Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
文献紹介20181126_Learning and Evaluating Interpreta...
Search
T.Tada
November 26, 2018
Technology
70
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
文献紹介20181126_Learning and Evaluating Interpretable Sentence Embeddings
T.Tada
November 26, 2018
More Decks by T.Tada
See All by T.Tada
文献紹介_202002_Is artificial data useful for biomedical Natural Language Processing algorithms?
tad
0
75
文献紹介_202001_A Novel System for Extractive Clinical Note Summarization using EHR Data
tad
0
190
文献紹介_201912_Publicly Available Clinical BERT Embeddings
tad
0
180
文献紹介_201911_EDA: Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks
tad
0
230
文献紹介_201910_Do Neural NLP Models Know Numbers? Probing Numeracy in Embeddings
tad
0
110
文献紹介_201909_Sentence Mover’s Similarity_ Automatic Evaluation for Multi-Sentence Texts
tad
0
170
文献紹介_201908_Medical Word Embeddings for Spanish_ Development and Evaluation
tad
0
73
文献紹介_201907_Is Word Segmentation Necessary for Deep Learning of Chinese Representations
tad
0
120
文献紹介_201906_Predicting Annotation Difficulty to Improve Task Routing and Model Performance for Biomedical Information Extraction
tad
0
110
Other Decks in Technology
See All in Technology
徹底討論!ECS vs EKS!
daitak
3
1.8k
UIパーツの設計を「型」から読み解く 〜TSKaigiのセッションから得た学び〜
yud0uhu
0
100
Flow 不死:AI 時代 DevOps 的不變本質
cheng_wei_chen
2
550
When Platform Engineering Meets GenAI
sucitw
0
200
フルAIで個人開発して学んだあれこれ / yuruai vol.1
isaoshimizu
0
150
サイバーエージェントにおけるAI推進戦略と変革への取り組み
shotatsuge
0
610
攻撃者がいなくてもAIエージェントはインシデントを起こす
nomizone
0
130
AIペネトレーションテスト・ セキュリティ検証「AgenticSec」紹介資料
laysakura
2
7.7k
感情と身体を置き去りにしない、エンジニアの生きのこり方 ──いまから、ここから「自分の状態」を扱うという選択
saorimurooka
0
360
5分でわかる Amazon Connect_20260608
hwangbyeonghun
0
130
自分が詳しくない領域でAIを使う #プロヒス2026
konifar
20
7.9k
アラート調査向けAIエージェントの本番導入とその後/AI Agents for Alert Investigation: Production Deployment and After
taddy_919
1
250
Featured
See All Featured
The Curious Case for Waylosing
cassininazir
1
400
Speed Design
sergeychernyshev
33
1.9k
Crafting Experiences
bethany
1
190
The Straight Up "How To Draw Better" Workshop
denniskardys
239
140k
Build The Right Thing And Hit Your Dates
maggiecrowley
39
3.2k
Optimising Largest Contentful Paint
csswizardry
37
3.7k
ピンチをチャンスに:未来をつくるプロダクトロードマップ #pmconf2020
aki_iinuma
128
56k
Effective software design: The role of men in debugging patriarchy in IT @ Voxxed Days AMS
baasie
0
440
SEO in 2025: How to Prepare for the Future of Search
ipullrank
3
3.6k
How to optimise 3,500 product descriptions for ecommerce in one day using ChatGPT
katarinadahlin
PRO
1
3.6k
Winning Ecommerce Organic Search in an AI Era - #searchnstuff2025
aleyda
1
2.1k
4 Signs Your Business is Dying
shpigford
187
22k
Transcript
- 文献紹介 2018/11/26 - Learning and Evaluating Sparse Interpretable Sentence
Embeddings 長岡技術科学大学 自然言語処理研究室 多田太郎
About the thesis Authors : Valentin Trifonov, Octavian-Eugen Ganea, Anna
Potapenko*, Thomas Hofmann ETH Zurich, Switzerland, National Research University Higher School of Economics, Russia* Conference : Proceedings of the 2018 EMNLP Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP, pages 200–210 2
Abstract ・sentence embedding を解釈したい ・ベクトルをスパースにする手法と可読性の評価手法を提案 ・密なベクトルより解釈性が増加 3
Introduction 解釈性とスパースな表現には関連性がある (Murphy et al. : 2012) ベクトルのスパース化には2つの手法がある ・ベクトルを生成し、後処理 ・ベクトル生成時にスパースなものとする
4
Models スタンダードなseq2seqに基づき以下に取り組む 1. Enforcing Sparsity by Post-Processing Dense Embeddings 2.
Enforcing Sparsity during Embedding Learning ・k-Sparse ・Sparsemax 5
Models 1. Enforcing Sparsity by Post-Processing Dense Embeddings Eは2000次元のsparseなベクトルとなる 6
Models 2. Enforcing Sparsity during Embedding Learning スパース化layerでdenseなベクトルZをsparseなベクトル Eに変換するように学習 ・k-Sparse
0でない次元数kを固定したスパース表現 ・Sparsemax softmaxの応用,このsparseな確率分布を利用 上記kを固定しないため、各文に対して柔軟 7
Experiments 1. Training Details ボキャブラリサイズ:20,000 word embeddings : 100 次元
GRU(Cho et al. : 2014)を使用 入力と同じ文字列が出力される様に学習 2. Data ・the Cornell Movie-Dialogs Corpus: 500,000サンプル (バリデーションとテストに50,000サンプルずつ) ・The MS COCO: 600,000サンプル 8
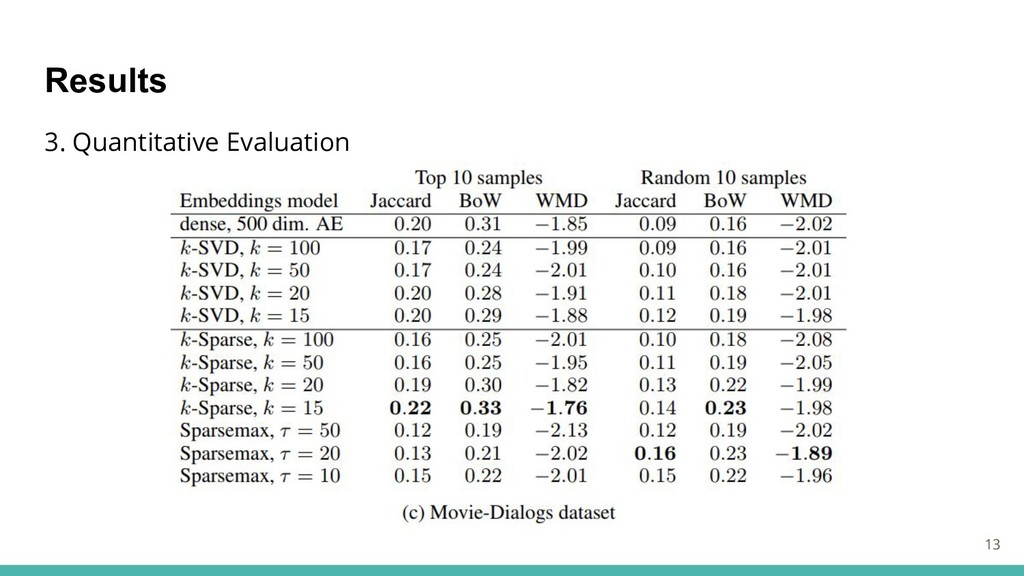
A Quantitative and Automated Evaluation Metric 9 トピック内の単語対の平均単語距離を利用. Topic coherence
:自動評価手法(Newman et al. 2010) をベースとする トピック内の単語ではなく,文ベクトル内の次元でランキングし、上位を使用. 合わせて全非0次元を考慮した場合の比較として、ランダムな選定でも実験.
A Quantitative and Automated Evaluation Metric 類似度計算の手法 10 1. Jaccard
Similarity 2. BoW Similarity 3. WMD Similarity The Word Mover’s Distance(Kusner et al. 2015) Word2Vevを利用したdocument distance measure
Results 1. Reconstruction Quality スパースになるにつれて結果が悪くなる 文法と関連したトピックというの面では上手く生成できている 11
Results 2. Highest-Ranked Samples 各ベクトルで上位となった値を使用 12
Results 3. Quantitative Evaluation 13
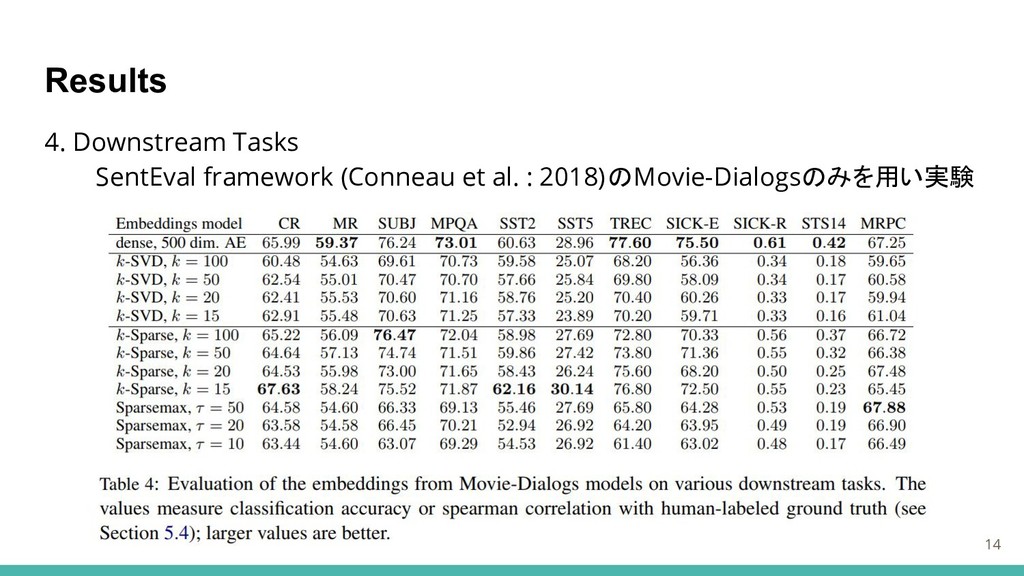
Results 4. Downstream Tasks SentEval framework (Conneau et al. :
2018)のMovie-Dialogsのみを用い実験 14
Discussion ・いい解釈性は取れたが,文の再構築では高いエラー ・スパース性が高いと 各文書の共通的な要素は得られるが,特徴的な情報が落ちてしまう ・分類タスクへの応用では性能が悪化 ・後処理とモデル内でのスパース化では,モデル内での処理の方が若干性能が良さそう スパースlayerで情報が落ち,高いLoss値となった モデルが複雑となるため,トレードオフな関係の様 Sparsemaxでスパース性kを固定しなくて良り,文の特徴に対して柔軟となった 15
Conclusion ・NNの中間表現は基本的に理解できないが,解釈性を得る事は重要 ・スパース化により情報が落ち,タスクでの精度は悪化 ・本論文のスパース化で文ベクトルの解釈性は増した ・評価手法では人間の直感的な理解に沿ったスコアになっている 他の類似度計算手法を用いることも出来,リーズナブル ・DLモデルを理解するヒントとなる可能性 16
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}