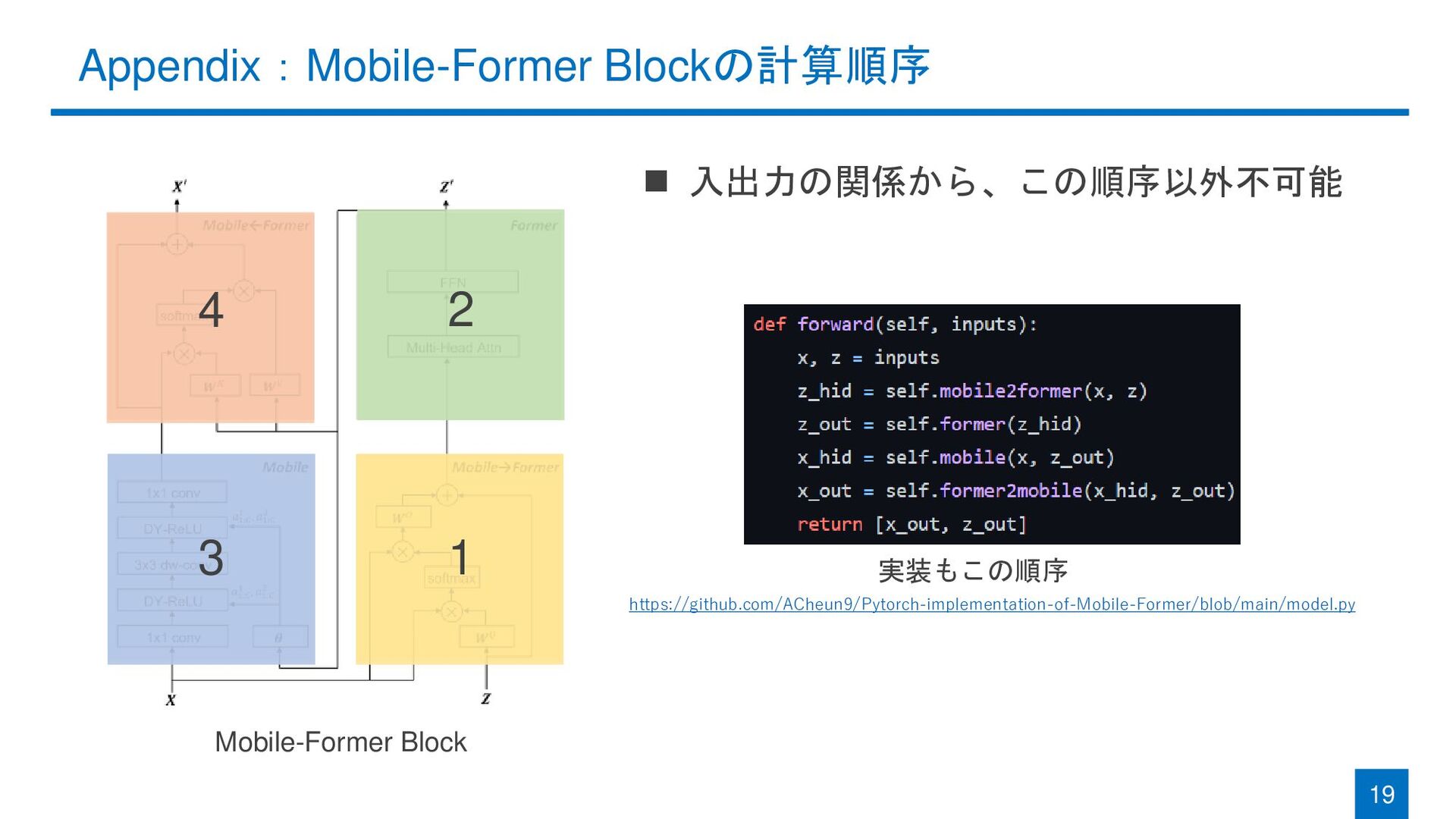
Appendix:Mobile-Former Blockの計算順序 19 Mobile-Former Block ◼ 入出力の関係から、この順序以外不可能 1 2 3
4 実装もこの順序 https://github.com/ACheun9/Pytorch-implementation-of-Mobile-Former/blob/main/model.py
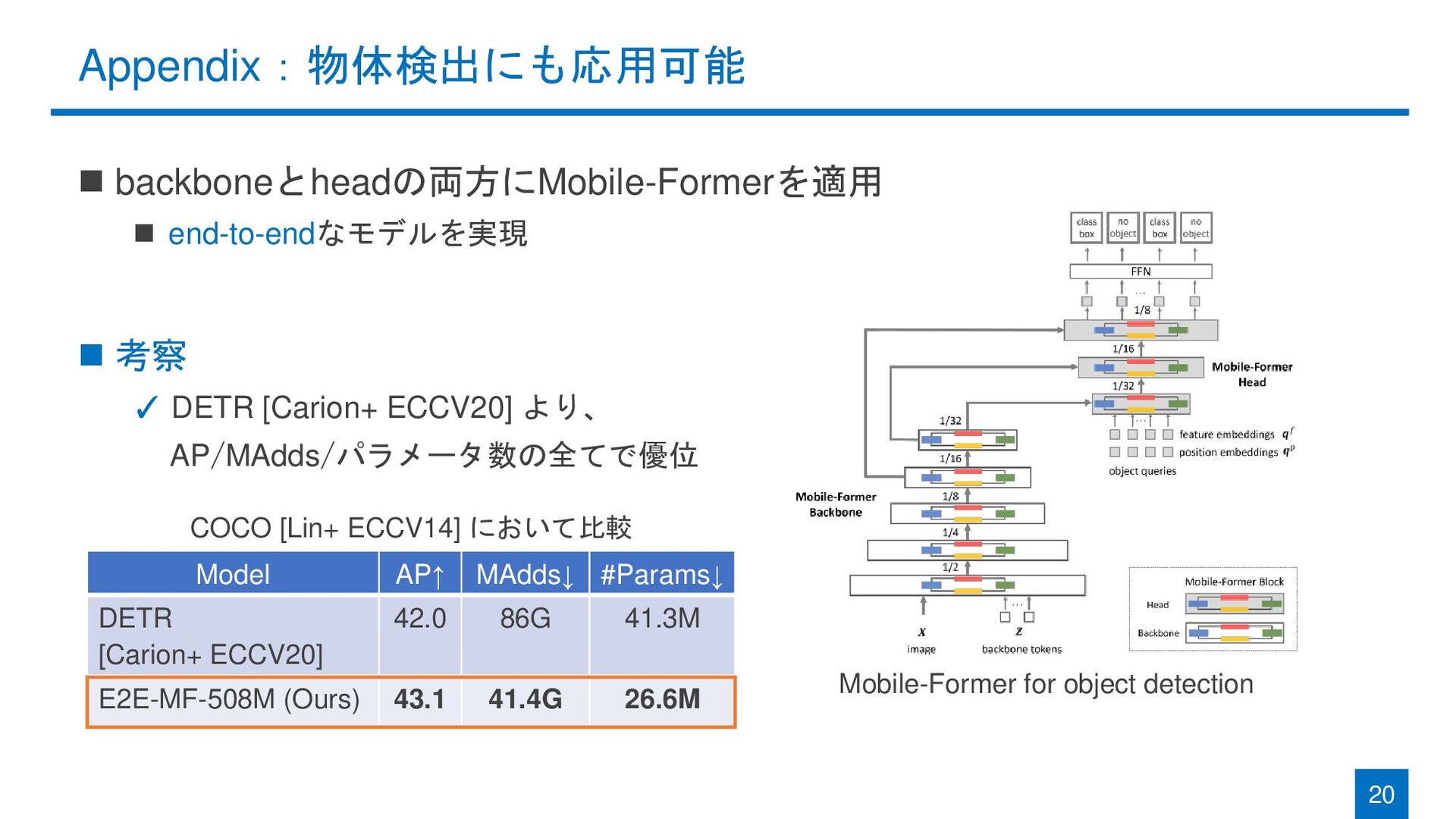
Appendix:物体検出にも応用可能 ◼ backboneとheadの両方にMobile-Formerを適用 ◼ end-to-endなモデルを実現 ◼ 考察 ✓ DETR [Carion+
ECCV20] より、 AP/MAdds/パラメータ数の全てで優位 20 Mobile-Former for object detection COCO [Lin+ ECCV14] において比較 Model AP↑ MAdds↓ #Params↓ DETR [Carion+ ECCV20] 42.0 86G 41.3M E2E-MF-508M (Ours) 43.1 41.4G 26.6M
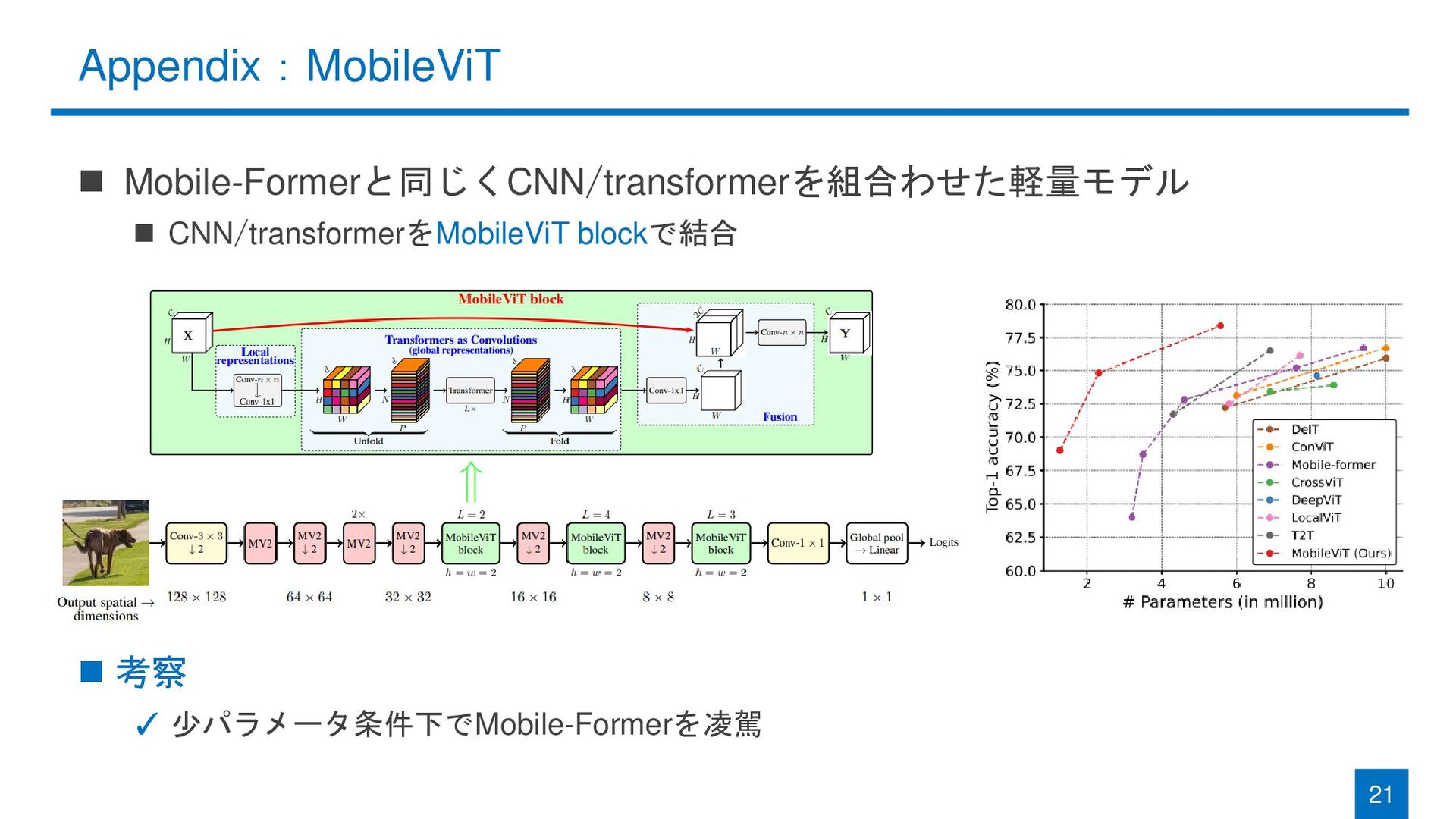
Appendix:MobileViT ◼ Mobile-Formerと同じくCNN/transformerを組合わせた軽量モデル ◼ CNN/transformerをMobileViT blockで結合 ◼ 考察 ✓ 少パラメータ条件下でMobile-Formerを凌駕
21
{kind=link}
{kind=link}
![関連研究:計算量/性能面で改善の余地 3 Model Detail MobileNetV1, V2, V3 [Howard+ 17], [Sandler+](https://files.speakerdeck.com/presentations/859abebfd5d440d0927705e0a1bcb7bf/slide_2.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![◼ 実験:ImageNet [Deng+ CVPR09] における画像分類 ◼ 計算コストが近いモデル同士で比較 定量的結果:対CNN/ViTともに計算コスト/性能で優位 11 Multiply-Adds:計算コストの指標](https://files.speakerdeck.com/presentations/859abebfd5d440d0927705e0a1bcb7bf/slide_10.jpg){kind=link}
![追試およびエラー分析(定性的結果):小さな類似物体の認識が課題 12 ◼ 類似の発展手法:MobileViT [Mehta+ ICLR22] ◼ データセット:花の5クラス画像分類(tf_flowers) ◼ 改善案:localな特徴量をより重視するため、CNNの寄与を向上](https://files.speakerdeck.com/presentations/859abebfd5d440d0927705e0a1bcb7bf/slide_11.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}