Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Rの基礎9 基本的な統計と検定
Search
xjorv
January 23, 2021
Education
220
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Rの基礎9 基本的な統計と検定
Rの基礎9では、Rでの統計や検定の基礎について説明します。
xjorv
January 23, 2021
More Decks by xjorv
See All by xjorv
コンパートメントモデル
xjorv
3
6k
コンパートメントモデルをStanで解く
xjorv
0
520
生物学的同等性試験 検出力の計算法
xjorv
0
3.7k
生物学的同等性試験ガイドライン 同等性パラメータの計算方法
xjorv
0
6.6k
粉体特性2
xjorv
0
2.6k
粉体特性1
xjorv
0
2.9k
皮膜5
xjorv
0
2.4k
皮膜4
xjorv
0
2.3k
皮膜3
xjorv
0
2.3k
Other Decks in Education
See All in Education
NDIAS Automotive / IoT CTF 2026 Recap - Keyfob & OSINT
himitu23
0
160
Info Session MSc Computer Science & MSc Applied Informatics
signer
PRO
0
300
Case Studies and Future Research - Lecture 12 - Next Generation User Interfaces (4018166FNR)
signer
PRO
0
180
2026年度春学期 統計学 第3回 クロス集計と感度・特異度,データの可視化 (2026. 4. 23)
akiraasano
PRO
0
160
教育現場から見た Ruby on Rails
yasslab
PRO
0
190
Examen de Selectividad. Geografía julio 2026 (Convocatoria Extraordinaria). UCLM
juanmartin2026
0
4.3k
2026年度春学期 統計学 第1回 イントロダクション ー 統計的なものの見方・考え方について (2026. 4. 9)
akiraasano
PRO
0
180
Catecismo 26 #2 - Do Credo; Introdução ao 1º artigo
cm_manaus
0
130
自己紹介 / who-am-i
yasulab
6
7k
Visionary Initiative: Materials-Positive Society — Evolving “Things,” empowering a positive society | Science Tokyo
sciencetokyo
PRO
0
110
2026年度春学期 統計学 第5回 分布をまとめるー記述統計量(平均・分散など) (2026. 5. 7)
akiraasano
PRO
0
160
DECADE_ゴルフ_コースマネジメント完全ガイド.pdf
ozekinote
0
100
Featured
See All Featured
実際に使うSQLの書き方 徹底解説 / pgcon21j-tutorial
soudai
PRO
201
75k
GraphQLの誤解/rethinking-graphql
sonatard
75
12k
Future Trends and Review - Lecture 12 - Web Technologies (1019888BNR)
signer
PRO
0
3.6k
Building Adaptive Systems
keathley
44
3.1k
Noah Learner - AI + Me: how we built a GSC Bulk Export data pipeline
techseoconnect
PRO
0
210
RailsConf & Balkan Ruby 2019: The Past, Present, and Future of Rails at GitHub
eileencodes
141
35k
Typedesign – Prime Four
hannesfritz
42
3.1k
The Pragmatic Product Professional
lauravandoore
37
7.3k
WENDY [Excerpt]
tessaabrams
11
38k
Efficient Content Optimization with Google Search Console & Apps Script
katarinadahlin
PRO
1
640
[RailsConf 2023] Rails as a piece of cake
palkan
59
6.7k
The Myth of the Modular Monolith - Day 2 Keynote - Rails World 2024
eileencodes
28
3.5k
Transcript
Rの基礎 9 基本的な統計と検定 2020/8/15 Ver. 1.0
基本統計量 ベクトルの平均・分散・標準偏差などは関数で簡単に求まる mean sd var max min quantile sum median
平均値 標準偏差 分散 最大値 最小値 4分位値 合計 中央値
summary関数 基本統計量はsummary関数で表示できる データがあれば、とりあえずsummary関数の引数にしてみる
確率分布と乱数 Rでは、確率分布に従った乱数を簡単に得ることができる *乱数: ランダムな数のこと。乱数シミュレーションなどで利用できる runif rnorm rbinom rpois 一様分布 正規分布
二項分布 ポアソン分布
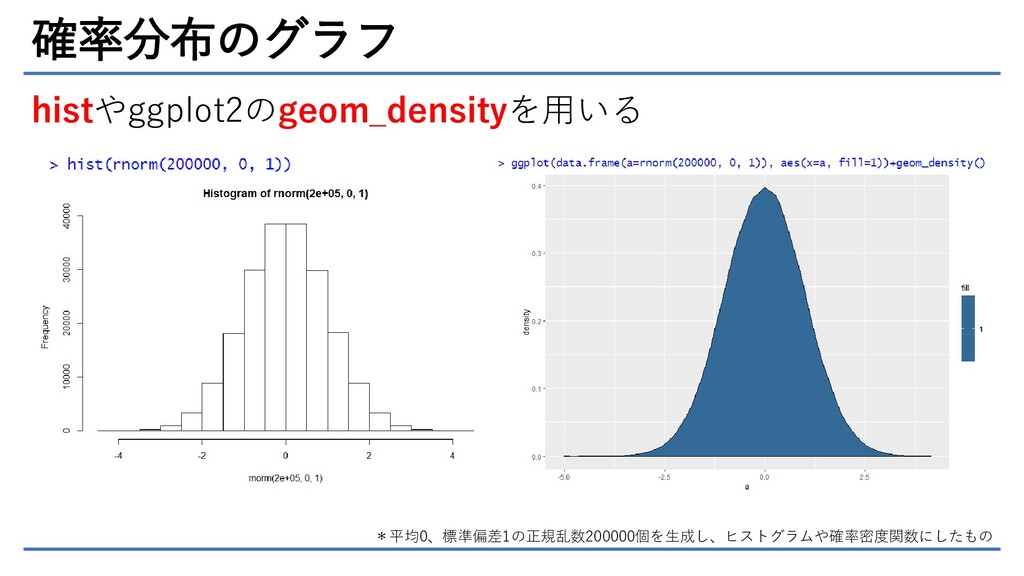
確率分布のグラフ histやggplot2のgeom_densityを用いる *平均0、標準偏差1の正規乱数200000個を生成し、ヒストグラムや確率密度関数にしたもの
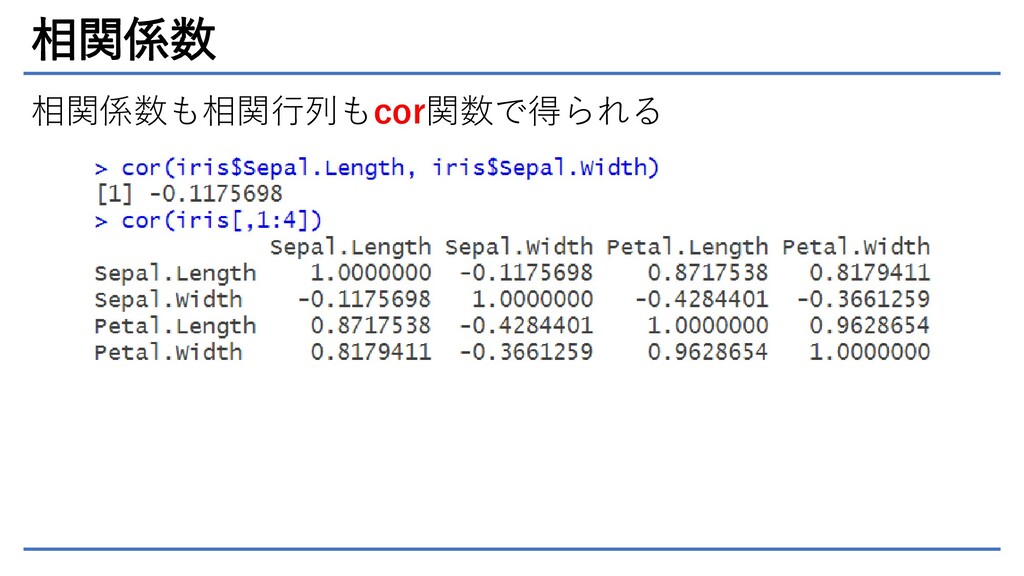
相関係数 相関係数も相関行列もcor関数で得られる
直線回帰 直線回帰はlm関数で計算できる • Rでは、Y~Xという表現で2数の関係を示す • Yが従属変数、Xが説明変数となる • Interceptは切片、説明変数の数字は傾きとなる 切片 傾き
直線回帰の詳しい情報 回帰の結果をsummary関数の引数に取る 切片と傾き 切片と傾きの検定結果 *検定では傾きや切片が有意にゼロから離れていることを示す
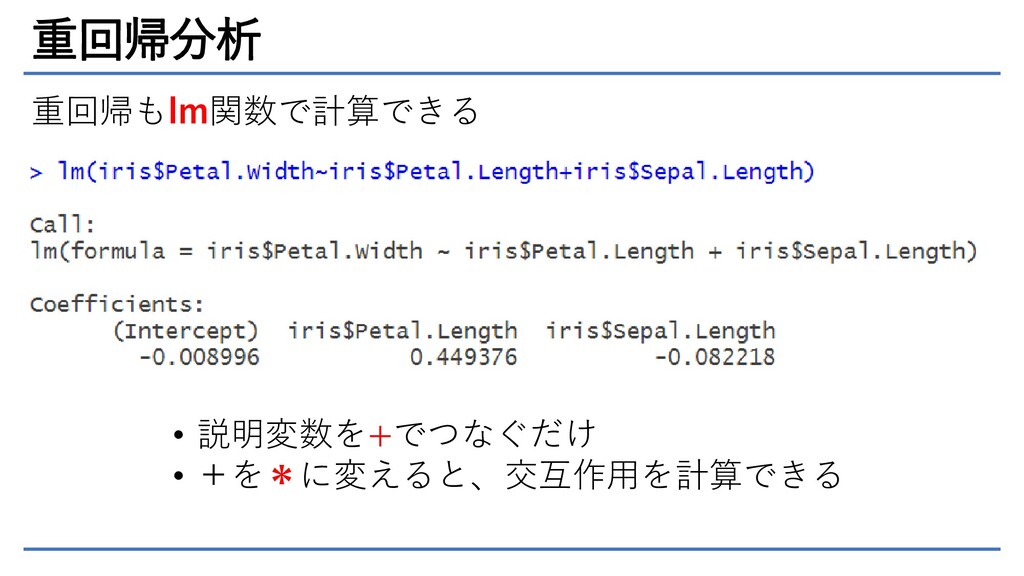
重回帰分析 重回帰もlm関数で計算できる • 説明変数を+でつなぐだけ • +を*に変えると、交互作用を計算できる
平均の差の検定: t検定 t検定は、t.test関数で実行できる t.test(1つ目の集団, 2つ目の集団)で計算できる これがp値 Welchは等分散でないときのt検定の拡張
平均の差の検定: ウィルコクソンの順位和検定 ウィルコクソンはt検定のノンパラメトリック*版 wilcox.test(1つ目の集団, 2つ目の集団)で計算できる *ノンパラメトリック: 集団が正規分布しないときに使用する検定手法。検出力が低い
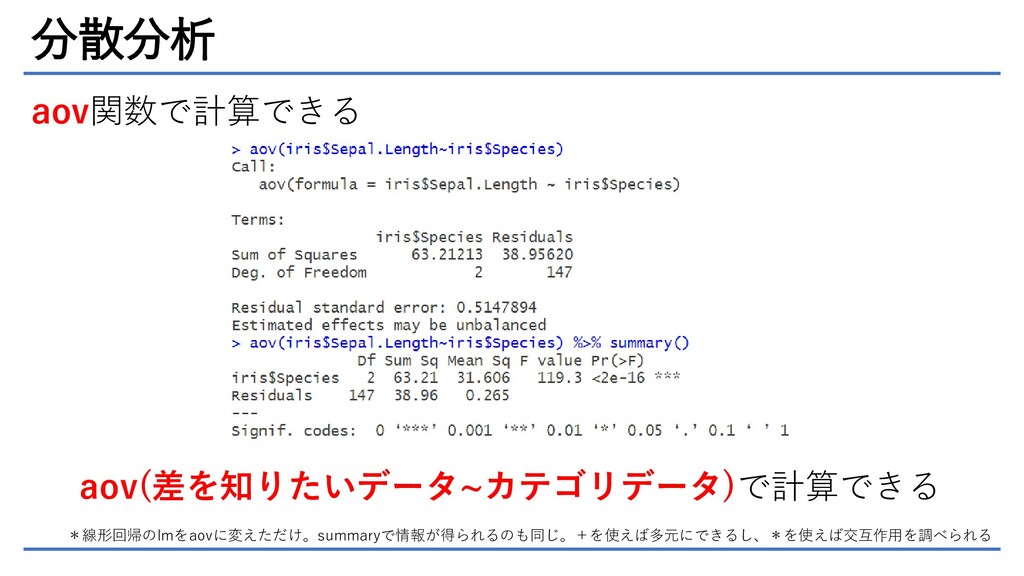
分散分析 aov関数で計算できる aov(差を知りたいデータ~カテゴリデータ)で計算できる *線形回帰のlmをaovに変えただけ。summaryで情報が得られるのも同じ。+を使えば多元にできるし、*を使えば交互作用を調べられる
カテゴリデータ: factor(因子) カテゴリを示すときに因子を多用する • データフレームを読み込むと文字列は因子に変換*される • 数字に名前がついたもの • 同じ名前のものが同じカテゴリとして扱われる *stringAsFactors
= Tがデフォルトなので、read.table関数で読み込むと変換が起きる
多重比較: Tukeyの方法 総当りの比較にはTukeyの方法を用いる TukeyHSD(aovの結果)で計算できる *他にScheffeやDunnett、Kruskal-Wallis、holm、Bonferroniの方法などがある
検出力の計算 検定の検出力はpowerから始まる関数で行う power.t.test, power.prop.test, power.anova.testなどがある これが検出力
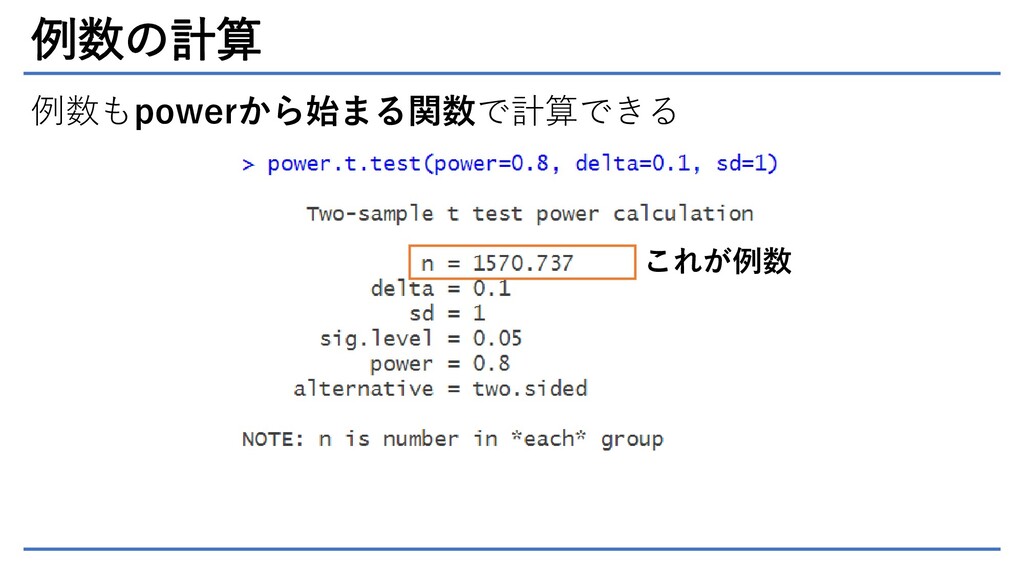
例数の計算 例数もpowerから始まる関数で計算できる これが例数
まとめ • Rには統計に関する手法・パッケージが豊富にある • カテゴリデータの扱いに因子を用いる • 「R 統計手法」で検索すれば、だいたい手法が見つかる
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}