Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Kubernetes実践トラブルシューティング
Search
Sponsored
·
SiteGround - Reliable hosting with speed, security, and support you can count on.
→
Satoru Takeuchi
PRO
August 26, 2021
Technology
10k
2
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Kubernetes実践トラブルシューティング
以下イベントの発表資料です。
https://k8sjp.connpass.com/event/218143/
Satoru Takeuchi
PRO
August 26, 2021
More Decks by Satoru Takeuchi
See All by Satoru Takeuchi
Machine Check Exception
sat
PRO
2
32
バイナリダンプの模様を読む
sat
PRO
0
68
cpコマンドはディスク上でデータを コピーしないことがある
sat
PRO
3
54
114-ファイルのshallow_copy.pdf
sat
PRO
2
38
113-Btrfsのスナップショット.pdf
sat
PRO
0
16
システム強制終了時にファイルシステムの整合性を保つ~ コピーオンライト編 ~
sat
PRO
0
59
システム強制終了時に ファイルシステムの整合性を保つ ~ ジャーナリング編 ~
sat
PRO
2
63
ファイルシステムの整合性を回復するfsck
sat
PRO
1
65
小学校5,6年生向けキャリア教育 大人になるまでの道
sat
PRO
8
5.2k
Other Decks in Technology
See All in Technology
あなたの『Site』はどこですか? — xREという考え方
miyamu
0
1.2k
しくみを学んで使いこなそう GitHub Copilot app
torumakabe
1
210
AI時代の EM への処方箋
staka121
PRO
0
130
Gen3R: 3D Scene Generation Meets Feed-Forward Reconstruction
spatial_ai_network
0
110
最適な自走を最小限の支援で — M&Aで拡大する組織で少人数SREが挑んだ1年 / SRE NEXT 2026
genda
0
1k
環境凍結という Toil を倒す -セルフサービス型 Ephemeral テスト環境の 設計と実践
shirouz
1
2.2k
アカウントが増えてからでは遅い? ~ マルチアカウント統制の勘所 ~
kenichinakamura
0
220
AI駆動開発におけるQAエンジニアの役割事例 〜AI駆動開発の現場から〜
kobayashiyorimitsu
0
490
Baseline対応のDOMの型定義を作った
uhyo
3
730
Claude Code公式skillで 自分の仕事を少しずつ手放そう!(Claude Code開発ノウハウ大公開スペシャル by クラスメソッド)
kaym
0
130
SRE本の知られざる名シーン / The Hidden Gems of Google SRE Book
nari_ex
1
360
“全部コピーしない”ファイルデータの活用 : — FSx for ONTAP × S3 Tables × Icebergで作るメタデータカタログ
yoshiki0705
0
710
Featured
See All Featured
Pawsitive SEO: Lessons from My Dog (and Many Mistakes) on Thriving as a Consultant in the Age of AI
davidcarrasco
0
180
Understanding Cognitive Biases in Performance Measurement
bluesmoon
32
3k
Design in an AI World
tapps
1
260
Applied NLP in the Age of Generative AI
inesmontani
PRO
4
2.4k
Design of three-dimensional binary manipulators for pick-and-place task avoiding obstacles (IECON2024)
konakalab
0
490
KATA
mclloyd
PRO
35
15k
Winning Ecommerce Organic Search in an AI Era - #searchnstuff2025
aleyda
1
2.1k
Navigating Team Friction
lara
192
16k
Intergalactic Javascript Robots from Outer Space
tanoku
273
27k
Performance Is Good for Brains [We Love Speed 2024]
tammyeverts
12
1.7k
sira's awesome portfolio website redesign presentation
elsirapls
0
300
Avoiding the “Bad Training, Faster” Trap in the Age of AI
tmiket
0
190
Transcript
Kubernetes 実践トラブルシューティング Aug. 26th, 2021 sat@サイボウズ ストレージチーム 1
はじめに ▌サイボウズのインフラ基盤はKubernetesクラスタ ▌ストレージもK8sクラスタ上に構築 ⚫Rook/Ceph(後述)によって分散ストレージを提供 ▌ストレージ開発中に発生した問題を例にトラブル シューティングのノウハウを共有 ⚫ストレージ、Rook/Cephについての前提知識は不要 2
このセッションで学べること ▌実際に起きた問題のトラブルシューティングの流れ ▌なぜその調査をしたのか、という思考プロセス ▌ログやメトリクスの重要性 3
もくじ ▌Rook/Ceph概要 ▌サイボウズのRook/Cephクラスタと監視/ログ基盤 ▌トラブル解析事例 ▌まとめ 4
Rook/Ceph概要 5
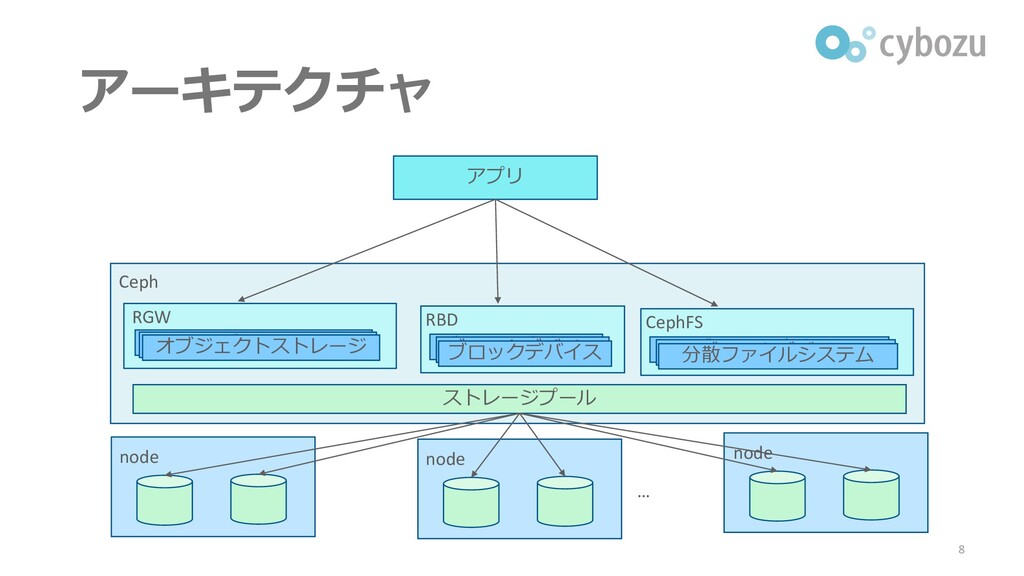
Cephとは ▌OSSのスケーラブルな分散ストレージ ⚫多くの種類のストレージを提供可能(後述) ⚫ペタバイトスケールのデータを扱える ▌20年以上にわたって幅広く使われてきた ⚫CERN, NASA ▌主な開発元はRed Hat ⚫Red
Hat Ceph Storageなどの製品を提供 6
提供するストレージの種類 ▌S3互換オブジェクトストレージRGW ⚫今日取り扱うのはこれ ▌ブロックデバイスRBD ▌分散ファイルシステムCephFS 7
アーキテクチャ 8 アプリ ストレージプール Ceph node node node … RBD
RGW ブロックデバイス オブジェクト ブロックデバイス ブロックデバイス オブジェクト オブジェクトストレージ CephFS ブロックデバイス ブロックデバイス 分散ファイルシステム
▌RGWが提供するendpointにアプリがアクセス オブジェクトストレージの使い方 9 Rook/Cephクラスタ アプリ RGW daemon
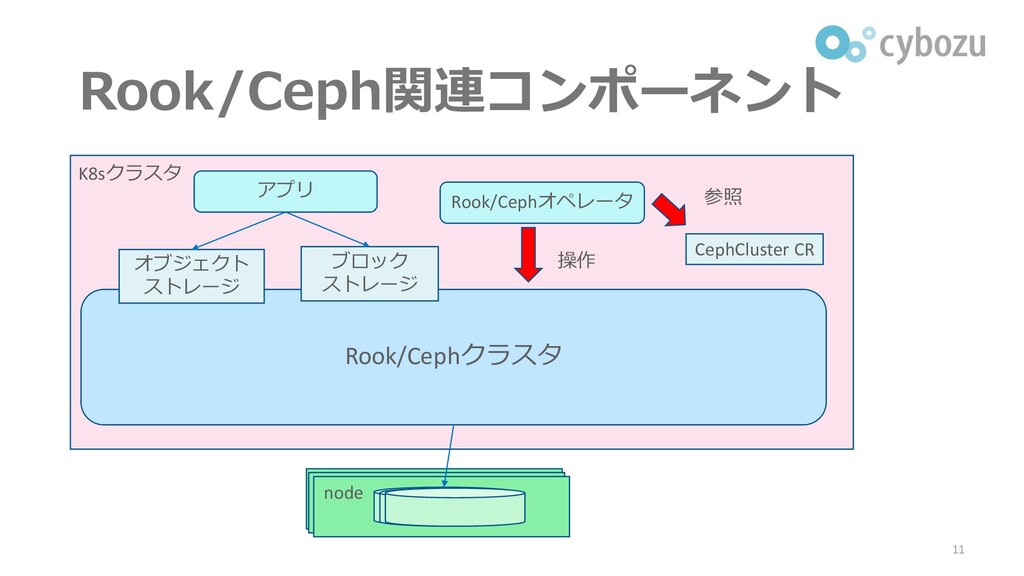
Rookとは ▌Kubernetes上で動作するCephのオーケストレータ ⚫CNCFのgraduated Project ▌主な開発元 ⚫Red Hat, サイボウズ ▌製品 ⚫Red
Hat OpenShift Container Storage 10
Rook/Ceph関連コンポーネント 11 K8sクラスタ Rook/Cephクラスタ オブジェクト ストレージ ブロック ストレージ HDD node
HDD アプリ Rook/Cephオペレータ CephCluster CR 操作 参照
オブジェクトストレージの使い方 12 K8sクラスタ Rook/Cephクラスタ アプリのPod RGW Pod
サイボウズの Rook/Cephクラスタと監視/ログ基盤 13
なぜRook/Cephなのか ▌商用製品はできれば避けたい ⚫ユーザデータは極めて重要 ⚫データ消失するとお客様もサイボウズも大ダメージ ⚫無いものは無い。取り返しがつかない ⚫商用製品には勝手に手を入れられない ⚫トラブル発生時にとれる手段が減る ▌OSSの自前運用が有力な選択肢 ⚫Rook/Cephが要件を満たしていた 14
サイボウズのRook/Cephクラスタ 15 K8sクラスタ Rook/Cephクラスタ (HDD) オブジェクト ストレージ ブロック ストレージ HDD
node node SSD HDD HDD SSD NVMe SSD アプリ Rook/Cephクラスタ (NVMe SSD) ブロック ストレージ
開発/運用プロセス 1. 検証&構築&実機上で運用 2. 課題が見つかる ⚫基本はupstreamで修正&次回の新版を使う ⚫マージまで一時的に独自版運用 and/or パラメタ設定で回避 ⚫マージ不可能ならば上記の運用を続けることも許容
3. 1に戻る 16
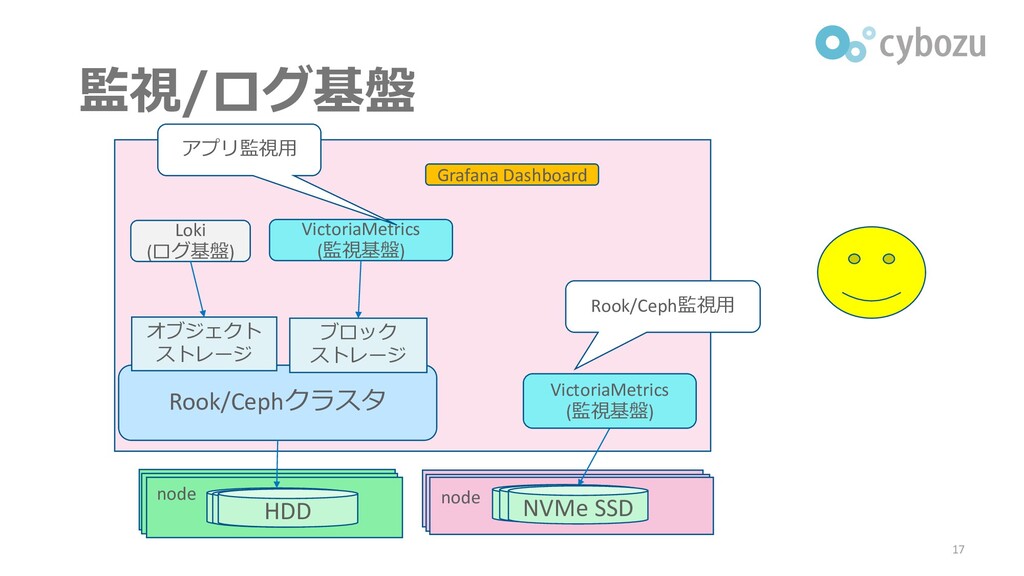
監視/ログ基盤 17 Rook/Cephクラスタ Loki (ログ基盤) VictoriaMetrics (監視基盤) オブジェクト ストレージ ブロック
ストレージ HDD node node SSD HDD HDD SSD NVMe SSD VictoriaMetrics (監視基盤) Grafana Dashboard アプリ監視用 Rook/Ceph監視用
監視/ログ基盤の使い方(1/4) 18 Rook/Cephクラスタ Loki (ログ基盤) オブジェクト ストレージ HDD node node
SSD HDD HDD SSD NVMe SSD VictoriaMetrics (監視基盤) Grafana Dashboard ①メトリクス収集 ①ログ収集
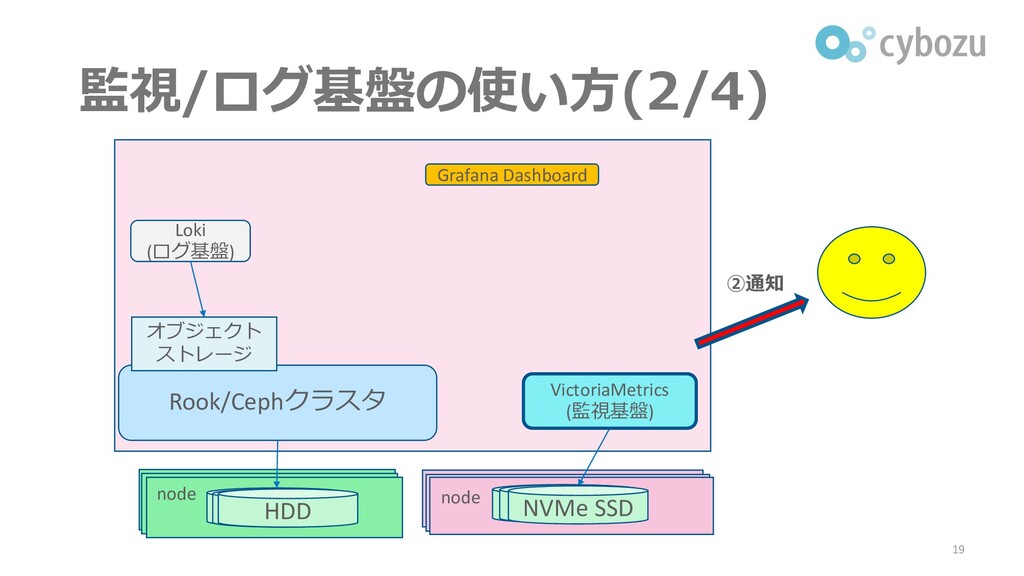
監視/ログ基盤の使い方(2/4) 19 Rook/Cephクラスタ Loki (ログ基盤) オブジェクト ストレージ HDD node node
SSD HDD HDD SSD NVMe SSD VictoriaMetrics (監視基盤) Grafana Dashboard ②通知
監視/ログ基盤の使い方(3/4) 20 Rook/Cephクラスタ Loki (ログ基盤) オブジェクト ストレージ HDD node node
SSD HDD HDD SSD NVMe SSD VictoriaMetrics (監視基盤) Grafana Dashboard ③操作
監視/ログ基盤の使い方(4/4) 21 Rook/Cephクラスタ Loki (ログ基盤) オブジェクト ストレージ HDD node node
SSD HDD HDD SSD NVMe SSD VictoriaMetrics (監視基盤) Grafana Dashboard ④クエリ発行
監視/ログ基盤の嬉しさ ▌システムのログやメトリクスを一か所に保存できる ▌システム全体の長期的な挙動がわかる ⚫ 「正常なときと異常なときと何が違うか」など ⚫ クエリ言語(PromQL, LogQL)により一括して情報を取得可能 ▌システムにおかしなことがあれば技術者に通知できる ⚫
技術者が常にダッシュボードを監視していなくてよい 22
トラブル解析事例 23
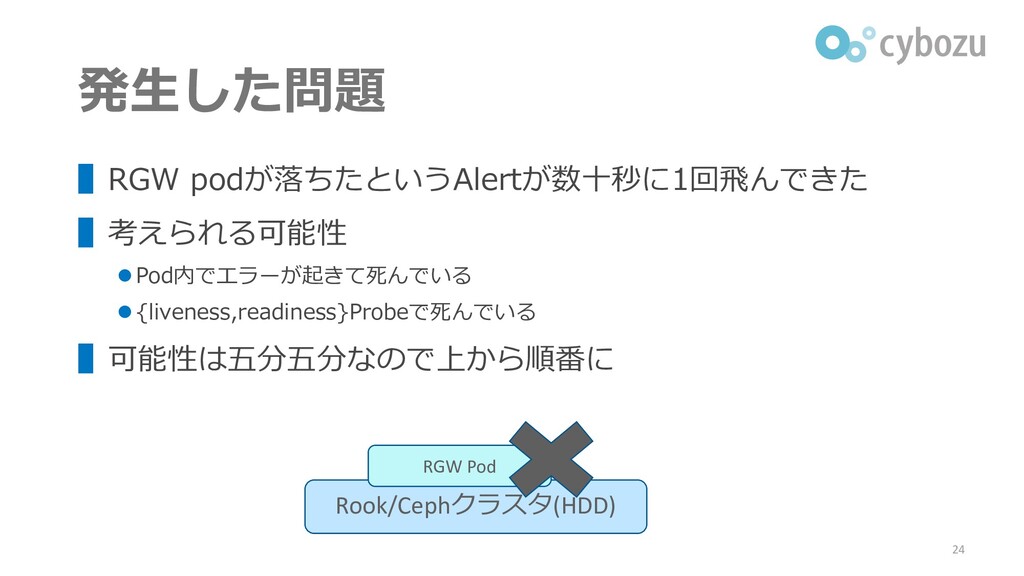
発生した問題 ▌RGW podが落ちたというAlertが数十秒に1回飛んできた ▌考えられる可能性 ⚫ Pod内でエラーが起きて死んでいる ⚫ {liveness,readiness}Probeで死んでいる ▌可能性は五分五分なので上から順番に 24
Rook/Cephクラスタ(HDD) RGW Pod
Pod内で死んでいるかどうかの確認 ▌ログを見る ⚫DashboardからLokiのログを確認 ▌以下のようなログが繰り返し出力されていた ▌“…lock failed”というメッセージは問題ないとわかった ▌しかし自ら強制終了した形跡はない - NOTICE: resharding
operation on bucket index detected, blocking - RGWReshardLock::lock failed to acquire lock on loki-bucket-XXX ret=-16 25
{liveness,readiness}Probeの発生有無を確認 ▌Podに起きたイベントを確認 ▌livenessProbeで殺され続けていた ▌Next action ⚫livenessProbeで何をチェックしているか確認 $ kubectl –n ceph-hdd
describe pod rook-ceph-rgw-XXX … Events: … spec.containers{rgw} Warning Unhealthy Liveness probe failed:… 26
livenessProbeの設定を確認 ▌RGW Podの定義を見る ▌Endpointは”swift/healthcheck” ▌Next action ⚫上記endpointの意味を調べる $ kubectl get
pod rook-ceph-rgw-XXX –o yaml … livenessProbe: … httpGet: path: /swift/healthcheck … 27
/swift/healthcheckの意味を調査 1. Web検索&ソース調査 2. RGWのサービスが生きていれば成功するとわかった 3. ダッシュボードからRGWのオブジェクト数を確認 28 オブジェクト数→ 時間→
• 全然増えていない • 普段はLokiが作るオブジェクトが 定期的に増える
状況の整理 ▌明らかになったこと 1. RGWのサービスが停止している 2. livenessProbeの使い方を間違えている ⚫ livenessProbe: Podの正常動作可否を確認 ⚫
readinessProbe: サービス提供可否を確認 ▌Next action ⚫重要度が高い①を先に調査 29
なぜサービスが停止するのかを調査 ▌RGW podのログを再び確認 ▌Dynamic resharding(後述)という処理が繰り返し動いている 0 block_while_resharding ERROR: bucket is
still resharding, please retry 0 check_bucket_shards: resharding needed: … 0 check_bucket_shards: resharding needed: … … 0 NOTICE: resharding operation on bucket index detected, blocking 0 RGWReshardLock::lock failed to acquire lock on reshard.0000000009 ret=-16 1 RGWRados::check_bucket_shards bucket loki-bucket-XXX needs resharding; … 30
Dynamic reshardingとは ▌resharding ⚫1つのbucketに対して1つindexが存在 ⚫ オブジェクト名からオブジェクトの場所を引く ⚫Indexは複数の領域にshardされている ⚫オブジェクト数増加にって検索速度が劣化 ⚫速度の劣化はreshardによって防げる ▌Dynamic
resharding ⚫オブジェクト数が増えてくると自動的にreshardする機能 31
仮説 ▌以下のようにreshard処理が永久に終わらない 1. オブジェクト数が増えたためdynamic resharding発動 2. Reshard中は/swift/healthcheckを叩くと失敗 3. ゆえにRGW PodのlivenessProbeが失敗
4. Podが殺される 5. Reshard処理が中断 6. 1に戻る ▌Next Action ⚫実際にそうなっているか確認 32
Reshardのstatusを確認 ▌Reshard処理の進捗を確認 ▌定期的にreshard処理が失敗し続けていた ⚫ 仮説は裏付けられた $ radosgw-admin reshard status --bucket=loki-bucket-XXX
[ { "reshard_status": "in-progress", "new_bucket_instance_id": “YYY", "num_shards": 419 }, { "reshard_status": "in-progress", "new_bucket_instance_id": “YYY", "num_shards": 419 }, … 33
対策を考える ▌短期対策 ⚫今まさにオブジェクトストレージが使えない問題を解決 ▌中長期対策 ⚫次回以降問題を起きなくする ⚫短期対策の後で考える 34
短期対策 ▌livenessProbeを無効化してreshardを実行 ▌手順 1. operatorを一時停止(deploymentのreplica数を0に) ⚫ 以下操作の後にoperatorがDeploymentを再度書き換えるのを防ぐ 2. RGWのDeploymentからlivenessProbeを削除 3.
手動でreshard処理を起動 4. reshard終わったらoperatorを再度動かす 35
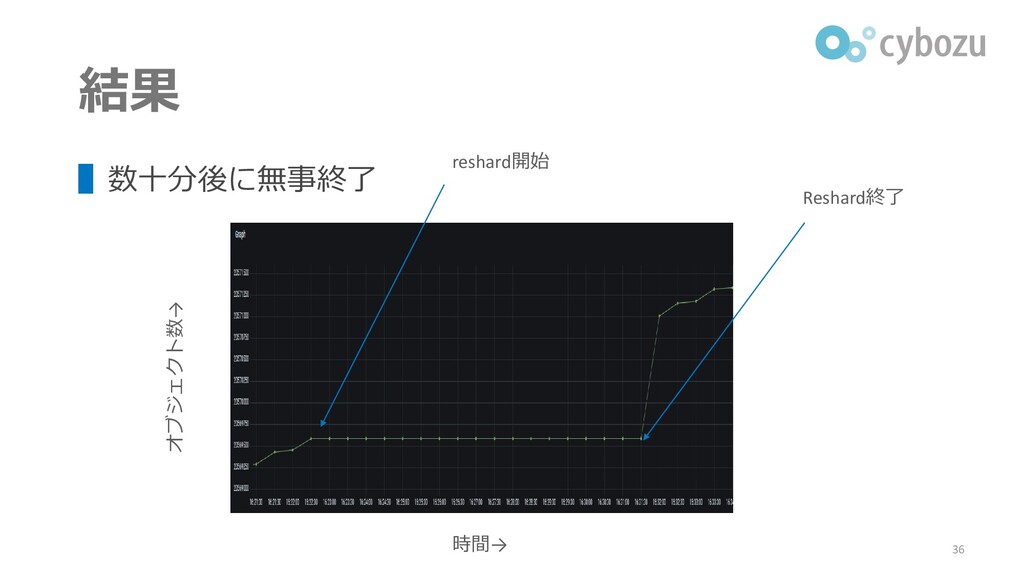
結果 ▌数十分後に無事終了 36 オブジェクト数→ 時間→ reshard開始 Reshard終了
中期対策 ▌考えられる案 1. dynamic reshardingを無効化 2. 最初からshardの数を十分に増やしておく ▌ひとまず上記対処は見送り ⚫次に起きるのは数か月後 ⚫現状このストレージは可用性の保証がない
⚫他に優先すべきタスクがある 37
長期対策 1. まずは過去事例調査 ⚫Rookにほぼ同じissueが報告されていた 2. Issueにコメントして議論開始 3. 長期対策向けの方針を決定 ⚫最新版のCephで再現させ、再現するならreshard処理中にサービス停 止をしなくするよう活動(自分でPR投げるかも)
⚫RookのlivenessProbeのありかたについて議論 38
得られたもの ▌今後同じ問題を回避できるようになった ▌技術者の経験値が上がった ⚫今後の類似トラブル調査に当たりがつくようになった 39
その他トラシュー用のTIPS ▌システムに対して「いつ」「何をしたか」を常に記録 ⚫何か起きたときに発生契機を突き止めるためのヒントになる ▌調査中のログも可能な限り残す ⚫今後の調査に役立つ ▌最後にwikiなどにまとめる ⚫色々なところに情報が散らばっていると後から追いにくい ⚫そのうち記憶が無くなる 40
まとめ 41
学んだこと ▌実際に起きた問題のトラブルシューティングの流れ ▌なぜその調査をしたのか、という思考プロセス ▌ログやメトリクスの重要性 42
今後について ▌やること ⚫性能チューニング&可用性を高める ⚫技術者を育てる ⚫機能追加 ⚫ リモートレプリケーション ⚫ バックアップ/リストア ⚫既存データの移行
▌一緒に働いてくれるかたを募集中! 43
44 おわり
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}