Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
[Journal club] COMET: A Neural Framework for MT...
Search
Semantic Machine Intelligence Lab., Keio Univ.
PRO
July 28, 2023
Technology
690
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
[Journal club] COMET: A Neural Framework for MT Evaluation
Semantic Machine Intelligence Lab., Keio Univ.
PRO
July 28, 2023
More Decks by Semantic Machine Intelligence Lab., Keio Univ.
See All by Semantic Machine Intelligence Lab., Keio Univ.
[Journal club] Predict Before You Explore: Predictive Planning with Specialized Memory for Embodied Question Answering
keio_smilab
PRO
0
81
[Journal club] PHyCLIP: 𝒍𝟏-Product of Hyperbolic Factors Unifies Hierarchy and Compositionality in Vision-Language Representation Learning
keio_smilab
PRO
0
86
[Journal club] ReMEmbR: Building and Reasoning Over Long-Horizon Spatio-Temporal Memory for Robot Navigation
keio_smilab
PRO
0
110
[Journal club] ReLaGS: Relational Language Gaussian Splatting
keio_smilab
PRO
0
120
[Journal club] Flow as the Cross-Domain Manipulation Interface
keio_smilab
PRO
0
98
Mobi-𝜋: Mobilizing Your Robot Learning Policy
keio_smilab
PRO
0
160
A Gentle Introduction to Transformers
keio_smilab
PRO
16
7k
FlowAR: Scale-wise Autoregressive Image Generation Meets Flow Matching
keio_smilab
PRO
0
60
[Journal club] VLA-Adapter: An Effective Paradigm for Tiny-Scale Vision-Language-Action Model
keio_smilab
PRO
1
150
Other Decks in Technology
See All in Technology
AIコード生成×サプライチェーン攻撃 — PHPが直面する“二重の信頼問題
shinyasaita
0
450
Jitera Company Deck
jitera
0
270
AI Native なプロダクト組織の立ち上げ方 : 生産性 100 倍への挑戦
mikesorae
0
1.2k
なぜ、あなたのエージェントは言うことを聞かないのか
segavvy
1
360
_NIKKEI_Tech_Talk__勉強会は熱量では続かない___17回続いた輪読会の設計術.pdf
_awache
1
100
Devsumi 2026 Summer 人もAIも使える共通基盤を事業の加速装置にする~デザインシステム運用に学ぶ組織レバレッジ~ 渡辺 凌央
legalontechnologies
PRO
1
280
Oracle Base Database Service 技術詳細
oracle4engineer
PRO
15
110k
「守りたい体験」を渡すだけで E2E を生成させられるようになった話
hinac0
2
1k
AmplifyHostingConstructからSSRフレームワークのためのホスティング設計を考察する/amplify-hosting-construct
fossamagna
1
300
AI時代の開発生産性を捉え直す — 経営と現場をつなぐ「開発組織のオブザーバビリティ」— / AI Dev Ex Conference 2026
tkyowa
1
1.3k
人とエージェントが高め合う協業設計
kintotechdev
0
750
SoccerMaster: A Vision Foundation Model for Soccer Understanding
kzykmyzw
0
160
Featured
See All Featured
How Fast Is Fast Enough? [PerfNow 2025]
tammyeverts
3
660
Heart Work Chapter 1 - Part 1
lfama
PRO
8
36k
Connecting the Dots Between Site Speed, User Experience & Your Business [WebExpo 2025]
tammyeverts
11
970
RailsConf 2023
tenderlove
30
1.5k
Designing for Performance
lara
611
70k
Measuring & Analyzing Core Web Vitals
bluesmoon
9
900
The untapped power of vector embeddings
frankvandijk
2
1.8k
個人開発の失敗を避けるイケてる考え方 / tips for indie hackers
panda_program
123
22k
Bootstrapping a Software Product
garrettdimon
PRO
307
120k
Jamie Indigo - Trashchat’s Guide to Black Boxes: Technical SEO Tactics for LLMs
techseoconnect
PRO
0
510
The Success of Rails: Ensuring Growth for the Next 100 Years
eileencodes
47
8.2k
Abbi's Birthday
coloredviolet
3
8.8k
Transcript
慶應義塾⼤学 杉浦孔明研究室 B4 齋藤⼤地 COMET: A Neural Framework for MT
Evaluation Ricardo Rei, Craig Stewart, Ana C Farinha, Alon Lavie (Unbabel AI) EMNLP 2020 COMET: A Neural Framework for MT Evaluation (Rei et al., EMNLP 2020)
背景:Rule-basedの評価指標は⼈間による評価との相関が低い - 3 - ▪ Rule-basedの評価指標 • BLEU [Papineni+, ACL02]やMETEOR
[Lavie+, ACL05] • !-gramの⼀致率に基づいて評価 ü シンプルで⾼速 ü 機械翻訳において主流 Ø ⼈間による評価との相関が低い BLEU = BP× exp + !"# $ ,! log 0! = 短い翻訳へのPenalty × 5 − gram精度の幾何平均 METEOR = Fmean ∗ 1 − #chunks #unigrams_matched
既存研究:学習可能な既存尺度は改善が必要 - 4 - ▪ RUSE [Shimanaka+, WMT18] • MLPにより⼈間による評価を回帰
▪ BLEURT [Sellam+, ACL20] • Wikipediaから取得した⼤量のテキストデータを 使⽤し,BERT [Devlin+, NAACL19]で事前学習 • ⼈間による評価でFine-tuning Ø 未だ性能に改善の余地あり RUSE [Shimanaka+, WMT18] BERT [Devlin+, NAACL19]
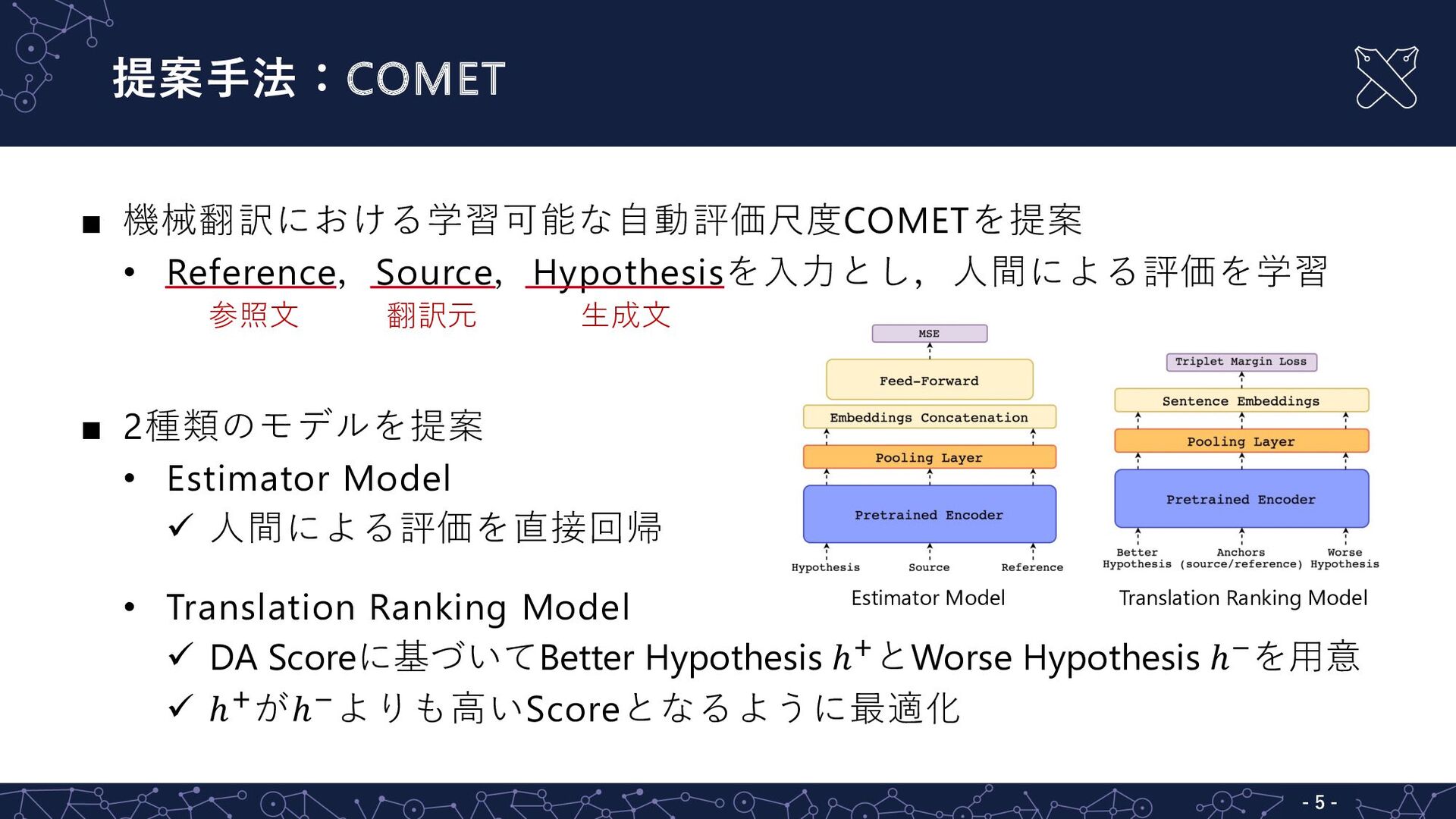
提案⼿法:COMET - 5 - ▪ 機械翻訳における学習可能な⾃動評価尺度COMETを提案 • Reference,Source,Hypothesisを⼊⼒とし,⼈間による評価を学習 ▪ 2種類のモデルを提案
• Estimator Model ü ⼈間による評価を直接回帰 • Translation Ranking Model ü DA Scoreに基づいてBetter Hypothesis ℎIとWorse Hypothesis ℎJを⽤意 ü ℎIがℎJよりも⾼いScoreとなるように最適化 参照⽂ 翻訳元 ⽣成⽂ Estimator Model Translation Ranking Model
Estimator Model:⼈間による評価を直接回帰 - 6 - ▪ Source #,Hypothesis ℎ,Reference $の埋め込み表現から
アダマール積と差を計算し,FFNに⼊⼒ ▪ Quality ScoreとPredicted ScoreのMSEを最⼩化 • DA (Direct Assessment)[Graham+, LAW13] • HTER (Human Targeted Edit Rate)[Snover+, AMTA06] • MQM (Multidimensional Quality Metrics)[Lommel+, 14]
Estimator Model:⼈間による評価を直接回帰 - 7 - ▪ Source #,Hypothesis ℎ,Reference $の埋め込み表現から
アダマール積と差を計算し,FFNに⼊⼒ ▪ Quality ScoreとPredicted ScoreのMSEを最⼩化 • DA (Direct Assessment)[Graham+, LAW13] • HTER (Human Targeted Edit Rate)[Snover+, AMTA06] • MQM (Multidimensional Quality Metrics)[Lommel+, 14] Sourceの埋め込み表現を直接含めない理由 「各⾔語の特徴空間は,適切に対応付けられていない」 [Zhao+, ACL20] Ø Sourceの埋め込み表現を排除し特徴空間を縮⼩ → モデルがより関連性のある情報に集中
Translation Ranking Model①:%Iが%Jよりも⾼いScoreとなるように最適化 - 8 - ▪ ⼊⼒:Better Hypothesis ℎIとWorse
Hypothesis ℎJ ▪ 埋め込み表現 #, ℎI, ℎJ, $ からTriplet Margin Loss [Schroff+, CVPR15]を計算 → 'と%Iの距離が, 'と%Jの距離よりも(以上 ⼤きくなるように最適化() についても同様) ※ !: source, ": reference
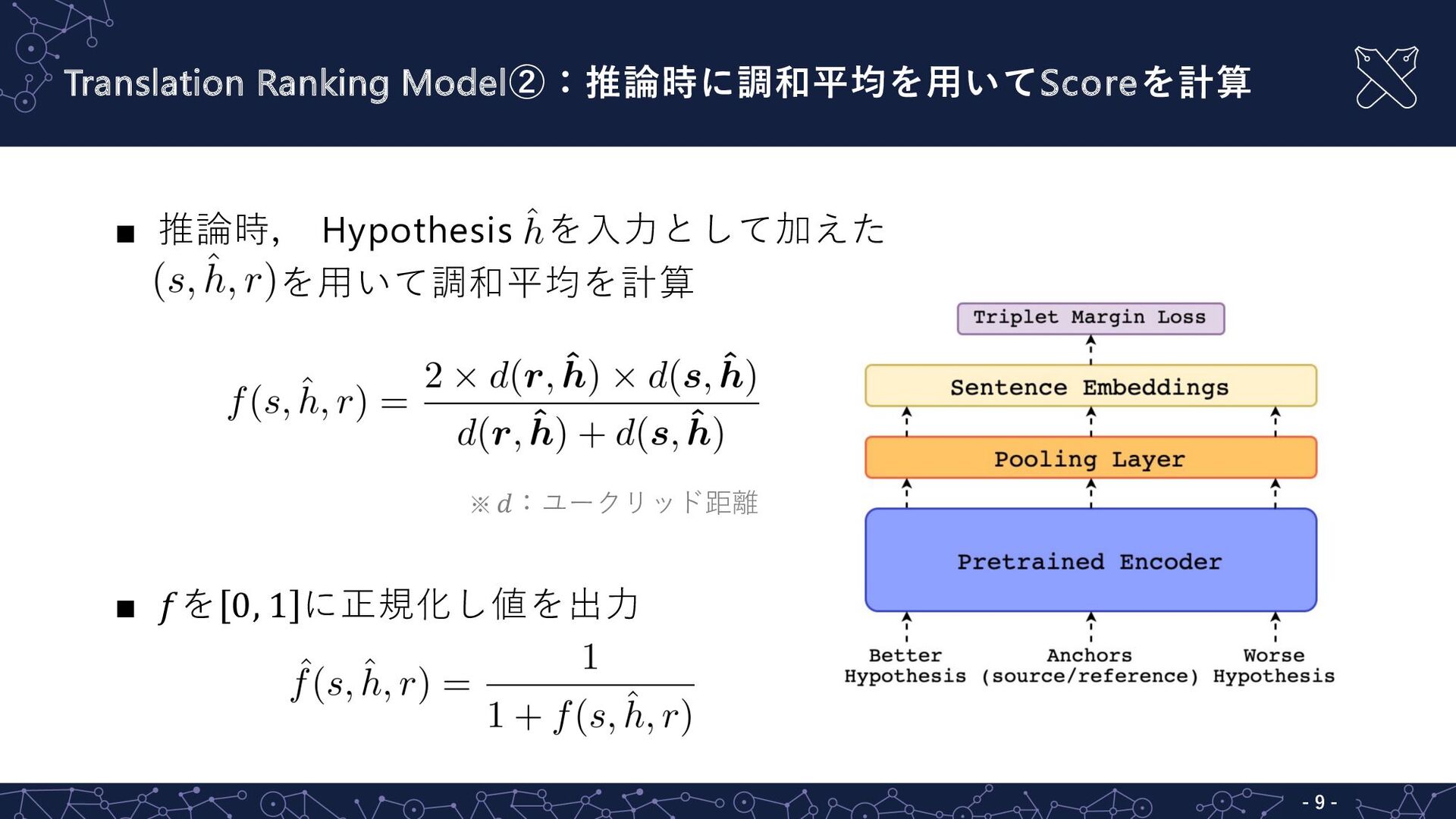
- 9 - ▪ 推論時, Hypothesis hを⼊⼒として加えた #, * ℎ,
$ を⽤いて調和平均を計算 ▪ +を 0, 1 に正規化し値を出⼒ ※ K:ユークリッド距離 Translation Ranking Model②:推論時に調和平均を⽤いてScoreを計算
実験設定:3つのモデルを⽤意 - 10 - ▪ Estimator Model • COMET-HTER:4つの⾔語ペアで学習しHTERを回帰 •
COMET-MQM:12の⾔語ペアで学習しMQMを回帰 ▪ Translation Ranking Model • COMET-Rank:24の⾔語ペアで学習しDAを回帰 ⼈間による評価 • HTER:評価者がHypothesisを編集しEdit Rateを計算 • MQM:エラーの度合いに応じて3段階に分類 • DA:翻訳の品質を⼈間が評価 Estimator Model Translation Ranking Model
実験設定:3つのモデルを⽤意 - 11 - ▪ Estimator Model • COMET-HTER:4つの⾔語ペアで学習しHTERを回帰 •
COMET-MQM:12の⾔語ペアで学習しMQMを回帰 ▪ Translation Ranking Model • COMET-Rank:24の⾔語ペアで学習しDAを回帰 ⼈間による評価 • HTER:評価者がHypothesisを編集しEdit Rateを計算 • MQM:エラーの度合いに応じて3段階に分類 • DA:翻訳の品質を⼈間が評価 Estimator Model Translation Ranking Model データセット • 訓練データ • COMET-HTER:QT21 Corpus [Specia+, XVI21] • COMET-MQM:MQM Corpus (独⾃に収集) • COMET-Rank:WMT DARR Corpus (2017, 2018) [Barrault+, WMT19] • テストデータ:WMT DARR Corpus (2019)
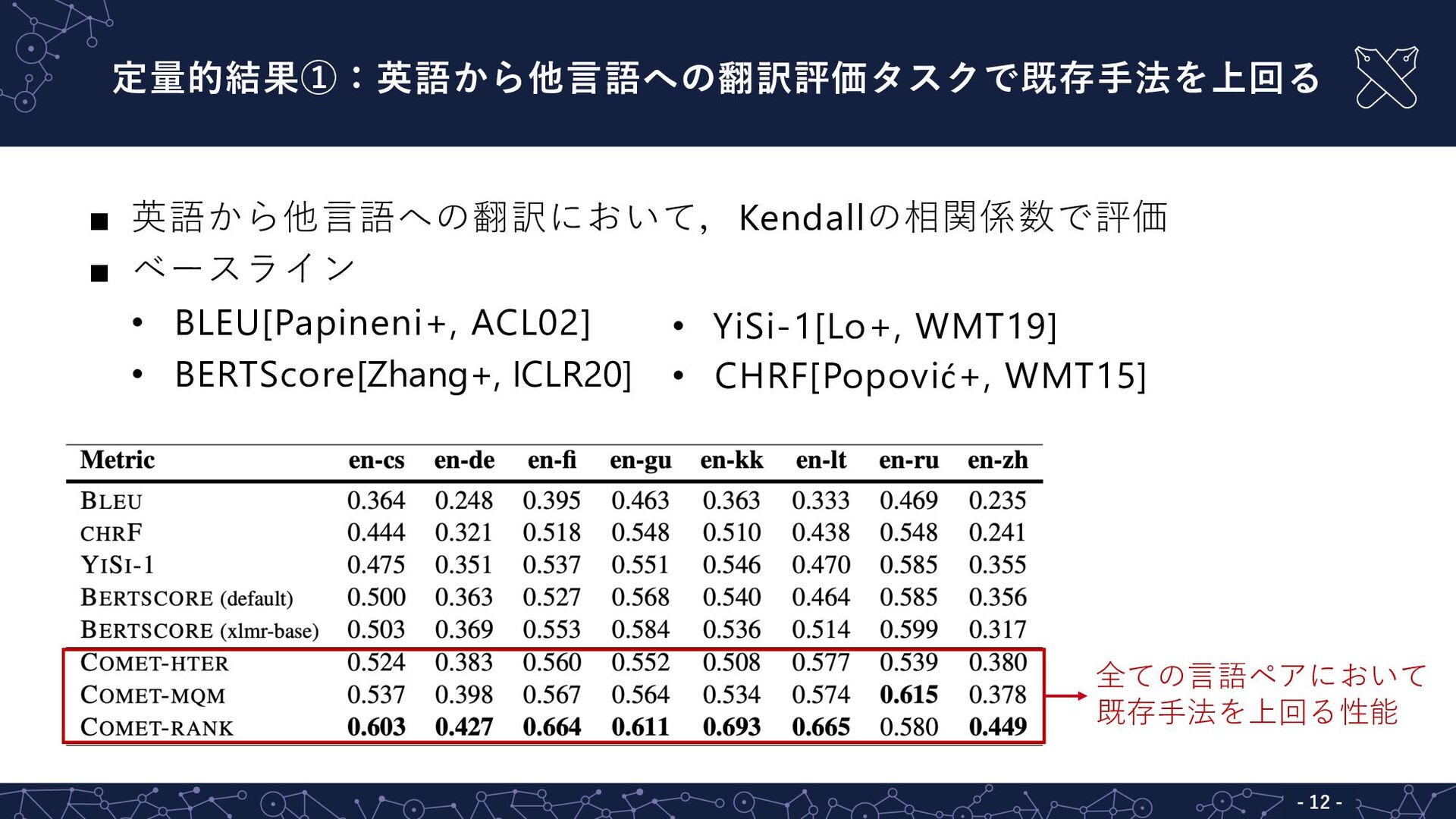
定量的結果①:英語から他⾔語への翻訳評価タスクで既存⼿法を上回る - 12 - ▪ 英語から他⾔語への翻訳において,Kendallの相関係数で評価 ▪ ベースライン • BLEU[Papineni+,
ACL02] • BERTScore[Zhang+, ICLR20] 全ての⾔語ペアにおいて 既存⼿法を上回る性能 • YiSi-1[Lo+, WMT19] • CHRF[Popović+, WMT15]
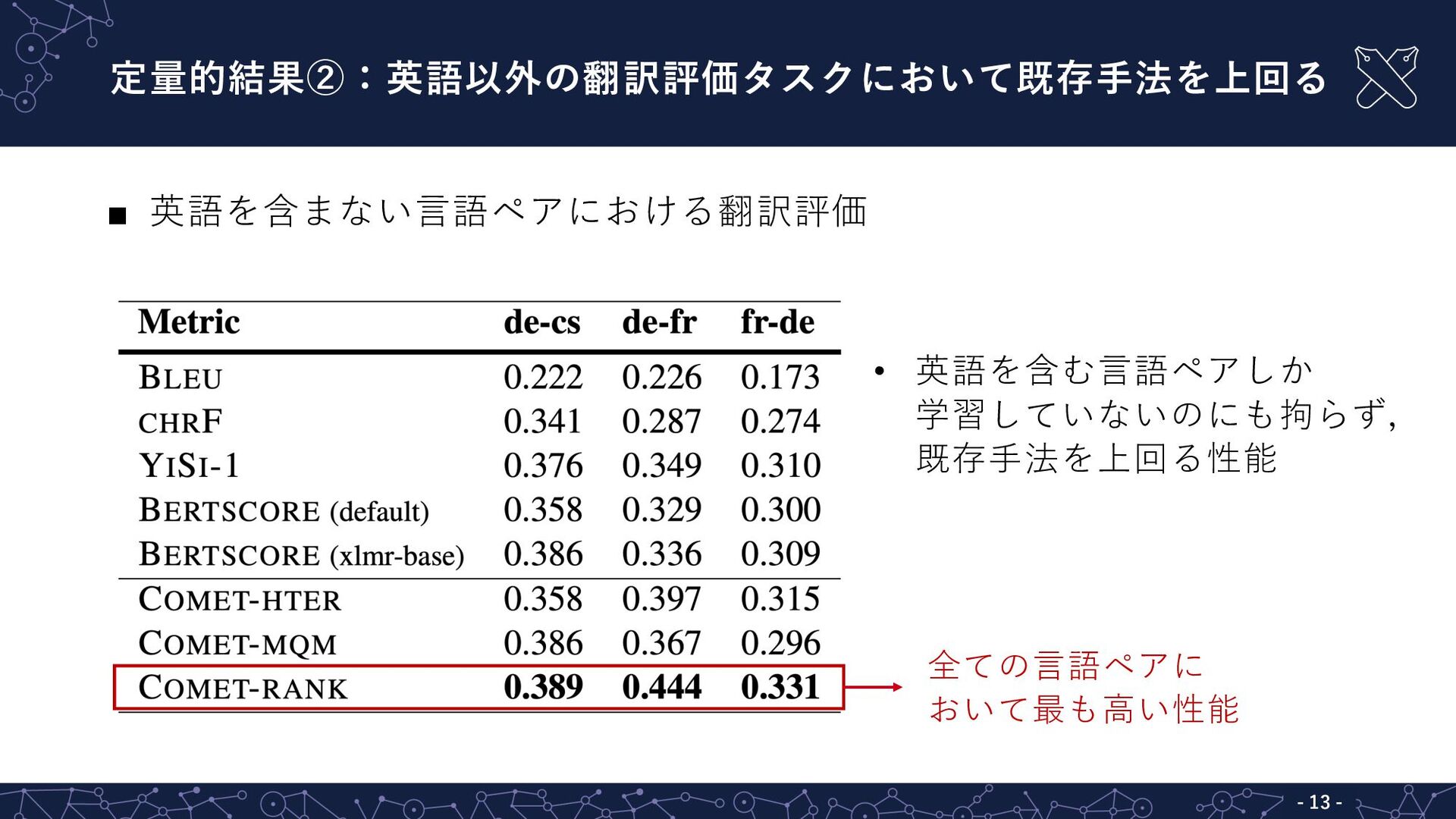
定量的結果②:英語以外の翻訳評価タスクにおいて既存⼿法を上回る - 13 - ▪ 英語を含まない⾔語ペアにおける翻訳評価 • 英語を含む⾔語ペアしか 学習していないのにも拘らず, 既存⼿法を上回る性能
全ての⾔語ペアに おいて最も⾼い性能
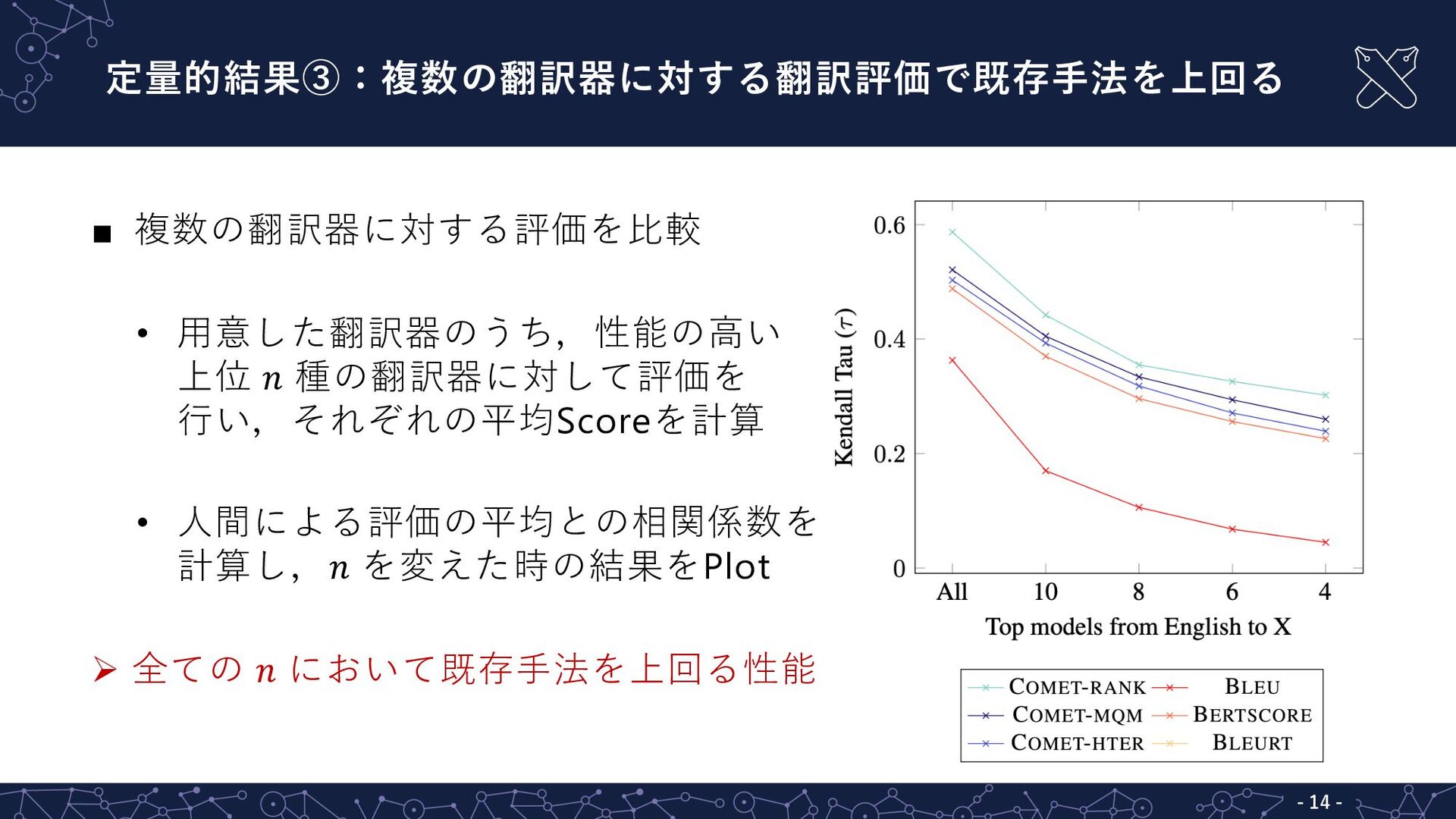
定量的結果③:複数の翻訳器に対する翻訳評価で既存⼿法を上回る - 14 - ▪ 複数の翻訳器に対する評価を⽐較 • ⽤意した翻訳器のうち,性能の⾼い 上位 !
種の翻訳器に対して評価を ⾏い,それぞれの平均Scoreを計算 • ⼈間による評価の平均との相関係数を 計算し,! を変えた時の結果をPlot Ø 全ての ! において既存⼿法を上回る性能
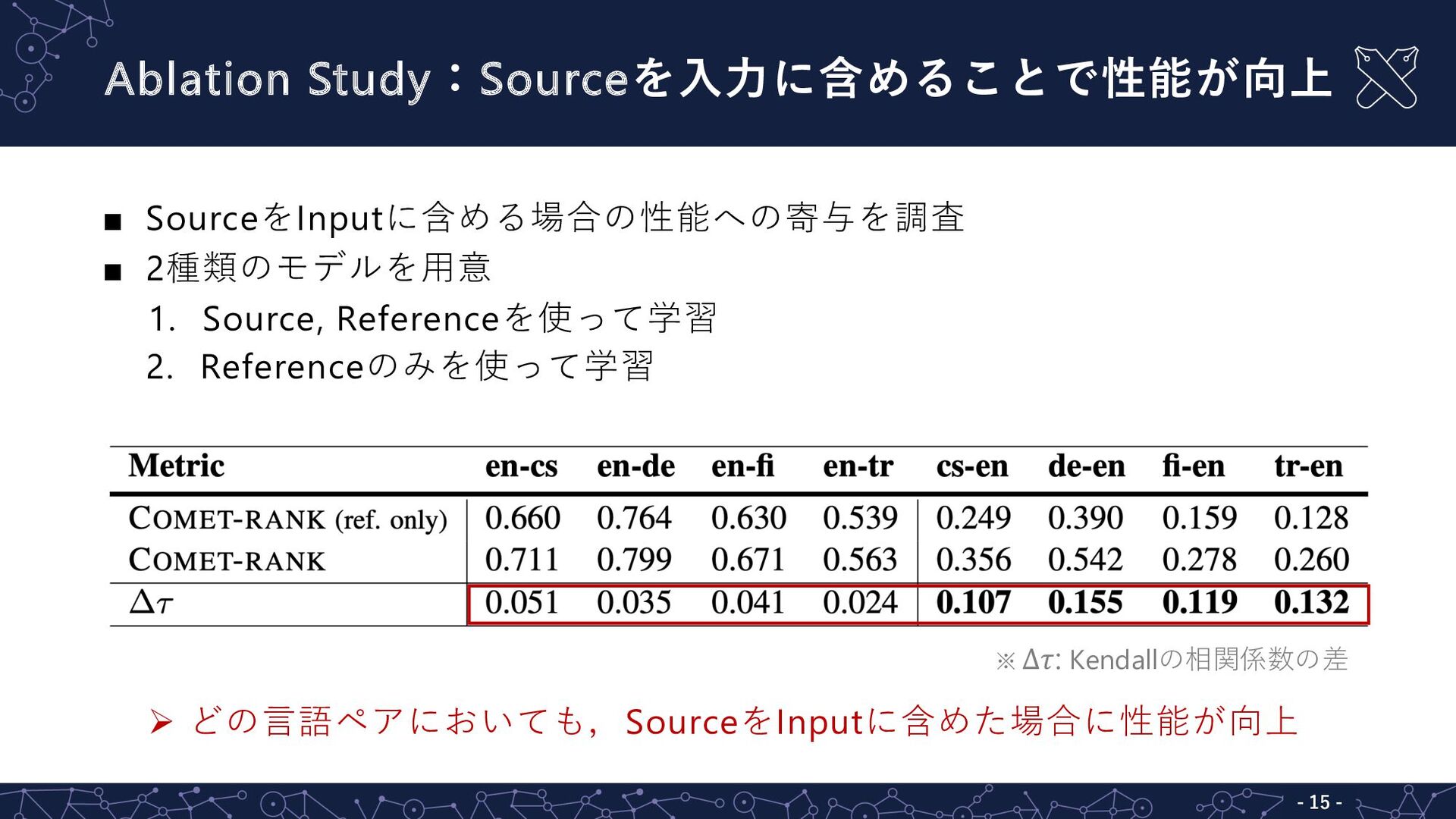
Ablation Study:Sourceを⼊⼒に含めることで性能が向上 - 15 - ▪ SourceをInputに含める場合の性能への寄与を調査 ▪ 2種類のモデルを⽤意 1.
Source, Referenceを使って学習 2. Referenceのみを使って学習 Ø どの⾔語ペアにおいても,SourceをInputに含めた場合に性能が向上 ※ ∆$: Kendallの相関係数の差
結論 - 18 - ▪ 問題点 • 機械翻訳の評価において,BLEUやMETEORといった Rule-basedの⼿法は,⼈間による評価との相関が低い ▪
提案⼿法 • 機械翻訳における学習可能な⾃動評価尺度COMETを提案 • Reference,Source,Hypothesisを⼊⼒とし,⼈間による評価を学習 ▪ 様々な機械翻訳評価タスクにおいて既存⼿法を上回る性能
Appendix:DA - 20 - ▪ DA (Direct Assessment)[Graham+, LAW13]:連続的な評価スケール Continuous
Measurement Scales [Graham+, LAW13] Continuous rating scale Likert-type scale
Appendix:TER, HTER - 21 - ▪ TER [Snover+, AMTA06]:事前に作成されたReferenceを⽤いて評価 ▪
HTER [Snover+, AMTA06] • 以下の処理により動的に新たなReferenceを⽣成して評価 • Step1:作業者にHypothesisとReferenceを提⽰ • Step2:作業者はReferenceをもとにHypothesisを編集し, 新たにTargeted Referenceを作成 • Step3:Targeted Referenceを⽤いてTERと同様にScoreを計算 ※S:ReferenceとHypothesisを⽐較した時の置換語数, I:ReferenceとHypothesisを⽐較した時の挿⼊語数 D:ReferenceとHypothesisを⽐較した時の脱落語数, M : 単語もしくは単語列のシフト回数 T:Referenceの単語数
Appendix:MQM - 22 - ▪ MQM:Multidimensional Quality Metric • エラーの度合いに応じて,Minor
/ Major / Criticalの3つに分類 !!"#$% :Minor Errorの数, !!&'$% :Major Errorの数, !(%"). :Critical Errorの数
Appendix:BERT Score - 23 - ▪ BERT Score [Zhang+, ICLR20]
• 事前学習されたBERT [Devlin+, NAACL19]から得られる ベクトル表現を利⽤して,トークン間のcos類似度を計算 • 最後にPrecision, Recall, F値を計算
Appendix:BLEU - 24 - ▪ BLEU [Papineni+, ACL02] • !-gramのうち,どの程度が正解テキストに含まれているかを評価
• 出⼒テキストの⻑さに対する制約であるBP (Brevity Penalty)を導⼊ BLEU = BP× exp / !"# $ 0! log 4! = 短い翻訳へのPenalty × 9 − gram精度の幾何平均 ただし, LM = N 1 if P ≥ R S(#&'/)) if P ≤ R , 0! = ∑+ 5−gramの⼀致数 ∑+ 全5−gram数 P : 翻訳⽂の⻑さ R : referenceの⻑さ ,! : 重み (Baselineでは,! = 1/N)
Appendix:Kendallの相関係数 - 25 - ▪ Kendallの相関係数:⼤⼩関係の⼀致率に基づいた相関係数 ただし,
{kind=link}
![背景:Rule-basedの評価指標は⼈間による評価との相関が低い - 3 - ▪ Rule-basedの評価指標 • BLEU [Papineni+, ACL02]やMETEOR](https://files.speakerdeck.com/presentations/cb6e08aef3b941f3839c7339f72c0f39/slide_1.jpg){kind=link}
![既存研究:学習可能な既存尺度は改善が必要 - 4 - ▪ RUSE [Shimanaka+, WMT18] • MLPにより⼈間による評価を回帰](https://files.speakerdeck.com/presentations/cb6e08aef3b941f3839c7339f72c0f39/slide_2.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Appendix:DA - 20 - ▪ DA (Direct Assessment)[Graham+, LAW13]:連続的な評価スケール Continuous](https://files.speakerdeck.com/presentations/cb6e08aef3b941f3839c7339f72c0f39/slide_17.jpg){kind=link}
![Appendix:TER, HTER - 21 - ▪ TER [Snover+, AMTA06]:事前に作成されたReferenceを⽤いて評価 ▪](https://files.speakerdeck.com/presentations/cb6e08aef3b941f3839c7339f72c0f39/slide_18.jpg){kind=link}
{kind=link}
![Appendix:BERT Score - 23 - ▪ BERT Score [Zhang+, ICLR20]](https://files.speakerdeck.com/presentations/cb6e08aef3b941f3839c7339f72c0f39/slide_20.jpg){kind=link}
![Appendix:BLEU - 24 - ▪ BLEU [Papineni+, ACL02] • !-gramのうち,どの程度が正解テキストに含まれているかを評価](https://files.speakerdeck.com/presentations/cb6e08aef3b941f3839c7339f72c0f39/slide_21.jpg){kind=link}
{kind=link}