= 0 se e somente se = 0, III. = , IV. + ≤ + . Lembrem-se: Uma norma num espaço vetorial é uma função ∙ ∶ → ℝ satisfazendo: É a forma de medir tamanho de vetores!
. Basta garantir as quatro propriedades relacionadas pelo Galileu. Já conferimos que o conjunto ℳ× das matrizes × com a adição de matrizes e a multiplicação por fator de escala é um espaço vetorial.
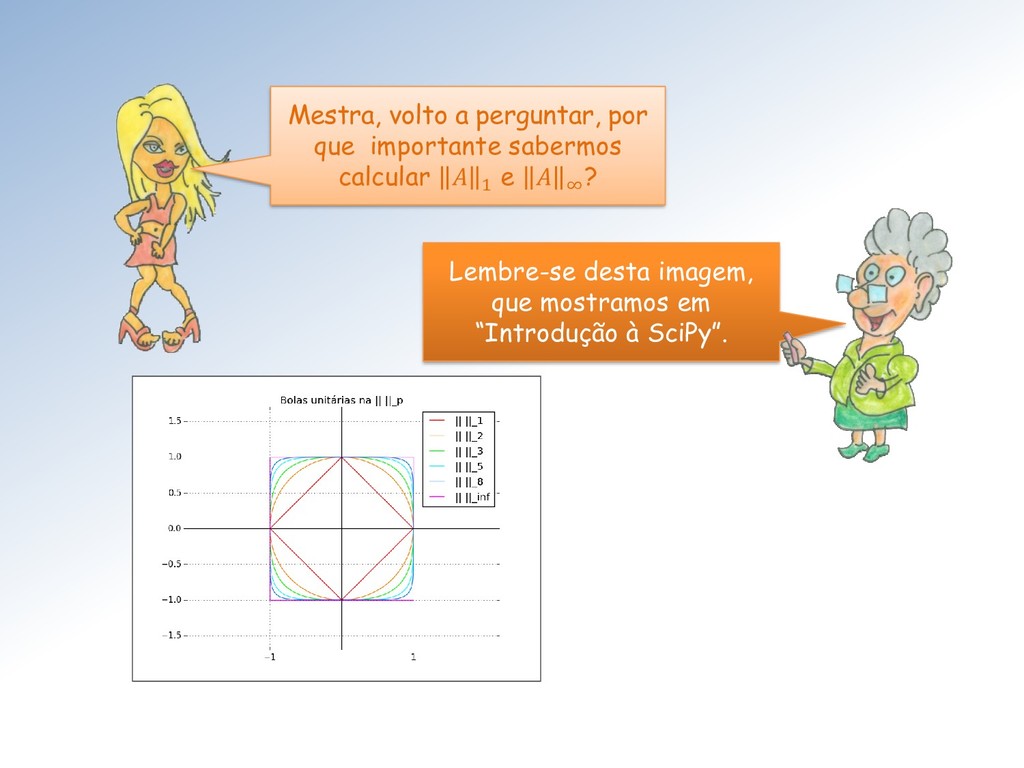
uma norma em ℝ, então a função × : ℳ× → ℝ definida por ⟼ × = sup ≠0 é uma norma em ℳ× . É uma norma matricial denominada norma matricial induzida (pelas normas em ℝ e ℝ).
= 1. Portanto isto também vale para o supremo: + = sup =1 + ≤ + . Brilhante Cabelos de Fogo! Assim é válida a exigência IV, a desigualdade triangular: + ≤ + , ∀, ∈ ℳ× .
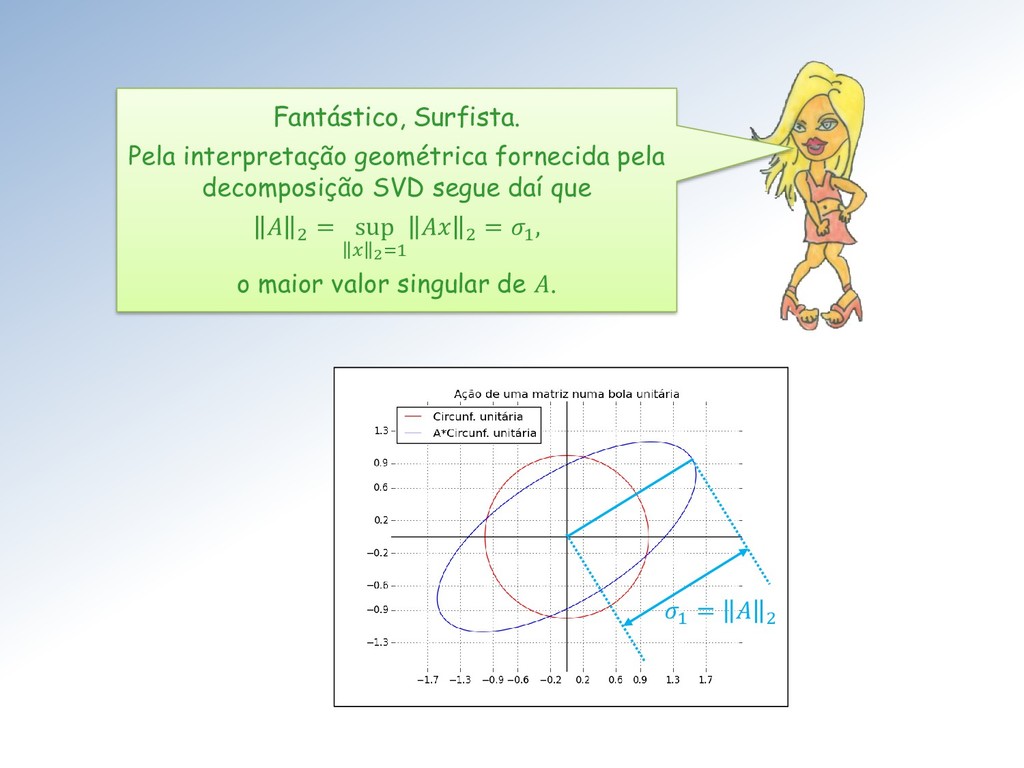
Você mesma concluiu que a 2 de uma matriz é o seu maior valor singular 1 . E o cálculo de valores singulares é difícil e trabalhoso. Assim, precisaremos contornar esse problema.
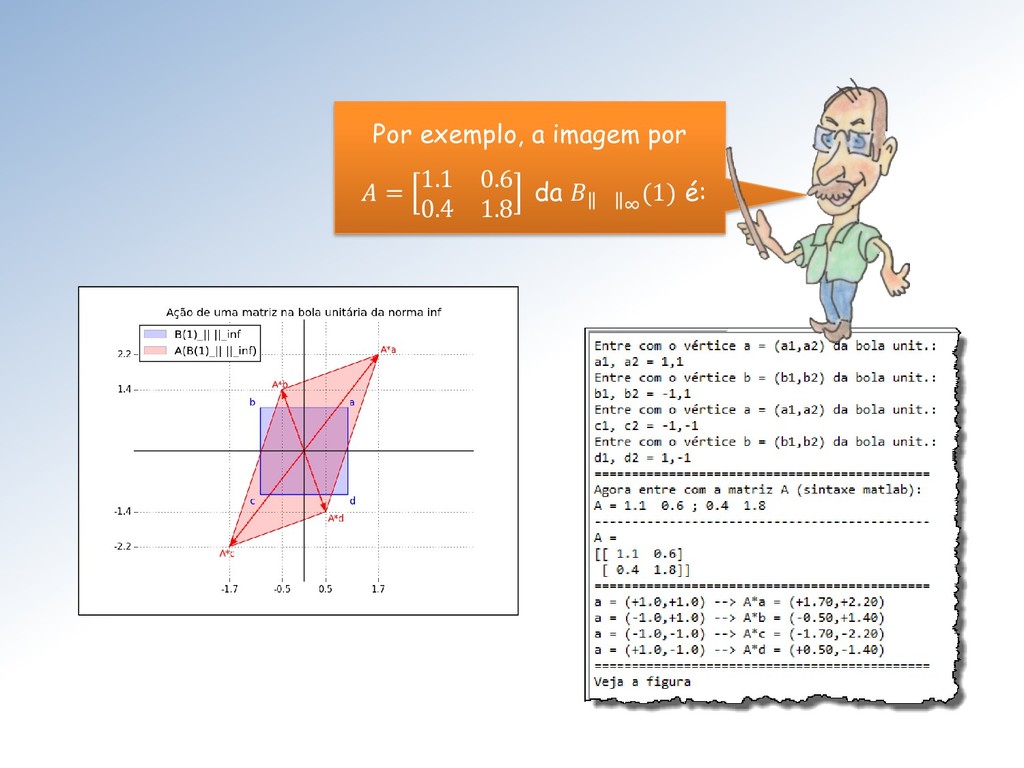
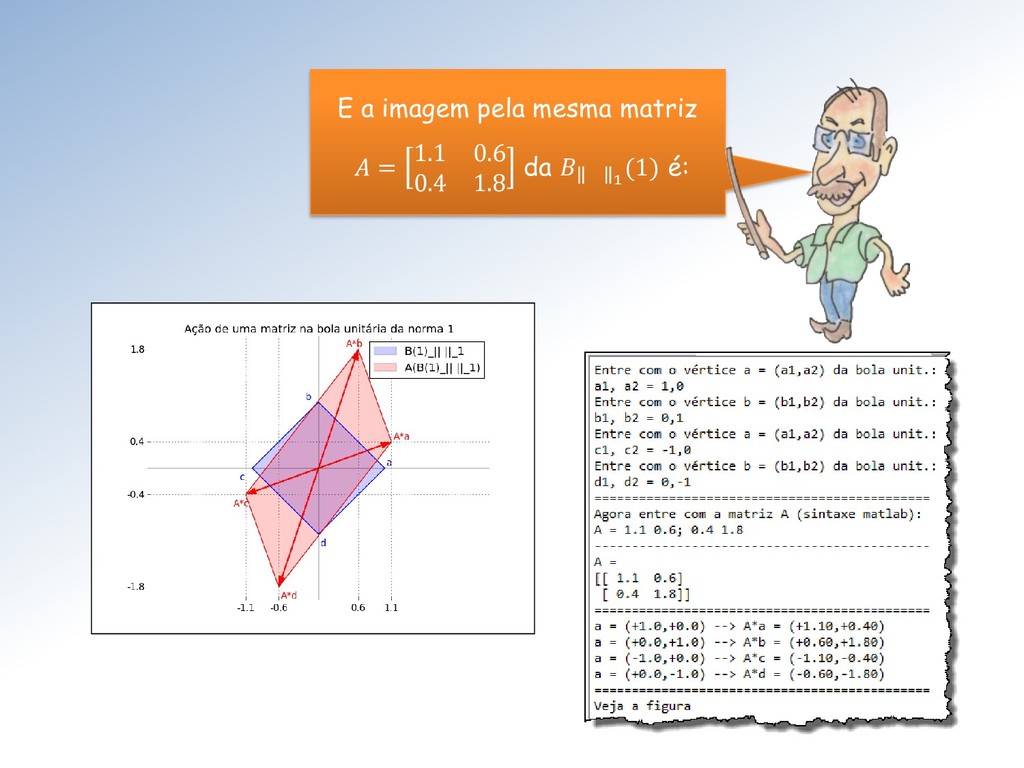
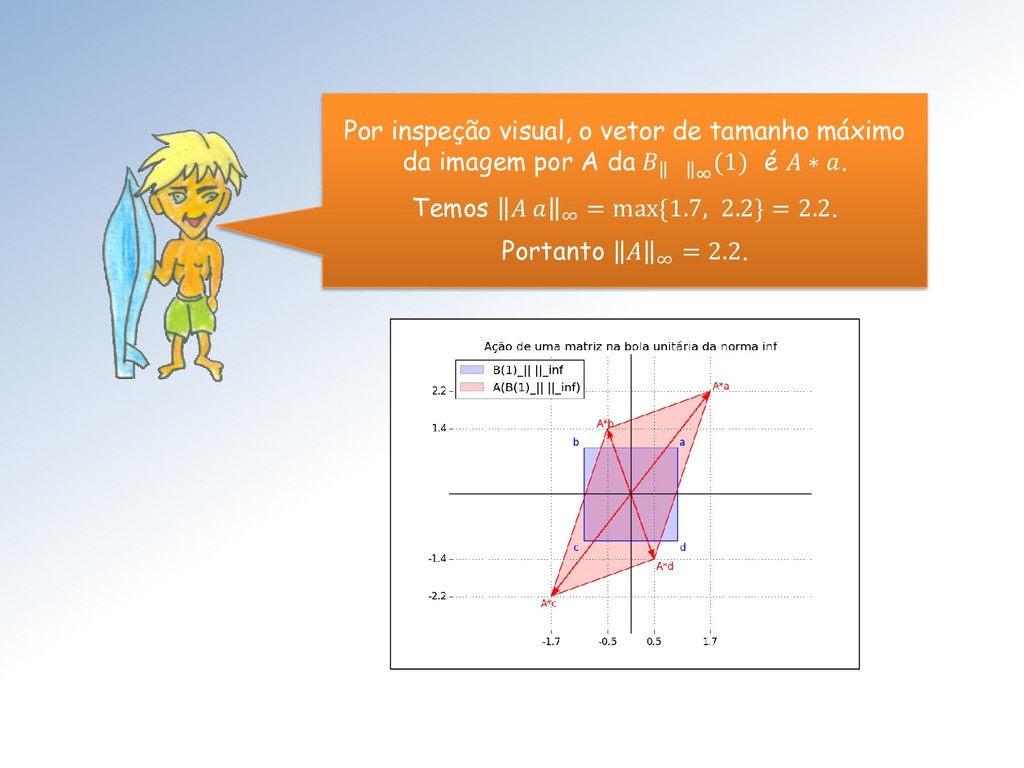
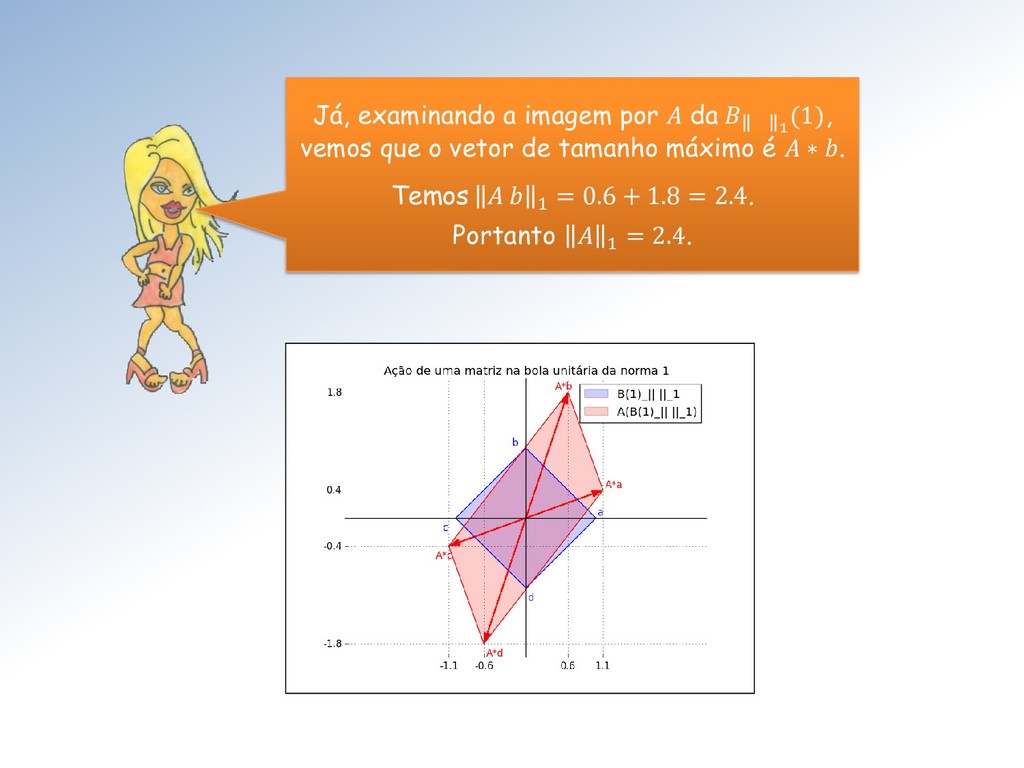
= max{ 11 + 21 , 12 + 22 } • ∞ = max{ 11 + 12 , 21 + 22 } Por esses dois resultados: • 1 é referida como norma (...) das colunas de e • ∞ como norma (...) das linhas de . (...) = (do máximo da soma dos valores absolutos)
funções ∶ ℝ → ℝ dadas por ↦ ∈ ℝ, ∈ ℝ. O 1º passo da generalização é imediato: substituímos os módulos por normas. Assim eles serão os números dados por: , = () e , = , ∙ Τ ()
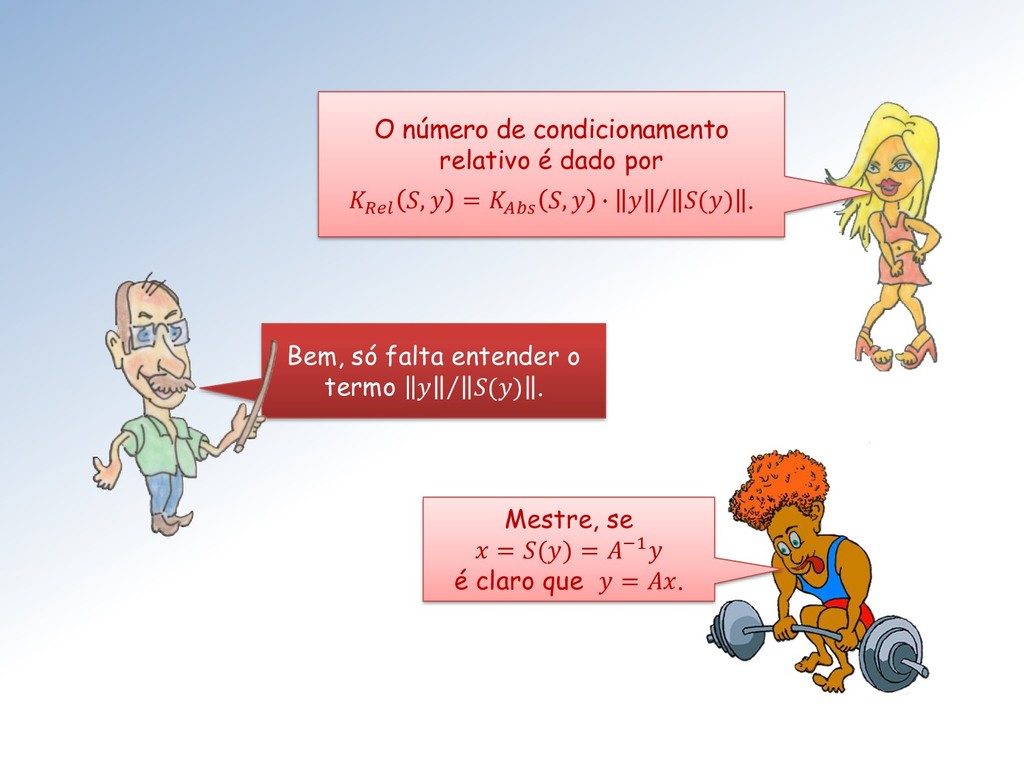
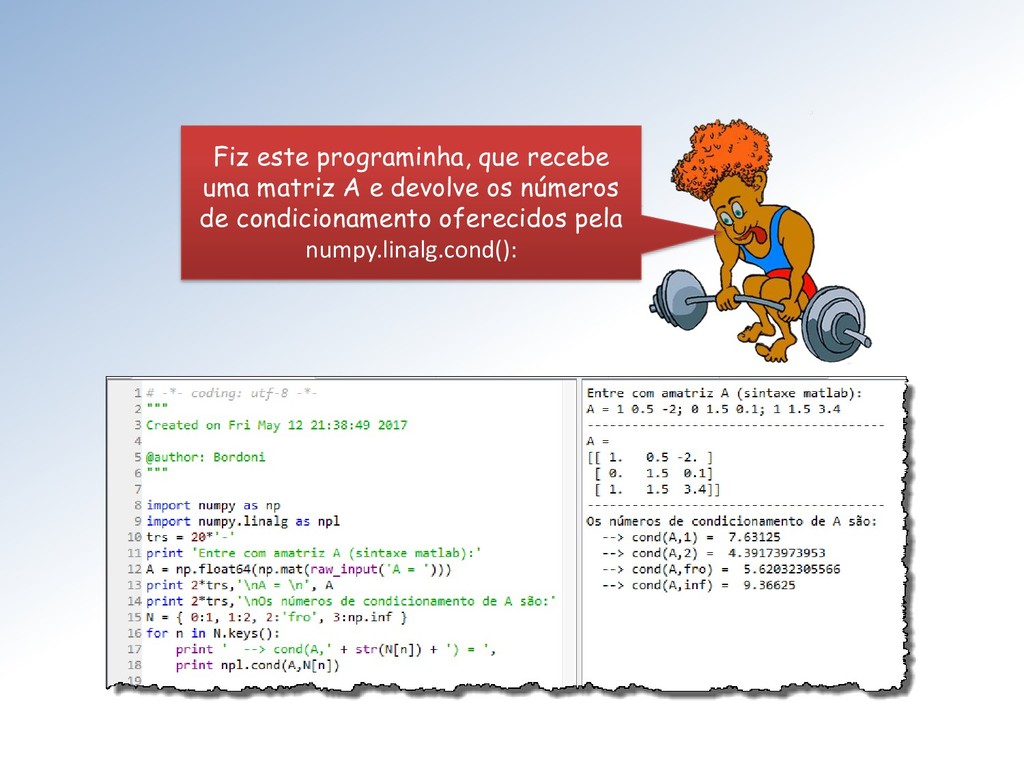
= é dada por = −1. Assim, a função é : ↦ = −1. Brilhante Cabelos de Fogo. O número de condicionamento para o problema da resolução de sistemas lineares é, portanto , = −1 .
= é = , = −1 ∙ Portanto os números de condicionamento absoluto e relativo para sistemas lineares = dependem apenas da matriz (e da −1): • = , = −1 , • = , = ∙ −1 .
singular de A , • −1 2 = Τ 1 - o menor valor singular de A . Assim = Τ Em outras palavras = Τ , é o inverso da excentricidade do hiper elipsoide que é a imagem por A da circunferência unitária.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}