Expression Segmentation – Need to Identify the target object from long instruction sentences 3 "Go to the living room and fetch the pillow closest to the radio art on the wall." Inputs Output Dataset Sentence length (avg.) G-Ref [Mao+, CVPR16] 8.4 SHIMRIE (Ours) 18.8
instruction • Our method: MDSM – 1st-stage: Introduce Multimodal Encoder – 2nd-stage: Refine the mask by the diffusion model • Result – Outperformed the existing method on the SHIMRIE dataset • generate more appropriate masks from long sentences 11
``the candle on the right’’ – OSMI: ``Go to the dining table. Then pick up the candle on the right.’’ 14 Even the latest segmentation model, SEEM [Zou+, 23], is difficult to address OSMI tasks e.g. ``Pick up the plant in front of the mirror.’’
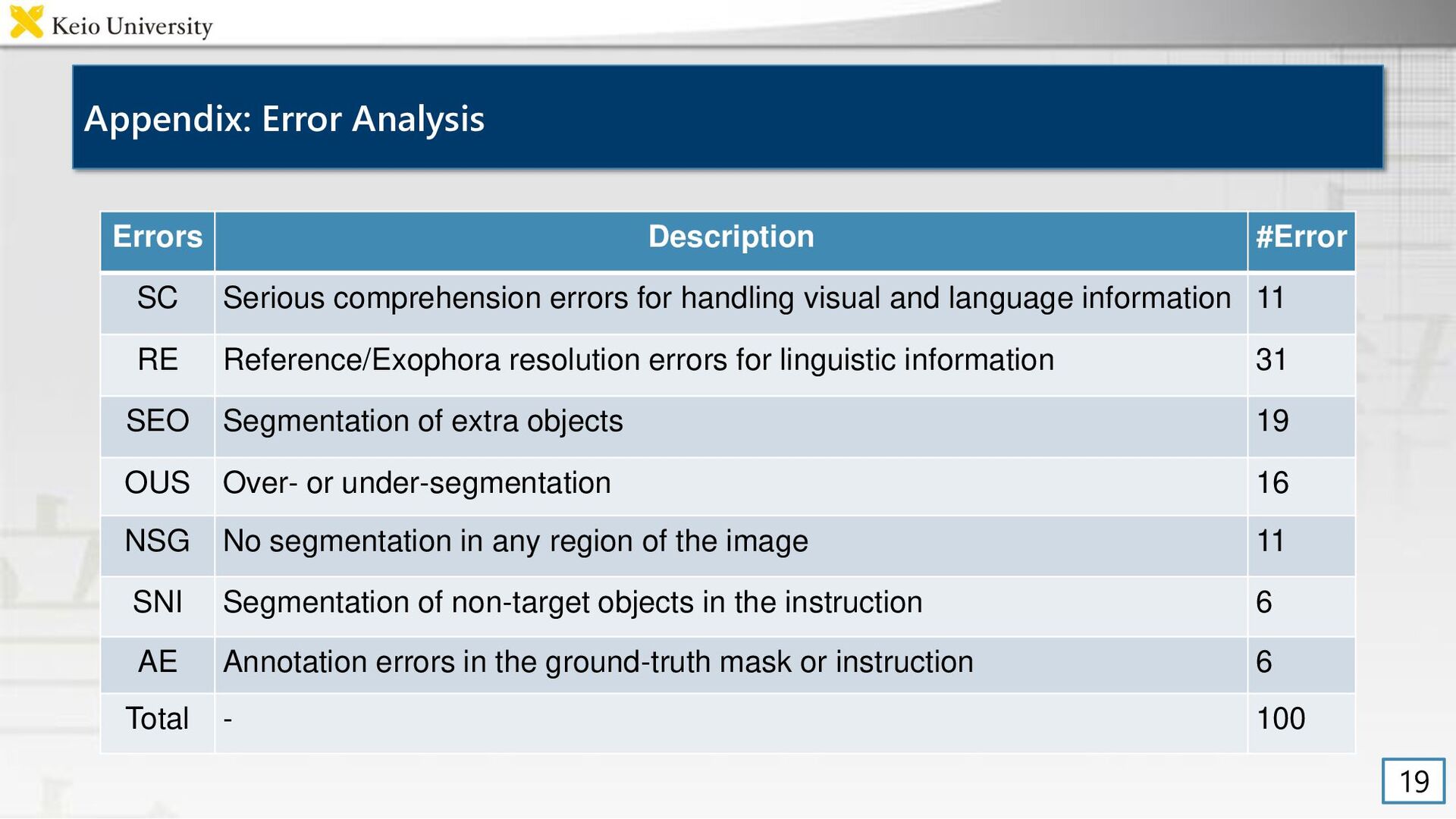
errors for handling visual and language information 11 RE Reference/Exophora resolution errors for linguistic information 31 SEO Segmentation of extra objects 19 OUS Over- or under-segmentation 16 NSG No segmentation in any region of the image 11 SNI Segmentation of non-target objects in the instruction 6 AE Annotation errors in the ground-truth mask or instruction 6 Total - 100
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Quantitative results: Outperformed the existing method 8 [%] Method mIoU](https://files.speakerdeck.com/presentations/e524775d1e9e488d927158d3953ac745/slide_7.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Appendix: SHIMRIE dataset 15 REVERIE [Qi+, CVPR20]: Instructions, bboxes &](https://files.speakerdeck.com/presentations/e524775d1e9e488d927158d3953ac745/slide_12.jpg){kind=link}
![Appendix: PWAM 16 [Yang+, CVPR22]](https://files.speakerdeck.com/presentations/e524775d1e9e488d927158d3953ac745/slide_13.jpg){kind=link}
![Appendix: Ablation Study 17 mIoU oIoU [email protected] [email protected] [email protected] [email protected]](https://files.speakerdeck.com/presentations/e524775d1e9e488d927158d3953ac745/slide_14.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}