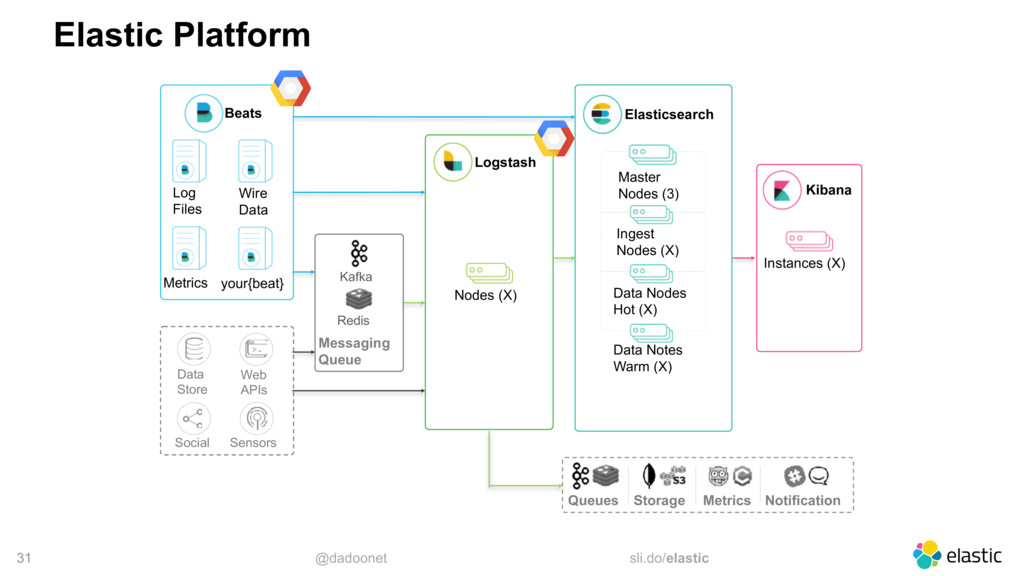
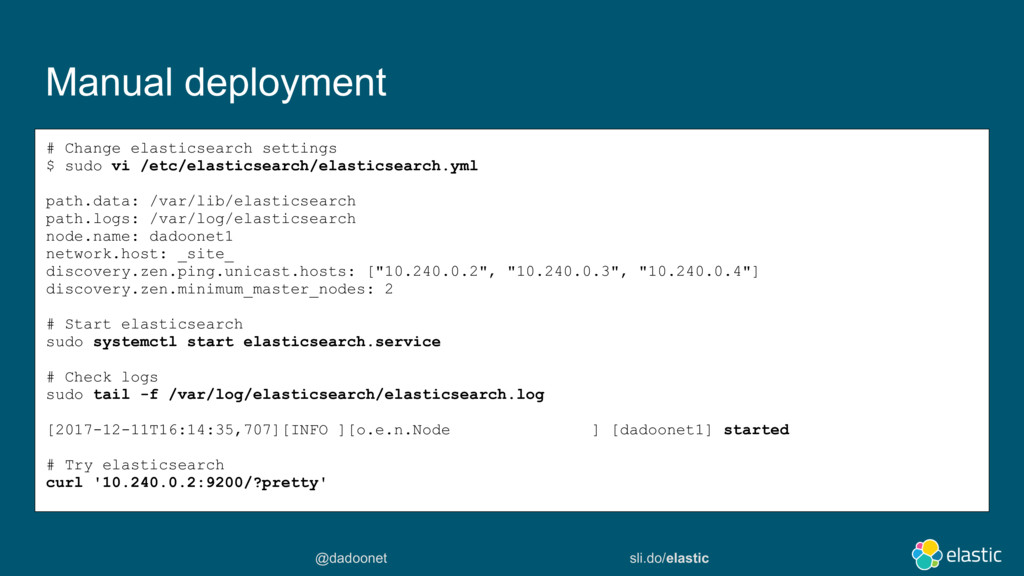
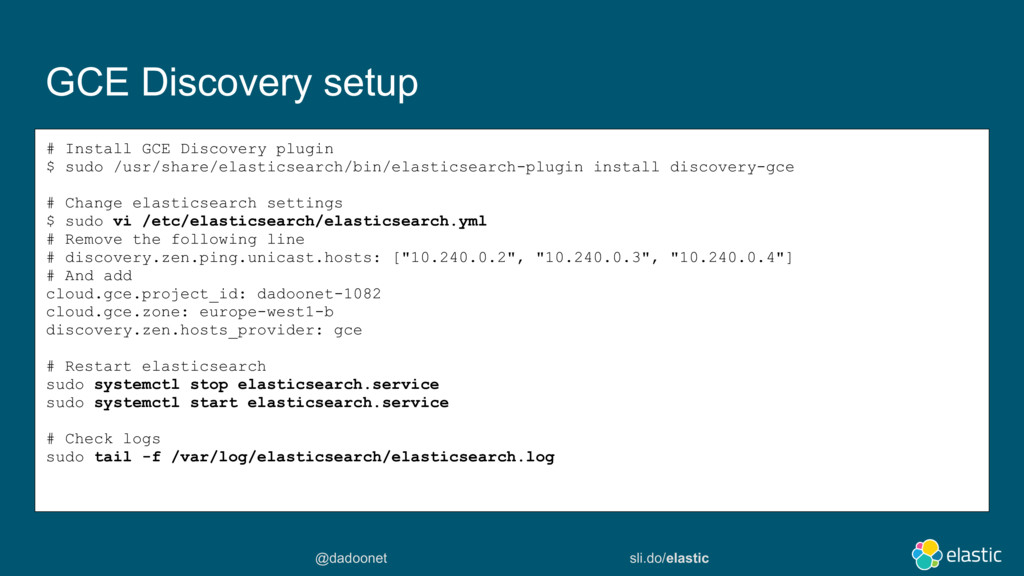
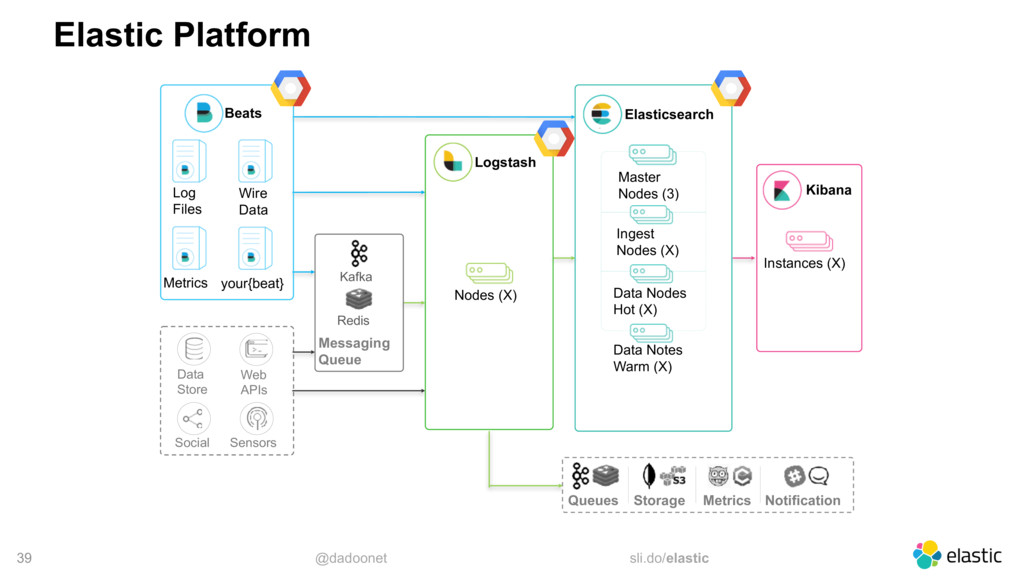
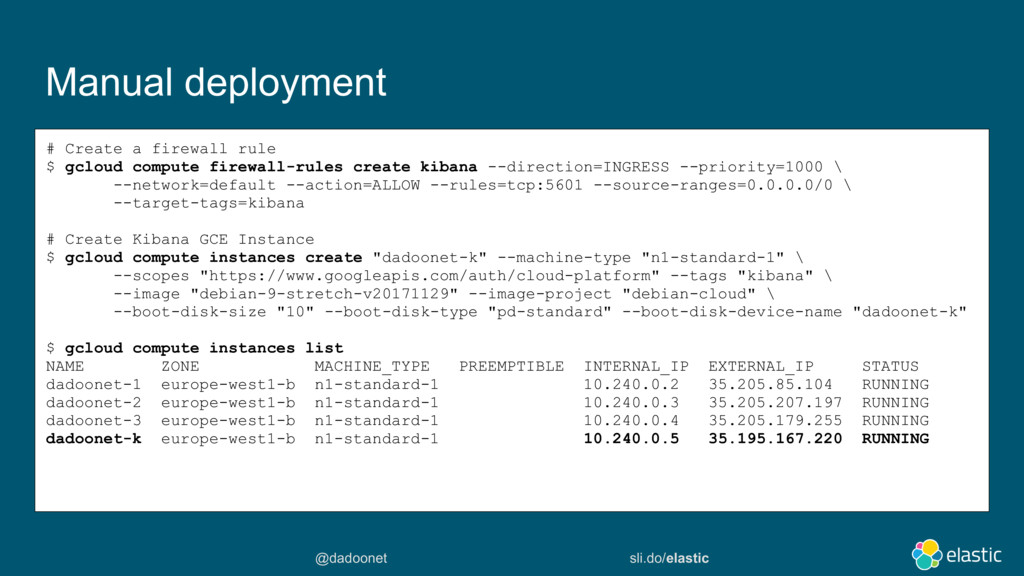
Pour déployer elasticsearch sur Google Compute Platform, plusieurs options s'offrent à vous :
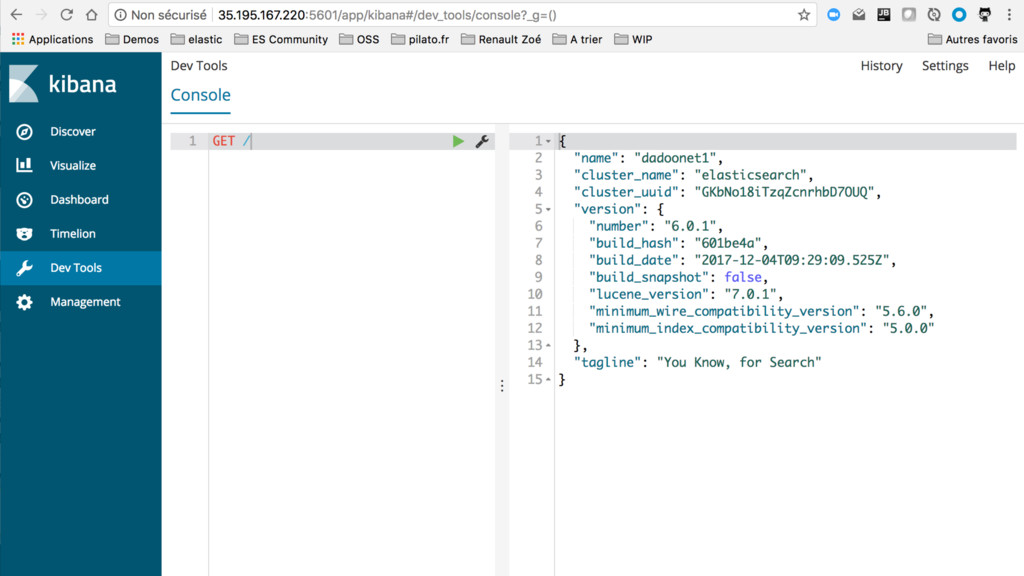
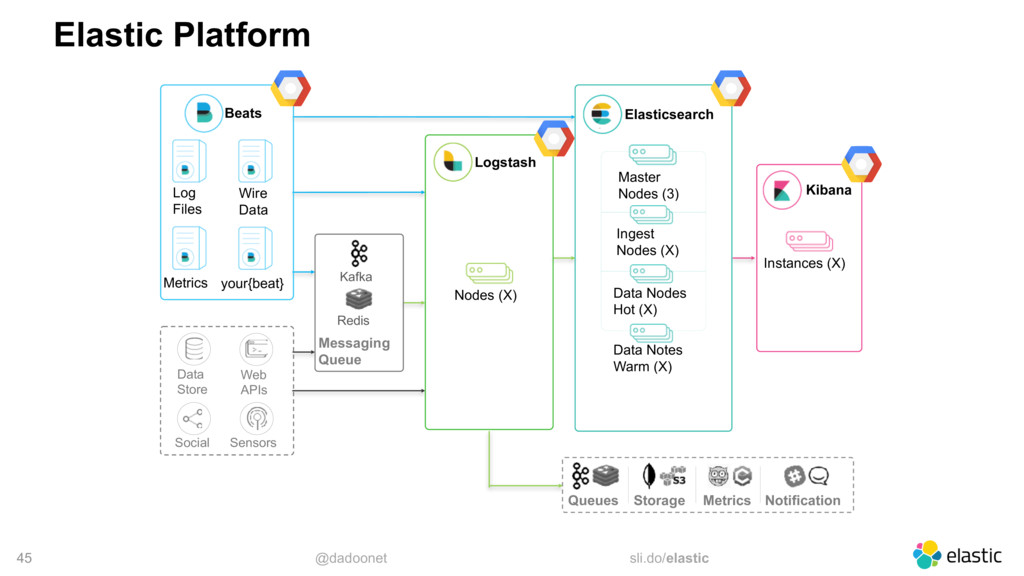
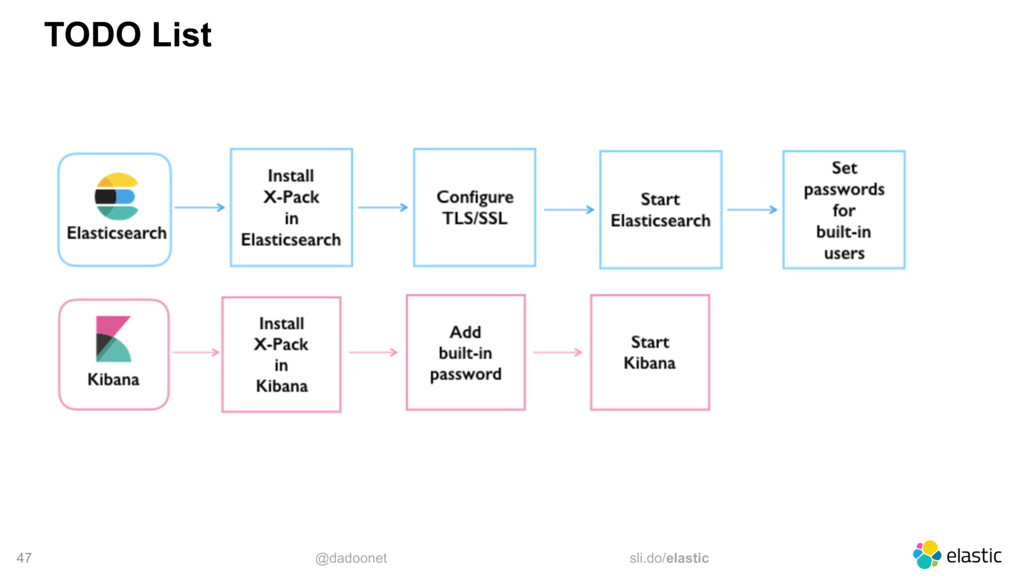
Démarrer des instances GCE, installer et configurer elasticsearch pour le discoveryIdem mais installer le plugin discovery-gce qui vous simplifiera la découverte des noeudsPuis installer X-Pack basic pour monitorer les ressources.Utiliser Elastic Cloud Entreprise et le déployer sur des instances GCELaisser elastic la société, déployer et manager vos instances sur GCP via cloud.elastic.co (http://cloud.elastic.co/)
Ce talk vous décrira ces différentes options disponibles ainsi que quelques trucs et astuces pour optimiser au mieux votre usage d'elasticsearch quelque soit le mode de déploiement.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
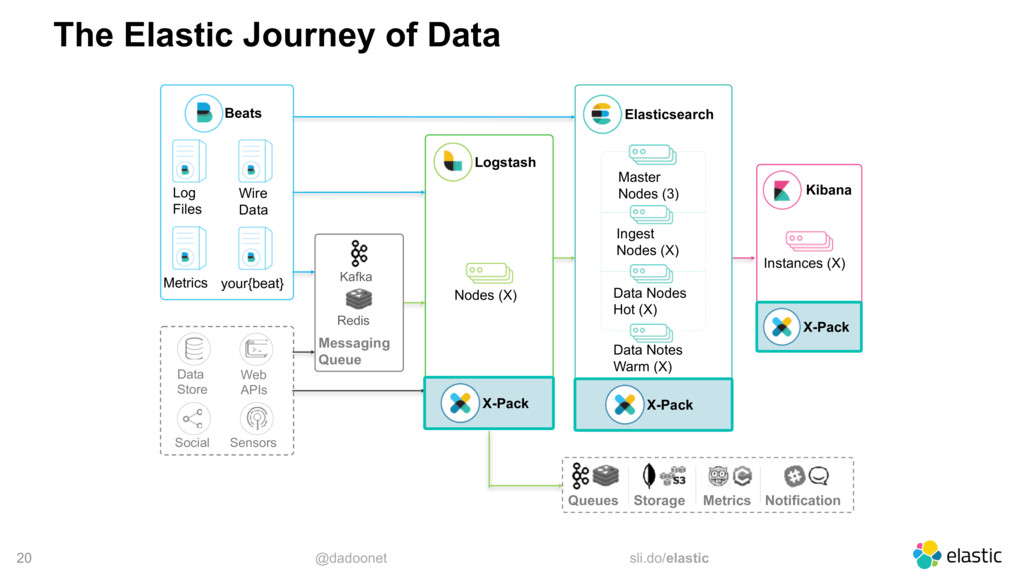{kind=link}
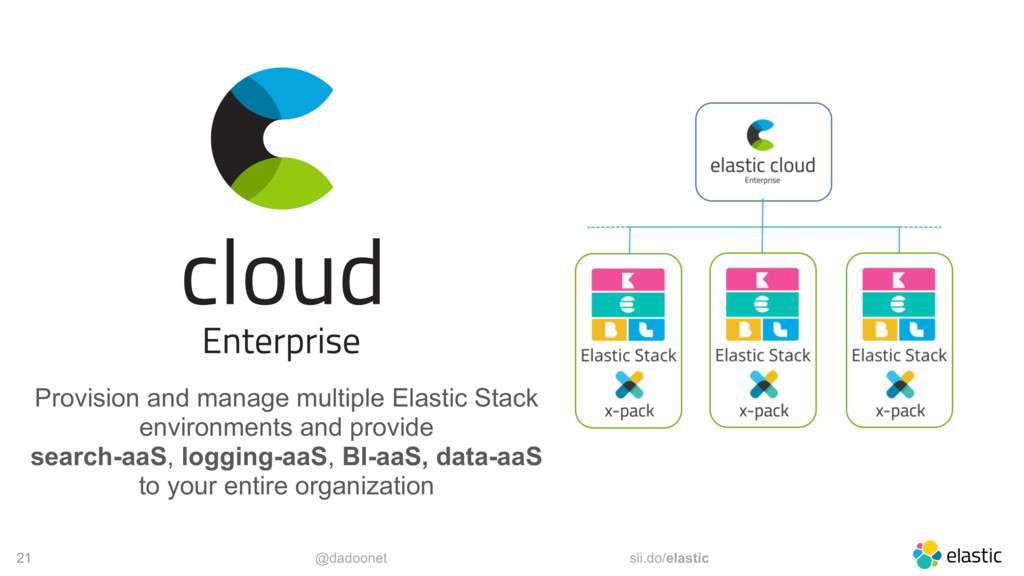{kind=link}
{kind=link}
{kind=link}
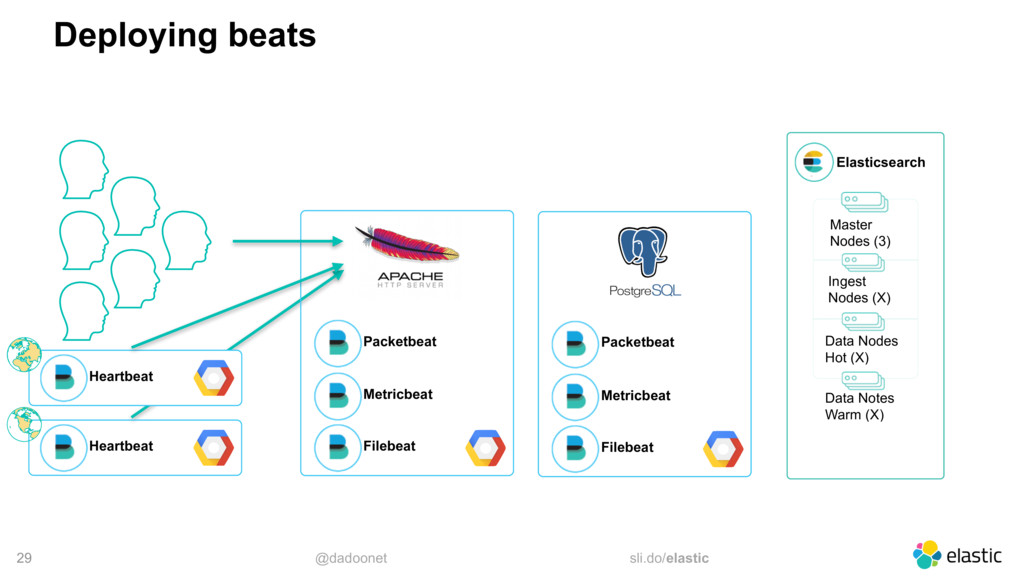{kind=link}
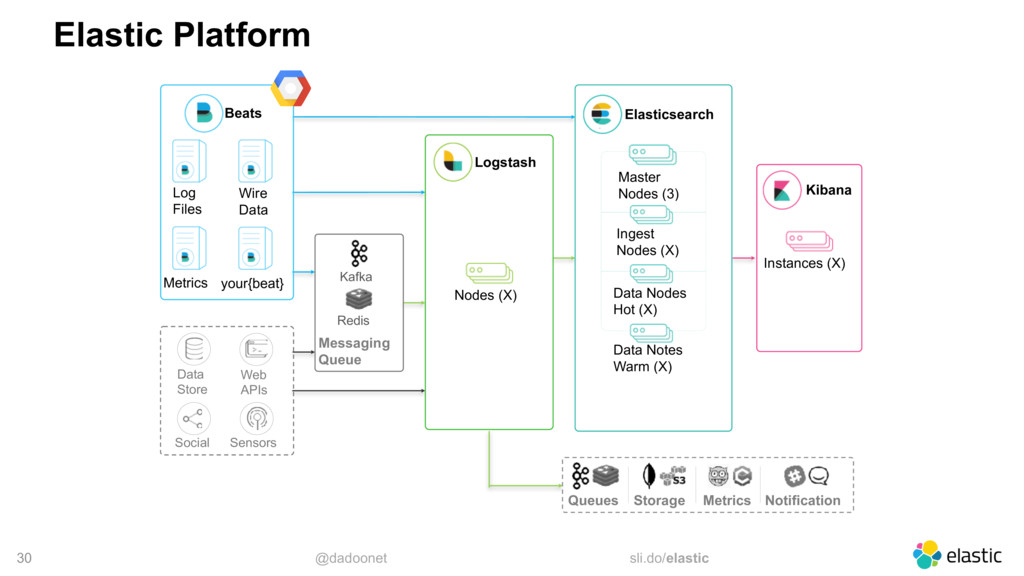{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
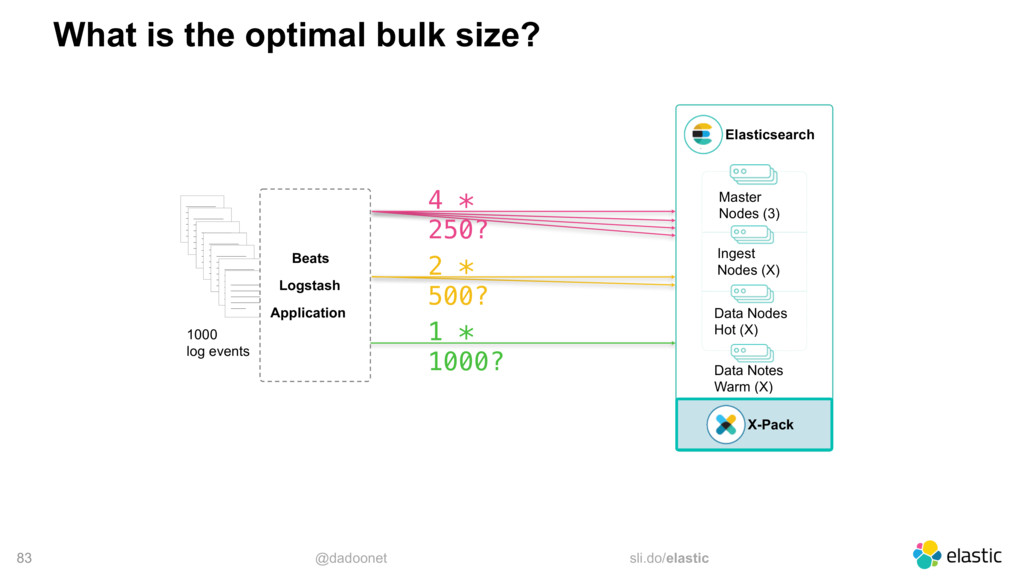{kind=link}
{kind=link}
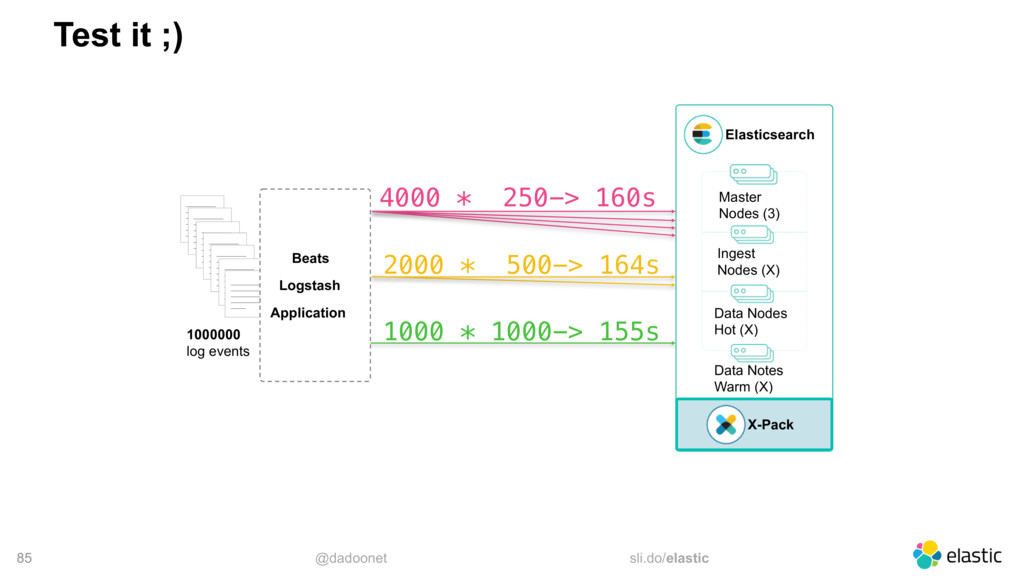{kind=link}
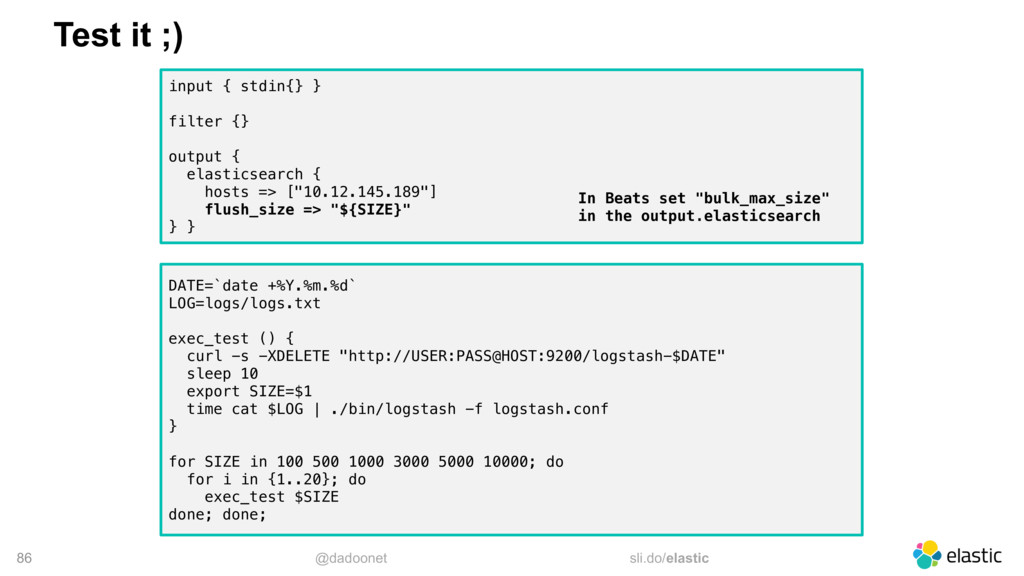{kind=link}
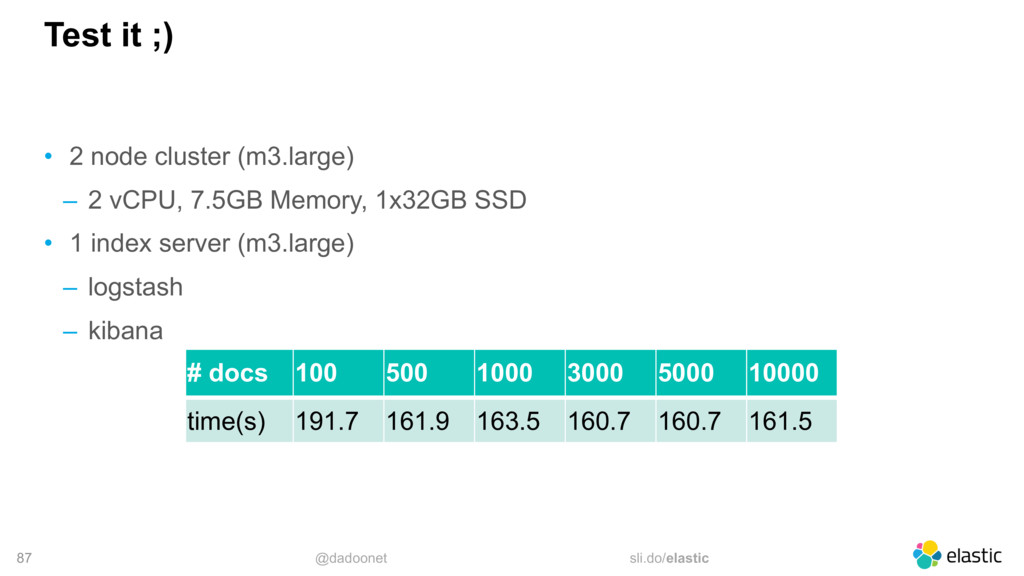{kind=link}
{kind=link}
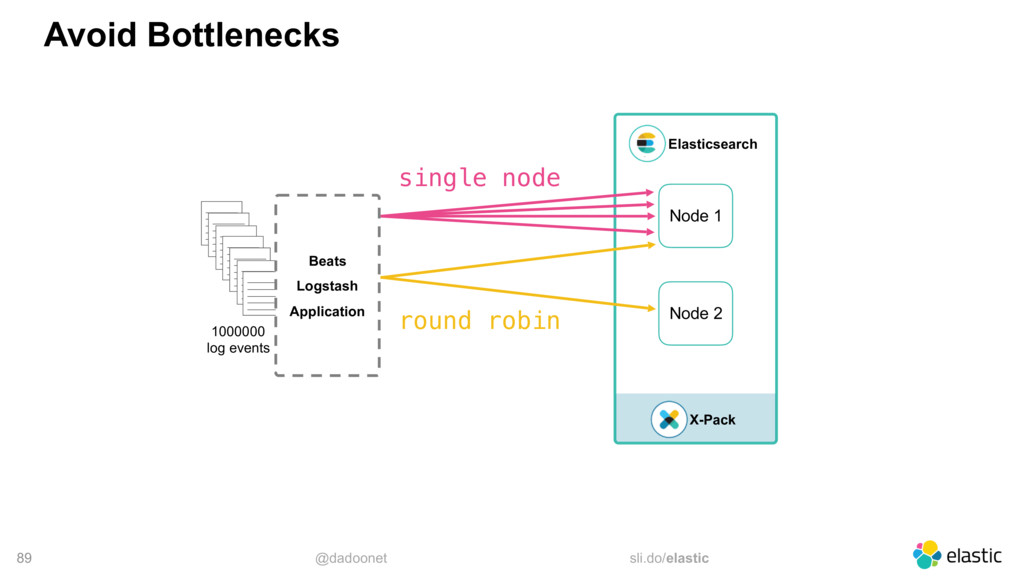{kind=link}
{kind=link}
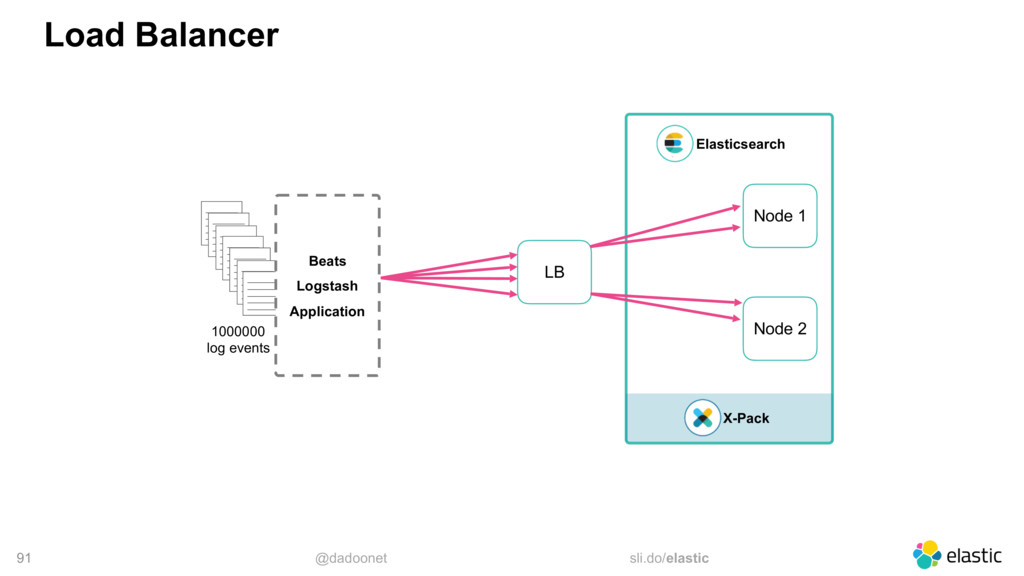{kind=link}
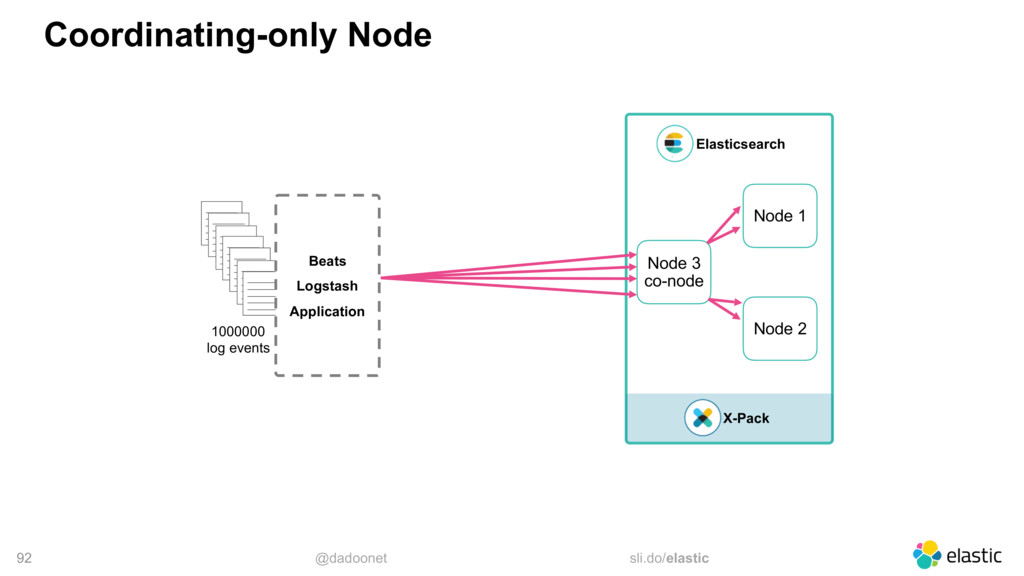{kind=link}
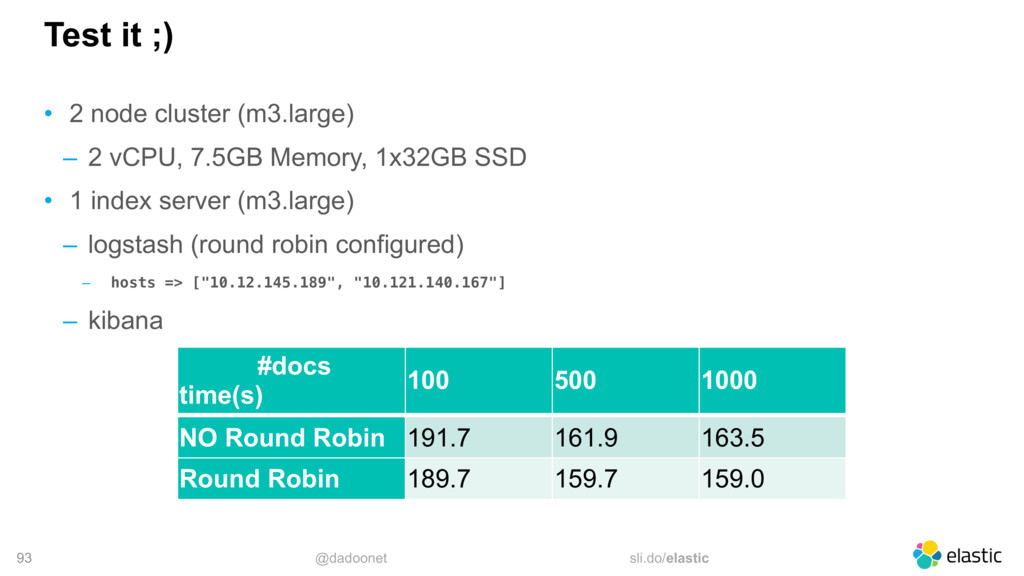{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}